Specialized vs. General-Purpose ZK: Which is the Future?
ZK Stack, dedicated vs. general-purpose ZK: Which one is the future? Golden Finance, the line between dedicated and general-purpose ZK is blurring.
 JinseFinance
JinseFinance

Original text: https://notes.ethereum.org/@vbuterin/enshrined_zk_evm
Translator: Denlink Community[1] Translation Team
Layer2 EVM protocol built on Ethereum, including Optimistic Rollups and ZK Rollups, all rely on EVM verification. However, this requires them to trust a large code base, and if there are vulnerabilities in the code base, these virtual machines are at risk of being hacked. Additionally, even a ZK-EVM that is intended to be fully equivalent to an L1 EVM will require some form of governance mechanism to replicate changes from the L1 EVM to its own EVM implementation.
This situation is not ideal because these projects are replicating functionality that already exists in the Ethereum protocol, and Ethereum governance is already responsible for upgrading and fixing bugs. Place: ZK-EVM basically does the job of validating Layer1 Ethereum blocks! Additionally, over the next few years we expect light clients [2] to become more and more powerful, and soon L1 EVM executions fully authenticated using ZK-SNARKs . At that point, the Ethereum network will effectively have ZK-EVM built-in. Therefore, a question arises: why not make ZK-EVM natively used for rollup?
This article will introduce several versions of encapsulated ZK-EVM that can be implemented and detail the trade-offs and design challenges, as well as what not to do Reasons for a particular direction. The advantages of implementing protocol features should be weighed against the benefits of leaving it to the ecosystem and keeping the underlying protocol simple.
Basic functions: Verify Ethereum blocks. The protocol feature (not yet determined whether it is an opcode, precompilation, or other mechanism) should accept (at least) a pre-state root, a block, and a post-state root as input, and verify that the post-state root is actually on the pre-state root The result of executing the block.
Compatibility with the Ethereum multi-client philosophy[3], which means we hope Avoid using a single attestation system and instead allow different customers to use different attestation systems. This in turn means a few things:
Data availability requirements: For any EVM execution through encapsulated ZK-EVM, we expect toguarantee underlying data availability[4], This way provers using a different proof system can re-certify executions, and clients relying on that proof system can verify newly generated proofs.
The proof is stored outside the EVM and block data structures: The ZK-EVM feature does not accept SNARKs directly as EVM inputs because different clients expect different types of SNARKs. Instead, it may be similar to blob verification: transactions can include claims (pre-state, block body, post-state) that need to be proven, an opcode or precompilation can access the content of these claims, and the client Consensus rules will separately check for data availability and the existence of proofs for each claim made in the block.
Auditability: If any execution is proven, we want the underlying data to be available to the user and developers can check. In fact, this adds another reason why data availability requirements are important.
Upgradeability: If a vulnerability is found in a specific ZK-EVM solution, we want to be able to fix it quickly, andNo hard fork required. This adds to the importance of proofs being stored outside of the EVM and block data structures.
Support almost - EVMs: One of the attractions of L2 is to innovate at the execution level and extend EVM. If the VM for a given L2 is only slightly different from the EVM, then it would be nice if the parts of the L2 that are the same as the EVM can still use the native in-protocol ZK-EVM, only for the parts that are different from the EVM Rely on their own code. This can be accomplished by designing the ZK-EVM functionality in a way that allows the caller to specify a bitfield, opcode, or address list, to be processed by an externally provided table rather than by the EVM itself. We can also make the gas cost customizable within a limited scope.
< strong>The multi-client concept is probably the most assertive requirement on the above list. There is the option of abandoning it and focusing on a ZK-SNARK scheme, which would simplify the design, but at the cost of becoming a larger conceptual shift for Ethereum (as it would essentially abandon much of what Ethereum has long client philosophy) and introduce greater risk. In the long term future, such as when formal verification techniques become more sophisticated, it may be better to go this route, but right now it seems too risky.
Another option is a closed multi-client system , where a fixed set of attestation systems are known within the protocol. For example, we might decide to use three ZK-EVMs: PSE ZK-EVM[5], Polygon ZK-EVM[6] and Kakarot [7]. A block requires proofs from two of these three to be considered valid. This is better than a single proof system, but it makes the system less adaptable because users must maintain validators for each proof system, necessarily having implications for things like the political governance process that incorporates new proof systems.
This leads me to an open multi-client system where the proof is placed "outside the block" and is provided by the client End-to-end verification. Individual users will use the client they want to validate blocks, as long as there is a prover creating a proof for the proof system. Proof systems gain influence by convincing users to run them, not by convincing protocol governance processes. However, the complexity cost of this approach is higher, as we will see.
Besides the basic guarantees of correct functionality and security, the most important feature is speed . While it is possible to design an asynchronous in-protocol ZK-EVM function that only returns the answer to each claim after N slots, if we can reliably guarantee that the proof can be generated in a few seconds, the problem becomes Much easier, so anything that happens to each block clock is independent.
While generating proofs for Ethereum blocks today takes many minutes or even hours, we know of no theoretical reason to prevent massive parallelization:We It is always possible to assemble enough GPUs to separately prove different parts of a block's executionand then merge the proofs together using recursive SNARKs. Additionally, hardware acceleration through FPGAs and ASICs can help optimize proofs. However, achieving this is a significant engineering challenge that should not be underestimated.
Similar to EIP-4844 blob transaction[8], we introduce a new transaction that contains ZK-EVM claims Type:

Similar to EIP-4844, the object propagated in the memory pool will be a modified version of the transaction:
The latter can be converted to the former, but not vice versa. We also extended the block side car object (introduced in EIP-4844[9]) to include a list of proofs for claims made in the block.
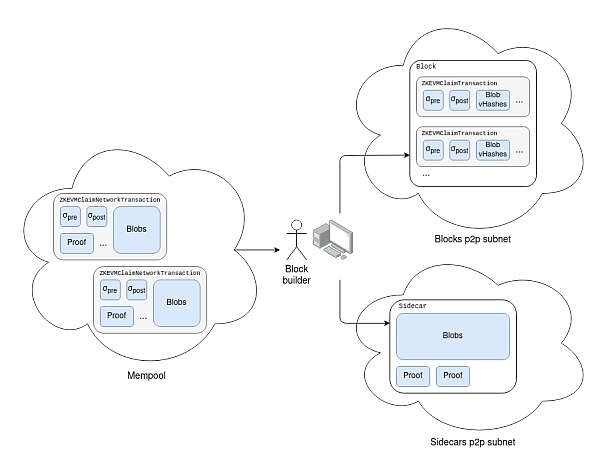
Note that in practice we will most likely want to split the sidecar into two separate sidecars, one for blobs and one for proofs, and have a separate subnet for each type of proof ( There is also a subnet for blobs).
On the consensus layer, we added a verification rule: the client can only accept the block after seeing a valid proof of each claim in the block piece. The proof must be a ZK-SNARK proving that the concatenation of transaction_and_witness_blobs is the serialization of the (Block, Witness) pair, and that the block is executed on pre_state_root using Witness(i) is valid, and (ii) the correct post_state_root is output. Potentially, a client could choose to wait for M-of-N of multiple types of proofs.
A philosophical point to mention here is that the block execution itself can be viewed as simply being required with ZKEVMClaimTransaction One of the (σpre,σpost,Proof) triples that are checked together with the triples provided in the object. Therefore, users' ZK-EVM implementations can replace their execution clients; the execution clients will still be used by (i) provers and block builders, and (ii) nodes that care about local usage indexing and storing data.
Suppose there are two ethers Square clients, one using PSE ZK-EVM and the other using Polygon ZK-EVM. Assume that by now both implementations have evolved to the point where they can prove Ethereum block execution in 5 seconds, and that for each proof system there are enough independent volunteers running the hardware to generate the proofs.
Unfortunately, since individual attestation systems are not included, they cannot receive incentives in the protocol; however, we expect that running compared to research and development The cost of certifiers will be lower so we can fund certifiers simply through a common agency used for funding public goods.
Suppose someone releases ZKEvmClaimNetworkTransaction, but only releases a proof version of PSE ZK-EVM. Polygon ZK-EVM's proof nodes saw this happening, computed and republished the object with Polygon ZK-EVM proof.
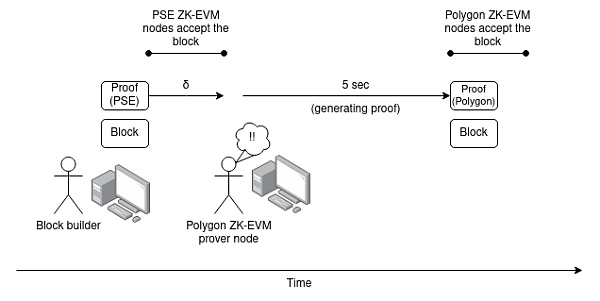
This increases the total maximum delay between the earliest honest node to accept a block and the latest honest node to accept the same block last, from δ to 2δ+Tprove (assume here T< sub>prove < 5s).
The good news, however, is thatif we adopt single-slot finality, we can almost certainly combine this additional latency with the inherent Multiple rounds of consensus delays are "pipelined" together. For example, in this 4-subslot proposal [10], the "head vote" step may only need to check the validity of the basic block, but the "freeze and confirm" step requires the existence of a prove.
An ideal goal of ZK-EVM functionality is< strong>Support almost-EVMs: It is an EVM with some additional features. This could include new precompilers, new opcodes, options to write contracts using the EVM or a completely different VM (as is the case with Arbitrum Stylus[11]), or even having synchronization Multiple parallel EVMs for cross-communication.
Some modifications can be supported in a simple way: we can define a language that allows ZKEVMClaimTransaction to pass the complete description of the modified EVM rule . This can be applied to:
Custom gas cost table (user is not allowed to reduce gas fee, but can increase it)
Disable specific opcodes
Set block number (this will mean different rules depending on hard fork)
Set a flag that activates a full set of EVM changes specifically for L2 but not for L1, or other simple changes
To allow users to introduce new features more openly by introducing new precompilers (or opcodes), we can add precompiled input/output scripts included as part of the blob in the ZKEVMClaimNetworkTransaction at:

EVM execution will be modified. An array inputs will be initialized to empty. When the address in used_precompile_addresses is called for the ith time, we add InputsRecord(callee_address, gas, input_calldata) to inputs and replace the called RETURNDATA is set to outputs[i]. Finally, we check that used_precompile_addresses has been called len(outputs) in total, and that inputs_commitments is consistent with the inputs The result of the blob produced by SSZ serialization matches the promise. The purpose of exposing inputs_commitments is to facilitate external SNARKs to prove the relationship between inputs and outputs.
Note the asymmetry between input (stored in a hash) and output (stored as bytes). This is because execution needs to be able to be done by a client that only sees the input and understands the EVM. EVM executions already have the input generated for them, so they only need to check that the generated input matches the claimed input, which only requires a hash check. However, the output must be provided to them in full and therefore data availability is a must.
Another useful feature might be to allow "privileged transactions" that can be called from any sender account. These transactions can be run between two other transactions, or when the precompiler is called in another (possibly also privileged) transaction. This can be used to allow non-EVM mechanisms to call back to the EVM.
This design may be modified to support new or modified opcodes in addition to new or modified precompilers. Even with just the precompiler, this design is very powerful. For example:
By setting used_precompile_addresses to include a list of regular account addresses with certain flags in the state and generate a SNARK proof To prove its correct construction, you can support features like Arbitrum Stylus style, where the contract can write its code in the EVM or WASM (or other VM). Privileged transactions can be used to allow WASM accounts to call back to the EVM.
You can demonstrate a parallelism of multiple EVMs by adding external checks to verify that the input/output records and privileged transactions executed by multiple EVMs match in the correct manner. systems that communicate over synchronized channels.
Type 4 ZK-EVM[13] can be run through multiple implementations: one will be Solidity or other higher level The language is directly converted to a SNARK-friendly VM implementation, and another compiles it into EVM code and executes it in the built-in ZK-EVM. The second (inevitably slower) implementation can only run in the event that a faulty prover sends a transaction assertion that is vulnerable, and collects the bounty when providing a transaction that is processed differently.
A pure asynchronous VM can be implemented by making all calls return zero and mapping the calls to privileged transactions added to the end of the block.
Above One challenge with the design is that it is completely stateless, which makes it data inefficient. Using ideal data compression, an ERC20 send can be up to 3x more space efficient when using stateful compression than using only stateless compression.
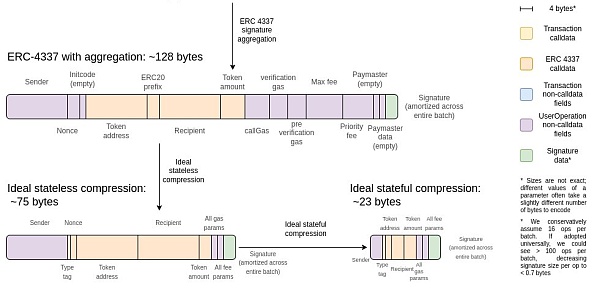
In addition, stateful EVM does not need to provide witness data. In both cases, the principle is the same: requiring data to be available is a waste because we already know that data is available because it was entered or generated in a previous EVM execution.
If we want to make the ZK-EVM function stateful, we have two options:
Requires σpre to be empty, or a pre-declared key and value data available list, or a previous execution of σpost A list of sub>
To (σpre, σpost, Proof) The tuple adds a blob promise with the block-generated receipt R. Any previously generated or used blob commitment can be referenced in a ZKEVMClaimTransaction, including representatives of blocks, witnesses, receipts, and even regular EIP-4844 blob transactions, perhaps with some time constraints, that can be accessed during their execution ( It may be through a series of instructions: "Insert the bytes N...N+k-1 of commitment i at position j of block + witness data")
(1) Basically: instead of incorporating stateless EVM verification (encapsulation), incorporate the EVM subchain (encapsulation). (2) Essentially creates a minimal built-in stateful compression algorithm that uses previously used or generated blobs as dictionaries. Both of these methods will add burden to the proving node, and only the proving node can store more information; in case (2), it is easier to make this burden time-limited than case (1).
Closed Multi-proof systems, where a fixed number of proof systems have an M-of-N structure, avoid many of the above complexities. Closed multi-certifier systems in particular do not need to worry about ensuring that data is on-chain. Additionally, the closed multi-prover system will allow ZK-EVM proofs to be executed off-chain; making it compatible with the EVM Plasma solution[14].
However, closed multi-certifier systems increase governance complexity and eliminate auditability, which are trade-offs. The high cost of these benefits.
The EVM verification functionality currently implemented by the Layer2 team will be handled by the protocol, but the Layer2 project will still be responsible for many important functions:< /p>
Fast pre-validation: Single slot finality may slow down Layer1 slots, which the Layer2 project already provides for its users With "pre-confirmation" supported by Layer 2's own security, the latency is much lower than one slot. This service will continue to be handled purely by Layer2.
MEV Mitigation Strategies : This may include encrypted memory pools, reputation-based sequence selection, and other features that Layer1 is unwilling to implement.
Extensions to the EVM : Layer2 projects can include important extensions to the EVM, providing great value to their users. This includes alomost-EVM and disparate approaches such as Arbitrum Stylus's WASM support and the SNARK-friendly Cairo (https://www.cairo-lang.org/) language.
Convenience for users and developers: The Layer2 team is committed to attracting users and projects into its ecosystem and making them feel welcome. Welcome; they are compensated by capturing MEV and congestion charges within their network. This relationship will continue to exist.
ZK Stack, dedicated vs. general-purpose ZK: Which one is the future? Golden Finance, the line between dedicated and general-purpose ZK is blurring.
JinseFinanceEVM’s lead is not as large as people think, and it is definitely not “insurmountable”.
JinseFinanceThe Parallel Ethereum Virtual Machine (Parallel EVM) is an upgraded version of the traditional Ethereum Virtual Machine (EVM). It improves the blockchain transaction throughput and improves transaction processing speed and efficiency by processing multiple non-conflicting transactions simultaneously.
JinseFinanceModularity and zero-knowledge proof are two major trends driving the development of blockchain technology.
JinseFinanceParadigm led a $225 million financing round for Monad, drawing market attention to “Parallel EVM”.
JinseFinanceCan Parallel EVM enable existing decentralized applications to achieve Internet-level performance?
JinseFinanceEVM++ aims to open the boundaries of EVM to adapt to the new crypto world
JinseFinanceJinseFinanceJustin Sun explained that the zkEVM integration has the potential to benefit the TRON and Bittorent ecosystems.
 CryptoSlate
CryptoSlateZK-rollups have gained traction on Ethereum. Can the technology also be applied to Bitcoin?
 The Crypto Illuminati
The Crypto Illuminati