Unveiling Courtyard's Tokenized Pokémon Card Giveaway
Courtyard, a startup in the crypto collectibles space, is distributing numerous branded mystery packs that include graded and tokenised Pokémon cards.
 Jixu
Jixu

Over the past two years, Ethereum has fully committed to a “Rollup-centric” roadmap. The strategy involves locking up ETH in a bridge contract, executing transactions off-chain, and using proofs — either fraud proofs or zero-knowledge proofs (ZKPs) — to verify the state of Layer2 (L2) and process withdrawals.
However, there is a significant challenge: Ethereum itself does not natively verify EVM executions, forcing rollups to independently implement their own proof systems on-chain to verify state transitions.
Ethereum frequently undergoes hard forks, which may modify the EVM, meaning that rollup teams must be responsible for maintaining and updating their custom implementations. This typically requires the formation of a security committee or the adoption of a token-based voting governance system to manage updates to their bridge contract and proof mechanism.
In our previous series, we explored Based rollups and Booster rollups. Now, we’ll turn to a deeper dive into the concept of native rollups.
There can be a lot of confusion between the definitions of Based rollup, Booster rollup, and Native rollup. In previous series, we have already introduced Based rollup and Booster rollup, so it is recommended that you check those out before reading this article. But we will quickly review the three types.
Based Rollups use the L1 validator set for transaction ordering, promoting decentralization, but may affect throughput due to relatively long L1 block times (e.g. 12 seconds). However, efforts are being made to improve this experience, using pre-confirmation technology to enable users to enjoy faster transaction finalization as the community continues to innovate.
Booster Rollups scale execution and storage by emulating L1 processing on L2, allowing applications to grow without redeploying. While this approach offers scalability, it introduces additional complexity and requires more complex engineering effort to develop and maintain than traditional rollups.
Native Rollups leverage L1’s own state transfer function (STF) as a validator for application layer state transitions. However, while Optimism, Arbitrum, and other rollups operate in an EVM-equivalent environment, they often contain custom modifications that are complex or impractical to implement directly on Ethereum.
Native rollups, once known as fiat rollups, have been discussed in detail in various writings. Additionally, the term “canonical rollup” was briefly used by @apolynya. However, the term “fiat” was eventually replaced with “native” to indicate that existing EVM-equivalent rollups could potentially be upgraded to this model. The term “native” was coined by @danrobinson and an anonymous contributor from Lido. How do native rollups work? The native rollup proposal introduces the EXECUTE precompile, which is intended to serve as a validator for rollup state transitions. This precompile will allow rollup teams to use it in their validator contracts, provide Based for the proof system, and make the rollup inherit Ethereum’s native validation. Since this new precompile is somewhat similar to the “EVM in the EVM” concept, it will be updated through Ethereum’s hard fork process under its social consensus. This ensures that changes to the EVM are reflected in the precompile, enabling rollups to inherit Ethereum’s validation and relieving rollup teams of governance responsibilities in terms of security committees or multi-signatures, making rollups more intrinsically secure for users.
The EXECUTE precompile acts as a validator for EVM state transitions, allowing rollups to leverage Ethereum's native Based facilities at the application layer. It uses inputs such as pre_state_root, post_state_root, trace, and gas_used to verify transitions, leveraging a gas pricing mechanism similar to EIP-1559. Depending on the scalability needs of the rollup, validators can enforce the correctness of rollup state transitions through re-execution or SNARK proofs. In addition, a one-slot delay is integrated to mitigate centralization risks, such as MEV-based proof competition.
This precompile simplifies rollup development through "trustless rollup" support in the proof system. If combined with a Based rollup design, where both the ordering and proof systems are managed by Ethereum, this structure enables complete trustlessness, often referred to as an "ultrasonic rollup". It improves composability and has the potential for real-time settlement, encouraging more composable and secure rollup designs.
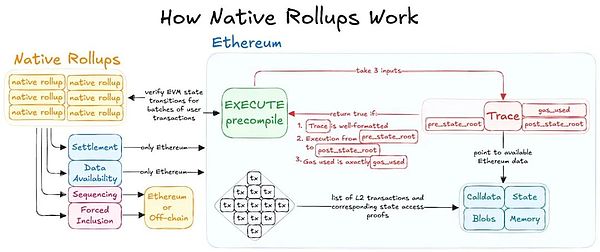
The proposed precompile behaves like the EVM, re-executing rollup transactions to verify correctness. This goes against the core advantage of rollup, which is off-chain execution and only submitting validity proofs to Ethereum. Instead, the precompile essentially reflects what Ethereum already does and does not add any value in alleviating the computational burden from L1.
The choice of an EVM-like validator instead of a zk validator stems from the current immaturity of ZK technology. The currently widely used zkVM has shown vulnerabilities, and the rapid evolution of ZKP makes hard-coding specific zk validators on-chain risky and inflexible. Ethereum instead prioritizes diversity and neutrality, allowing experimentation with different zk clients without locking in to a single validator.
However, this does not mean that precompiles have failed to contribute to Ethereum’s scalability. Although Ethereum ensures its security by keeping zk proof validators off-chain, it leverages this precompile to verify the zk proofs submitted by the rollup. This allows Ethereum validators to avoid fully simulating all rollup transactions from start to finish. Instead, by relying on zk proofs off-chain, the network maintains its security guarantees while striving to achieve scalability in terms of execution.
With native rollups, much of the complex work can be handled by precompiles, making things like fraud proofs or SNARK checks simpler. This means less code to write and maintain, and no additional systems like proof networks or security committees are required.
On-chain SNARK verification is expensive, so many zk-rollups settle transactions infrequently to save costs. EXECUTE precompiles can help reduce these costs by using SNARK recursion to package multiple proofs together. This approach can make rollups more efficient at verifying transactions, making off-chain verification more cost-effective.
Ensuring error-free operation in traditional rollups is challenging and often requires extensive checks. Many teams mitigate risk by adopting centralized ordering to prevent the generation of malicious blocks. However, with native execution of precompiles, more secure and permissionless ordering mechanisms may be achieved. This approach can allow rollups to inherit not only the security of L1, but also the fungibility of assets, as transactions are verified directly in the trusted environment of Ethereum.
There are many EVM-compatible rollups, but few are equivalent to the EVM: keeping in sync with changes in the main blockchain often requires a team or voting system to update the rollup, which can be risky. Native rollups can automatically update with the main blockchain, keeping everything in sync, without the need for additional rules or voters.
For zk-rollups, achieving ultra-low latency attestation times, such as 100 milliseconds, is a highly challenging engineering task. In contrast, native rollups may allow for more “relaxed” attestation schedules, extending them to a full slot. This approach reduces the pressure to generate proofs immediately, potentially improving reliability and enhancing integration with L1.
All current rollup stacks, such as the OP Stack and Arbitrum Orbit Stack, have the potential to transform into “native rollups”, directly inheriting Ethereum’s security features. This upgrade will make users feel happier because security is enhanced, and rollup teams feel more comfortable because they no longer need a security committee. At the same time, rollup teams can still continue to compete by providing an efficient shared sorting layer and capture sorting fees to maximize MEV.
However, not all rollups will transition to native form. Some L2 features are inherently incompatible with native rollups, including unique transaction types, different gas accounting methods, and precompiles that cannot be found on the main L1 blockchain. The diversity of VMs between L2 rollups, each sharing a common security Based, is a major advantage of the L2 ecosystem today, such as
@EclipseFND is an SVM rollup,
@movementlabsxyz
is a MoveVM rollup, or @Starknet is a CairoVM rollup.
As @doganeth_en points out, future rollups will fall into three categories: enterprise rollups, performance-focused rollups, and “aligned” native rollups.
Enterprises will focus on managing, ordering, and owning their rollups, ideal for businesses that want web2-like control over transaction order, execution, and applications.
Performance-focused rollups will use Ethereum’s settlement but rely on alternative data availability for optimal performance, such as
@megaeth_labs">@megaeth_labs uses @eigen_da
for data availability. These rollups are less decentralized but increase the utility of $ETH at the expense of certain Ethereum features. Native rollups will be fully integrated with Ethereum’s Based facilities and offer: Ethereum-level decentralization, shared execution with direct state access, and cheaper off-chain ZK proof verification. These rollups contribute to Ethereum’s network effects and may share revenue, but their sustainability relies on natural economic incentives. Conclusion Native rollups represent a major advancement in the Ethereum rollup hub roadmap, providing an approach that is more aligned with Ethereum’s Based facilities. By introducing EXECUTE precompiles, native rollups simplify governance, removing the need for multi-signatures, security committees, or token-based voting systems. This approach not only enhances security, but also enables rollups to scale more efficiently, leveraging off-chain zk-proofs, thereby ensuring trust minimization and scalability.
While this proposal is promising, it is not without challenges. While most existing rollups are labeled as EVM-equivalent, they typically have slight modifications to the EVM. As a result, transitioning to a native rollup model may impose additional development burdens on rollups with custom EVM implementations.
Nonetheless, native rollups offer a compelling path to marry the security and flexibility of Ethereum with rollup design. By facilitating alignment with L1, they encourage innovation while reducing fragmentation, making Ethereum’s ecosystem more cohesive and resilient in the future. If you haven’t already, be sure to check out
Part I and Part II of our Rollups 2.0 series, focusing on Based Rollups and Enhanced Rollups, respectively. In our next article, we’ll dive deeper into the concept of gigagas rollups and explore how this innovative rollup design pushes Ethereum’s scalability boundaries and further enhances the rollup ecosystem.
Acknowledgements: This post was written by @paramonoww . Special thanks to @korayakpinarr for his feedback and review.
Courtyard, a startup in the crypto collectibles space, is distributing numerous branded mystery packs that include graded and tokenised Pokémon cards.
JixuStablecoin issuer Circle has revealed its v2.2 upgrade, aiming to reduce transaction fees by approximately 7%. While the announcement carries a tone of promise, some may view it as an attempt to stay relevant in an increasingly competitive landscape.
 Jasper
JasperThousands of instances of AI-generated content are being discovered weekly, presenting a potential avenue for terrorist groups and violent extremists to evade automated detection systems, warn experts.
JixuIn a plot twist, Taiwanese singer Nine Chen, entangled in a web of investments, now faces legal repercussions. Initially a witness, Chen now finds himself a defendant, adding an unexpected layer to his challenges. Known for his business savvy, Chen diversified into streetwear, restaurants, NFTs, escape rooms, and cyber poker. While his streetwear venture thrives with an eight-figure annual turnover, others yield mixed results.
 Joy
JoyTaiwanese prosecutors discover new suspects in the JPEX saga, complicating legal proceedings and worrying financial regulators.
 Hui Xin
Hui XinOver 2,800 cyber police personnel have undergone extensive training in advanced cryptocurrency forensics. This aligns with broader efforts to modernize law enforcement in the digital era and fortify legal frameworks against emerging technology misuse.
 Aaron
AaronTotal losses are still being calculated as of time of writing, with some estimates placing it above $100 million.
 Davin
DavinThe Chinese government emphasises that theft of digital collections constitutes a breach of protection laws and infringes upon the legal interests associated with the unauthorised acquisition of computer information system data.
 Kikyo
KikyoBinance Russia users will have only until 31 January 2024 to withdraw their rubles from the exchange.
 Catherine
CatherineFTX initiates legal action against Bybit and associates in a $953 million asset recovery effort, amidst broader bankruptcy proceedings and ongoing efforts to reclaim funds.
Hui Xin