
مايكروسوفت تعزز دعمها لنماذج OpenAI GPT-4-5 وGPT-5
وتشير التقارير إلى أن شركة مايكروسوفت تخطط لاستضافة أحدث طراز من OpenAI في وقت مبكر من الأسبوع المقبل.
 JinseFinance
JinseFinance

المصدر: قلب الآلة
قسم التحرير في قلب الآلة< / strong>
الذكاء الاصطناعي للأغراض العامة، الذكاء الاصطناعي الذي يمكن استخدامه في الحياة اليومية، إذا لم يتم صنعه على هذا النحو، فسوف أشعر بالحرج من إطلاق مؤتمر الآن.
في الصباح الباكر من يوم 15 مايو، تم افتتاح مؤتمر مطوري Google I/O السنوي "حفل مهرجان ربيع التكنولوجيا" رسميًا. كم مرة ذكرت الكلمة الرئيسية التي تبلغ مدتها 110 دقيقة الذكاء الاصطناعي؟ قامت Google بإجراء إحصائيات خاصة بها:

نعم، يتم الحديث عن الذكاء الاصطناعي في كل دقيقة.
وصلت المنافسة في مجال الذكاء الاصطناعي التوليدي إلى ذروة جديدة مؤخرًا، ومن الطبيعي أن يدور محتوى مؤتمر I/O هذا حول الذكاء الاصطناعي.
"قبل عام واحد، وعلى هذه المرحلة، شاركنا لأول مرة خططًا لـ Gemini، وهو نموذج أصلي كبير متعدد الوسائط، كان يمثل جيلًا جديدًا من عمليات الإدخال/الإخراج"، هذا ما قاله الرئيس التنفيذي لشركة Google، ساندر بيتشاي يي (سوندار بيتشاي). "اليوم، نأمل أن يتمكن الجميع من الاستفادة من تقنية Gemini. ستدخل هذه الميزات الرائعة إلى البحث والصور وأدوات الإنتاجية وأنظمة Android والمزيد."
قبل 24 ساعة، أخذت OpenAI زمام المبادرة عمدًا عند إصدار GPT-4o ، مما يصدم العالم من خلال التفاعل الصوتي والفيديو والنص في الوقت الفعلي. اليوم، عرضت Google مشروعي Astra وVeo، اللذين يقارنان بشكل مباشر OpenAI الحالي الرائد GPT-4o وSora.
هذه لقطة حية لنموذج أولي لمشروع أسترا:
إننا نشهد حروب الأعمال الأكثر تطورًا، والتي يتم إجراؤها بأكثر الطرق تواضعًا.
في مؤتمر I/O، أظهرت Google إمكانات البحث التي يدعمها أحدث إصدار من Gemini.
قبل خمسة وعشرين عامًا، قامت Google بتشغيل الموجة الأولى من عصر المعلومات من خلال محرك البحث الخاص بها. الآن، يمكن لمحركات البحث الإجابة على أسئلتك بشكل أفضل مع تطور تكنولوجيا الذكاء الاصطناعي التوليدي، مع الاستفادة بشكل أفضل من المحتوى السياقي، والوعي بالموقع، وقدرات المعلومات في الوقت الفعلي.
استنادًا إلى أحدث إصدار من نموذج جيميني القابل للتخصيص، يمكنك أن تطلب من محرك البحث أي شيء تفكر فيه، أو أي شيء يجب القيام به - من البحث إلى التخطيط إلى الخيال، وسيتولى Google الاهتمام بذلك كل شيء.
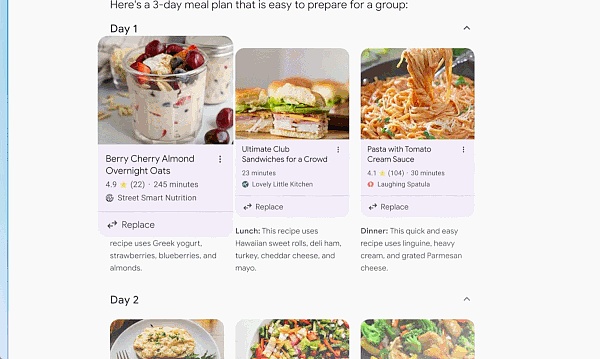
في بعض الأحيان تريد الإجابات بسرعة ولكن ليس لديك الوقت لتجميع كل المعلومات المعلومات معا معا. في هذا الوقت، سيقوم محرك البحث بالعمل نيابةً عنك من خلال نظرة عامة على الذكاء الاصطناعي. من خلال الذكاء الاصطناعي، يمكن للذكاء الاصطناعي زيارة عدد كبير من مواقع الويب تلقائيًا لتقديم إجابة لسؤال معقد.
بفضل إمكانات الاستدلال المنطقي متعددة الخطوات المخصصة لـ Gemini، ستساعد ميزة AI Overview في حل المشكلات المتزايدة التعقيد. لم تعد بحاجة إلى تقسيم أسئلتك إلى عمليات بحث متعددة، يمكنك الآن طرح الأسئلة الأكثر تعقيدًا دفعة واحدة، مع كل الفروق الدقيقة والمحاذير التي فكرت بها.
بالإضافة إلى العثور على الإجابات أو المعلومات الصحيحة للأسئلة المعقدة، يمكن لمحركات البحث العمل معك لإنشاء خطة خطوة بخطوة.
في I/O، سلطت Google الضوء على إمكانيات الوسائط المتعددة والنصوص الطويلة للنماذج الكبيرة. يؤدي التقدم التكنولوجي إلى جعل أدوات الإنتاجية، مثل Google Workspace، أكثر ذكاءً.
على سبيل المثال، يمكننا الآن أن نطلب من Gemini تلخيص جميع رسائل البريد الإلكتروني الأخيرة من المدرسة. سيحدد رسائل البريد الإلكتروني ذات الصلة في الخلفية وحتى يحلل المرفقات مثل ملفات PDF. ستحصل بعد ذلك على ملخص للنقاط الرئيسية وعناصر العمل.

إذا كنت مسافرًا وغير قادر على حضور اجتماع المشروع، وتسجيل الإجتماع ساعة واحدة. إذا تم عقد الاجتماع على Google Meet، يمكنك أن تطلب من برج الجوزاء تعريفك بالنقاط الرئيسية. هناك مجموعة تبحث عن متطوعين وأنت متواجد في ذلك اليوم. يمكن أن يساعدك Gemini في كتابة بريد إلكتروني للتقديم.
علاوة على ذلك، ترى Google المزيد من الفرص في الوكلاء النموذجيين الكبار، معتقدة أنهم قادرون على العمل كأنظمة ذكية تتمتع بقدرات التفكير والتخطيط والذاكرة. يمكن للتطبيقات التي تستخدم Agent "التفكير" في عدة خطوات مقدمًا والعمل عبر البرامج والأنظمة لمساعدتك على إكمال المهام بشكل أكثر سهولة. وقد انعكست هذه الفكرة في منتجات مثل محركات البحث، ويمكن للناس أن يروا بشكل مباشر تحسن قدرات الذكاء الاصطناعي.
على الأقل فيما يتعلق بتطبيقات Family Bucket، تتفوق Google على OpenAI.
يتمتع Google بمزايا فطرية من حيث علم البيئة، ولكن تأسيس النماذج الكبيرة أمر مهم للغاية، وقد قامت Google بدمج قوة فريقها الخاص وشركة DeepMind لهذا الغرض. اليوم، اعتلى هاسابيس المسرح أيضًا لأول مرة في مؤتمر I/O وقدم شخصيًا النموذج الجديد الغامض.

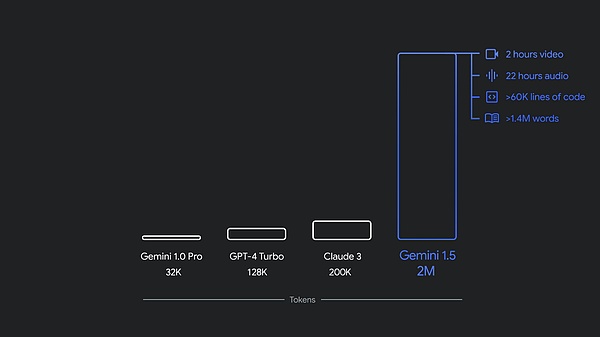
في ديسمبر من العام الماضي، أطلقت Google برنامج Gemini 1.0، وهو أول نظام أصلي متعدد الوسائط. الموديل متوفر بثلاثة أحجام: Ultra و Pro و Nano. وبعد بضعة أشهر فقط، أصدرت Google إصدارًا جديدًا، 1.5 Pro، مع أداء محسّن ونافذة سياقية تجاوزت مليون رمز مميز.
الآن، أعلنت Google عن تقديم سلسلة من التحديثات لسلسلة طرازات Gemini، بما في ذلك Gemini 1.5 Flash الجديد، وهو نموذج Google خفيف الوزن للسرعة والكفاءة، وProject Astra، وهو رؤية Google لمستقبل مساعدي الذكاء الاصطناعي).
في الوقت الحالي، يتوفر كل من 1.5 Pro و1.5 Flash في المعاينة العامة، مع توفر نافذة سياقية تحتوي على مليون رمز مميز في Google AI Studio وVertex AI. يوفر 1.5 Pro الآن أيضًا نافذة سياقية تحتوي على 2 مليون رمز مميز من خلال قائمة انتظار للمطورين وعملاء Google Cloud الذين يستخدمون واجهة برمجة التطبيقات.
بالإضافة إلى ذلك، توسعت Gemini Nano أيضًا من إدخال النص العادي إلى إدخال الصور. في وقت لاحق من هذا العام، بدءًا من Pixel، ستطلق Google جهاز Gemini Nano متعدد الوسائط. وهذا يعني أن مستخدمي الهاتف المحمول ليسوا قادرين على معالجة إدخال النص فحسب، بل يمكنهم أيضًا فهم المزيد من المعلومات السياقية مثل البصر والصوت واللغة المنطوقة.
تم تحسين 1.5 Flash الجديد من أجل السرعة والكفاءة.
1.5 Flash هو أحدث عضو في سلسلة نماذج Gemini والأسرع بين نموذج الجوزاء لواجهات برمجة التطبيقات. تم تحسينه للمهام واسعة النطاق وذات الحجم الكبير وعالية التردد، مع خدمات أكثر فعالية من حيث التكلفة ونافذة سياق طويلة مذهلة (مليون رمز مميز).

يتمتع Gemini 1.5 Flash بقدرات تفكير قوية متعددة الوسائط ونافذة سياقية طويلة ومبتكرة.
1.5 يتفوق Flash في الملخصات وتطبيقات الدردشة وترجمات الصور والفيديو واستخراج البيانات من المستندات والجداول الطويلة والمزيد. وذلك لأن 1.5 Pro يقوم بتدريبه من خلال عملية تسمى "التقطير"، حيث ينقل المعرفة والمهارات الأساسية من نموذج أكبر إلى نموذج أصغر وأكثر كفاءة.
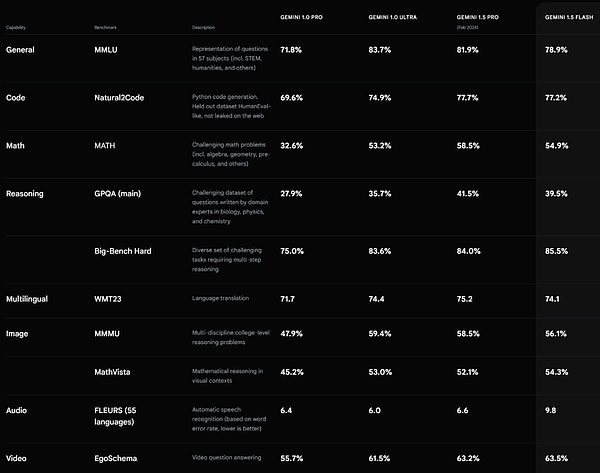
أداء فلاش Gemini 1.5. المصدر https://deepmind.google/technologies/gemini/#introduction
ذكرت Google أن أكثر من 1.5 مليون مطور يستخدمون نموذج Gemini اليوم، وأكثر من 2 مليار مستخدم للمنتج استخدموا Gemini.

في الأشهر القليلة الماضية، أضافت Google نوافذ Gemini 1.5 Pro السياقية إلى التوسعة بما يتجاوز 2 مليون رمز مميز، عززت Google أيضًا إنشاء التعليمات البرمجية والتفكير المنطقي والتخطيط والحوار متعدد المنعطفات وقدرات فهم الصوت والصورة من خلال التحسينات في البيانات والخوارزميات.

1.5 يستطيع Pro الآن اتباع تعليمات معقدة ومفصلة بشكل متزايد، بما في ذلك تلك التوجيهات التي تحدد السلوك على مستوى المنتج الذي يتضمن الأدوار والتنسيقات والأنماط. بالإضافة إلى ذلك، تسمح Google أيضًا للمستخدمين بتوجيه سلوك النموذج من خلال ضبط أوامر النظام.
الآن بعد أن أضافت Google فهم الصوت في Gemini API وGoogle AI Studio، يمكن لـ 1.5 Pro الآن إجراء الاستدلال على صور الفيديو والصوت الذي تم تحميله في Google AI Studio. بالإضافة إلى ذلك، تعمل Google على دمج الإصدار 1.5 Pro في منتجات Google، بما في ذلك Gemini Advanced وتطبيق Workspace.
يبلغ سعر Gemini 1.5 Pro 3.50 دولارًا لكل مليون رمز.
في الواقع، أحد أكثر التحولات إثارة في Gemini هو بحث Google.
على مدار العام الماضي، أجاب بحث Google على مليارات الاستفسارات كجزء من تجربة إنشاء البحث. الآن يمكن للأشخاص استخدامه للبحث بطرق جديدة، وطرح أنواع جديدة من الأسئلة، واستعلامات أطول وأكثر تعقيدًا، وحتى البحث باستخدام الصور، والحصول على أفضل المعلومات التي يقدمها الويب.

Google على وشك إطلاق ميزة Ask Photos. في حالة صور جوجل، تم إطلاق الميزة منذ حوالي تسع سنوات. واليوم، يقوم المستخدمون بتحميل أكثر من 6 مليارات صورة ومقطع فيديو يوميًا. يحب الناس استخدام الصور للبحث في حياتهم. الجوزاء يجعل الأمر أسهل.
لنفترض أنك تدفع في موقف للسيارات ولا يمكنك تذكر رقم لوحة الترخيص الخاصة بك. في السابق، كان بإمكانك البحث عن الكلمات الرئيسية في الصور ثم التمرير خلال سنوات من الصور بحثًا عن لوحات الترخيص. الآن، كل ما عليك فعله هو طلب الصور.

على سبيل المثال آخر، تتذكر الحياة المبكرة لابنتك لوسيا. الآن، يمكنك أن تسأل الصورة: متى تعلمت لوسيا السباحة؟ يمكنك أيضًا المتابعة بشيء أكثر تعقيدًا: أخبرني كيف تسير سباحة لوسيا.
هنا، الجوزاء يتجاوز البحث البسيط ويحدد خلفيات مختلفة - بما في ذلك مشاهد مختلفة مثل حمامات السباحة والمحيطات وما إلى ذلك، والصور تجمع كل شيء معًا لسهولة المشاهدة. تطرح Google خدمة Ask Photos هذا الصيف، مع المزيد في المستقبل.

اليوم، أصدرت Google أيضًا سلسلة من التحديثات للنموذج المفتوح مصدر النموذج الكبير جيما — —جيما 2 هنا.
وفقًا للتقارير، تتبنى Gemma 2 بنية جديدة وتهدف إلى تحقيق أداء وكفاءة مذهلين. معلمة النموذج مفتوح المصدر حديثًا هي 27B.

بالإضافة إلى ذلك عائلة جيما تم توسيعه أيضًا باستخدام PaliGemma، أول نموذج لغة مرئية من Google مستوحى من PaLI-3.
كان الوكلاء دائمًا اتجاهًا بحثيًا رئيسيًا في Google DeepMind.
لقد شاهدنا بالأمس جهاز GPT-4o من OpenAI وأصبنا بالصدمة من قدراته القوية على التفاعل الصوتي والمرئي في الوقت الفعلي.
اليوم، تم الكشف عن رؤية DeepMind والتفاعل الصوتي لمشروع وكيل الذكاء الاصطناعي العام Project Astra، وهذه هي رؤية Google DeepMind لمساعدي الذكاء الاصطناعي المستقبليين.
لكي تكون فعالًا حقًا، تقول Google، يحتاج الوكلاء إلى فهم العالم الحقيقي الديناميكي المعقد والاستجابة له مثل البشر، كما يحتاجون أيضًا إلى استيعاب وتذكر ما يرونه ويسمعونه لفهم السياق واتخاذ الإجراء . بالإضافة إلى ذلك، يجب أن يكون الوكيل استباقيًا وقابلاً للتعليم وشخصيًا حتى يتمكن المستخدمون من التحدث إليه بشكل طبيعي، دون تأخير أو تأخير.
على مدى السنوات القليلة الماضية، عملت Google على تحسين الطريقة التي تدرك بها نماذجنا، وتفكر، وتتحدث لجعل سرعة وجودة التفاعلات أكثر طبيعية.
في الكلمة الرئيسية اليوم، أظهر Google DeepMind القدرات التفاعلية لمشروع Astra:
وفقًا للتقارير، طورت Google نموذجًا أوليًا ذكيًا للوكيل يعتمد على Gemini، والذي يمكنه معالجة المعلومات بشكل مستمر بشكل أسرع عن طريق التشفير إطارات الفيديو، والجمع بين إدخال الفيديو والصوت في جدول زمني للأحداث، وتخزين هذه المعلومات مؤقتًا من أجل الاستدعاء الفعال.
من خلال نموذج الكلام، قامت Google أيضًا بتعزيز نطق الوكيل وتزويد الوكيل بنطاق أوسع من نغمات الصوت. يمكن لهؤلاء الوكلاء فهم السياق الذي يتم استخدامهم فيه بشكل أفضل والاستجابة بسرعة أثناء المحادثات.
مجرد تعليق مختصر هنا. يشعر قلب الآلة أن العرض التوضيحي الذي أصدره مشروع Project Astra أسوأ بكثير من العرض التوضيحي في الوقت الفعلي لـ GPT-4o من حيث التجربة التفاعلية. سواء كان الأمر يتعلق بطول الاستجابة، أو الثراء العاطفي للصوت، أو القدرة على المقاطعة، وما إلى ذلك، فإن التجربة التفاعلية لـ GPT-4o تبدو أكثر طبيعية. وأتساءل كيف يشعر القراء؟
فيما يتعلق بمقاطع الفيديو المولدة بالذكاء الاصطناعي، أعلنت Google عن إطلاق نموذج إنشاء الفيديو Veo. Veo قادر على إنتاج مقاطع فيديو عالية الجودة بدقة 1080 بكسل في مجموعة متنوعة من الأنماط ويمكن أن يصل طولها إلى أكثر من دقيقة.
من خلال فهمه المتعمق للغة الطبيعية والدلالات المرئية، حقق نموذج Veo اختراقات في فهم محتوى الفيديو، وتقديم صور عالية الوضوح، ومحاكاة المبادئ الفيزيائية. تعبر مقاطع الفيديو التي تم إنشاؤها بواسطة Veo بدقة وإحكام عن النية الإبداعية للمستخدم.
على سبيل المثال، أدخل النص الموجه:
تتميز العديد من قناديل البحر المرقطة النابضة تحت الماء بأجسامها الشفافة متوهجة في أعماق المحيطات.
(تنبض العديد من قناديل البحر المرقطة تحت الماء. وتتألق أجسامها الشفافة في أعماق المحيطات. )< /span>
لمثال آخر، لإنشاء فيديو شخصية، أدخل المطالبة:
راعي بقر وحيد يركب حصانه عبر سهل مفتوح عند غروب الشمس الجميل، والضوء الناعم، والألوان الدافئة.
(في ظل غروب الشمس الجميل والضوء الناعم والألوان الدافئة، يركب راعي البقر وحيدًا عبر السهول المفتوحة)
فيديو أقرب لشخص ما، أدخل المطالبة: <
امرأة تجلس بمفردها في مقهى خافت الإضاءة، أمامها رواية نصف مكتملة مفتوحة أمامها فيلم نوير جمالي، غامض الجو أبيض وأسود.
(امرأة تجلس بمفردها في مقهى ذات إضاءة خافتة، تقرأ كتابًا غير مكتوب. الرواية النهائية تقع أمامها. جمالية فيلم نوير، جو غامض.)
من اللافت للنظر أن نموذج Veo يقدم مستوى غير مسبوق من التحكم الإبداعي والفهم لمصطلحات الفيلم مثل "الوقت". - التصوير بالفاصل الزمني" و"التصوير الجوي" يجعل الفيديو متماسكًا وواقعيًا.
على سبيل المثال، للحصول على لقطة جوية للساحل على مستوى الفيلم، أدخل المطالبة:
لقطة من طائرة بدون طيار على طول ساحل غابة هاواي، يوم مشمس
(لقطة بطائرة بدون طيار على طول ساحل غابة هاواي، يوم مشمس)< /p>
يدعم Veo أيضًا استخدام الصور والنصوص معًا كمطالبات لإنشاء مقاطع فيديو. من خلال توفير الصور المرجعية والإشارات النصية، تتبع مقاطع الفيديو التي تم إنشاؤها بواسطة Veo نمط الصورة والأوصاف النصية للمستخدم.
ومن المثير للاهتمام أن العرض التوضيحي الذي أصدرته Google عبارة عن فيديو "alpaca" تم إنشاؤه بواسطة Veo، والذي يذكرنا بسهولة بنموذج سلسلة Llama مفتوحة المصدر من Meta.

فيما يتعلق بمقاطع الفيديو الطويلة، يمكن لشركة Veo إنتاج مقاطع فيديو مدتها 60 ثانية أو حتى أطول . ويمكنه القيام بذلك من خلال مطالبة واحدة أو من خلال تقديم سلسلة من المطالبات التي تحكي قصة معًا. وهذا أمر بالغ الأهمية لتطبيق نماذج توليد الفيديو في إنتاج الأفلام والتلفزيون.
يعتمد Veo على أعمال إنشاء المحتوى المرئي من Google، بما في ذلك شبكات الاستعلام التوليدية (GQN)، وDVD-GAN، وImagen-Video، وPhenaki، وWALT، وVideoPoet، وLumiere، والمزيد.
بدءًا من اليوم، ستوفر Google إصدار معاينة من VideoFX لبعض منشئي المحتوى باستخدام Veo ، يمكن لمنشئي المحتوى الانضمام إلى قائمة انتظار Google. ستجلب Google أيضًا بعض ميزات Veo إلى منتجات مثل YouTube Shorts.
فيما يتعلق بإنشاء نص إلى صورة، قامت Google مرة أخرى بترقية سلسلة نماذجها - حيث أطلقت Imagen 3.
تم تحسين Imagen 3 وترقيته من حيث توليد التفاصيل والإضاءة والتداخل وما إلى ذلك، وتم تحسين القدرة على فهم المطالبات بشكل كبير.
لمساعدة Imagen 3 في التقاط التفاصيل من المطالبات الأطول، مثل زوايا الكاميرا أو تركيباتها المحددة، أضافت Google تفاصيل أكثر ثراءً إلى التسميات التوضيحية لكل صورة في بيانات التدريب.
على سبيل المثال، إذا أضفت "بعيدًا قليلاً عن التركيز في المقدمة"، و"الضوء الدافئ"، وما إلى ذلك إلى موجه الإدخال، فيمكن لـ Imagen 3 إنشاء صور كما هو مطلوب:

بالإضافة إلى ذلك، أجرت Google تحسينات خاصة لمعالجة مشكلة "النص غير الواضح" في إنشاء الصور، أي أنه قام بتحسين عرض الصور بحيث يكون النص الموجود في الصور التي تم إنشاؤها واضحًا ومنمقًا.

من أجل تحسين سهولة الاستخدام، سيوفر Imagen 3 إصدارات متعددة، كل إصدار محسّن لأنواع مختلفة من المهام.
بدءًا من اليوم، تقدم Google إصدار معاينة من Imagen 3 في ImageFX لبعض منشئي المحتوى، ويمكن للمستخدمين الاشتراك للانضمام إلى قائمة الانتظار.
يعمل الذكاء الاصطناعي التوليدي على تغيير الطريقة التي يتفاعل بها البشر مع التكنولوجيا، وفي الوقت نفسه يجلب فوائد للشركات فرص كفاءة ضخمة. لكن هذه التطورات تتطلب مزيدًا من قوة الحوسبة والذاكرة والاتصالات لتدريب أقوى النماذج وضبطها.
ولتحقيق هذه الغاية، أطلقت جوجل الجيل السادس من مادة TPU Trillium، وهو أقوى مادة TPU وأكثرها كفاءة في استخدام الطاقة حتى الآن، وسيتم إطلاقه رسميًا في نهاية عام 2024.
إن TPU Trillium عبارة عن أجهزة مخصصة للغاية ومخصصة للذكاء الاصطناعي، حيث تم الإعلان عن العديد من الابتكارات في مؤتمر Google I/O، بما في ذلك النماذج الجديدة مثل Gemini 1.5 Flash وImagen 3 وGemma 2، والتي يتم تنفيذها جميعها قيد التدريب. على TPU ويتم توفير الخدمات باستخدام TPU.

وفقًا للتقارير، مقارنة بـ TPU v5e، فإن حساب الذروة لكل شريحة من Trillium تم تحسين أداء TPU بمقدار 4.7 مرة، كما أنه يضاعف أيضًا عرض النطاق الترددي للذاكرة ذات النطاق الترددي العالي (HBM) وعرض النطاق الترددي للربط بين الرقائق (ICI). بالإضافة إلى ذلك، يتميز Trillium بالجيل الثالث من SparseCore المصمم للتعامل مع عمليات التضمين الكبيرة جدًا الشائعة في أعباء عمل التصنيف والتوصيات المتقدمة.
قالت Google إن Trillium يمكنه تدريب جيل جديد من نماذج الذكاء الاصطناعي بشكل أسرع مع تقليل زمن الوصول والتكلفة. بالإضافة إلى ذلك، تم تصنيف Trillium على أنه مادة TPU الأكثر استدامة من Google حتى الآن، مع تحسن بنسبة تزيد عن 67% في كفاءة استخدام الطاقة مقارنة بسابقه.
يمكن لـ Trillium التوسع إلى ما يصل إلى 256 وحدة معالجة حرارية (TPUs) في مجموعة حوسبة واحدة ذات نطاق ترددي عالٍ وزمن وصول منخفض (pod). بالإضافة إلى قابلية التوسع على مستوى المجموعة، يمكن توسيع Trillium TPU ليشمل مئات المجموعات وتوصيل آلاف الرقائق من خلال تقنية الشرائح المتعددة ووحدات المعالجة الذكية (وحدات المعالجة الذكية من التيتانيوم، ووحدات IPU) التي تشكل حاسوبًا فائقًا مترابطًا بواسطة PB (متعدد البيتابت). -في الثانية) شبكة مركز البيانات.
أطلقت Google أول إصدار من TPU v1 في وقت مبكر من عام 2013، تلته وحدات TPU السحابية في عام 2017. وتدعم وحدات TPU هذه خدمات متنوعة مثل البحث الصوتي في الوقت الفعلي، والتعرف على كائنات الصور، وترجمة اللغة حتى أنها توفر القوة التقنية لمنتجات مثل شركة السيارات ذاتية القيادة Nuro.
يعد Trillium أيضًا جزءًا من حاسوب Google الفائق الذي يعمل بالذكاء الاصطناعي، وهو عبارة عن بنية حوسبة فائقة رائدة مصممة للتعامل مع أعباء عمل الذكاء الاصطناعي المتطورة. تعمل Google مع Hugging Face لتحسين الأجهزة للتدريب على النماذج مفتوحة المصدر وتقديمها.

ما ورد أعلاه هو كل النقاط البارزة في مؤتمر Google I/O اليوم. يمكن ملاحظة أن Google تتنافس بشكل كامل مع OpenAI من حيث التكنولوجيا والمنتجات ذات النماذج الكبيرة. من خلال إصدارات OpenAI وGoogle في اليومين الماضيين، يمكننا أيضًا أن نجد أن منافسة النماذج الكبيرة قد دخلت مرحلة جديدة: أصبحت التجربة التفاعلية متعددة الوسائط والأكثر طبيعية نتاجًا لتقنية النماذج الكبيرة ومقبولة من قبل المزيد من الأشخاص. الأساسي.
بالتطلع إلى عام 2024، ستجلب لنا تكنولوجيا النماذج الكبيرة وابتكار المنتجات المزيد من المفاجآت.
وتشير التقارير إلى أن شركة مايكروسوفت تخطط لاستضافة أحدث طراز من OpenAI في وقت مبكر من الأسبوع المقبل.
JinseFinanceهذه هي المرة الأولى التي تتصدر فيها Google قائمة المتصدرين في Chatbot Arena.
JinseFinanceذكرت OpenAI أن إطلاق GPT-4o mini يمثل تقدمًا كبيرًا في تقليل التكاليف وتعزيز قدرات النموذج، وهي ملتزمة بجعل الذكاء الاصطناعي أكثر شعبية وموثوقية.
 WenJun
WenJunأطلقت شركة OpenAI "GPT-4o mini" في 18 يوليو، مدعية أنها أرخص وأكثر كفاءة من GPT-3.5 Turbo. هل تحاكي OpenAI إصدارات Apple المتكررة، وهل سيؤثر ذلك على جودة نماذج الذكاء الاصطناعي التوليدية الخاصة بها؟
 Kikyo
Kikyoتعمل شركة OpenAI على تكثيف الجهود من خلال إصدار خليفة لـGPT-4، مع التركيز على السلامة. وسط التدقيق الأخلاقي والانتقادات، تم تشكيل لجنة للسلامة والأمن لمعالجة المخاوف وضمان التطوير المسؤول للذكاء الاصطناعي.
 Huang Bo
Huang Boالاستقالات الأخيرة في OpenAI، بما في ذلك كبير العلماء إيليا سوتسكيفر وجان ليك من "فريق المحاذاة الفائقة"، تأتي في أعقاب خلافات حول إعطاء الأولوية للسلامة وسط إطلاق GPT-4o. لا تزال المخاوف قائمة بشأن تحول OpenAI نحو الربح والمخاطر الأمنية المحتملة في عمليات التعاون مثل تحديث iOS 18 من Apple الذي يدمج تقنية OpenAI.
 Weatherly
Weatherlyبعد 17 شهرًا فقط من ظهور ChatGPT، توصلت OpenAI إلى ذكاء اصطناعي فائق كما هو الحال في أفلام الخيال العلمي، وهو مجاني تمامًا ومتاح للجميع.
JinseFinanceأعلنت شركة OpenAI يوم الاثنين عن أحدث نموذج لغة كبير للذكاء الاصطناعي، والذي تقول إنه سيجعل ChatGPT أكثر ذكاءً وأسهل في الاستخدام.
JinseFinanceيعمل الإصدار الأخير على تحويل تفاعلات الذكاء الاصطناعي من خلال توسيع قاعدة المعرفة حتى أبريل 2023 وتقديم الدعم للمستندات المكونة من 300 صفحة.
 JixuJinseFinance
JixuJinseFinance