NYDIG: إن انخفاض BTC الناجم عن بيع ألمانيا وMt.Gox وعمال المناجم مبالغ فيه
وقال جريج سيبولارو من NYDIG إن تحركات blockchain الأخيرة أثارت مخاوف "غير عقلانية"، مما يوفر للمستثمرين فرصة شراء.
 JinseFinance
JinseFinance

في عام 2022، كتبت (آنا) اقتراحًا لنموذج أساسي مملوك للمستخدم يستخدم البيانات الخاصة بدلاً من البيانات المستخرجة علنًا من الإنترنت لإجراء التدريب. أعتقد أنه على الرغم من أنه من الممكن تدريب النماذج الأساسية باستخدام البيانات العامة (مثل Wikipedia و4Chan)، إلا أنك تحتاج إلى بيانات خاصة عالية الجودة لنقلها إلى المستوى التالي، والتي لا توجد إلا عندما تكون الأذونات أو تسجيل الدخول مطلوبة للوصول إلى الأنظمة الأساسية المعزولة (مثل مثل تويتر، الرسائل الشخصية، معلومات الشركة).
بدأ هذا التوقع يتحقق. لقد أدركت شركات مثل ريديت وتويتر قيمة بيانات النظام الأساسي الخاصة بها، لذلك قامت بإغلاق واجهات برمجة التطبيقات الخاصة بالمطورين (1، 2) لمنع الشركات الأخرى من استخدام بياناتها النصية بحرية لتدريب النماذج الأساسية.
هذا تغيير كبير عما كان عليه قبل عامين. يلخص الرأسمالي المغامر سام ليسين التغيير قائلاً: "[المنصات] ترمي هذه الهراء في الخلف، دون مراقبة، ثم فجأة، تجد نفسك، يا إلهي، هذا الهراء من ذهب، أليس كذلك؟" يجب علينا قفل سلة المهملات." على سبيل المثال، تم تدريب GPT-3 على WebText2، الذي يجمع النص من جميع روابط التزام Reddit التي تحتوي على 3 تصويتات مؤيدة على الأقل (3، 4). مع واجهة برمجة تطبيقات Reddit الجديدة، لم يعد هذا ممكنًا.
أصبح الإنترنت أقل انفتاحًا، مع قيام المنصات المعزولة ببناء جدران أكبر من أي وقت مضى لحماية بيانات التدريب الثمينة الخاصة بها.
على الرغم من أن المطورين لم يعد بإمكانهم الوصول إلى هذه البيانات على نطاق واسع، إلا أنه لا يزال بإمكان الأفراد الوصول إلى بياناتهم الخاصة وتصديرها عبر الأنظمة الأساسية بسبب لوائح خصوصية البيانات (5، 6 ) . إن حقيقة قيام الأنظمة الأساسية بإغلاق واجهات برمجة تطبيقات المطورين، بينما لا يزال بإمكان المستخدمين الفرديين الوصول إلى بياناتهم الخاصة، تمثل فرصة: هل يمكن لـ 100 مليون مستخدم تصدير بيانات النظام الأساسي الخاصة بهم لإنشاء أكبر مجموعة من البيانات في العالم؟ ستقوم مجموعة البيانات هذه بتجميع جميع بيانات المستخدم التي جمعتها شركات التكنولوجيا الكبرى والشركات الأخرى، والتي غالبًا ما تكون مترددة في مشاركتها. وستكون هذه أكبر مجموعة بيانات تدريب وأكثرها شمولاً حتى الآن، وأكبر 100 مرة من مجموعات البيانات المستخدمة لتدريب النماذج الأساسية الرائدة اليوم. 1
تدريب النموذج الأساسي تقدير تقريبي لكيفية مقارنة مجموعة البيانات بمجموعة بيانات نموذجية للمستخدم. المصادر والحسابات.

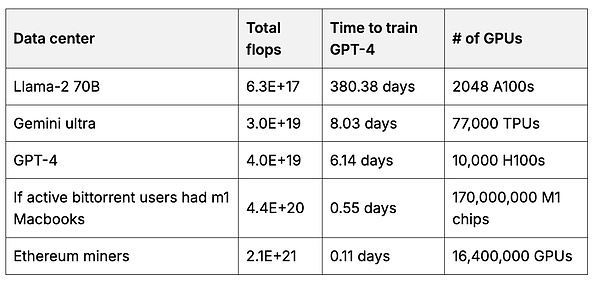
يمكن للمستخدمين بعد ذلك إنشاء نموذج أساسي مملوك للمستخدم يستخدم بيانات أكثر مما يمكن لأي شركة واحدة تجميعه. يتطلب تدريب النموذج الأساسي الكثير من حوسبة GPU. ولكن يمكن لكل مستخدم استخدام أجهزته الخاصة للمساعدة في تدريب جزء صغير من النموذج، ثم دمج الأجزاء معًا لإنشاء نموذج أكبر وأكثر قوة (7، 8، 9). 2 عندما تكون الحوافز مناسبة، يستطيع المستخدمون تجميع كميات كبيرة من العمليات الحسابية. على سبيل المثال، يبلغ إجمالي الجهد الحسابي الذي يبذله القائمون بتعدين إيثريوم 50 مرة ضعف الجهد المستخدم لتدريب النماذج الأساسية الرائدة.
مقارنة مع وحدة معالجة الرسومات الخاصة بعامل منجم Ethereum هذا لتقدير إجمالي عدد عمليات النقطة العائمة (عمليات النقطة العائمة في الثانية = مجموع سرعات "التفكير" لجميع وحدات معالجة الرسومات) في مركز البيانات المستخدم لتدريب النموذج الأساسي. 3مع مصادر الحساب.
سيمتلك المستخدمون الذين يساهمون في النموذج النموذج ويديرونه بشكل جماعي. يمكنهم الحصول على أموال مقابل استخدام النموذج وحتى الحصول على أموال بشكل متناسب بناءً على مقدار تحسين بياناتهم للنموذج. يمكن للمجموعة تطوير قواعد الاستخدام، بما في ذلك من يمكنه الوصول إلى النموذج وما هي الضوابط التي ينبغي تنفيذها. ربما سينشئ المستخدمون في كل بلد نماذجهم الخاصة التي تمثل أيديولوجيتهم وثقافتهم. أو ربما لا تمثل دولة واحدة الخط الفاصل الصحيح، وسنرى عالمًا حيث يكون لكل دولة في الشبكة نموذجها الأساسي الخاص بناءً على بيانات عضويتها.
أشجعك على تخصيص الوقت للتفكير في أجزاء النموذج الأساسي التي ترغب في الحصول عليها وبيانات التدريب التي يمكنك المساهمة بها من النظام الأساسي الذي تستخدمه. من المحتمل أن يكون لديك بيانات أكثر مما تدرك - أوراق بحثك، وأعمالك الفنية غير المنشورة، ومستندات Google الخاصة بك، وملفاتك الشخصية للمواعدة، وسجلاتك الطبية، ورسائل Slack الخاصة بك. إحدى الطرق لجمع هذه البيانات معًا هي من خلال خادم شخصي، والذي يسمح لك بسهولة استخدام بياناتك الخاصة مع LLM محلي. في المستقبل، يمكن لخادمك الشخصي أيضًا تدريب جزء من نموذج قاعدة المستخدمين لديك.
تميل النماذج الأساسية إلى أن تكون احتكارية لأنها تتطلب استثمارات أولية كبيرة في البيانات والحوسبة. من السهل علينا أن نختار الخيار السهل: أن نفعل ما في وسعنا باستخدام نموذج مفتوح المصدر متأخر بعدة أجيال، وهو ما تبقى من شركات الذكاء الاصطناعي الكبرى. لكن لا ينبغي لنا أن نكتفي بالتخلف عن أجيال قليلة ونأكل بقايا الطعام فقط! كمستخدمين، يجب علينا إنشاء أفضل النماذج الخاصة بنا، ولدينا البيانات والقدرة الحاسوبية اللازمة لتحقيق ذلك.
يحدث تحول اقتصادي ضخم حيث أصبح الذكاء الاصطناعي قادرًا بشكل متزايد على أداء عمل اقتصادي قيم. قامت شركات التكنولوجيا الكبرى بتدريب نماذج الذكاء الاصطناعي على عملك العام، وكتابتك، وأعمالك الفنية، وصورك، وغيرها من البيانات، بالإضافة إلى بيانات الأشخاص الآخرين، وبدأت في جني مليارات الدولارات كل عام (1). إنهم الآن يلاحقون بياناتك غير المتوفرة على الإنترنت العام، ويشترون بياناتك الخاصة من شركات مثل Reddit حتى يتمكنوا من زيادة إيرادات الذكاء الاصطناعي إلى تريليونات الدولارات سنويًا (2، 3).
هذا هو الهدف من DAOs البيانات. DAO البيانات هي كيان لا مركزي يسمح للمستخدمين بتجميع وإدارة بياناتهم ومكافأة المساهمين برموز مميزة خاصة بمجموعة البيانات والتي تمثل ملكية مجموعة بيانات محددة. إنه نوع من مثل اتحاد البيانات. يمكن لمجموعات البيانات هذه تكرار أو حتى تجاوز تلك التي تبيعها شركات التكنولوجيا الكبرى بمئات الملايين من الدولارات ( 4 ). تتمتع DAO بالتحكم الكامل في مجموعة البيانات ويمكنها اختيار تأجيرها أو بيع نسخ مجهولة. على سبيل المثال، يمكن أيضًا استخدام بيانات Reddit لإنشاء منصات جديدة مملوكة للمستخدمين، بما في ذلك الأصدقاء ومنشوراتك السابقة والبيانات الأخرى التي يمكن استخدامها بسهولة على الأنظمة الأساسية الجديدة.
إذا كنت مهتمًا بالتفاصيل الفنية: تحتوي Data DAO على مكونين رئيسيين: 1) الحوكمة على السلسلة، حيث يتم الحصول على الرموز المميزة من خلال مساهمات البيانات؛ 2) خادم آمن، مشفر باستخدام أزواج المفاتيح العامة والخاصة، حيث توجد مجموعات البيانات المملوكة للمجتمع. للمساهمة، عليك أولاً التحقق من البيانات لإثبات الملكية وتقدير قيمتها. يتم بعد ذلك تشفير البيانات في المتصفح باستخدام المفتاح العام للخادم ويتم تخزين البيانات المشفرة في السحابة. لن يتم فك تشفير البيانات إلا عندما يوافق DAO على اقتراح منح الوصول. على سبيل المثال، يمكن أن يسمح لشركات الذكاء الاصطناعي بتأجير البيانات لتدريب النماذج. يمكنك قراءة المزيد عن بنية شبكة Vana، المصممة لتمكين الملكية الجماعية لمجموعات البيانات والنماذج، هنا.
لا تفيد بيانات DAO المستخدمين فحسب، بل تعزز أيضًا تطوير الذكاء الاصطناعي، مما يجعل من الممكن بناء الذكاء الاصطناعي مثل البرامج مفتوحة المصدر، مما يسمح لجميع أولئك الذين يساهمون فائدة. يكافح الذكاء الاصطناعي مفتوح المصدر للعثور على نموذج عمل قابل للتطبيق: فالدفع مقابل وحدات معالجة الرسومات والبيانات والباحثين أمر مكلف. علاوة على ذلك، بمجرد تدريب النموذج، لا توجد طريقة لاسترداد هذه التكاليف إذا كان مفتوح المصدر. يمكن تطبيق البنية التقنية لـ DAO للبيانات على نموذج DAO، حيث يمكن للمستخدمين والمطورين المساهمة بالبيانات والحسابات والأبحاث مقابل ملكية النموذج.
الخيار الافتراضي في مجتمع اليوم هو السماح لشركات التكنولوجيا الكبرى بأخذ بياناتنا واستخدامها لتدريب نماذج الذكاء الاصطناعي التي تناسبنا. إنهم يستفيدون من نماذج الذكاء الاصطناعي هذه لأنه يتم استبدالنا بنماذج مدربة على بياناتنا. هذه صفقة سيئة جدًا للمجتمع، ولكنها أمر جيد لشركات التكنولوجيا الكبرى. والطريقة الوحيدة لمنع حدوث ذلك هي من خلال العمل الجماعي. البيانات هي العملة، والبيانات الجماعية هي القوة. أنا أشجعك على المشاركة: يتم إطلاق أول DAO للبيانات في العالم والتي تركز على بيانات Reddit اليوم على شبكة Vana. من خلال تحطيم خنادق البيانات التي تسيطر عليها قلة مميزة، تقوم DAOs الخاصة بالبيانات بإنشاء مسار إلى إنترنت مملوك للمستخدم حقًا.
وقال جريج سيبولارو من NYDIG إن تحركات blockchain الأخيرة أثارت مخاوف "غير عقلانية"، مما يوفر للمستثمرين فرصة شراء.
JinseFinanceمستخدمو دفتر الأستاذ يحتجون على الرقابة على وسائل التواصل الاجتماعي.
 Beincrypto
Beincryptoأصدر Reddit كمية محدودة من NFTs المجانية لـ Rabbids avatar ويقوم المستخدمون بتجميعها ، مع استنفاد أصناف متعددة بالفعل.

تم إنشاء أكثر من 3 ملايين محفظة Reddit Vault.
Beincryptoاستخدم عامل التعدين ما يقرب من 30 مليون غوي لدفع ثمن تلك الصفقة.
 Coindesk
Coindeskحظرت الصين تداول العملات المشفرة والتعدين العام الماضي.
CoindeskBeincryptoقالت الشركة أن المشروع من المقرر أن يستخدم blockchain Polygon (MATIC) للتداول اللامركزي ومبيعات الطرف الثالث.
 Cointelegraph
Cointelegraphستطلق منصة الوسائط الاجتماعية الشهيرة Reddit ميزة جديدة تسمى Collectible Avatars. هذه العناصر المدعومة من blockchain هي رموز غير قابلة للاستبدال (NFTs) ...
 Bitcoinist
Bitcoinistتظهر البيانات أن عائدات منجم البيتكوين تتعرض لضغوط في الآونة الأخيرة حيث أنها تحقق الآن 61٪ أقل من ...
Bitcoinist