إن تتبع البيانات السرية من Ledger Live يثير القلق
يكشف تحقيق Rekt Builder عن تتبع نشاط المستخدم السري لـ Ledger Live، مما يثير مخاوف خطيرة تتعلق بالخصوصية لمستخدمي محفظة أجهزة Ledger.
 Kikyo
Kikyo

المؤلف: تشين جين؛ المصدر: قيمة سلسلة الكربون
دع رؤساء وادي السيليكون ونخب وول ستريت لا يفعلون شيئًا أبدًا ما يتبادر إلى ذهني هو أن DeepSeek، وهي قوة غامضة من الشرق، يمكنها في الواقع أن تتسبب في انخفاض سوق الأسهم الأمريكية وثرواتها الهائلة وانكماشها بين عشية وضحاها. وفي 28 يناير، وفقًا للبيانات ذات الصلة، خسرت أسهم الرقائق الأمريكية تريليون دولار بين عشية وضحاها. تبخرت القيمة السوقية لشركة NVIDIA بمقدار 600 مليار دولار أمريكي في يوم واحد، مسجلة رقمًا قياسيًا لسوق الأسهم الأمريكية. حتى الرئيس الأمريكي ترامب لم يستطع إلا أن يخرج ويدلي ببعض التعليقات. وقال إن الارتفاع المفاجئ لتطبيق الذكاء الاصطناعي الصيني DeepSeek "يجب أن يكون بمثابة دعوة للاستيقاظ لشركات التكنولوجيا الأمريكية"، وقال إنه أمر جيد للشركات الصينية أن تطور نماذج ذكاء اصطناعي أرخص وأكثر كفاءة.
وقال ترامب إنه لا يزال يتوقع أن تهيمن شركات التكنولوجيا الأمريكية على الذكاء الاصطناعي، لكنه أقر بالتحديات التي يفرضها مساعد الذكاء الاصطناعي منخفض التكلفة DeepSeek. ارتفع تطبيق DeepSeek إلى المركز الأول في متجر تطبيقات Apple في نهاية الأسبوع الماضي.
السؤال التالي هو، هل هذه مجرد البداية؟
في الثامن والعشرين من كانون الثاني (يناير)، وفقًا لتقرير صحيفة "فايننشال تايمز" البريطانية، ألقى صندوق تحوط صيني غير معروف قنبلة في مجال الذكاء الاصطناعي. إن نموذج الذكاء الاصطناعي الكبير الذي طوروه يتساوى في الواقع مع نموذج OpenAI الخاص بشركة Sam Altman الرائدة في السوق، ولكن بجزء بسيط من التكلفة. تتعامل OpenAI مع عمل نماذجها كتقنية خاصة، في حين أن DeepSeek's R1 يجعل جوهر التكنولوجيا مفتوح المصدر، مما يجذب المطورين لاستخدامها والبناء عليها.
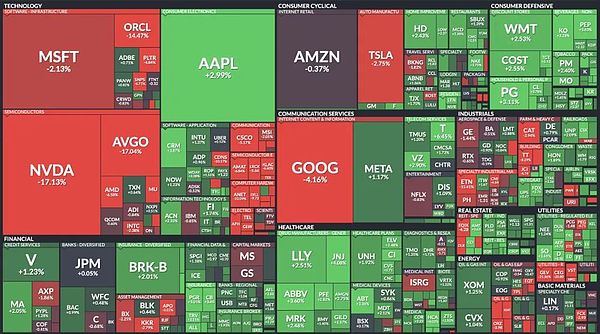
قبل افتتاح سوق الأسهم الأمريكية يوم الاثنين، كانت أكبر خمسة أسهم تكنولوجية في مجال الذكاء الاصطناعي - Nvidia وAlphabet وAmazon وMicrosoft وMeta Platforms - قد وتبخرت القيمة السوقية المجمعة لما يقرب من 750 مليار دولار. إذا فاز DeepSeek دون استخدام رقائقه الأكثر تقدمًا، فقد يكون الأمر قاتمًا بشكل خاص بالنسبة لشركة Nvidia.
بعد افتتاح سوق الأسهم الأمريكية: انخفض سهم Nvidia للرقائق بما يصل إلى 17.5%. وانخفض سهم Broadcom بما يصل إلى 16.5٪. وانخفض سهم TSMC بنسبة 14.3٪. وانخفض سهم ميكرون 10.5%. انخفض الذراع بنسبة 10.0٪. وانخفض سهم AMD بنسبة 5.6%. خسرت أسهم الرقائق المذكورة أعلاه ما يقرب من تريليون دولار من قيمتها السوقية في يوم واحد. من بينها، فقدت إنفيديا جميع مكاسبها منذ 2 أكتوبر، حيث انخفضت بنسبة 21٪ في يومي تداول. انخفضت القيمة السوقية لشركة Nvidia بمقدار 630 مليار دولار. ويأتي ذلك في الوقت الذي خسرت فيه أكبر شركة مدرجة في العالم خمس قيمتها في يومين الأسبوع الماضي. كما تقلصت قيمة هوانغ رينكسون الشخصية بمقدار 100 مليار دولار أمريكي.
إن المستثمرين في شركات التكنولوجيا وشركات الطاقة، بما في ذلك شركة تصنيع الرقائق ASML، الذين كانوا يأملون في أن يؤدي تطوير مراكز البيانات إلى دفع نمو الشركات، أصبحوا الآن قلقين بشأن مستقبلهم. تضيع. تشير تقديرات Visible Alpha إلى أن الشركات الكبيرة جدًا ستنفق ما يقرب من 300 مليار دولار على النفقات الرأسمالية هذا العام. ويتوقع المحللون أن تعلن ميتا ومايكروسوفت عن إجمالي استثمار قدره 94 مليار دولار في عام 2024 عندما تعلنان عن أرباحهما يوم الأربعاء.
قالت بعض تحليلات وسائل الإعلام الأجنبية إن منافسة الذكاء الاصطناعي قد بدأت. من الواضح أن أسباب انهيار أسعار أسهم Nvidia تتضمن حقيقة أن DeepSeek أصبحت رائدة في ابتكارات الذكاء الاصطناعي، والتي تسميها Nvidia "التطورات الرائعة في الذكاء الاصطناعي".
ثانيًا، من الناحية النظرية، يعد التقدم في الذكاء الاصطناعي مفيدًا لشركة Nvidia لأنه يعني المزيد من الطلب على الرقائق. المشكلة هي أن برنامج DeepSeek موجود في الصين، وأن الولايات المتحدة تفرض حصارًا على تكنولوجيا الرقائق على الصين. وهذا يعني أن Nvidia يمكنها فقط بيع شرائح H800 الأضعف إلى DeepSeek بكميات كبيرة، ولكن ليس شرائح H100 التي تكلف كل منها أكثر من 30 ألف دولار. وحتى لو كانت شركة DeepSeek تمتلك فقط شرائح منخفضة الأداء، فقد تمكنت الصين بشكل فعال من توليد نموذج للذكاء الاصطناعي كان أرخص وأكثر كفاءة بنسبة 96%، وانخفض السعر أيضًا بنسبة تزيد على 90%.
في الوقت نفسه، نماذج الذكاء الاصطناعي الخاصة بهم مجانية، في حين أن نماذج الذكاء الاصطناعي مثل ChatGPT باهظة الثمن نسبيًا (أكثر من 200 دولار شهريًا) وأقل كفاءة. ويبدو أن الصين بدأت في الابتكار بمعدل كان يُعتقد في السابق أنه مستحيل. ويعتقد مجتمع التكنولوجيا في الولايات المتحدة أن موقعه المهيمن لا يمكن استبداله. تواجه أسهم شركات التكنولوجيا الكبيرة في الولايات المتحدة الآن حقيقة أن لديها حرية الوصول إلى نماذج أفضل للذكاء الاصطناعي، وأنها تتحسن فقط. لماذا ندفع علاوة مقابل منتج أسوأ؟
قد يكون رد الفعل التالي هو قيام الولايات المتحدة بتقييد برنامج DeepSeek أو تصدير الرقائق إلى الصين (لقد رأينا هذا منذ عدة أشهر)، ولكن من الواضح أن هذا غير ممكن . إذا تمكنت Nvidia من إيجاد طريقة للاستفادة من الطلب الجديد الناتج عن نمو DeepSeek، فسيتم النظر إلى هذا الانخفاض على أنه هدية. وفي نهاية المطاف، سوف تشتد المنافسة في أجهزة وبرمجيات الذكاء الاصطناعي، ولن تكون أي شركة "آمنة"، وسوف تتسارع وتيرة الإبداع.
فما هو سبب فوز DeepSeek؟ وكيف سيتكشف الذكاء الاصطناعي في المستقبل؟
قام جافين بيكر، الشريك الإداري لشركة الاستثمار الأمريكية Atreides، بتحليل DeepSeek واتجاهات التطور المستقبلية للذكاء الاصطناعي من أبعاد متعددة. أشاد " ماسك " بهذا باعتباره أفضل تحليل رآه على الإطلاق.
قال جافين بيكر إن الشيء الأكثر أهمية هو أن DeepSeek R1 أرخص بكثير من Open ai o1 وكفاءة الاستدلال أعلى أيضًا ليس من 600 مأخوذة من 10000 دولار من بيانات التدريب. تكلفة R1 أقل بنسبة 93% لكل استخدام لواجهة برمجة التطبيقات مقارنة بـ o1، ويتم تشغيلها محليًا على محطة عمل متطورة، ولا يبدو أنها تصل إلى أي حدود مجنونة للمعدلات. تُظهر الرياضيات البسيطة أنه في FP8، يتطلب كل 1b من المعلمات النشطة 1 جيجابايت من ذاكرة الوصول العشوائي، لذا يتطلب R1 37 جيجابايت من ذاكرة الوصول العشوائي. يمكن أن تؤدي المعالجة المجمعة إلى تقليل التكاليف بشكل كبير، ويمكن أن تؤدي المزيد من العمليات الحسابية إلى زيادة عدد الرموز المميزة في الثانية، لذلك لا يزال إجراء الاستدلال في السحابة يتمتع بمزايا. لاحظ أيضًا أن هناك بالفعل ديناميكيات جيوسياسية مؤثرة هنا، والتي لا أعتقد أنها محض صدفة لأن هذا يأتي بعد Stargate. 500 مليار دولار - بالكاد نعرفك.
DeepSeek هو/كان التنزيل رقم واحد في الفئة ذات الصلة على متجر التطبيقات. من الواضح أنه يتقدم على ChatGPT؛ وهو أمر لا يستطيع الجوزاء ولا كلود القيام به. 2) من منظور الجودة، يمكن مقارنته بـ o1، على الرغم من أنه يتخلف عن o3. 3) تم بالفعل تحقيق تقدم كبير في الخوارزمية، مما يجعل التدريب والاستدلال أكثر كفاءة. يعد تدريب FP8 وMLA والتنبؤ متعدد العلامات أمرًا مهمًا للغاية. 4) من السهل التحقق من أن تكلفة التدريب على r1 تبلغ 6 ملايين دولار فقط. ورغم أن هذا صحيح، إلا أنه مضلل للغاية. 5) حتى بنية أجهزتهم جديدة، أود أن أشير إلى أنهم يستخدمون PCI-Express للتوسع.
اختلافات دقيقة: 1) وفقًا للورقة الفنية، فإن مبلغ الـ 6 ملايين دولار لا يشمل "التكاليف المرتبطة بالأبحاث السابقة وتجارب الاستئصال في الهندسة المعمارية والخوارزميات والبيانات". ". وهذا يعني أنه إذا أنفق المختبر مئات الملايين من الدولارات على الأبحاث الأولية وكان لديه إمكانية الوصول إلى مجموعات أكبر، فمن الممكن تدريب نموذج بجودة R1 بتكلفة تشغيلية تبلغ 6 ملايين دولار. يبدو أن شركة Deepseek لديها أكثر من 2048 طائرة من طراز H800؛ وقد ذكرت إحدى أوراقها السابقة مجموعة مكونة من 10000 طائرة من طراز A100. سيكون من المستحيل على فريق ذكي بنفس الدرجة أن ينفق 6 ملايين دولار فقط لبناء مجموعة تضم 2000 وحدة معالجة رسومات وتدريب r1 من الصفر. حوالي 20% من إيرادات Nvidia تأتي من سنغافورة. على الرغم من الجهود الحثيثة التي تبذلها شركة Nvidia، فإن 20% من وحدات معالجة الرسومات الخاصة بالشركة قد لا تكون موجودة في سنغافورة. 2) لقد قاموا بالكثير من أعمال التحسين - أي أنه من غير المحتمل أن يتمكنوا من تدريب هذا النموذج دون الوصول غير المقيد إلى GPT-4o وO1. وكما أشار لي @altcap بالأمس، فإنه من المضحك بعض الشيء تقييد الوصول إلى وحدات معالجة الرسوميات الرائدة دون القيام بأي شيء لمواجهة قدرة الصين على تحسين النماذج الأمريكية الرائدة - فمن الواضح أنه يتعارض مع الغرض من قيود التصدير. لماذا تشتري بقرة عندما يمكنك الحصول على الحليب مجانا؟
الخلاصة: 1) سيؤدي تقليل تكاليف التدريب إلى زيادة العائد على الاستثمار في الذكاء الاصطناعي. 2) على المدى القصير، ليس لهذا أي آثار إيجابية على النفقات الرأسمالية للتدريب أو موضوع "القوة". 3) بالنسبة للفائزين الحاليين بـ "البنية التحتية للذكاء الاصطناعي" في مجال التكنولوجيا والصناعة والمرافق والطاقة، فإن الخطر الأكبر هو أن الإصدار المبسط من r1 يمكن تشغيله محليًا على حافة محطة عمل متطورة (ذكر أحدهم Mac Studio برو). وهذا يعني أنه سيتم تشغيل نماذج مماثلة على الهواتف الفائقة في غضون عامين تقريبًا. إذا تحول المنطق إلى الهوامش لأنه "جيد بما فيه الكفاية"، فإننا نعيش في عالم مختلف تمامًا مع فائزين مختلفين تمامًا - أي أكبر دورة ترقية لأجهزة الكمبيوتر والهواتف الذكية التي شهدناها على الإطلاق. لقد تأرجحت الحوسبة بين المركزية واللامركزية لفترة طويلة. 4) الذكاء الفائق قريب جدًا، ولا أحد يعرف حقًا ما هي العائدات الاقتصادية للذكاء الفائق. إذا كان نموذج الاستدلال الذي تبلغ قيمته 100 مليار دولار والذي تم تدريبه على أكثر من 100000 بلاكويل (o5، Gemini 3، Grok 4) يمكنه علاج السرطان واختراع محرك الالتواء، فإن العائد على ASI سيكون مرتفعًا للغاية، وستكون نفقات تكاليف التدريب واستهلاك الطاقة ثابتة النمو. ستصبح كرات دايسون (التي يشار إليها عمومًا بالهياكل الصلبة التي تشكل قشرة مستمرة حول النجم) مرة أخرى أفضل تفسير لمفارقة فيرمي. آمل أن تكون عوائد ASI مرتفعة - سيكون ذلك رائعًا. 5) يعد هذا أمرًا جيدًا حقًا للشركات التي تستخدم الذكاء الاصطناعي: البرمجيات، والإنترنت، وما إلى ذلك. 6) من منظور اقتصادي، يؤدي هذا إلى زيادة كبيرة في قيمة التوزيع والبيانات الفريدة - YouTube وFacebook وInstagram وX. 7) قد تتوقف المعامل الأمريكية عن إطلاق نماذجها الرائدة لمنع عملية التحسين الأساسية في R1، على الرغم من أنها قد تكون مكشوفة بالكامل بالفعل في هذا الصدد. على سبيل المثال، قد يكون r1 كافيًا لتدريب r2 وما إلى ذلك.
Grok-3 على وشك الظهور، مما قد يكون له تأثير كبير على الاستنتاجات المذكورة أعلاه. يمكن القول إن هذا هو أول اختبار رئيسي لقانون قياس ما قبل التدريب منذ GPT-4. مثلما استغرق الأمر أسابيع لتحويل v3 إلى r1 من خلال التعلم المعزز، فإن التعلم المعزز المطلوب لتحسين قدرات الاستدلال في Grok-3 قد يستغرق أيضًا أسابيع. كلما كان النموذج الأساسي أفضل، كلما كان نموذج الاستدلال أفضل لأن قوانين القياس الثلاثة مضاعفة - التدريب المسبق، والتعلم المعزز أثناء ما بعد التدريب، وحساب وقت الاختبار أثناء الاستدلال (وظيفة التعلم المعزز). لقد أثبت Grok-3 بالفعل أنه قادر على إنجاز مهام تتجاوز o1 - انظر عرض Tesseract - إلى أي مدى سيكون أبعد من ذلك مهمًا للغاية. لإعادة صياغة عبارة أوركي لم يذكر اسمه في البرجين، قد لا يمر وقت طويل قبل أن نتمكن من تناول اللحوم مرة أخرى. الوقت سيخبرنا بكل شيء، "الحقائق تتحدث بصوت أعلى من الكلمات، وسوف أغير رأيي".
ومع ذلك، يعتقد محلل الاستثمار في الأسهم الأمريكية شو لاوماو أن عمليات البيع المكثفة سببه DeepSeek يوم الاثنين إنه رد فعل مبالغ فيه. يظل سرد نمو الذكاء الاصطناعي على المدى الطويل سليما ويمكن القول إنه أقوى الآن من أي وقت مضى. هناك مفارقة جيفونز في الاقتصاد، والتي تنص على أن التحسينات في كفاءة استخدام الموارد تميل إلى زيادة (بدلاً من تقليل) الاستهلاك الإجمالي لذلك المورد، لأن الكفاءة الأعلى ستؤدي إلى تقليل تكلفة استخدام المورد، مما يؤدي إلى زيادة في الطلب على الموارد.
وهذا ما حدث مع استخدام الفحم في المحركات البخارية. أدت التحسينات في كفاءة المحرك البخاري إلى تقليل استهلاك الفحم لكل وحدة إنتاج. ومع ذلك، فإنه يجعل التكنولوجيا التي تعمل بالفحم أكثر جاذبية من الناحية الاقتصادية، مما يؤدي إلى اعتمادها على نطاق أوسع وزيادة الاستهلاك الإجمالي للفحم في نهاية المطاف. حدث هذا على شبكة الإنترنت، حيث أصبحت أجهزة الكمبيوتر أصغر وأرخص، وكان الوصول إلى الإنترنت مجانيًا في الأساس، وكان لدى الجميع جهاز كمبيوتر، وكان بإمكان الجميع الوصول إلى الإنترنت على مدار الساعة.
وينطبق الشيء نفسه على الذكاء الاصطناعي الآن. مع انخفاض تكلفة التدريب والاستدلال على نماذج الذكاء الاصطناعي بشكل كبير، سيقوم المزيد والمزيد من الشركات والأفراد ببناء نماذج الذكاء الاصطناعي الخاصة بهم، وأصبح الذكاء الاصطناعي شائعًا في جميع أنحاء العالم وتغلغل في جميع جوانب المجتمع.
يكشف تحقيق Rekt Builder عن تتبع نشاط المستخدم السري لـ Ledger Live، مما يثير مخاوف خطيرة تتعلق بالخصوصية لمستخدمي محفظة أجهزة Ledger.
Kikyoتشكل الولايات المتحدة سياسة العملات المشفرة الأمريكية، وتقود اتجاهات التنظيم الوطنية.
 Brian
Brianيعمل موقع GetGrass.io على تمكين المستخدمين من تحقيق الدخل من النطاق الترددي الخامل، ويعد بإعادة توزيع الإيرادات بالكامل وإعطاء الأولوية للخصوصية.
 Alex
Alexتقترح PancakeSwap خفض إمدادات CAKE من 750 مليونًا إلى 450 مليونًا، مما يمثل محورًا استراتيجيًا نحو اقتصاد رمزي مستقر.
Kikyoأصدر المؤسس المشارك لـ Solana، أناتولي ياكوفينكو، مؤخرًا كشفًا جديرًا بالملاحظة، واصفًا البروتوكول بأنه "Ethereum L2 with Wormhole Eigenlayer". يعد هذا البيان المبهم، على الرغم من طبيعته التقنية، بمثابة محاولة لتخفيف التنافس الشديد بين Solana ونظيره الأكبر Ethereum (ETH).
 Joy
Joyيبدأ معرض ZK عمليات استرداد الأموال من USDC، مما يمثل لحظة مهمة في رحلة الطبقة الثانية لـ Ethereum ويظهر مشاركة المجتمع القوية.
Brianتبرز Celestia Ecosystem كلاعب رئيسي في ابتكار تقنية blockchain، حيث تقدم تطبيقات متنوعة وعمليات إسقاط جوي محتملة
Alexتعلق شركة Bitzlato عمليات سحب البيتكوين وسط تحديات قانونية بعد اعتراف مؤسسها المشارك بالذنب ومصادرة الأصول.
Kikyoتقدم براءة الاختراع، التي تم تقديمها في نوفمبر 2019، نظامًا يستخدم تقنية blockchain لإدارة فعالة لمركبات الطرق.
Brianيشهد المستثمرون تحولًا حيث تتفوق أسهم تعدين Bitcoin، بقيادة Marathon Digital وRiot Platforms، على نمو Bitcoin، محققة مكاسب تزيد عن 800٪. وسط هذه الطفرة، تؤكد التحركات الإستراتيجية وتوقعات السوق على المسار الواعد للأسهم المرتبطة بالعملات المشفرة وسط تحديات القطاع.
Joy