
تتجاوز مجموعات تعهدات Bounce Brand التوقعات في قطاع التمويل اللامركزي
تجاوزت مجموعات تعهدات Bounce Brand لرمز AMMX التوقعات بشكل كبير، مما يشير إلى ثقة المستثمرين القوية والابتكار في قطاع التمويل اللامركزي.
 Brian
Brian

المصدر: Tencent Technology
منذ عيد الربيع، استمرت شعبية DeepSeek في الارتفاع، إلى جانب العديد من سوء الفهم والجدال. يقول بعض الناس إنها "فخر المنتجات المحلية التي تتفوق على OpenAI"، بينما يقول آخرون إنها "مجرد طريقة ذكية لنسخ مهام النماذج الأجنبية الكبيرة".
تتركز هذه المفاهيم الخاطئة والخلافات بشكل أساسي في خمسة جوانب:
1. الأساطير المفرطة والتشويه غير العقلاني، هل DeepSeek حقًا ابتكار من المستوى الأدنى؟ هل هناك أي أساس لما يسمى بـ ChatGPT المقطر؟ 2. هل تبلغ تكلفة DeepSeek حقًا 5.5 مليون دولار أمريكي فقط؟ 3. إذا كان DeepSeek قادرًا حقًا على أن يكون بهذه الكفاءة، فهل ستذهب النفقات الرأسمالية الضخمة في مجال الذكاء الاصطناعي التي تنفقها شركات العملاق العالمي الكبرى سدى؟
4. هل يستخدم DeepSeek برمجة PTX؟ هل يمكنه حقًا تجاوز الاعتماد على Nvidia CUDA؟ 5. DeepSeek يحظى بشعبية كبيرة في جميع أنحاء العالم، ولكن هل سيتم حظره في الدول الأجنبية بسبب عدم الامتثال والقضايا الجيوسياسية وغيرها؟ 1. الأساطير المفرطة والتشهير غير المدروس هل DeepSeek هو حقًا ابتكار من المستوى الأدنى؟
يعتقد خبير الإنترنت كاوز أن قيمته في تعزيز تطوير الصناعة تستحق التقدير، ولكن من السابق لأوانه الحديث عن التخريب. وفقًا لبعض التقييمات المهنية، فهو لا يتفوق على ChatGPT في حل بعض المشكلات الرئيسية.
على سبيل المثال، قام شخص ما باختبار الكود لمحاكاة ارتداد كرة عادية في مساحة مغلقة. كان أداء البرنامج الذي كتبه DeepSeek مختلفًا عن أداء ChatGPT o3-mini من حيث التوافق مع الفيزياء.
لا تبالغ في إضفاء الأساطير عليها، ولكن لا تقلل من شأنها أيضًا دون تفكير.
هناك حاليا وجهتا نظر متطرفتان بشأن الإنجازات التكنولوجية التي حققتها شركة DeepSeek: الأولى تصف اختراقها التكنولوجي بأنه "ثورة ثورية"؛ والثانية تعتقد أنها مجرد تقليد للنماذج الأجنبية، وهناك حتى تكهنات بأنها حققت تقدما من خلال تقطير نموذج OpenAI. قالت شركة Microsoft أن DeepSeek قام باستخلاص نتائج ChatGPT، لذا استغل بعض الأشخاص هذه المشكلة واستخفوا بـ DeepSeek ووصفوه بأنه لا قيمة له.
في الواقع، كلا وجهتي النظر متحيزتان للغاية.
ولكي نكون أكثر دقة، فإن الاختراق الذي حققته شركة DeepSeek هو ترقية للنموذج الهندسي تهدف إلى معالجة نقاط الألم في الصناعة، مما يفتح مسارًا جديدًا لـ "الأقل هو الأكثر" في التفكير بالذكاء الاصطناعي.
إنه يقوم بشكل أساسي بالابتكارات على ثلاثة مستويات:
أولاً، من خلال تقليص بنية التدريب - على سبيل المثال، تبسط خوارزمية GRPO الخوارزميات المعقدة إلى حلول هندسية يمكن تنفيذها من خلال التخلص من نموذج Critic (أي تصميم "المحرك المزدوج") المطلوب في التعلم التعزيزي التقليدي؛
ثانيًا، يتبنى معايير تقييم بسيطة. على سبيل المثال، في سيناريوهات إنشاء التعليمات البرمجية، يتم استخدام نتائج التجميع ومعدلات اجتياز اختبار الوحدة بشكل مباشر بدلاً من التسجيل اليدوي. يحل نظام القواعد الحتمي هذا بشكل فعال مشكلة التحيز الذاتي في تدريب الذكاء الاصطناعي؛
أخيرًا، يجد توازنًا دقيقًا في استراتيجية البيانات. من خلال الجمع بين وضع Zero الذي يسمح بالتطور المستقل الخوارزمي الخالص مع وضع R1 الذي يتطلب فقط آلاف البيانات المصنفة يدويًا، فإنه يحتفظ بقدرة التطور المستقل للنموذج مع ضمان قابلية التفسير البشري. ومع ذلك، لم تخترق هذه التحسينات الحدود النظرية للتعلم العميق، ولم تقلب تمامًا النموذج الفني للنماذج الرائدة مثل OpenAI o1/o3. وبدلاً من ذلك، حلت نقاط الضعف في الصناعة من خلال التحسين على مستوى النظام.
DeepSeek هو برنامج مفتوح المصدر بالكامل ويقوم بتوثيق هذه الابتكارات بالتفصيل، مما يسمح للعالم باستخدام هذه التطورات لتحسين تدريب نموذج الذكاء الاصطناعي الخاص بهم. يمكن رؤية هذه الابتكارات في الوثائق مفتوحة المصدر. كما سلط تانيشك ماثيو أبراهام، مدير الأبحاث السابق في Stability AI، الضوء على ثلاثة ابتكارات من DeepSeek في منشور مدونة حديث: 1. آلية الاهتمام متعدد الرؤوس: تعتمد نماذج اللغة الكبيرة عادةً على بنية Transformer وتستخدم ما يسمى بآلية الاهتمام متعدد الرؤوس (MHA). قام فريق DeepSeek بتطوير نسخة مختلفة من آلية MHA التي يمكنها استخدام الذاكرة بكفاءة أكبر وتحقيق أداء أفضل. 2. GRPO مع مكافآت قابلة للتحقق: يثبت DeepSeek أن عملية التعلم التعزيزي (RL) البسيطة للغاية يمكنها في الواقع تحقيق نتائج مماثلة لنتائج GPT-4. والأمر الأكثر أهمية هو أنهم طوروا نسخة مختلفة من خوارزمية التعلم المعزز PPO تسمى GRPO وهي أكثر كفاءة وأداء أفضل. 3. DualPipe: عند تدريب نماذج الذكاء الاصطناعي في بيئة متعددة وحدات معالجة الرسومات، يجب مراعاة العديد من العوامل المتعلقة بالكفاءة. قام فريق DeepSeek بوضع نهج جديد يسمى DualPipe وهو أكثر كفاءة وأسرع بشكل كبير. يشير "التقطير" بالمعنى التقليدي إلى تدريب احتمالات الرمز (logits)، ولكن ChatGPT لا يفتح هذا النوع من البيانات، لذا من المستحيل أساسًا "التقطير" ChatGPT.
لذلك، من وجهة نظر تقنية، لا ينبغي التشكيك في إنجازات DeepSeek. نظرًا لأن عملية التفكير المرتبطة بسلسلة OpenAI o1 لم يتم الكشف عنها مطلقًا، فمن الصعب تحقيق هذه النتيجة ببساطة من خلال الاعتماد على "التقطير" ChatGPT. يعتقد Caoz أن DeepSeek ربما استخدم جزئيًا بعض معلومات المجموعة المقطرة أثناء تدريبه، أو قام ببعض التحقق من التقطير، ولكن هذا يجب أن يكون له تأثير ضئيل على جودة وقيمة النموذج بأكمله.
بالإضافة إلى ذلك، فإن تحسين النموذج الخاص بك بناءً على التحقق من تقطير النموذج الرائد هو عملية روتينية للعديد من فرق النماذج الكبيرة. ومع ذلك، يتطلب الأمر واجهة برمجة تطبيقات إنترنت والمعلومات التي يمكن الحصول عليها محدودة للغاية، وهو أمر من غير المرجح أن يكون عاملاً حاسمًا. وبالمقارنة بالكم الهائل من معلومات بيانات الإنترنت، فإن المجموعة التي يمكن الحصول عليها من خلال استدعاء النموذج الكبير الرائد من خلال واجهة برمجة التطبيقات هي قطرة في دلو. ومن المعقول أن نفترض أنها تستخدم أكثر للتحقق من الاستراتيجيات وتحليلها بدلاً من استخدامها مباشرة للتدريب على نطاق واسع.
تحتاج جميع النماذج الكبيرة إلى الحصول على تدريب على مجموعة البيانات من الإنترنت، كما تساهم النماذج الكبيرة الرائدة باستمرار في توفير مجموعة البيانات للإنترنت. ومن هذا المنظور، لا يمكن لأي نموذج كبير رائد أن ينجو من مصير التجميع والتقطير، ولكن لا داعي لاعتبار هذا مفتاح النجاح أو الفشل.
في النهاية، كل شخص هو جزء من الآخر ونحن نتحرك للأمام بشكل متكرر.
التكلفة 5.5 مليون دولار. هذا الاستنتاج صحيح وخاطئ في نفس الوقت لأنه لا يوضح التكلفة.
قام تانيشك ماثيو أبراهام بتقدير تكلفة DeepSeek بشكل موضوعي:
أولاً، من الضروري أن نفهم من أين يأتي هذا الرقم. ظهر هذا الرقم لأول مرة في ورقة DeepSeek-V3، والتي نُشرت قبل شهر واحد من ورقة DeepSeek-R1؛ DeepSeek-V3 هو النموذج الأساسي لـ DeepSeek-R1، مما يعني أن DeepSeek-R1 أجرى في الواقع تدريبًا إضافيًا على التعلم التعزيزي على أساس DeepSeek-V3.
لذا، فإن رقم التكلفة هذا في حد ذاته ليس دقيقًا بما فيه الكفاية لأنه لا يأخذ في الاعتبار التكلفة الإضافية لتدريب التعلم المعزز. ومع ذلك، فإن هذه التكلفة الإضافية قد لا تتجاوز بضع مئات الآلاف من الدولارات.

الشكل: مناقشة التكلفة في ورقة DeepSeek-V3
إذن، هل تكلفة 5.5 مليون دولار المذكورة في ورقة DeepSeek-V3 دقيقة؟
أسفرت التحليلات المتعددة التي اعتمدت على تكلفة وحدة معالجة الرسوميات وحجم مجموعة البيانات ومقياس النموذج عن تقديرات مماثلة. ومن الجدير بالذكر أنه على الرغم من أن DeepSeek V3/R1 هو نموذج يحتوي على 671 مليار معلمة، إلا أنه يستخدم بنية مزيج من الخبراء، مما يعني أنه يتم استخدام حوالي 37 مليار معلمة فقط في أي استدعاء وظيفة أو انتشار أمامي، وهو الأساس لحساب تكلفة التدريب.
يرجى ملاحظة أن DeepSeek يقدم تقارير عن التكاليف التقديرية استنادًا إلى أسعار السوق الحالية. نحن لا نعلم كم تبلغ التكلفة الفعلية لمجموعة وحدات معالجة الرسوميات 2048 H800 (ملاحظة: ليست H100، وهو مفهوم خاطئ شائع). عادةً، يكون شراء مجموعات وحدات معالجة الرسوميات بكميات كبيرة أرخص من شرائها على شكل أجزاء، وبالتالي قد تكون التكلفة الفعلية أقل.
ولكن النقطة الأساسية هي أن هذه هي تكلفة الجولة التدريبية النهائية فقط. هناك العديد من التجارب صغيرة النطاق ودراسات الاستئصال قبل الوصول إلى التدريب النهائي، مما يتسبب في تكاليف كبيرة لا تنعكس في هذا التقرير.
بالإضافة إلى ذلك، هناك العديد من التكاليف الأخرى، مثل رواتب الباحثين. وفقًا لشركة SemiAnalysis، يُقال إن باحثي DeepSeek يحصلون على ما يصل إلى مليون دولار. ويمكن مقارنة هذا بالرواتب المرتفعة في مختبرات الذكاء الاصطناعي العام المتطورة مثل OpenAI أو Anthropic. ينكر بعض الأشخاص التكلفة المنخفضة والكفاءة التشغيلية لـ DeepSeek بسبب وجود هذه التكاليف الإضافية. هذا البيان غير عادل على الإطلاق. لأن شركات الذكاء الاصطناعي الأخرى تنفق أيضًا الكثير من الأموال على الرواتب، والتي عادةً لا يتم تضمينها في تكلفة النموذج. "
كما قدمت شركة Seminalysis (وهي شركة مستقلة للأبحاث والتحليل تركز على أشباه الموصلات والذكاء الاصطناعي) تحليلاً لتكلفة الذكاء الاصطناعي الإجمالية في مجال الذكاء الاصطناعي لشركة DeepSeek. يلخص هذا الجدول التكلفة الإجمالية لـ DeepSeek AI عند استخدام أربعة أنواع مختلفة من وحدات معالجة الرسوميات (A100 وH20 وH800 وH100)، بما في ذلك تكلفة شراء المعدات وبناء الخوادم وتكاليف التشغيل. بناءً على فترة أربع سنوات، تبلغ التكلفة الإجمالية لهذه الوحدات الستين ألف وحدة معالجة رسومية 2.573 مليار دولار أمريكي، بشكل أساسي تكلفة شراء الخوادم (1.629 مليار دولار) وتكاليف التشغيل (944 مليون دولار).
على الرغم من أن Deep Seek قد وجد مسارًا أكثر كفاءة، إلا أن قانون المقياس لا يزال صالحًا، ولكن لا يزال بإمكان المزيد من موارد الحوسبة تحقيق نتائج أفضل.
ذكرت ورقة DeepSeek أن DeepSeek يستخدم برمجة PTX (تنفيذ الخيط المتوازي). من خلال مثل هذا التحسين المخصص لـ PTX، يمكن لنظام DeepSeek ونموذجه إصدار أداء أفضل للأجهزة الأساسية.
النص الأصلي للورقة هو كما يلي:
"نحن نستخدم تعليمات PTX (تنفيذ الخيوط المتوازية) المخصصة ونضبط حجم كتلة الاتصال تلقائيًا، مما يقلل بشكل كبير من استخدام ذاكرة التخزين المؤقت L2 والتداخل مع وحدات SM الأخرى."
"نحن نستخدم تعليمات PTX (تنفيذ الخيوط المتوازية) المخصصة ونضبط حجم كتلة الاتصال تلقائيًا، مما يقلل بشكل كبير من استخدام ذاكرة التخزين المؤقت L2 والتداخل مع وحدات SM الأخرى."
هناك تفسيران لهذا المحتوى المتداول على الإنترنت. يعتقد صوت واحد أن هذا "لتجاوز احتكار CUDA"؛ والصوت الآخر هو أنه نظرًا لعدم تمكن DeepSeek من الحصول على الرقائق الأعلى جودة، لحل مشكلة النطاق الترددي المحدود للترابط بين وحدات معالجة الرسوميات H800، فيجب عليها النزول إلى مستوى أدنى لتحسين قدرات الاتصال بين الرقائق. ويعتقد داي قوه هاو، الأستاذ المشارك في جامعة شنغهاي جياو تونغ، أن كلا البيانين غير دقيقين. أولاً وقبل كل شيء، تعتبر تعليمات PTX (تنفيذ الخيط الموازي) في الواقع مكونًا يقع داخل طبقة برنامج تشغيل CUDA، ولا تزال تعتمد على نظام CUDA البيئي. لذلك، فمن الخطأ القول بأن PTX يمكنه تجاوز احتكار CUDA.
استخدم الأستاذ داي جوهاو عرضًا تقديميًا لشرح العلاقة بين PTX وCUDA بوضوح:
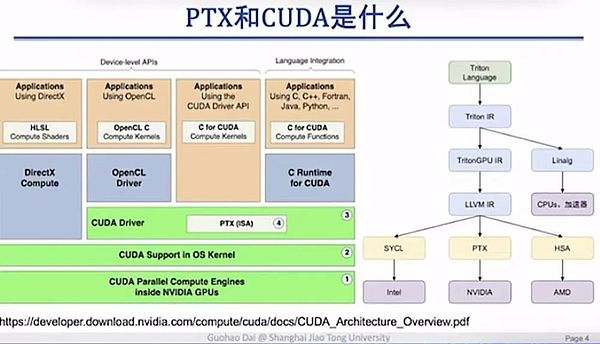
تم إنشاء عرض PPT بواسطة داي جوهاو، الأستاذ المشارك في جامعة شنغهاي جياو تونغ
CUDA هي واجهة ذات مستوى أعلى نسبيًا توفر سلسلة من واجهات البرمجة الموجهة للمستخدم. يتم إخفاء PTX بشكل عام في برنامج تشغيل CUDA، لذلك لن يتعرض جميع مهندسي التعلم العميق أو خوارزميات النموذج الكبيرة لهذه الطبقة.
فلماذا تعتبر هذه الطبقة مهمة جدًا؟ السبب هو أننا نستطيع أن نرى من هذا المنظور أن PTX يتفاعل مباشرة مع الأجهزة الأساسية، مما يتيح برمجة واستدعاء أفضل للأجهزة الأساسية.
ببساطة، لا يعد حل تحسين DeepSeek هو الحل الأخير في ظل الظروف الفعلية لقيود الشريحة، بل هو تحسين استباقي. وبغض النظر عما إذا كانت الشريحة المستخدمة هي H800 أو H100، فإن هذه الطريقة يمكن أن تحسن كفاءة الاتصال والترابط. 5. هل سيتم حظر DeepSeek في الخارج؟
بعد أن أصبح DeepSeek شائعًا، قامت شركات الحوسبة السحابية الخمس الكبرى NVIDIA وMicrosoft وIntel وAMD وAWS بإطلاق DeepSeek أو دمجه. وعلى الصعيد المحلي، تدعم شركات Huawei وTencent وBaidu وAlibaba وVolcano Engine أيضًا نشر DeepSeek.
ومع ذلك، هناك بعض التعليقات العاطفية المفرطة على الإنترنت. فمن ناحية، أطلقت شركات سحابية عملاقة أجنبية برنامج DeepSeek، و"أقنع الأجانب".
في الواقع، فإن نشر هذه الشركات لتقنية DeepSeek يرجع إلى اعتبارات تجارية أكثر. وباعتبارها بائعًا للحلول السحابية، فإن دعم نشر أكبر عدد ممكن من النماذج الأكثر شهرة وكفاءة من شأنه أن يوفر خدمات أفضل للعملاء. وفي الوقت نفسه، يمكنها أيضًا الاستفادة من حركة المرور المرتبطة بـ DeepSeek وربما جلب بعض التحويلات الجديدة للمستخدمين.
صحيح أن نشر البرنامج كان مركّزاً عندما كان DeepSeek يحظى بشعبية كبيرة، ولكن الادعاءات بأن DeepSeek كان لديه إعجاب خاص به أو أن الشركة كانت "مذهلة" مبالغ فيها. والأسوأ من ذلك أن بعض الناس قد اختلقوا قصة مفادها أنه بعد الهجوم على DeepSeek، شكلت دائرة التكنولوجيا الصينية تحالف المنتقمين لدعم DeepSeek بشكل مشترك.
من ناحية أخرى، هناك أيضًا أصوات تقول إنه بسبب أسباب جيوسياسية وأسباب عملية أخرى، سيتم حظر استخدام DeepSeek قريبًا في الخارج.
وفي هذا الصدد، قدم كاوز تفسيرًا واضحًا نسبيًا: في الواقع، ما نسميه DeepSeek يشمل في الواقع منتجين، أحدهما هو DeepSeek، وهو تطبيق مشهور عالميًا، والآخر هو مكتبة أكواد مفتوحة المصدر على GitHub. يمكن اعتبار الأول بمثابة عرض توضيحي للأخير، أي عرض كامل للقدرات. وقد يتحول الأخير إلى نظام بيئي مفتوح المصدر مزدهر.
ما هو مقيد في الاستخدام هو تطبيق DeepSeek، في حين أن ما يصل إليه العمالقة ويقدمونه هو نشر برنامج DeepSeek مفتوح المصدر. إنهما شيئان مختلفان تماما. دخلت DeepSeek ساحة الذكاء الاصطناعي العالمية باعتبارها "نموذجًا صينيًا كبيرًا" واعتمدت بروتوكول المصدر المفتوح الأكثر سخاءً - ترخيص MIT، والذي يسمح حتى بالاستخدام التجاري. إن المناقشات الحالية حول هذا الموضوع تجاوزت إلى حد كبير نطاق الابتكار التكنولوجي، ولكن التقدم التكنولوجي لم يكن قط نزاعًا أبيض وأسود حول الصواب والخطأ. بدلاً من الوقوع في المبالغة أو الإنكار التام، فمن الأفضل ترك الوقت والسوق لاختبار قيمتها الحقيقية. بعد كل شيء، في ماراثون الذكاء الاصطناعي، المنافسة الحقيقية قد بدأت للتو.
المراجع:
"بعض المفاهيم الخاطئة الشائعة حول DeepSeek" المؤلف: caoz
https://mp.weixin.qq.com/s/Uc4mo5U9CxVuZ0AaaNNi5g
"أقوى تفكيك احترافي لـ DeepSeek موجود هنا، التفسير الفائق الصرامة للبروفيسور تشينغجياوفو" المؤلف: ZeR0
https://mp.weixin.qq.com/s/LsMOIgQinPZBnsga0imcvA
فضح أوهام DeepSeek المؤلف: Tanishq Mathew Abraham، رئيس الأبحاث السابق في Stability AI
https://www.tanishq.ai/blog/posts/deepseek-delusions.html
تجاوزت مجموعات تعهدات Bounce Brand لرمز AMMX التوقعات بشكل كبير، مما يشير إلى ثقة المستثمرين القوية والابتكار في قطاع التمويل اللامركزي.
Brianيقوم مشروع Jupiter بتجديد إستراتيجية رمز JUP الخاص به، مع التركيز على التوزيع والحوكمة العادلة التي تركز على المجتمع.
 Alex
Alexيشير دفع الحكومة الإندونيسية لبورصات العملات المشفرة للتسجيل في بورصة السلع المستقبلية (CFX) إلى تحول كبير في المشهد التنظيمي للأصول الرقمية في البلاد.
 Joy
Joyيشكل التبني العالمي للعملات الرقمية للبنوك المركزية، بمشاركة أكثر من 130 دولة، تهديدًا كبيرًا لهيمنة الدولار الأمريكي في التمويل الدولي. ومع تقدم تحالف البريكس جنبًا إلى جنب مع تطورات العملات الرقمية للبنوك المركزية، يظهر عام 2024 كعام محوري يحدد مستقبل الدولار وسط تصاعد جهود إلغاء الدولرة.
Joyتكشف البيانات الموجودة على السلسلة أن الضحية فقد إجمالي 275,700 رابط، تقدر قيمتها حاليًا بـ 4.33 مليون دولار، في معاملتين سريعتين خلال دقيقة من الموافقة على المعاملة.
Brianأصدر رئيس وزراء سنغافورة لي هسين لونج مذكرة تحذيرية للجمهور، كشف فيها عن مقطع فيديو مقلق يتم تداوله عبر الإنترنت. المقطع الملفق، الذي من المفترض أنه يظهر رئيس الوزراء لي في مقابلة مع شبكة سي جي تي إن، يؤيد منصة استثمار العملات المشفرة التي يُزعم أن الحكومة وافقت عليها.
Joyيتهم ZachXBT مستخدم X الذي يخاف من الثدي بأنه ليس سوى محتال مزعوم وراء NFT Machine. وفقًا لقناة Telegram التابعة لـ ZachXBT في 28 ديسمبر، فقد أكد بجرأة أن "مستخدم X/Twitter Scaredofboobs هو محتال يُعرف باسم NFT Machine."
Joyتطلق Bitcoin Cats مجموعة Genesis NFT على Bitcoin Ordinals، ويتم بيعها على BakerySwap.
Alexيتمتع الموقعون المدرجون في القائمة البيضاء بإمكانية الوصول المبكر لشراء رمز SoBit، $SOBB، عند إطلاقه.
Brianتمت سرقة 4.4 مليون دولار من Chainlink بواسطة Pink Drainer في عملية سرقة إلكترونية متطورة.
 Kikyo
Kikyo