المصدر: Quantum Bit
في اليوم الثالث من أسبوع المصدر المفتوح، كشفت DeepSeek عن "القوة" وراء استدلال التدريب V3/R1 -
DeepGEMM: مكتبة FP8 GEMM (ضرب المصفوفة العامة) التي تدعم عمليات ضرب المصفوفة الكثيفة والمختلطة للخبراء (MoE).
دعونا نلقي أولاً نظرة موجزة على GEMM. GEMM، أو عملية الضرب العام للمصفوفات، هي عملية أساسية في الجبر الخطي. وهي عملية "عادية" في الحوسبة العلمية والتعلم الآلي والتعلم العميق وغيرها من المجالات، كما أنها تشكل جوهر العديد من مهام الحوسبة عالية الأداء. ومع ذلك، نظرًا لأن تعقيدها الحسابي غالبًا ما يكون كبيرًا نسبيًا، فإن تحسين أداء GEMM أمر بالغ الأهمية. لا يزال DeepGEMM مفتوح المصدر من DeepSeek يحتفظ بخصائص "الأداء العالي + التكلفة المنخفضة"، مع النقاط البارزة التالية:
الأداء العالي: على وحدة معالجة الرسوميات ذات بنية Hopper، يمكن لـ DeepGEMM تحقيق أداء يصل إلى 1350+FP8 TFLOPS.
البساطة: يتكون المنطق الأساسي من حوالي 300 سطر من التعليمات البرمجية فقط، ولكن الأداء أفضل من النوى المضبوطة بواسطة خبراء.
التجميع في الوقت المناسب (JIT): يستخدم التجميع الكامل في الوقت المناسب، مما يعني أنه يمكنه إنشاء كود مُحسَّن بشكل ديناميكي في وقت التشغيل للتكيف مع أحجام الأجهزة والمصفوفات المختلفة.
لا توجد تبعيات ثقيلة: تم تصميم هذه المكتبة لتكون خفيفة الوزن للغاية ولا تحتوي على تبعيات معقدة، مما يجعل من السهل نشرها واستخدامها.
يدعم تخطيطات مصفوفة متعددة: يدعم تخطيط المصفوفة الكثيفة وتخطيطين لـ MoE، مما يجعله قابلاً للتكيف مع سيناريوهات التطبيق المختلفة، بما في ذلك على سبيل المثال لا الحصر نماذج الخبراء الهجينة في التعلم العميق.
ببساطة، يتم استخدام DeepGEMM بشكل أساسي لتسريع عمليات المصفوفة في التعلم العميق، وخاصة في تدريب النماذج واسعة النطاق والاستدلال عليها. وهو مناسب بشكل خاص للسيناريوهات التي تتطلب موارد حوسبة فعالة ويمكن أن يحسن كفاءة الحوسبة بشكل كبير.
يبدي العديد من مستخدمي الإنترنت "تقبلاً" كبيرًا لهذا الإصدار مفتوح المصدر. ويقارن بعض الأشخاص بين DeepGEMM والبطل الخارق في الرياضيات، معتقدين أنه أسرع من الآلة الحاسبة السريعة وأقوى من المعادلات متعددة الحدود.
كما شبه بعض الأشخاص إصدار DeepGEMM باستقرار الحالة الكمومية في واقع جديد، وأشادوا بتجميعه النظيف والأنيق في الوقت المناسب.
بالطبع... بدأ بعض الأشخاص يشعرون بالقلق بشأن أسهم Nvidia الخاصة بهم...
تعرف على المزيد حول DeepGEMM
DeepGEMM هي مكتبة مصممة خصيصًا لتنفيذ عمليات الضرب العام للمصفوفات FP8 (GEMMs) الموجزة والفعّالة. كما تتمتع بقدرات توسع دقيقة. هذا التصميم مشتق من DeepSeek V3.
يمكنه التعامل مع كل من عملية ضرب المصفوفة العامة العادية وضرب المصفوفة العامة المجمعة MoE. تمت كتابة هذه المكتبة بلغة CUDA ولا تحتاج إلى التجميع أثناء التثبيت لأنها ستقوم بتجميع جميع برامج kernel من خلال وحدة تجميع في الوقت المناسب (JIT) خفيفة الوزن في وقت التشغيل.
حاليًا، يدعم DeepGEMM فقط Hopper Tensor Core من NVIDIA.
من أجل حل مشكلة عدم دقة أنوية موتر FP8 بدرجة كافية عند حساب التراكم، فإنها تعتمد طريقة التراكم (الترقية) ذات المستويين لأنوية CUDA. على الرغم من أن DeepGEMM يستعير بعض الأفكار من CUTLASS وCuTe، إلا أنه لا يعتمد كثيرًا على قوالبهما أو عملياتهما الجبرية. على العكس من ذلك، تم تصميم هذه المكتبة لتكون بسيطة للغاية، مع وظيفة أساسية واحدة فقط وحوالي 300 سطر من التعليمات البرمجية.
وهذا يجعله موردًا موجزًا وسهل الفهم لتعلم تقنيات ضرب المصفوفات وتحسينها في FP8 تحت بنية Hopper.
على الرغم من تصميمه خفيف الوزن، فإن أداء DeepGEMM يمكن أن يضاهي أو يتجاوز أداء المكتبات التي تم ضبطها بواسطة خبراء لمجموعة متنوعة من أشكال المصفوفة.
فما هي العروض المحددة؟ قام الفريق باختبار جميع الأشكال التي يمكن استخدامها في الاستدلال على DeepSeek-V3/R1 (بما في ذلك التعبئة المسبقة وفك التشفير، ولكن بدون التوازي الموتر) باستخدام NVCC 12.8 على H800.
يوضح الشكل أدناه أداء DeepGEMM العادي للنماذج الكثيفة:
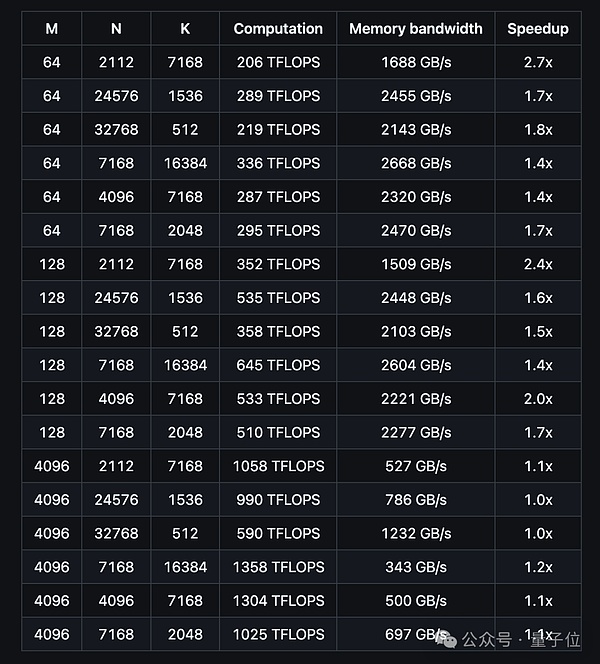
وفقًا لنتائج الاختبار، يمكن أن يصل أداء الحوسبة لـ DeepGEMM إلى ما يصل إلى 1358 TFLOPS، ويمكن أن يصل عرض النطاق الترددي للذاكرة إلى ما يصل إلى 2668 جيجابايت/ثانية. يمكن أن تصل نسبة التسريع إلى 2.7 مرة مقارنة بالتنفيذ المحسن المستند إلى CUTLASS 3.6.
دعونا نلقي نظرة على أداء DeepGEMM الذي يدعم التخطيط المتجاور لنموذج MoE:
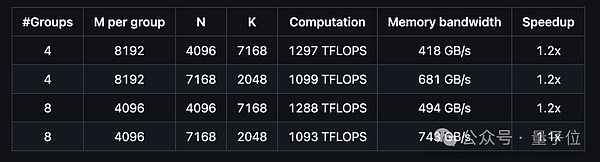
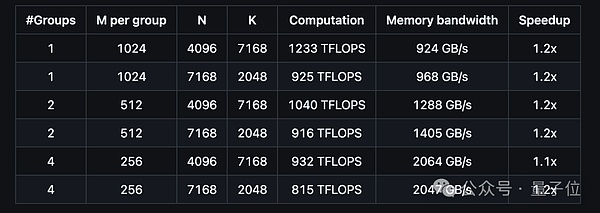
ويكون أداء دعم التخطيط المقنع لنموذج MoE كما يلي:
كيف تستخدمه؟
لاستخدام DeepGEMM، تحتاج إلى الانتباه إلى العديد من التبعيات، بما في ذلك:
يكون كود التطوير على النحو التالي:
# يجب استنساخ الوحدة الفرعيةgit [email protected]:deepseek-ai/DeepGEMM.git# إنشاء روابط رمزية لأطراف ثالثة (CUTLASS وCuTe) تتضمن أدلة pyt hon setup.py develop # اختبار تجميع JIT python tests/test_jit.py # اختبار جميع أدوات GEMM (العادية والمتجاورة والمجمعة المقنعة) python tests/test_core.py يكون كود التثبيت على النحو التالي:
python setup.py install
بعد الخطوات المذكورة أعلاه، قم باستيراد deep_gemm في مشروع Python الخاص بك.
من حيث الواجهة، بالنسبة لـ DeepGEMM العادي، يمكن استدعاء الدالة deep_gemm.gemm_fp8_fp8_bf16_nt لدعم تنسيق NT (الجانب الأيسر غير المنقول والجانب الأيمن المنقول). بالنسبة لـ DeepGEMM المجمعة، فإن التخطيط المستمر هو m_grouped_gemm_fp8_fp8_bf16_nt_contiguous؛ والتخطيط المقنع هو m_grouped_gemm_fp8_fp8_bf16_nt_masked. يوفر DeepGEMM أيضًا وظائف أداة مثل تعيين الحد الأقصى لعدد SMs والحصول على حجم محاذاة TMA؛ وهو يدعم متغيرات البيئة مثل DG_NVCC_COMPILER وDG_JIT_DEBUG. بالإضافة إلى ذلك، يوفر فريق DeepSeek أيضًا العديد من طرق التحسين، بما في ذلك:
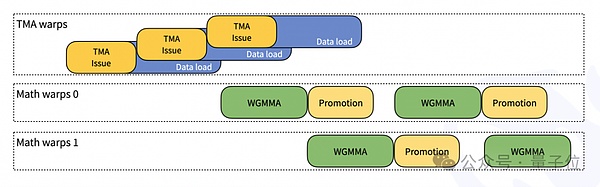
تصميم JIT: يتم تجميع جميع النوى في وقت التشغيل، دون الحاجة إلى التجميع أثناء التثبيت؛ يدعم الاختيار الديناميكي لحجم الكتلة الأمثل ومرحلة خط الأنابيب.
التدرج الدقيق: حل مشكلة دقة FP8 من خلال تراكم طبقتين من أنوية CUDA؛ دعم أحجام الكتل غير ذات القوة 2 لتحسين استخدام SM.
تداخل FFMA SASS: تحسين الأداء عن طريق تعديل بتات العائد وإعادة الاستخدام لتعليمات SASS.
يمكن للأصدقاء المهتمين النقر فوق رابط GitHub في نهاية المقالة لعرض التفاصيل~
شيء آخر
سهم Nvidia هذه الأيام... حسنًا... كان ينخفض مرة أخرى:
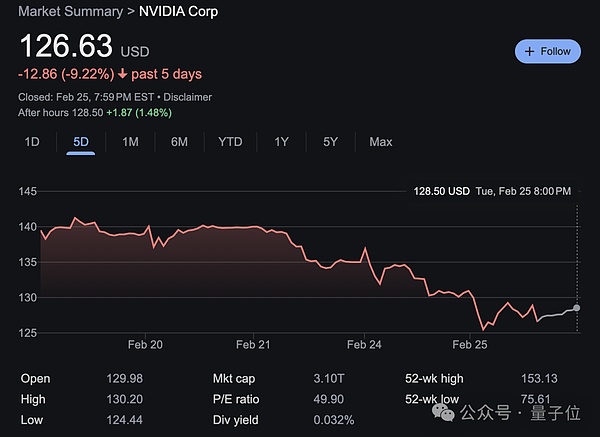
ومع ذلك، في الصباح الباكر من اليوم السابع والعشرين بتوقيت بكين، من المقرر إصدار تقرير أداء Nvidia للربع الرابع للسنة المالية 2025، ويمكننا أن نتطلع إلى أدائها~


 Weiliang
Weiliang


