[ميزة] ارتفاع أسعار التشفير ─ هل هو سباق ثور أم مصيدة ثور؟
ارتفعت أسعار العملات المشفرة مؤخرًا ، ولكن في حين أن البعض متفائل بعودة المضاربين على العملة المشفرة ، يشعر آخرون أنها مجرد فخ ثور في سوق صاعدة. ما هو رأيك في هذا؟
 Catherine
Catherine

في السنوات القليلة الماضية، لقد اجتذب التطور السريع للذكاء الاصطناعي (AI) وتكنولوجيا Web3 اهتمامًا واسع النطاق في جميع أنحاء العالم. باعتباره تقنية تحاكي وتقليد الذكاء البشري، حقق الذكاء الاصطناعي اختراقات كبيرة في مجالات مثل التعرف على الوجوه، ومعالجة اللغات الطبيعية، والتعلم الآلي. لقد أحدث التطور السريع لتكنولوجيا الذكاء الاصطناعي تغييرات وابتكارات هائلة في جميع مناحي الحياة.
سيصل حجم سوق صناعة الذكاء الاصطناعي إلى 200 مليار دولار أمريكي في عام 2023. وقد قام عمالقة الصناعة واللاعبون المتميزون مثل OpenAI وCacter.AI وMidjourney ظهرت لقيادة الطريق.
وفي الوقت نفسه، يعمل Web3، باعتباره نموذج شبكة ناشئ، على تغيير الطريقة التي نفهم بها ونستخدم بها الإنترنت تدريجيًا. يعتمد Web3 على تقنية blockchain اللامركزية ويحقق مشاركة البيانات وإمكانية التحكم فيها واستقلالية المستخدم وإنشاء آليات الثقة من خلال وظائف مثل العقود الذكية والتخزين الموزع والتحقق اللامركزي من الهوية. المفهوم الأساسي لـ Web3 هو تحرير البيانات من أيدي السلطات المركزية ومنح المستخدمين الحق في التحكم في البيانات والحق في مشاركة قيمة البيانات.
وقد وصلت القيمة السوقية الحالية لصناعة Web3 إلى 25 تريليون، سواء كانت Bitcoin أو Ethereum أو Solana أو لاعبين مثل Uniswap وStepn في طبقة التطبيقات، روايات وسيناريوهات جديدة تظهر أيضًا واحدة تلو الأخرى، وتجذب المزيد والمزيد من الأشخاص للانضمام إلى صناعة Web3.
من السهل أن تجد أن الجمع بين الذكاء الاصطناعي وWeb3 هو مجال يوليه المنشئون ورأس المال الاستثماري في الشرق والغرب اهتمامًا وثيقًا بكيفية التكامل البئرتان من الأسئلة الجديرة بالاهتمام للغاية التي يجب استكشافها.
ستركز هذه المقالة على حالة التطوير الحالية لـ AI+Web3 وتستكشف القيمة والتأثير المحتملين الناتج عن هذا التكامل. سنقدم أولاً المفاهيم والخصائص الأساسية للذكاء الاصطناعي وWeb3، ثم نستكشف العلاقة المتبادلة بينهما. بعد ذلك، سنقوم بتحليل الوضع الحالي لمشاريع AI+Web3 ونناقش بعمق القيود والتحديات التي تواجهها. ومن خلال هذا البحث، نأمل أن نقدم مراجع ورؤى قيمة للمستثمرين والممارسين في الصناعات ذات الصلة.
الذكاء الاصطناعي وWeb3 إن تطوير الذكاء الاصطناعي يشبه وجهي التوازن، فقد أدى الذكاء الاصطناعي إلى تحسينات في الإنتاجية، في حين أحدث الويب 3 تغييرات في علاقات الإنتاج. إذًا ما هو نوع الشرر الذي يمكن أن يتصادم معه الذكاء الاصطناعي وWeb3؟ بعد ذلك، سنقوم أولاً بتحليل الصعوبات ومساحة التحسين التي تواجهها صناعات الذكاء الاصطناعي وWeb3، ثم نناقش كيف يمكن لبعضنا البعض المساعدة في حل هذه الصعوبات.
الصعوبات التي تواجهها صناعة الذكاء الاصطناعي ومجال التحسين المحتمل
< /li>< li>الصعوبات التي تواجهها صناعة Web3 والمجال المحتمل للتحسين
< strong>2.1 المعضلات التي تواجهها صناعة الذكاء الاصطناعي
لاستكشاف الصعوبات التي تواجهها صناعة الذكاء الاصطناعي، دعونا أولاً نلقي نظرة على طبيعة صناعة الذكاء الاصطناعي. لا يمكن فصل جوهر صناعة الذكاء الاصطناعي عن ثلاثة عناصر: قوة الحوسبة والخوارزميات والبيانات.
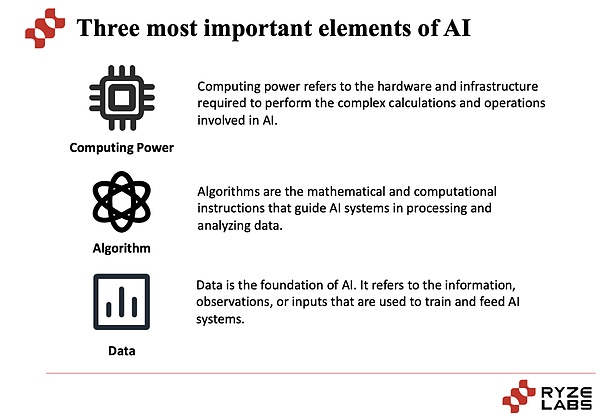
الأولى هي قوة الحوسبة: تشير قوة الحوسبة إلى القدرة على إجراء عمليات حسابية ومعالجة واسعة النطاق. غالبًا ما تتطلب مهام الذكاء الاصطناعي معالجة كميات كبيرة من البيانات وإجراء حسابات معقدة، مثل تدريب نماذج الشبكات العصبية العميقة. يمكن لقوة الحوسبة عالية الكثافة تسريع عملية التدريب والاستدلال النموذجي وتحسين أداء وكفاءة أنظمة الذكاء الاصطناعي. في السنوات الأخيرة، مع تطور تكنولوجيا الأجهزة، مثل وحدات معالجة الرسومات (GPUs) وشرائح الذكاء الاصطناعي المخصصة (مثل TPU)، لعبت التحسينات في قوة الحوسبة دورًا مهمًا في تعزيز تطوير صناعة الذكاء الاصطناعي. واحتلت شركة Nvidia، التي ارتفعت أسهمها بشكل كبير في السنوات الأخيرة، حصة سوقية كبيرة كمزود لوحدات معالجة الرسومات وحققت أرباحًا عالية.
ما هي الخوارزميات: الخوارزميات هي المكونات الأساسية لأنظمة الذكاء الاصطناعي ويتم استخدامها لحل المشكلات والأساليب الرياضية والإحصائية لتحقيق المهمة. يمكن تقسيم خوارزميات الذكاء الاصطناعي إلى خوارزميات التعلم الآلي التقليدية وخوارزميات التعلم العميق، ومن بينها خوارزميات التعلم العميق التي حققت اختراقات كبيرة في السنوات الأخيرة. يعد اختيار الخوارزميات وتصميمها أمرًا بالغ الأهمية لأداء وفعالية أنظمة الذكاء الاصطناعي. يمكن للخوارزميات المحسنة والمبتكرة باستمرار تحسين دقة وقوة وقدرات تعميم أنظمة الذكاء الاصطناعي. سيكون للخوارزميات المختلفة تأثيرات مختلفة، لذا فإن تحسين الخوارزمية يعد أيضًا أمرًا بالغ الأهمية لتأثير إكمال المهمة.
سبب أهمية البيانات: المهمة الأساسية لنظام الذكاء الاصطناعي هي استخراج البيانات من البيانات من خلال أنماط التعلم والتدريب والانتظام.
البيانات هي أساس التدريب وتحسين النماذج، ومن خلال عينات البيانات واسعة النطاق، يمكن لأنظمة الذكاء الاصطناعي تعلم نماذج أكثر دقة وذكاءً. يمكن لمجموعات البيانات الغنية أن توفر معلومات أكثر شمولاً وتنوعًا، مما يسمح للنماذج بتعميم البيانات غير المرئية بشكل أفضل، مما يساعد أنظمة الذكاء الاصطناعي على فهم مشاكل العالم الحقيقي وحلها بشكل أفضل.
بعد فهم العناصر الأساسية الثلاثة للذكاء الاصطناعي الحالي، دعونا نلقي نظرة على الصعوبات والتحديات التي يواجهها الذكاء الاصطناعي في هذه المجالات ثلاثة جوانب، أولاً، فيما يتعلق بالقوة الحاسوبية، تتطلب مهام الذكاء الاصطناعي عادةً كمية كبيرة من موارد الحوسبة للتدريب على النماذج والاستدلال، وخاصةً لنماذج التعلم العميق. ومع ذلك، فإن الحصول على قوة حاسوبية واسعة النطاق وإدارتها يمثل تحديًا مكلفًا ومعقدًا. تعد التكلفة واستهلاك الطاقة وصيانة معدات الحوسبة عالية الأداء من المشكلات. خاصة بالنسبة للشركات الناشئة والمطورين الأفراد، قد يكون الحصول على قوة حاسوبية كافية أمرًا صعبًا.
فيما يتعلق بالخوارزميات، على الرغم من أن خوارزميات التعلم العميق حققت نجاحًا كبيرًا في العديد من المجالات، إلا أنه لا تزال هناك بعض المعضلات والتحديات. على سبيل المثال، يتطلب تدريب الشبكات العصبية العميقة كميات كبيرة من البيانات وموارد الحوسبة، وبالنسبة لبعض المهام، قد تكون قابلية تفسير النموذج وقابليته للتفسير غير كافية. بالإضافة إلى ذلك، تعد قوة الخوارزمية وقدرتها على التعميم من المشكلات المهمة أيضًا، وقد يكون أداء النموذج على البيانات غير المرئية غير مستقر. من بين الخوارزميات العديدة، فإن كيفية العثور على أفضل خوارزمية لتقديم أفضل خدمة هي عملية تتطلب الاستكشاف المستمر.
فيما يتعلق بالبيانات، تعد البيانات القوة الدافعة للذكاء الاصطناعي، ولكن الحصول على بيانات عالية الجودة ومتنوعة لا يزال يمثل تحديًا. قد يكون من الصعب الحصول على البيانات في بعض المجالات، مثل البيانات الصحية الحساسة في المجال الطبي. بالإضافة إلى ذلك، تعد جودة البيانات ودقتها والتعليقات التوضيحية من المشكلات أيضًا، ويمكن أن تؤدي البيانات غير الكاملة أو المتحيزة إلى سلوك خاطئ أو تحيز في النموذج. وفي الوقت نفسه، تعد حماية خصوصية البيانات وأمنها أحد الاعتبارات المهمة أيضًا.
بالإضافة إلى ذلك، هناك أيضًا مشكلات مثل قابلية التفسير والشفافية. إن طبيعة الصندوق الأسود لنماذج الذكاء الاصطناعي هي مسألة ذات اهتمام عام. بالنسبة لبعض التطبيقات، مثل التمويل والرعاية الطبية والعدالة، يجب أن تكون عملية اتخاذ القرار الخاصة بالنموذج قابلة للتفسير وقابلة للتتبع، وغالبًا ما تفتقر نماذج التعلم العميق الحالية إلى الشفافية. يظل شرح عملية اتخاذ القرار الخاصة بالنموذج وتقديم تفسيرات جديرة بالثقة يمثل تحديًا.
بالإضافة إلى ذلك، فإن نماذج الأعمال للعديد من الشركات الناشئة في مجال الذكاء الاصطناعي ليست واضحة تمامًا، مما يجعل العديد من رواد الأعمال في مجال الذكاء الاصطناعي يشعرون بالارتباك.
2.2 الصعوبات التي تواجهها صناعة Web3
وفي فيما يتعلق بالصناعة، توجد حاليًا العديد من الصعوبات التي تحتاج إلى حل في جوانب مختلفة، سواء كان ذلك يتعلق بتحليل بيانات Web3، أو تجربة المستخدم السيئة لمنتجات Web3، أو مشاكل نقاط الضعف في كود العقد الذكي وهجمات المتسللين. مساحة كبيرة للتحسين. باعتباره أداة لتحسين الإنتاجية، يتمتع الذكاء الاصطناعي أيضًا بالكثير من الإمكانات في هذه الجوانب.
الأول هو تحسين قدرات تحليل البيانات والتنبؤ: لقد أحدث تطبيق تقنية الذكاء الاصطناعي في تحليل البيانات والتنبؤ بها تأثيرًا كبيرًا على صناعة Web3. من خلال التحليل الذكي واستخراج خوارزميات الذكاء الاصطناعي، يمكن لمنصة Web3 استخراج معلومات قيمة من البيانات الضخمة وإجراء تنبؤات وقرارات أكثر دقة. وهذا له أهمية كبيرة لتقييم المخاطر والتنبؤ بالسوق وإدارة الأصول في مجال التمويل اللامركزي (DeFi).
بالإضافة إلى ذلك، يمكن أيضًا تحقيق تحسينات في تجربة المستخدم والخدمات الشخصية: يتيح تطبيق تقنية الذكاء الاصطناعي لمنصة Web3 توفير تجربة مستخدم أفضل وخدمات مخصصة. من خلال تحليل بيانات المستخدم ونمذجةها، يمكن لمنصة Web3 أن تزود المستخدمين بتوصيات مخصصة وخدمات مخصصة وتجارب تفاعلية ذكية. يساعد هذا على تحسين مشاركة المستخدم ورضاه ويعزز تطوير نظام Web3 البيئي، على سبيل المثال، ترتبط العديد من بروتوكولات Web3 بأدوات الذكاء الاصطناعي مثل ChatGPT لخدمة المستخدمين بشكل أفضل.
في ما يتعلق بالأمن وحماية الخصوصية، فإن تطبيق الذكاء الاصطناعي له أيضًا تأثير عميق على صناعة Web3. يمكن استخدام تقنية الذكاء الاصطناعي للكشف عن الهجمات الإلكترونية والدفاع ضدها، وتحديد السلوك غير الطبيعي، وتوفير أمان أقوى. وفي الوقت نفسه، يمكن أيضًا تطبيق الذكاء الاصطناعي على حماية خصوصية البيانات لحماية المعلومات الشخصية للمستخدمين على منصة Web3 من خلال تقنيات مثل تشفير البيانات وحوسبة الخصوصية. فيما يتعلق بتدقيق العقود الذكية، نظرًا لاحتمال وجود ثغرات ومخاطر أمنية في عملية كتابة وتدقيق العقود الذكية، يمكن استخدام تقنية الذكاء الاصطناعي لأتمتة تدقيق العقود واكتشاف الثغرات الأمنية لتحسين أمان وموثوقية العقود.
يمكن ملاحظة أن الذكاء الاصطناعي يمكنه المشاركة والمساعدة في العديد من الجوانب فيما يتعلق بالصعوبات التي تواجهها صناعة Web3 والمجال المحتمل للتحسين.
الجمع بين الذكاء الاصطناعي وWeb3 يبدأ مشروع Web3 بشكل أساسي من جانبين رئيسيين، استخدام تقنية blockchain لتحسين أداء مشاريع الذكاء الاصطناعي، واستخدام تقنية الذكاء الاصطناعي لخدمة تحسين مشاريع Web3.
وبالدور حول هذين الجانبين، ظهر عدد كبير من المشاريع لاستكشاف هذا الطريق، بما في ذلك مشاريع مختلفة مثل Io.net، وGensyn، وRitual. بعد ذلك، ستحلل هذه المقالة الوضع الحالي وتطور المسارات الفرعية المختلفة للذكاء الاصطناعي الذي يساعد web3 وWeb3 الذي يساعد الذكاء الاصطناعي.
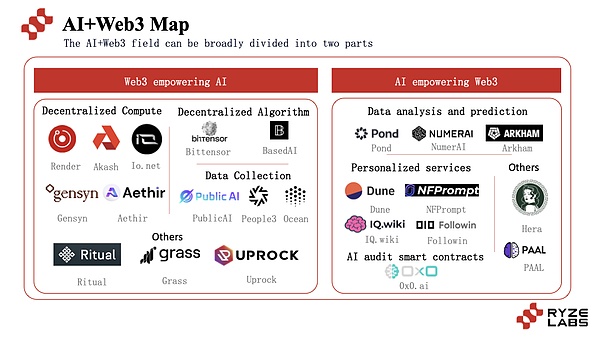
3.1 Web3 يساعد الذكاء الاصطناعي
3.1.1 قوة الحوسبة اللامركزية
منذ أن أطلقت OpenAI ChatGPT في نهاية عام 2022، فجّرت جنون الذكاء الاصطناعي، وبعد خمسة أيام من إطلاقها، وصل عدد المستخدمين إلى مليون مستخدم، بينما استغرق Instagram حوالي اثنين استغرق نصف شهر للوصول إلى مليون عملية تنزيل. بعد ذلك، تطور Chatgpt أيضًا بسرعة. وفي غضون شهرين، وصل عدد المستخدمين النشطين شهريًا إلى 100 مليون. وبحلول نوفمبر 2023، وصل عدد المستخدمين النشطين أسبوعيًا إلى 100 مليون. مع ظهور Chatgpt، انتشر مجال الذكاء الاصطناعي بسرعة من مسار متخصص إلى صناعة جذبت الكثير من الاهتمام.
وفقًا لتقرير Trendforce، يتطلب ChatGPT 30,000 وحدة معالجة رسوميات NVIDIA A100 لتشغيله، وسيتطلب GPT-5 عددًا أكبر من العمليات الحسابية في المستقبل. لقد أدى هذا أيضًا إلى بدء سباق تسلح بين شركات الذكاء الاصطناعي المختلفة، فقط من خلال إتقان ما يكفي من القوة الحاسوبية يمكننا التأكد من حصولنا على القوة والمزايا الكافية في حرب الذكاء الاصطناعي، وبالتالي هناك نقص في وحدات معالجة الرسومات.
قبل ظهور الذكاء الاصطناعي، كان عملاء NVIDIA، أكبر مزود لوحدات معالجة الرسومات، يتركزون في الخدمات السحابية الثلاث الرئيسية: AWS، وAzure، وGCP. مع ظهور الذكاء الاصطناعي، ظهر عدد كبير من المشترين الجدد، بما في ذلك شركات التكنولوجيا الكبرى ميتا وأوراكل وغيرها من منصات البيانات وشركات الذكاء الاصطناعي الناشئة، وجميعهم انضموا إلى الحرب لتخزين وحدات معالجة الرسومات لتدريب نماذج الذكاء الاصطناعي. قامت شركات التكنولوجيا الكبرى مثل Meta وTesla بزيادة مشترياتها من نماذج الذكاء الاصطناعي المخصصة والأبحاث الداخلية بشكل كبير. كما تقوم شركات النمذجة الأساسية مثل Anthropic ومنصات البيانات مثل Snowflake وDatabricks بشراء المزيد من وحدات معالجة الرسومات لمساعدة العملاء على تقديم خدمات الذكاء الاصطناعي.
كما ذكر Semi Analysis العام الماضي، "وحدة معالجة الرسومات غنية ووحدة معالجة الرسومات فقيرة"، لدى عدد قليل من الشركات أكثر من 20000 وحدة معالجة رسومات A100/H100، ويمكن لأعضاء الفريق تقديم المشاريع استخدم 100 إلى 1000 وحدة معالجة رسومات. هذه الشركات هي إما موفرة للخدمات السحابية أو LLMs ذاتية الصنع، بما في ذلك OpenAI، وGoogle، وMeta، وAnthropic، وInflection، وTesla، وOracle، وMistral، وما إلى ذلك.
ومع ذلك، فإن معظم الشركات تعاني من ضعف وحدة معالجة الرسومات. ولا يمكنها إلا أن تعاني مع عدد أقل بكثير من وحدات معالجة الرسومات وقضاء الكثير من الوقت والطاقة في القيام بأشياء يصعب القيام بها تعزيز شيء عن تطوير النظام البيئي. وهذا لا يقتصر على الشركات الناشئة. بعض شركات الذكاء الاصطناعي الأكثر شهرة - Hugging Face، وDatabricks (MosaicML)، وTogether، وحتى Snowflake لديها أقل من 20 ألف A100/H100. وتتمتع هذه الشركات بمواهب تقنية عالمية المستوى، ولكنها محدودة بسبب المعروض من وحدات معالجة الرسومات. ومقارنة بالشركات الكبيرة، فهي في وضع غير مؤات في المنافسة في مجال الذكاء الاصطناعي.
لا يقتصر هذا النقص على "ضعف وحدة معالجة الرسومات". حتى في نهاية عام 2023، كانت شركة OpenAI، الرائدة في مجال الذكاء الاصطناعي، كذلك غير قادر على الحصول على ما يكفي من وحدات معالجة الرسومات اضطر إلى إغلاق التسجيل المدفوع لبضعة أسابيع أثناء شراء المزيد من مستلزمات وحدة معالجة الرسومات.
يمكن ملاحظة أنه مع التطور السريع للذكاء الاصطناعي، كان هناك عدم تطابق خطير بين جانب الطلب وجانب العرض لوحدات معالجة الرسومات، وأصبحت مشكلة العرض الذي يتجاوز الطلب وشيكة.
لحل هذه المشكلة، بدأت بعض مشاريع Web3 في محاولة الجمع بين الميزات التقنية لـ Web3 لتوفير خدمات الحوسبة اللامركزية، بما في ذلك Akash وRender وGensyn و أكثر. القاسم المشترك بين هذه المشاريع هو أن الرموز المميزة تُستخدم لتشجيع المستخدمين على توفير طاقة حوسبة وحدة معالجة الرسومات الخاملة، لتصبح جانب العرض لقوة الحوسبة لتوفير دعم طاقة الحوسبة لعملاء الذكاء الاصطناعي.
يمكن تقسيم صورة جانب العرض بشكل أساسي إلى ثلاثة جوانب: مقدمو الخدمات السحابية، وعمال مناجم العملات المشفرة، والمؤسسات.
يشمل مقدمو الخدمات السحابية موفري الخدمات السحابية الكبار (مثل AWS وAzure وGCP) ومقدمي الخدمات السحابية GPU (مثل Coreweave وLambda وCrusoe وما إلى ذلك. ).يمكن للمستخدمين كسب الدخل عن طريق إعادة بيع قوة الحوسبة الخاملة لمقدمي الخدمات السحابية. عمال تعدين العملات المشفرة مع تحول إيثريوم من إثبات العمل (PoW) إلى إثبات الحصة (PoS)، أصبحت قوة حوسبة وحدة معالجة الرسومات الخاملة أيضًا جانبًا محتملًا مهمًا للعرض. بالإضافة إلى ذلك، يمكن للشركات الكبيرة مثل Tesla وMeta التي اشترت عددًا كبيرًا من وحدات معالجة الرسومات بسبب التخطيط الاستراتيجي أيضًا استخدام قوة حوسبة وحدة معالجة الرسومات الخاملة كجانب توريد.
ينقسم اللاعبون الحاليون على المسار تقريبًا إلى فئتين. إحداهما تستخدم قوة الحوسبة اللامركزية لاستدلال الذكاء الاصطناعي، والأخرى تستخدم قوة الحوسبة اللامركزية يتم استخدام الطاقة لتدريب الذكاء الاصطناعي. الأول مثل Render (على الرغم من أنه يركز على العرض، إلا أنه يمكن استخدامه أيضًا لتوفير قوة حوسبة الذكاء الاصطناعي)، وAkash، وAethir، وما إلى ذلك؛ والأخير مثل io.net (يمكن أن يدعم كلاً من الاستدلال والتدريب) وGensyn أكبر فرق بين الاثنين هو أن قوة الحوسبة ومتطلبات القوة مختلفة.
دعونا نتحدث أولاً عن مشروع استدلال الذكاء الاصطناعي السابق. يجذب هذا النوع من المشاريع المستخدمين للمشاركة في توفير الطاقة الحاسوبية من خلال الحوافز الرمزية، ثم يستخدم الحوسبة يتم توفير خدمة شبكة الطاقة لجانب الطلب، وبالتالي تحقيق مطابقة العرض والطلب لقوة الحوسبة الخاملة. تم ذكر مقدمة وتحليل هذا النوع من المشاريع في تقرير بحث DePIN السابق الخاص بشركة Ryze Labs، مرحبا بكم في العرض.
النقطة الأساسية هي أنه من خلال آلية الحوافز الرمزية، يجذب المشروع الموردين أولاً ثم يجذب المستخدمين لاستخدامه، وبالتالي تحقيق البداية الباردة وآلية التشغيل الأساسية للمشروع، مما يتيح المزيد من التوسع والتطوير. في ظل هذه الدورة، يتمتع جانب العرض بعوائد رمزية ذات قيمة متزايدة، ويتمتع جانب الطلب بخدمات أرخص وأكثر فعالية من حيث التكلفة، وتظل القيمة الرمزية للمشروع متسقة مع نمو المشاركين على جانبي العرض والطلب يجذب ارتفاع أسعار العملات الرمزية المزيد من المشاركين والمضاربين للمشاركة، مما يشكل عملية التقاط القيمة.
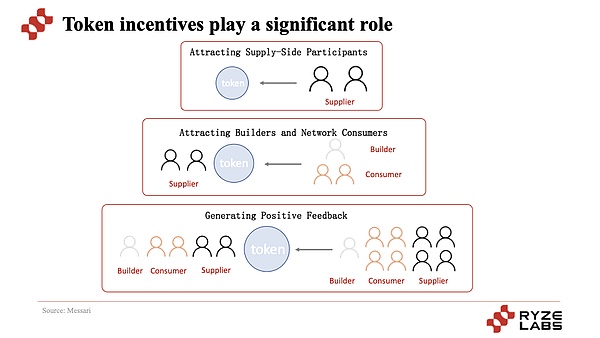
النوع الآخر هو استخدام قوة الحوسبة اللامركزية لتدريب الذكاء الاصطناعي، مثل Gensyn وio.net (يمكن دعم كل من تدريب الذكاء الاصطناعي واستدلال الذكاء الاصطناعي). في الواقع، لا يختلف منطق التشغيل لهذا النوع من المشاريع بشكل أساسي عن منطق مشاريع الذكاء الاصطناعي، فهو لا يزال يستخدم حوافز رمزية لجذب مشاركة جانب العرض لتوفير القدرة الحاسوبية لاستخدامها من قبل جانب الطلب.
باعتبارها شبكة طاقة حوسبة لا مركزية، تمتلك io.net حاليًا أكثر من 500000 وحدة معالجة رسوميات وقد حققت أداءً جيدًا جدًا في مشاريع طاقة الحوسبة اللامركزية بالإضافة إلى قوة الحوسبة تم دمج Render وfilecoin، وتم تطوير المشاريع البيئية بشكل مستمر.

بالإضافة إلى ذلك، تطبق Gensyn التدريب على الذكاء الاصطناعي من خلال تعزيز تخصيص المهام والمكافآت للتعلم الآلي من خلال العقود الذكية. كما هو موضح في الشكل أدناه، تبلغ تكلفة التدريب على التعلم الآلي في Gensyn حوالي 0.40 دولارًا أمريكيًا في الساعة، وهو أقل بكثير من التكلفة التي تزيد عن 2 دولار أمريكي لـ AWS وGCP.
يتضمن نظام Gensyn أربعة كيانات مشاركة: مقدمو الطلبات، والمنفذون، والمتحققون، والمراسلون.
المرسل: المستخدم المتطلب هو مستهلك المهمة، ويقدم المهمة المراد حسابها , الدفع مقابل مهام التدريب على الذكاء الاصطناعي
المنفذ: يقوم المنفذ بمهمة تدريب النموذج وينشئ دليلاً على إكمال المهمة للتحقق منها تفتيش الشخص.
المدقق: يربط عملية التدريب غير الحتمية بالحساب الخطي الحتمي، ويحاذي دليل المنفذ مع العتبات المتوقعة للمقارنة.
المبلغ عن المخالفات: تحقق من عمل المدقق واكسب المال عن طريق طرح الأسئلة عند اكتشاف المشاكل.
يمكن ملاحظة أن Gensyn يأمل أن يصبح بروتوكول حوسبة واسع النطاق وفعال من حيث التكلفة لنماذج التعلم العميق العالمية . ولكن بالنظر إلى هذا المسار، لماذا تختار معظم المشاريع قوة الحوسبة اللامركزية لاستنتاج الذكاء الاصطناعي بدلاً من التدريب؟
هنا أيضًا نساعد الأصدقاء الذين لا يفهمون تدريب الذكاء الاصطناعي واستدلاله على تقديم الفرق بين الاثنين:
تدريب الذكاء الاصطناعي: إذا قارنا الذكاء الاصطناعي بالطالب، فإن التدريب يشبه توفير كمية كبيرة من المعرفة إلى الذكاء الاصطناعي، يمكن أيضًا فهم الأمثلة على أنها ما نسميه غالبًا البيانات، ويتعلم الذكاء الاصطناعي من هذه الأمثلة المعرفية. وبما أن طبيعة التعلم تتطلب فهم وحفظ كميات كبيرة من المعلومات، فإن هذه العملية تتطلب الكثير من القوة الحاسوبية والوقت.
استدلال الذكاء الاصطناعي: إذن ما هو الاستدلال؟ يمكن فهمها على أنها استخدام المعرفة المكتسبة لحل المشكلات أو إجراء الاختبارات. في مرحلة الاستدلال، يستخدم الذكاء الاصطناعي المعرفة المكتسبة لحل المشكلات بدلاً من استخدام المعرفة الجديدة، وبالتالي فإن مقدار العمليات الحسابية المطلوبة في عملية الاستدلال صغير.
يمكن ملاحظة أن متطلبات الطاقة الحاسوبية لكل منهما مختلفة تمامًا فيما يتعلق بتطبيق قوة الحوسبة اللامركزية في الذكاء الاصطناعي سيتم تحليل المنطق وسهولة الاستخدام فيما يتعلق بتدريب الذكاء الاصطناعي بمزيد من التعمق في فصل التحديات اللاحق.
بالإضافة إلى ذلك، تأمل Ritual في الجمع بين الشبكات الموزعة ومنشئي النماذج للحفاظ على اللامركزية والأمن. منتجها الأول، Infernet، يمكّن العقود الذكية على blockchain من الوصول إلى نماذج الذكاء الاصطناعي خارج السلسلة، مما يسمح لهذه العقود بالوصول إلى الذكاء الاصطناعي بطريقة تحافظ على التحقق واللامركزية وحماية الخصوصية.
يتولى منسق Infernet مسؤولية إدارة سلوك العقد في الشبكة والاستجابة لطلبات الحوسبة الصادرة عن المستهلكين. عندما يستخدم المستخدمون الاستدلال، سيتم وضع الاستدلال والإثبات والأعمال الأخرى خارج السلسلة، وسيتم إرجاع نتائج المخرجات إلى المنسق ونقلها أخيرًا إلى المستهلكين على السلسلة من خلال العقود.
بالإضافة إلى شبكات طاقة الحوسبة اللامركزية، هناك أيضًا شبكات عرض النطاق الترددي اللامركزية مثل Grass لتحسين سرعة وكفاءة نقل البيانات. بشكل عام، يوفر ظهور شبكات الطاقة الحاسوبية اللامركزية إمكانية جديدة لجانب إمداد الطاقة الحاسوبية للذكاء الاصطناعي، مما يدفع الذكاء الاصطناعي إلى المضي قدمًا في اتجاه إضافي.
3.1.2 نموذج الخوارزمية اللامركزية
كما ذكرنا في الفصل الثاني، العناصر الأساسية الثلاثة للذكاء الاصطناعي هي قوة الحوسبة والخوارزميات والبيانات. نظرًا لأن قوة الحوسبة يمكن أن تشكل شبكة إمداد من خلال اللامركزية، فهل يمكن للخوارزميات أيضًا أن يكون لديها فكرة مماثلة وتشكل شبكة إمداد لنماذج الخوارزمية؟
قبل تحليل مشروع المسار، دعونا أولاً نفهم معنى نموذج الخوارزمية اللامركزية، سيكون الكثير من الناس فضوليين، نظرًا لوجود OpenAI بالفعل، فلماذا تفعل ذلك؟ هل ما زلت بحاجة إلى شبكة خوارزمية لامركزية؟
في الأساس، شبكة الخوارزمية اللامركزية هي سوق خدمات خوارزمية ذكاء اصطناعي لامركزي يربط العديد من نماذج الذكاء الاصطناعي المختلفة بناءً على المعرفة والمهارات التي تتمتع بها عندما يطرح المستخدمون أسئلة، سيختار السوق نموذج الذكاء الاصطناعي الأكثر ملاءمة للإجابة على الأسئلة لتقديم الإجابات. Chat-GPT هو نموذج للذكاء الاصطناعي تم تطويره بواسطة OpenAI يمكنه فهم وإنتاج نص يشبه الإنسان.
ببساطة، ChatGPT يشبه الطالب القادر جدًا على المساعدة في حل أنواع مختلفة من المشكلات، في حين أن شبكة الخوارزمية اللامركزية تشبه الشبكة التي تضم العديد من الطلاب الذين تأتي المدارس إليهم على الرغم من أن الطلاب الحاليين يتمتعون بقدرات كبيرة، إلا أن المدارس التي يمكنها تجنيد الطلاب من جميع أنحاء العالم تتمتع بإمكانات كبيرة على المدى الطويل.
في الوقت الحاضر، في مجال نماذج الخوارزمية اللامركزية، هناك أيضًا بعض المشاريع التي تتم تجربتها واستكشافها. بعد ذلك، سيتم استخدام المشروع التمثيلي Bittensor كحالة لمساعدة الجميع على فهم تطور هذا المجال المقسم.
في Bittensor، يساهم جانب العرض في نموذج الخوارزمية (أو القائمين بالتعدين) بنموذج التعلم الآلي الخاص بهم في الشبكة. يمكن لهذه النماذج تحليل البيانات وتقديم رؤى. تتم مكافأة موفري النماذج برموز العملة المشفرة TAO مقابل مساهماتهم.
من أجل ضمان جودة الإجابات على الأسئلة، يستخدم Bittensor آلية إجماع فريدة لضمان وصول الشبكة إلى توافق في الآراء بشأن أفضل إجابة. عندما يتم طرح سؤال، يقدم عمال المناجم النموذجيون المتعددون الإجابات. يقوم المدققون في الشبكة بعد ذلك بالعمل على تحديد أفضل إجابة وإرسالها مرة أخرى إلى المستخدم.
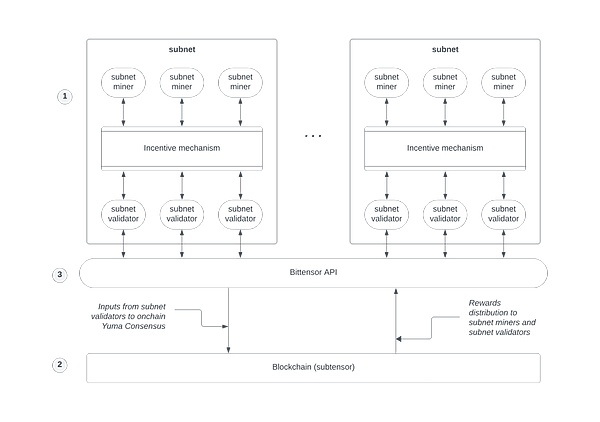
يلعب رمز Bittensor TAO بشكل أساسي دورين في العملية برمتها. من ناحية، يتم استخدامه لتشجيع القائمين بالتعدين على المساهمة بنماذج الخوارزمية في الشبكة. ومن ناحية أخرى، يحتاج المستخدمون إلى إنفاق الرموز المميزة لطرح الأسئلة والسماح مهام الشبكة كاملة.
نظرًا لأن Bittensor لا مركزي، يمكن لأي شخص لديه إمكانية الوصول إلى الإنترنت الانضمام إلى الشبكة، سواء كمستخدم يطرح أسئلة أو كمزود لإجابات القائمين بالتعدين. وهذا يجعل الذكاء الاصطناعي القوي في متناول عدد أكبر من الأشخاص.
باختصار، إذا أخذنا شبكات مثل Bittensor كمثال، فإن مجال نماذج الخوارزمية اللامركزية لديه القدرة على خلق موقف أكثر انفتاحًا وشفافية في هذا النظام البيئي يمكن تدريب نماذج الذكاء الاصطناعي ومشاركتها والاستفادة منها بطريقة آمنة ولا مركزية. بالإضافة إلى ذلك، هناك شبكات نموذجية خوارزمية لامركزية مثل BasedAI تحاول أشياء مماثلة. بالطبع، الجزء الأكثر إثارة للاهتمام هو استخدام ZK لحماية خصوصية بيانات المستخدمين الذين يتفاعلون مع النموذج.
مع تطور منصات النماذج الخوارزمية اللامركزية، سيكون لها تأثير على مختلف الصناعات من خلال تمكين الشركات الصغيرة من التنافس مع المؤسسات الأكبر في استخدام أدوات الذكاء الاصطناعي المتطورة. تأثير كبير محتمل.
3.1.3 جمع البيانات اللامركزية
من أجل والتدريب على نماذج الذكاء الاصطناعي، يعد توفير كمية كبيرة من البيانات أمرًا ضروريًا. ومع ذلك، لا تزال معظم شركات web2 حاليًا تحتفظ ببيانات المستخدم كبيانات خاصة بها، حيث تحظر منصات مثل X وReddit وTikTok وSnapchat وInstagram وYouTube جمع البيانات للتدريب على الذكاء الاصطناعي. لقد أصبح عقبة كبيرة أمام تطوير صناعة الذكاء الاصطناعي.
من ناحية أخرى، تبيع بعض منصات Web2 بيانات المستخدم لشركات الذكاء الاصطناعي دون مشاركة أي أرباح للمستخدمين. على سبيل المثال، أبرم موقع Reddit صفقة بقيمة 60 مليون دولار مع Google لتدريب نماذج الذكاء الاصطناعي على منشوراته. ونتيجة لذلك، فإن الحق في جمع البيانات يشغله رأس المال الكبير وأطراف البيانات الضخمة، مما يؤدي إلى تطوير الصناعة في اتجاه كثيف رأس المال.
في مواجهة هذا الوضع الحالي، قامت بعض المشاريع بدمج Web3 مع حوافز رمزية لتحقيق جمع لا مركزي للبيانات. بأخذ PublicAI كمثال، يمكن للمستخدمين المشاركة كنوعين من الأدوار في PublicAI:
واحد النوع هو مزود لبيانات الذكاء الاصطناعي ويمكن للمستخدمين العثور على محتوى قيم عليه
النوع الآخر هو أدوات التحقق من البيانات. يمكن للمستخدمين تسجيل الدخول إلى مركز بيانات PublicAI واختيار البيانات الأكثر قيمة للتدريب على الذكاء الاصطناعي تصويت. .
في المقابل، يمكن للمستخدمين الحصول على حوافز رمزية من خلال هذين النوعين من المساهمات، وبالتالي تعزيز المساهمين في البيانات والذكاء الاصطناعي. علاقة الفوز بين التنمية الصناعية.
بالإضافة إلى مشاريع مثل PublicAI المتخصصة في جمع البيانات للتدريب على الذكاء الاصطناعي، هناك العديد من المشاريع التي تجمع أيضًا بيانات لا مركزية من خلال الحوافز الرمزية، على سبيل المثال، Ocean يجمع بيانات المستخدم من خلال ترميز البيانات لخدمة الذكاء الاصطناعي، ويجمع Hivemapper بيانات الخرائط من خلال كاميرات سيارات المستخدمين، ويجمع Dimo بيانات سيارات المستخدمين، ويجمع WiHi بيانات الطقس وما إلى ذلك، ويتم جمعها من خلال مشاريع البيانات اللامركزية وهي أيضًا جانب العرض التدريب المحتمل على الذكاء الاصطناعي، لذلك بالمعنى الواسع، يمكن أيضًا تضمينها في نموذج Web3 لمساعدة الذكاء الاصطناعي.
3.1.4 يحمي ZK خصوصية المستخدم في الذكاء الاصطناعي
بالإضافة إلى مزايا اللامركزية التي توفرها تقنية blockchain، هناك ميزة أخرى مهمة جدًا وهي إثبات المعرفة الصفرية. ومن خلال تكنولوجيا المعرفة الصفرية، يمكن التحقق من المعلومات مع حماية الخصوصية.
في التعلم الآلي التقليدي، عادةً ما تحتاج البيانات إلى تخزينها ومعالجتها مركزيًا، مما قد يؤدي إلى خطر تسرب خصوصية البيانات. ومن ناحية أخرى، فإن طرق حماية خصوصية البيانات، مثل تشفير البيانات أو إلغاء تحديد هوية البيانات، قد تحد من دقة وأداء نماذج التعلم الآلي.
يمكن أن تساعد تقنية إثبات المعرفة الصفرية في مواجهة هذه المعضلة وحل التعارض بين حماية الخصوصية ومشاركة البيانات.
يسمح ZKML (التعلم الآلي ذو المعرفة الصفرية) بالتدريب والاستدلال على نماذج التعلم الآلي دون تسريب البيانات الأصلية باستخدام تقنية إثبات المعرفة الصفرية. تسمح إثباتات المعرفة الصفرية بإثبات صحة ميزات البيانات ونتائج النماذج دون الكشف عن محتوى البيانات الفعلي.
الهدف الأساسي لـ ZKML هو تحقيق التوازن بين حماية الخصوصية ومشاركة البيانات. ويمكن تطبيقه على سيناريوهات مختلفة، مثل تحليل البيانات الطبية والصحية، وتحليل البيانات المالية والتعاون بين المنظمات. باستخدام ZKML، يمكن للأفراد حماية خصوصية بياناتهم الحساسة أثناء مشاركتها مع الآخرين للحصول على رؤى أوسع وفرص للتعاون، دون القلق بشأن مخاطر انتهاكات خصوصية البيانات.
لا يزال هذا المجال في مراحله الأولى، ولا تزال معظم المشاريع قيد الاستكشاف، على سبيل المثال، اقترحت BasedAI طريقة لا مركزية تجمع بين FHE وLLM للحفاظ على سرية البيانات. الاستفادة من نماذج اللغات الكبيرة ذات المعرفة الصفرية (ZK-LLM) لتضمين الخصوصية في قلب البنية التحتية للشبكة الموزعة، مما يضمن بقاء بيانات المستخدم خاصة طوال تشغيل الشبكة.
إليك شرحًا موجزًا لماهية التشفير المتماثل بالكامل (FHE). التشفير المتماثل بالكامل هو تقنية تشفير تسمح بإجراء العمليات الحسابية على البيانات في حالة مشفرة دون الحاجة إلى فك التشفير. وهذا يعني أنه يمكن إجراء العمليات الحسابية المختلفة (مثل الجمع والضرب وما إلى ذلك) على البيانات المشفرة باستخدام FHE مع الحفاظ على الحالة المشفرة للبيانات والحصول على نتائج نفس العمليات التي يتم إجراؤها على البيانات الأصلية غير المشفرة، وهذا يحمي خصوصية بيانات المستخدم.
بالإضافة إلى الفئات الأربع المذكورة أعلاه، فيما يتعلق بمساعدة Web3 للذكاء الاصطناعي، هناك أيضًا مشاريع blockchain مثل Cortex التي تدعم تنفيذ برامج الذكاء الاصطناعي على السلسلة. حاليًا، أحد التحديات التي تواجه تنفيذ برامج التعلم الآلي على سلاسل الكتل التقليدية هو أن الأجهزة الافتراضية غير فعالة للغاية عند تشغيل أي نماذج تعلم آلي غير معقدة. لذلك، يعتقد معظم الناس أن تشغيل الذكاء الاصطناعي على blockchain أمر مستحيل. يستخدم Cortex Virtual Machine (CVM) وحدة معالجة الرسومات (GPU) لتنفيذ برامج الذكاء الاصطناعي على السلسلة وهو متوافق مع EVM. بمعنى آخر، يمكن لسلسلة Cortex تنفيذ جميع تطبيقات Ethereum Dapps ودمج التعلم الآلي للذكاء الاصطناعي في هذه التطبيقات اللامركزية بناءً على ذلك. يتيح ذلك تشغيل نماذج التعلم الآلي بطريقة لا مركزية وغير قابلة للتغيير وشفافة لأن إجماع الشبكة يتحقق من صحة كل خطوة من خطوات تفكير الذكاء الاصطناعي.
3.2 الذكاء الاصطناعي يساعد الويب3
في الذكاء الاصطناعي وWeb3 في الاصطدام، بالإضافة إلى مساعدة Web3 للذكاء الاصطناعي، فإن مساعدة الذكاء الاصطناعي لصناعة Web3 تستحق الاهتمام أيضًا. المساهمة الأساسية للذكاء الاصطناعي هي تحسين الإنتاجية، لذلك هناك العديد من المحاولات في الذكاء الاصطناعي لتدقيق العقود الذكية، وتحليل البيانات والتنبؤ بها، والخدمات الشخصية، والأمن وحماية الخصوصية، وما إلى ذلك.
3.2.1 تحليل البيانات والتنبؤ بها
موجود حاليًا بدأ مشروع Web3 في دمج خدمات الذكاء الاصطناعي الحالية (مثل ChatGPT) أو البحث الذاتي لتوفير خدمات تحليل البيانات والتنبؤ لمستخدمي Web3. التغطية واسعة جدًا، بما في ذلك توفير استراتيجيات الاستثمار من خلال خوارزميات الذكاء الاصطناعي، وأدوات الذكاء الاصطناعي للتحليل عبر السلسلة، وتنبؤات الأسعار والسوق، وما إلى ذلك.
على سبيل المثال، يستخدم Pond خوارزميات الرسم البياني للذكاء الاصطناعي للتنبؤ برموز ألفا القيمة المستقبلية وتقديم مشورة المساعدة الاستثمارية للمستخدمين والمؤسسات وBullBear AI استنادًا إلى بيانات سجل المستخدم ويتم تدريب سجل خط الأسعار واتجاهات السوق لتوفير المعلومات الأكثر دقة لدعم التنبؤ باتجاهات الأسعار لمساعدة المستخدمين على تحقيق الإيرادات والأرباح.
هناك أيضًا منصات منافسة استثمارية مثل Numerai، حيث يتنبأ المشاركون بسوق الأوراق المالية بناءً على الذكاء الاصطناعي ونماذج اللغات الكبيرة، ويستخدمون المنصة لتقديم جودة عالية مجانًا التدريب على البيانات وتقديم التوقعات يوميا. يقوم Numerai بحساب كيفية أداء هذه التنبؤات خلال الشهر التالي، ويمكن للمشاركين مشاركة الرنين المغناطيسي النووي (NMR) في النموذج لكسب مكافآت بناءً على أداء النموذج.
بالإضافة إلى ذلك، هناك منصات لتحليل البيانات على السلسلة مثل Arkham والتي تجمع أيضًا بين الذكاء الاصطناعي لتقديم الخدمات. تقوم Arkham بربط عناوين blockchain مع كيانات مثل البورصات والصناديق والحيتان، وتعرض البيانات الأساسية والتحليلات لهذه الكيانات للمستخدمين لتزويد المستخدمين بمزايا صنع القرار. الجزء الذي يجمعها مع الذكاء الاصطناعي هو أن Arkham Ultra يستخدم الخوارزميات لمطابقة العناوين مع كيانات العالم الحقيقي. وقد تم تطويره بواسطة المساهمين الأساسيين في Arkham على مدى ثلاث سنوات بدعم من مؤسسي Palantir وOpenAI.
3.2.2 الخدمة المخصصة
في Web2 في المشروع، لدى الذكاء الاصطناعي العديد من سيناريوهات التطبيق في مجالات البحث والتوصية، مما يخدم الاحتياجات الشخصية للمستخدمين. وينطبق الشيء نفسه على مشاريع Web3 حيث تعمل العديد من أطراف المشروع على تحسين تجربة المستخدم من خلال دمج الذكاء الاصطناعي.
على سبيل المثال، أطلقت شركة Dune، وهي منصة معروفة لتحليل البيانات، مؤخرًا أداة Wand، والتي تُستخدم لكتابة استعلامات SQL بمساعدة نماذج اللغة الكبيرة . من خلال وظيفة Wand Create، يمكن للمستخدمين إنشاء استعلامات SQL تلقائيًا بناءً على أسئلة اللغة الطبيعية، بحيث يمكن للمستخدمين الذين لا يفهمون SQL أيضًا البحث بشكل مريح للغاية.
بالإضافة إلى ذلك، بدأت بعض منصات محتوى Web3 أيضًا في دمج ChatGPT لملخص المحتوى. على سبيل المثال، قامت منصة الوسائط Web3 Followin بدمج ChatGPT لتلخيص آراء أ مسار معين وأحدث حالة؛ تلتزم منصة موسوعة Web3 IQ.wiki بأن تصبح المصدر الرئيسي لجميع المعرفة الموضوعية وعالية الجودة المتعلقة بتكنولوجيا blockchain والعملات المشفرة على الإنترنت، مما يجعل اكتشاف blockchain والوصول إليه عالميًا أسهل. تزويد المستخدمين بالمعلومات التي يمكنهم الوثوق بها، كما أنه يدمج GPT-4 لتلخيص مقالات الويكي، ويلتزم Kaito، وهو محرك بحث يعتمد على LLM، بأن يصبح منصة بحث Web3 وتغيير الطريقة التي يحصل بها Web3 على المعلومات؛
فيما يتعلق بالإنشاء، هناك أيضًا مشاريع مثل NFPrompt التي تقلل تكاليف إنشاء المستخدم. يسمح NFPrompt للمستخدمين بإنشاء NFT بسهولة أكبر من خلال الذكاء الاصطناعي، وبالتالي تقليل تكاليف الإنشاء للمستخدمين وتوفير العديد من الخدمات الشخصية أثناء الإنشاء.
3.2.3 العقد الذكي لتدقيق الذكاء الاصطناعي
في Web3 في هذا المجال، تعد مراجعة العقود الذكية أيضًا مهمة مهمة جدًا. يمكن أن يؤدي استخدام الذكاء الاصطناعي لتدقيق رموز العقود الذكية إلى تحديد الثغرات في الكود وإيجادها بشكل أكثر كفاءة ودقة.
كما ذكر فيتاليك ذات مرة، فإن أحد أكبر التحديات التي تواجه مجال العملات المشفرة هو الأخطاء في التعليمات البرمجية لدينا. أحد الاحتمالات الواعدة هو أن الذكاء الاصطناعي (AI) يمكن أن يبسط بشكل كبير استخدام أدوات التحقق الرسمية لإثبات أن مجموعات التعليمات البرمجية تلبي خصائص محددة. إذا كان من الممكن القيام بذلك، فسيكون من الممكن بالنسبة لنا الحصول على SEK EVM خاليًا من الأخطاء (مثل جهاز Ethereum الظاهري). كلما قللت عدد الأخطاء، أصبحت المساحة أكثر أمانًا، والذكاء الاصطناعي مفيد جدًا في تحقيق ذلك.
على سبيل المثال، يوفر مشروع 0x0.ai مدقق عقود ذكي يعمل بالذكاء الاصطناعي، والذي يستخدم خوارزميات متقدمة لتحليل العقود الذكية وتحديد الأخطاء التي قد تؤدي إلى الاحتيال أو أدوات للمخاطر الأمنية الأخرى لنقاط الضعف أو المشكلات المحتملة. يستخدم المدققون تكنولوجيا التعلم الآلي لتحديد الأنماط والجوانب الشاذة في التعليمات البرمجية، والإبلاغ عن المشكلات المحتملة لمزيد من المراجعة.
بالإضافة إلى الفئات الثلاث المذكورة أعلاه، هناك أيضًا بعض الحالات الأصلية التي تستخدم الذكاء الاصطناعي لمساعدة مجال Web3. على سبيل المثال، تساعد PAAL المستخدمين على إنشاء روبوتات AI مخصصة التي يمكن نشرها على Telegram وDiscord لخدمة مستخدمي Web3، وهي عبارة عن مجمع dex متعدد السلاسل يعتمد على الذكاء الاصطناعي، ويستخدم الذكاء الاصطناعي لتوفير أكبر مجموعة من الرموز المميزة وأفضل مسار للمعاملات بين أي أزواج من الرموز المميزة بشكل عام يساعد Web3 على أن يصبح أكثر، ويعمل معظمها كمساعدة على مستوى الأداة.
4.1 عقبات واقعية في قوة الحوسبة اللامركزية
جزء كبير من مشاريع Web3 الحالية لمساعدة الذكاء الاصطناعي إنه ابتكار مثير للاهتمام للغاية يجب التركيز عليه على قوة الحوسبة اللامركزية وتشجيع المستخدمين العالميين على أن يصبحوا جانب إمداد الطاقة الحاسوبية من خلال الحوافز الرمزية، ومع ذلك، من ناحية أخرى، يواجه أيضًا بعض المشكلات العملية التي تحتاج إلى حل:
مقارنة بموفري خدمات طاقة الحوسبة المركزية، تعتمد منتجات طاقة الحوسبة اللامركزية عادةً على العقد والمشاركين الموزعين حول العالم لتوفير موارد الحوسبة. نظرًا لأن اتصالات الشبكة بين هذه العقد قد تتعرض للتأخير وعدم الاستقرار، فقد يكون الأداء والاستقرار أسوأ من منتجات الحوسبة المركزية.
بالإضافة إلى ذلك، يتأثر توفر منتجات طاقة الحوسبة اللامركزية بالتوافق بين العرض والطلب. إذا لم يكن هناك ما يكفي من الموردين أو كان الطلب مرتفعًا جدًا، فقد لا تكون هناك موارد كافية أو عدم القدرة على تلبية احتياجات المستخدمين.
أخيرًا، تتضمن منتجات طاقة الحوسبة اللامركزية عادةً تفاصيل فنية وتعقيدًا أكثر من منتجات طاقة الحوسبة المركزية. قد يحتاج المستخدمون إلى فهم الشبكات الموزعة والعقود الذكية ومدفوعات العملات المشفرة والتعامل معها، وستصبح تكلفة فهمها واستخدامها أعلى.
بعد مناقشات متعمقة مع عدد كبير من مشاريع طاقة الحوسبة اللامركزية، وجدنا أن قوة الحوسبة اللامركزية الحالية تقتصر أساسًا على استدلال الذكاء الاصطناعي بدلاً من الذكاء الاصطناعي. يدرب.
بعد ذلك، سأساعدك على فهم الأسباب الكامنة وراء ذلك من خلال أربعة أسئلة صغيرة:
1. لماذا تختار معظم مشاريع الطاقة الحاسوبية اللامركزية القيام باستدلال الذكاء الاصطناعي بدلاً من التدريب على الذكاء الاصطناعي؟
2. أين تعتبر Nvidia رائعة جدًا؟ ما هو سبب صعوبة القيام بالتدريب اللامركزي على قوة الحوسبة؟
3. ما هي نتيجة قوة الحوسبة اللامركزية (Render وAkash وio.net وما إلى ذلك)؟
4. ما هي نتيجة الخوارزمية اللامركزية (Bittensor)؟
بعد ذلك، لنزيل الشرنقة طبقة تلو الأخرى:
1 ) النظر إلى هذا على المسار الصحيح، تختار معظم مشاريع الطاقة الحاسوبية اللامركزية إجراء استنتاجات الذكاء الاصطناعي بدلاً من التدريب يكمن الجوهر في المتطلبات المختلفة لقوة الحوسبة وعرض النطاق الترددي.
لمساعدة الجميع على الفهم بشكل أفضل، دعونا نقارن الذكاء الاصطناعي بالطالب:
تدريب الذكاء الاصطناعي: إذا قارنا الذكاء الاصطناعي بالطالب، فإن التدريب يشبه تزويد الذكاء الاصطناعي بكمية كبيرة من المعرفة والأمثلة، والتي يمكن فهمها أيضًا على أنها ما نطلق عليه غالبًا البيانات، ويتعلم الذكاء الاصطناعي من هذه الأمثلة المعرفية. وبما أن طبيعة التعلم تتطلب فهم وحفظ كميات كبيرة من المعلومات، فإن هذه العملية تتطلب الكثير من القوة الحاسوبية والوقت.
استدلال الذكاء الاصطناعي: إذن ما هو الاستدلال؟ يمكن فهمها على أنها استخدام المعرفة المكتسبة لحل المشكلات أو إجراء الاختبارات. في مرحلة الاستدلال، يستخدم الذكاء الاصطناعي المعرفة المكتسبة لحل المشكلات بدلاً من استخدام المعرفة الجديدة، وبالتالي فإن مقدار العمليات الحسابية المطلوبة في عملية الاستدلال صغير.
من السهل أن تجد أن فرق الصعوبة بين الاثنين يكمن أساسًا في الكم الهائل من البيانات المطلوبة لتدريب نماذج الذكاء الاصطناعي الكبيرة ومتطلبات النطاق الترددي العالي للغاية لـ اتصالات البيانات عالية السرعة، لذلك من الصعب للغاية تنفيذ قوة الحوسبة اللامركزية للتدريب. الاستدلال له متطلبات أصغر بكثير للبيانات وعرض النطاق الترددي، ومن المرجح أن يتم تنفيذه.
بالنسبة للنماذج الكبيرة، فإن الشيء الأكثر أهمية هو الاستقرار. في حالة انقطاع التدريب، يلزم إعادة التدريب، وتكون التكلفة الغارقة مرتفعة. من ناحية أخرى، يمكن تحقيق المتطلبات التي تتطلب قوة حاسوبية منخفضة نسبيًا، مثل استنتاج الذكاء الاصطناعي المذكور أعلاه، أو التدريب على النماذج الصغيرة والمتوسطة الحجم في بعض السيناريوهات المحددة. في اللامركزية، يوجد بعض موفري خدمات العقد الكبيرة نسبيًا شبكة الطاقة الحاسوبية التي يمكنها تلبية احتياجات الطاقة الحاسوبية الكبيرة نسبيًا.
2) إذن أين هي النقطة العالقة للبيانات وعرض النطاق الترددي؟ لماذا يصعب تحقيق التدريب اللامركزي؟
يتضمن ذلك عنصرين رئيسيين للتدريب على النماذج الكبيرة: قوة الحوسبة ذات البطاقة الواحدة والاتصال المتوازي متعدد البطاقات.
قوة الحوسبة ذات البطاقة الواحدة: حاليًا، تسمى جميع المراكز التي تحتاج إلى تدريب نماذج كبيرة بمراكز الحوسبة الفائقة. من أجل تسهيل فهم الجميع، يمكننا استخدام جسم الإنسان كاستعارة، حيث أن مركز الحوسبة الفائقة هو أنسجة جسم الإنسان، والوحدة الأساسية GPU هي الخلية. إذا كانت قوة الحوسبة لخلية واحدة (GPU) قوية جدًا، فقد تكون قوة الحوسبة الإجمالية (خلية واحدة × رقم) قوية جدًا أيضًا.
الاتصال المتوازي متعدد البطاقات: غالبًا ما يكلف تدريب نموذج كبير مئات المليارات من الجيجابايت بالنسبة لمراكز الحوسبة الفائقة التي تدرب نماذج كبيرة، على الأقل 10000 مستوى هناك حاجة إلى قاعدة A100. لذلك، يجب تعبئة عشرات الآلاف من البطاقات للتدريب. ومع ذلك، فإن تدريب النماذج الكبيرة ليس سلسلة بسيطة. وهذا لا يعني التدريب على البطاقة الأولى A100 ثم التدريب على البطاقة الثانية النماذج جزئيًا، عند التدريب على بطاقات رسومية مختلفة، قد تكون هناك حاجة لنتائج B عند التدريب A، لذلك يتم تضمين التوازي متعدد البطاقات.
لماذا تتمتع NVIDIA بهذه القوة وترتفع قيمتها السوقية، بينما تواجه AMD وHuawei وHorizon المحليتان حاليًا صعوبة في اللحاق بالركب. الجوهر ليس قوة الحوسبة ذات البطاقة الواحدة بحد ذاتها، ولكنه يكمن في جانبين: بيئة برامج CUDA واتصال NVLink متعدد البطاقات.
من ناحية، من المهم جدًا أن يكون لديك نظام بيئي برمجي يمكنه التكيف مع الأجهزة، مثل نظام CUDA الخاص بـ NVIDIA، وبناء النظام الجديد أمر صعب، مثل بناء لغة جديدة، وتكلفة الاستبدال مرتفعة جدًا.
من ناحية أخرى، فهو اتصال متعدد البطاقات، في جوهره، يعد النقل بين البطاقات المتعددة بمثابة إدخال وإخراج المعلومات، وكيفية الاتصال بالتوازي وكيفية الإرسال. وبسبب وجود NVLink، لا توجد طريقة لتوصيل بطاقات NVIDIA وAMD بالإضافة إلى ذلك، سيحد NVLink من المسافة المادية بين بطاقات الرسومات ويتطلب أن تكون بطاقات الرسومات في نفس مركز الحوسبة الفائقة، مما يؤدي إلى وجود قوة حوسبة لا مركزية؛ توزيعها في جميع أنحاء العالم هو أكثر صعوبة في تحقيقه.
تشرح النقطة الأولى سبب صعوبة اللحاق بشركتي AMD وHuawei المحليتين وHorizon حاليًا؛ وتشرح النقطة الثانية سبب صعوبة تحقيق التدريب اللامركزي.
3) ما هي نتيجة قوة الحوسبة اللامركزية؟
من الصعب حاليًا تدريب النماذج الكبيرة على قوة الحوسبة اللامركزية. والجوهر هو أن الشيء الأكثر أهمية في تدريب النماذج الكبيرة هو الاستقرار تمت مقاطعته، فمن الضروري إعادة التدريب، والتكاليف الغارقة مرتفعة. متطلبات الاتصال المتوازي لبطاقات متعددة عالية جدًا، وعرض النطاق الترددي محدود بالمسافة المادية. تستخدم NVIDIA NVLink لتحقيق اتصال متعدد البطاقات، ومع ذلك، في مركز الحوسبة الفائقة، سيحد NVLink من المسافة المادية بين بطاقات الرسومات، لذلك لا يمكن لطاقة الحوسبة المشتتة أن تشكل مجموعة طاقة حاسوبية للتدريب على النماذج الكبيرة.
ولكن من ناحية أخرى، يمكن تحقيق المتطلبات التي تتطلب قوة حاسوبية منخفضة نسبيًا، مثل استدلال الذكاء الاصطناعي، أو التطبيقات العمودية الصغيرة والمتوسطة الحجم في بعض التطبيقات المحددة يكون التدريب النموذجي ممكنًا عندما يكون هناك بعض مقدمي خدمات العقد الكبيرة نسبيًا في شبكة طاقة الحوسبة اللامركزية، فإن ذلك لديه القدرة على تلبية احتياجات الطاقة الحاسوبية الكبيرة نسبيًا. ومن السهل نسبيًا تنفيذ سيناريوهات الحوسبة المتطورة مثل العرض.
4) ما هي نتيجة نموذج الخوارزمية اللامركزية؟
تعتمد نتيجة نموذج الخوارزمية اللامركزية على نتيجة الذكاء الاصطناعي المستقبلي، وأعتقد أنه قد يكون هناك 1-2 معارك للذكاء الاصطناعي في المستقبل. عمالقة النماذج المغلقة المصدر (مثل ChatGPT)، إلى جانب النموذج المزدهر، في هذا السياق، لا تحتاج منتجات طبقة التطبيق إلى الارتباط بنموذج واحد كبير، ولكن التعاون مع نماذج كبيرة متعددة في هذا السياق، فإن نموذج Bittensor رائع محتمل.
4.2 مزيج AI+Web3 صعب نسبيًا ولا يحقق نمط 1+1>2
من بين المشاريع الحالية التي تجمع بين Web3 والذكاء الاصطناعي، وخاصة مشاريع Web3 المدعومة بالذكاء الاصطناعي، لا تزال معظم المشاريع تستخدم الذكاء الاصطناعي على السطح فقط ولا تعكس حقًا التكامل العميق بين الذكاء الاصطناعي والعملات المشفرة. وينعكس هذا التطبيق السطحي بشكل رئيسي في الجانبين التاليين:
أولاً، سواء كان ذلك يستخدم سواء تم استخدام الذكاء الاصطناعي لتحليل البيانات والتنبؤ بها، سواء تم استخدامه في سيناريوهات التوصية والبحث، أو لتدقيق التعليمات البرمجية، فلا يوجد فرق كبير بين مجموعة مشاريع Web2 والذكاء الاصطناعي. تستخدم هذه المشاريع ببساطة الذكاء الاصطناعي لتحسين الكفاءة والتحليل، ولا تُظهر التكامل الأصلي والحلول المبتكرة بين الذكاء الاصطناعي والعملات المشفرة.
ثانيًا، إن تكامل العديد من فرق Web3 مع الذكاء الاصطناعي يدور حول الاستفادة البحتة من مفهوم الذكاء الاصطناعي على مستوى التسويق. لقد استخدموا تقنية الذكاء الاصطناعي فقط في مجالات محدودة للغاية، ثم بدأوا في الترويج لاتجاه الذكاء الاصطناعي، مما خلق الوهم بأن المشروع يرتبط ارتباطًا وثيقًا بالذكاء الاصطناعي. ومع ذلك، فإن هذه المشاريع تترك فجوة كبيرة من حيث الابتكار الحقيقي.
على الرغم من هذه القيود المفروضة على مشاريع Web3 وAI الحالية، يجب أن ندرك أن هذه ليست سوى مرحلة مبكرة من التطوير. في المستقبل، يمكننا أن نتوقع المزيد من البحث والابتكار المتعمق لتحقيق تكامل أوثق بين الذكاء الاصطناعي والعملات المشفرة، وإنشاء المزيد من الحلول المحلية وذات المغزى في مجالات مثل التمويل، والمنظمات المستقلة اللامركزية، وأسواق التنبؤ، وخطة NFTs.
4.3 أصبحت اقتصاديات الرمز المميز حاجزًا لسرد مشاريع الذكاء الاصطناعي
كما ذكرنا في بداية مشكلة نموذج الأعمال لمشاريع الذكاء الاصطناعي، نظرًا لأن المزيد والمزيد من النماذج الكبيرة أصبحت مفتوحة المصدر تدريجيًا، فإن عددًا كبيرًا من مشاريع AI+Web3 غالبًا ما تكون مشاريع ذكاء اصطناعي خالصة يصعب تطويرها وتمويلها في Web2، لذلك اختاروا سرد Overlay Web3 واقتصاديات الرمز المميز لتحفيز مشاركة المستخدم.
لكن المفتاح الحقيقي هو ما إذا كان تكامل اقتصاديات الرمز المميز يمكن أن يساعد حقًا مشاريع الذكاء الاصطناعي في حل الاحتياجات الفعلية، أو ما إذا كان مجرد قيمة سردية أو قصيرة المدى الحقيقة هي أن هناك حاجة إلى علامة استفهام.
معظم مشاريع AI+Web3 الحالية بعيدة عن الوصول إلى المرحلة العملية ونأمل أن تستخدم المزيد من الفرق المتواضعة والمدروسة الرموز المميزة إن مشاريع الذكاء الاصطناعي ليست مجرد رموز، فهي وسيلة لبناء الزخم، ولكنها تلبي سيناريوهات الطلب الفعلي حقًا.
في الوقت الحالي، يحتوي مشروع AI+Web3 على وقد ظهرت العديد من الحالات والتطبيقات. بادئ ذي بدء، يمكن لتقنية الذكاء الاصطناعي توفير سيناريوهات تطبيق أكثر كفاءة وذكاءً لـ Web3. من خلال قدرات تحليل البيانات والتنبؤ بالذكاء الاصطناعي، يمكن أن يساعد مستخدمي Web3 في الحصول على أدوات أفضل في اتخاذ القرارات الاستثمارية والسيناريوهات الأخرى. بالإضافة إلى ذلك، يمكن للذكاء الاصطناعي أيضًا تدقيق رموز العقود الذكية، وتحسين عملية تنفيذ العقود الذكية، وتحسين الأداء والأداء من كفاءة blockchain. وفي الوقت نفسه، يمكن لتقنية الذكاء الاصطناعي أيضًا تقديم توصيات أكثر دقة وذكاءً وخدمات مخصصة للتطبيقات اللامركزية، مما يحسن تجربة المستخدم.
وفي الوقت نفسه، توفر ميزات اللامركزية وقابلية البرمجة في Web3 أيضًا فرصًا جديدة لتطوير تكنولوجيا الذكاء الاصطناعي. ومن خلال الحوافز الرمزية، توفر مشاريع قوة الحوسبة اللامركزية حلولاً جديدة لمعضلة نقص قوة حوسبة الذكاء الاصطناعي. كما توفر العقود الذكية وآليات التخزين الموزعة في Web3 منصة أوسع لمشاركة وتدريب خوارزميات الذكاء الاصطناعي. توفر آلية استقلالية المستخدم والثقة في Web3 أيضًا إمكانيات جديدة لتطوير الذكاء الاصطناعي. يمكن للمستخدمين اختيار المشاركة في مشاركة البيانات والتدريب، وبالتالي زيادة تنوع البيانات وجودتها وزيادة تحسين أداء ودقة نماذج الذكاء الاصطناعي.
على الرغم من أن المشروع المشترك الحالي لـ AI+Web3 لا يزال في مراحله الأولى ويواجه العديد من الصعوبات التي يجب مواجهتها، إلا أنه يجلب أيضًا العديد من المزايا. على سبيل المثال، تعاني منتجات الطاقة الحاسوبية اللامركزية من بعض أوجه القصور، ولكنها تقلل من الاعتماد على المؤسسات المركزية، وتوفر قدراً أعظم من الشفافية والقدرة على التدقيق، وتتيح المشاركة والابتكار على نطاق أوسع. بالنسبة لحالات استخدام واحتياجات مستخدم محددة، قد تكون منتجات طاقة الحوسبة اللامركزية خيارًا قيمًا، وينطبق الشيء نفسه عندما يتعلق الأمر بجمع البيانات، كما توفر مشاريع جمع البيانات اللامركزية بعض المزايا، مثل تقليل الاعتماد على مصدر بيانات واحد، تغطية أوسع للبيانات، وتعزيز تنوع البيانات وشمولها، من بين أمور أخرى. ومن الناحية العملية، يجب الموازنة بين هذه المزايا والعيوب واتخاذ التدابير الإدارية والفنية المقابلة للتغلب على التحديات لضمان أن يكون لمشاريع جمع البيانات اللامركزية تأثير إيجابي على تطوير الذكاء الاصطناعي.
بشكل عام، يوفر تكامل AI+Web3 إمكانيات غير محدودة للابتكار التكنولوجي المستقبلي والتنمية الاقتصادية. من خلال الجمع بين التحليل الذكي وقدرات اتخاذ القرار في الذكاء الاصطناعي مع اللامركزية واستقلالية المستخدم في Web3، نعتقد أنه يمكن بناء نظام اقتصادي وحتى اجتماعي أكثر ذكاءً وانفتاحًا وعدالة في المستقبل.
ارتفعت أسعار العملات المشفرة مؤخرًا ، ولكن في حين أن البعض متفائل بعودة المضاربين على العملة المشفرة ، يشعر آخرون أنها مجرد فخ ثور في سوق صاعدة. ما هو رأيك في هذا؟
Catherineقال مطورو المشروع إنهم سيعيدون شراء الرموز قريبًا.
 Others
Othersانخفض سعر SOL إلى أدنى مستوى له منذ مارس 2021.
 Beincrypto
Beincryptoيتم تداول APT داخل قناة موازية هبوطية.
Beincryptoيمكن لعملاء Voyager إرجاع 72٪ من الأموال.
Beincryptoوهو من أشد المؤمنين بنظام الرسوم البيانية وبدأ في توقع المسار الهبوطي لـ ADA في أوائل سبتمبر 2022.
BeincryptoSolana network faltered anew, as the crypto space's “Ethereum Killer” goes offline courtesy of faulty mechanics in its system.
 Bitcoinist
Bitcoinist NulltxNulltxNulltx
NulltxNulltxNulltx