تخطط لجنة الخدمات المالية الكورية للقضاء على غسيل أموال الأصول الافتراضية
ومن المفترض أن تقدم لجنة الخدمات المالية دعمًا للسياسات، وتشجع على إجراء تقييمات دورية لقدرات الشركات لتعزيز إجراءات مكافحة غسيل الأموال.
 Brian
Brian

مترجم: Heart of the Metaverse
في الآونة الأخيرة، أثار صعود DeepSeek نقاشًا واسع النطاق بين المستثمرين المغامرين ورجال الأعمال في وادي السيليكون. باعتبارها قوة ناشئة في مجال الذكاء الاصطناعي، فإن التطور السريع لشركة DeepSeek دفع الناس إلى إعادة التفكير في مستقبل ابتكار الذكاء الاصطناعي، وهيمنة نموذج المصدر المفتوح، واستدامة نماذج الأعمال التقليدية للذكاء الاصطناعي.
جوهر هذه المناقشة هو: هل يمثل DeepSeek تحولاً نموذجياً أم مجرد صدمة قصيرة الأمد؟ كيف ينبغي لشركات الذكاء الاصطناعي الحالية الاستجابة لهذا التغيير؟ 01. ابتكارات DeepSeek ومزاياها
يتعلم نموذج R1-Zero بالكامل من خلال نظام مكافآت آلي، كما أنه قادر على تسجيل نقاط ذاتية في مهام الرياضيات والبرمجة والمنطق. تعمل هذه العملية على تمكين قدرات التفكير التسلسلي التلقائي، مما يتيح للنموذج تمديد وقت التفكير، وإعادة تقييم الافتراضات، وتعديل الاستراتيجيات بشكل ديناميكي.
على الرغم من أن الناتج الأولي كان عبارة عن مزيج من لغات متعددة، فقد نجحت DeepSeek في تطوير نموذج DeepSeek R1 من خلال إدخال كمية صغيرة من البيانات عالية الجودة التي علق عليها الإنسان في عملية التعلم التعزيزي.
بالإضافة إلى ذلك، يعتمد DeepSeek أيضًا تصميم "مزيج من الخبراء" (MoE). تسمح تقنية MoE للنموذج باختيار شبكات فرعية متخصصة (أي "الخبراء") بشكل ديناميكي لمعالجة أجزاء مختلفة من المدخلات، مما يحسن الكفاءة بشكل كبير.
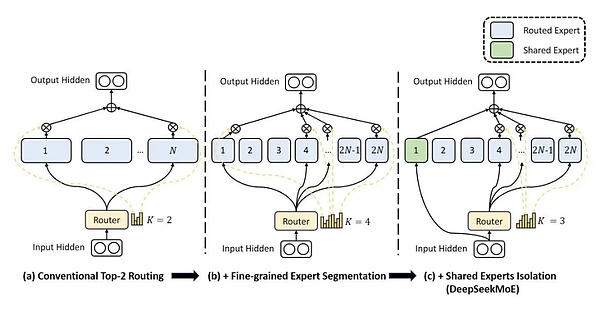
على عكس النموذج الشامل التقليدي، يحتاج MoE فقط إلى تنشيط جزء من شبكة الخبراء، وبالتالي تقليل التكلفة الحسابية مع الحفاظ على الأداء العالي. يتيح هذا النهج لـ DeepSeek التوسع بكفاءة، مما يوفر دقة أفضل مع انخفاض الطاقة والزمن الكامن.
يركز DeepSeek على التعلم التعزيزي والتعلم الآلي وتحسين ما بعد التدريب، مما يوضح مستقبل البنية التحتية للحوسبة الذكية مع الذاكرة المحسنة والشبكة والحوسبة التي أصبحت أدق وأسرع وأذكى. 02. تحدي نموذج الملكية التقليدي يتوقع أشو جارج، الشريك العام لشركة Foundation Capital، أن الحجم لم يعد الصيغة الفائزة الوحيدة في مجال الذكاء الاصطناعي. وأشار إلى أن شركة DeepSeek تنظر إلى الذكاء الاصطناعي باعتباره تحديًا للنظام وقامت بإجراء تحسينات شاملة من هندسة النموذج إلى استخدام الأجهزة. وأكد أيضًا أن الموجة التالية من ابتكارات الذكاء الاصطناعي ستقودها الشركات الناشئة التي تستخدم نماذج كبيرة لتصميم "أنظمة عملاء" معقدة يمكنها التعامل مع المهام المعقدة بدلاً من مجرد أتمتة العمليات البسيطة.
في غياب وحدة معالجة الرسوميات H100 الرائدة من Nvidia، قامت DeepSeek بتعزيز الاتصال بين الشرائح من خلال إعادة برمجة وحدات المعالجة العشرين على وحدة معالجة الرسوميات H800 واستخدمت تقنية التكميم FP8 لتقليل النفقات العامة للذاكرة. بالإضافة إلى ذلك، قاموا بتقديم تقنية التنبؤ متعددة الرموز، والتي تمكن النموذج من إنشاء كلمات متعددة في وقت واحد بدلاً من إنشائها كلمة بكلمة.
ولكن ليس هذا فحسب، بل إن نجاح DeepSeek في مجال الذكاء الاصطناعي مفتوح المصدر قد تحدى نموذج الملكية التقليدي. ويشير التبني الواسع النطاق لإطار عملها إلى أن تطوير الذكاء الاصطناعي يتحول في اتجاه أكثر توجهاً نحو المجتمع.
كما يكسر DeepSeek التصور الكامن بأن الاختراقات واسعة النطاق في مجال الذكاء الاصطناعي تتطلب استثمارات ضخمة في البنية التحتية. ومن خلال إثبات إمكانية تدريب النماذج المتطورة بكفاءة، فقد أجبر قادة الصناعة على إعادة التفكير فيما إذا كانت مجموعات وحدات معالجة الرسوميات التي تبلغ قيمتها عدة مليارات من الدولارات ضرورية حقًا.
مع تزايد كفاءة نماذج الذكاء الاصطناعي، يتزايد الاستخدام الإجمالي.
لقد أدت فعالية DeepSeek من حيث التكلفة إلى خفض حاجز الدخول، مما أدى إلى ظهور فئة جديدة من الشركات الناشئة ذات هياكل الذكاء الاصطناعي المبسطة. ويشير هذا الاتجاه إلى تحول أوسع في النظام البيئي للذكاء الاصطناعي، حيث أصبحت الكفاءة عاملاً أساسياً في التمييز، وليس مجرد قوة الحوسبة الخام. في الواقع، لم ينشئ DeepSeek مجالًا جديدًا، بل قام بتحسين وتحسين تقنية الذكاء الاصطناعي الموجودة، مما يدل على قوة التكرار. وهذا يثير السؤال التالي: هل ميزة المبادرة الأولى في تطوير الذكاء الاصطناعي مستدامة حقا؟ ولعل التحسين المستمر هو المكان الذي تكمن فيه القيادة الحقيقية.
مع التقدم في السرعة وقدرات الاستدلال والفعالية من حيث التكلفة، تمهد DeepSeek الطريق لعصر جديد من التطبيقات المعتمدة على الذكاء الاصطناعي.
إن الصناعة على وشك موجة من وكلاء الذكاء الاصطناعي القادرين على التعامل مع سير العمل المعقدة التي من شأنها إحداث ثورة في الصناعات من خلال زيادة الكفاءة وخفض التكاليف وتمكين حالات استخدام جديدة كانت مستحيلة في السابق. وبشكل عام، فإن صعود DeepSeek هو علامة على أن حلول الذكاء الاصطناعي تتجه نحو أن تصبح أكثر سهولة في الوصول إليها وفعالية من حيث التكلفة.
مع تكيف الصناعة، يتعين على الشركات إيجاد توازن بين الابتكار الخاص والتعاون المفتوح لضمان أن تظل الموجة التالية من تطوير الذكاء الاصطناعي فعالة وقابلة للتكيف وقابلة للتطوير. مع استمرار تقدم تكنولوجيا الذكاء الاصطناعي، فإن التفاعل بين شركات الذكاء الاصطناعي الرائدة واللاعبين الناشئين سيحدد المرحلة التالية من التقدم التكنولوجي.
ومن المفترض أن تقدم لجنة الخدمات المالية دعمًا للسياسات، وتشجع على إجراء تقييمات دورية لقدرات الشركات لتعزيز إجراءات مكافحة غسيل الأموال.
Brianيجلب دخول OKX إلى البرازيل أحدث الخدمات وابتكارات Web3، مما يشكل مستقبل تداول العملات المشفرة في المنطقة.
 Hui Xin
Hui Xinتم إطلاق Wind.app منذ عام 2022، وقد سهّل حجم المعاملات الإجمالي السنوي (GTV) الذي تجاوز 3 ملايين دولار.
Brianيحذر فيتاليك بوتيرين من التهديد الوجودي الناجم عن تطور الذكاء الاصطناعي غير المنضبط، ويدعو إلى التدخل ويقترح واجهات الدماغ والحاسوب كحل.
Hui Xinيتوقع رئيس البنك المركزي في سنغافورة تراجع العملات المشفرة الخاصة لعدم موثوقيتها. وهو يتصور مستقبلًا مع العملات المعدنية المنظمة والعملات الرقمية للبنك المركزي، وهو ما ردده راو من بنك الاحتياطي الهندي. يشير مجلس الاستقرار المالي إلى المخاطر التي تشكلها شركات العملات الرقمية المعقدة، مشددًا على الحاجة إلى لوائح تنظيمية قوية. إن التحول نحو العملات الرقمية المنظمة واضح، لكن الرقابة القوية تظل حاسمة.
 Joy
Joyمن المقرر أن تُحدث Titan Contents، التي أسسها الرئيس التنفيذي السابق لشركة SM Entertainment نيكي سيمين هان، ثورة في مشهد موسيقى البوب الكورية العالمي. من خلال ربط المواهب بين الشرق والغرب والاستفادة من Web3 و Metaverse و AI، تهدف الشركة إلى إعادة تعريف نماذج K-pop التقليدية. مع فريق من الخبراء، تستعد Titan Contents لتشكيل مستقبل هذا النوع، بهدف تحقيق النجاح الدولي في المشهد الديناميكي لموسيقى البوب الكورية.
Joyوكشفت Meta عن مزيد من التفاصيل فيما يتعلق بموقفها من الإعلانات السياسية، وتطالب الآن المعلنين بالكشف عن متى يستخدمون الذكاء الاصطناعي لمعالجة الصور أو مقاطع الفيديو في بعض الإعلانات السياسية.
Joyعند البحث عن المغني الشهير "إسرائيل كاماكاويوول" على Google، فإن ما يظهر ليس غلاف ألبوم مميز أو صورة أداء حي، بل تصوير تم إنشاؤه بواسطة الذكاء الاصطناعي. إنها صورة مثيرة للاهتمام، وإن كانت مزيفة، للفنان، حيث تعيد توجيه المستخدمين إلى موقع Midjourney الفرعي عند النقر.
Joyيواجه كريستيانو رونالدو دعوى قضائية جماعية محتملة بعد مزاعم بأن تأييده لـ Binance، وهي بورصة رائدة للعملات المشفرة، أدى إلى خسائر كبيرة للمستثمرين. تم رفع الدعوى أمام محكمة مقاطعة فلوريدا في 27 نوفمبر 2023، من قبل المدعين مايكل سيزيمور، وميكي فونجدارا، وجوردون لويس، وتزعم الدعوى أن ارتباط رونالدو ببينانس أدى إلى خسائر مالية للمستثمرين.
Joyبدأت هيئة الأوراق المالية والبورصات الفلبينية (SEC) خطوات لتقييد الوصول إلى منصة Binance، وهي أكبر بورصة للعملات المشفرة في العالم. وتأتي هذه الخطوة في أعقاب استقالة رئيس Binance السابق واعترافه بالذنب لانتهاك قوانين مكافحة غسيل الأموال الأمريكية.
Joy