Livepeer : LivepeerネットワークにAIビデオコンピューティングを導入する方法
ライブピアにAIビデオ・コンピューティングを導入する時が来た
 JinseFinance
JinseFinance

by Cynic, Shigeru
はじめに: アルゴリズム、演算、データの力を利用したAI技術の進歩は、データ処理とインテリジェントな意思決定の境界を再定義している。同時に、DePINは中央集権的なインフラから分散型のブロックチェーンベースのネットワークへのパラダイムシフトを象徴している。
世界がデジタルトランスフォーメーションに向けた動きをますます加速させる中、AIとDePIN(分散型物理インフラ)は、あらゆる業界の変革を推進する基盤技術となっています。AIとDePINの融合は、技術の迅速な反復とより広範な採用を促進するだけでなく、より安全で透明性の高い効率的なサービス提供への道を開きます。AIとDePINの統合は、技術の迅速な反復と広範な適用を促進するだけでなく、世界経済に遠大な変化をもたらす、より安全で透明かつ効率的なサービスモデルを切り開くだろう。
DePIN:分散型物理インフラ
DePIN(分散型物理インフラ。Decentralised Physical Infrastructure)である。狭義には、DePINは主に電力ネットワーク、通信ネットワーク、位置情報ネットワークなど、分散型台帳技術に支えられた伝統的な物理インフラの分散型ネットワークを指す。広義には、ストレージ・ネットワークやコンピューティング・ネットワークなど、物理デバイスによってサポートされるすべての分散ネットワークをDePINと呼ぶことができる。
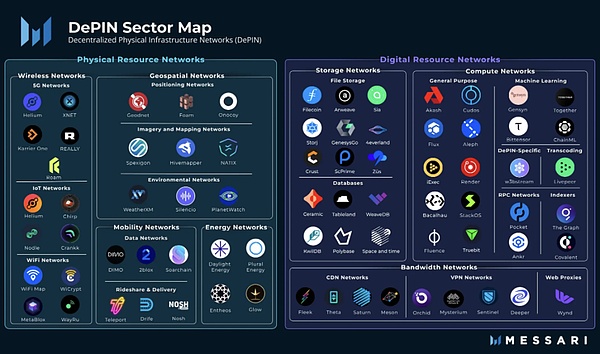
from: Messari
Cryptoが金融レベルでの分散型変革をもたらしたのであれば、DePINは実体経済での分散型ソリューションである。いわば、PoWマイナーはDePINなのだ。初日から、DePINはWeb3の中核的な柱となっている。
AIの3つの要素 - アルゴリズム、演算、データ
のうち2つを持つのはDePINだけです。人工知能(AI)の開発は、アルゴリズム、演算、データという3つの重要な要素に依存しているとしばしば考えられている。アルゴリズムとは、AIシステムを駆動する数学的モデルと手続き的ロジックを指し、演算とは、これらのアルゴリズムを実行するために必要な計算リソースを指し、データとは、AIモデルのトレーニングと最適化の基礎を指します。

3つの要素のうち、どれが最も重要ですか? chatGPTそうでなければ、学会や学術誌の論文がアルゴリズムの微調整に次ぐ微調整で埋め尽くされることはないだろう。しかし、chatGPTとその知能を支える大規模言語モデルLLMが発表されると、人々は後者2つの重要性に気づき始めた。大量の演算はモデルを作成するための必須条件であり、データの質と多様性は、アルゴリズムの卓越性を求める通常の要求とは異なり、堅牢で効率的なAIシステムを構築するために極めて重要なのだ。
ビッグモデルの時代には、AIは洗練されたプロセスからレンガを飛ばすようなものになり、コンピューティングパワーとデータの両方に対する需要がますます高まっており、DePINはそれを提供することができる。トークンのインセンティブはロングテール市場をこじ開け、大規模なコンシューマーグレードのコンピューティングパワーとストレージは、ビッグモデルによって提供される最高の糧となるだろう。
AIの分散化はオプションではなく、必須です
もちろん、AWSのサーバールームで利用可能なコンピューティングパワーとデータは、安定性、使用量、経験の面でDePINを凌駕している、と人は尋ねるかもしれません。DePINの経験はDePINに勝る。では、なぜ集中型サービスではなくDePINを選ぶのか?
この議論には当然それなりの根拠があります。結局のところ、現在全体を通して、ほとんどすべての大規模モデルは大規模なインターネット企業によって直接または間接的に開発されています。なぜですか?唯一の大規模なインターネット企業は、算術の強力な財政支援と十分な品質のデータを持っているからです。しかし、これは正しくありません、人々はもはやすべてを操作するためにインターネットの巨人に操作されることを望んでいません。
一方では、中央集権的なAIはデータのプライバシーやセキュリティのリスクを伴い、検閲や統制の対象となりうる。他方で、インターネット大手が作るAIは依存関係をさらに強化し、市場の中央集権化をもたらし、イノベーションへの障壁を高める可能性がある。

from: https://www.gensyn.ai/
人類はもうAIエラ・マルティン・ルターを必要とすべきではない。人々は神と直接話す権利を持つべきだ。
ビジネスの観点からのDePIN:コスト削減と効率化がカギ
分散型か中央集権型かという価値観の議論は置いておくとしても、ビジネスの観点からAIにDePINを使うメリットはまだあります。AIにDePINを使うメリットはまだある。
まず第一に、インターネット大手は多くのハイエンドグラフィックリソースを持っていますが、民間のコンシューマーグレードのグラフィックカードの組み合わせでも、非常にかなりの演算ネットワーク、つまり演算能力のロングテール効果を構成できることを明確に理解する必要があります。このような民生グレードのグラフィックカード、アイドル率は実際には非常に高い。DePINによって与えられるインセンティブが電気代を上回ることができる限り、ユーザーはネットワークに演算を貢献する意欲を持つ。同時に、すべての物理的設備はユーザー自身によって管理され、DePINネットワークは集中型プロバイダーの避けられない運用コストを負担する必要がなく、プロトコル設計そのものに集中するだけでよい。
データについては、DePINネットワークは潜在的なデータの可用性を解き放ち、エッジコンピューティングを含む伝送コストを削減することができます。同時に、ほとんどの分散ストレージネットワークは自動重複排除機能を備えており、AIのトレーニングによるデータクリーニングの作業を軽減します。
最後に、DePINがもたらす暗号経済学はシステムの耐障害性を高め、プロバイダー、消費者、プラットフォームにとってWin-Win-Winの状況を達成することが期待される。
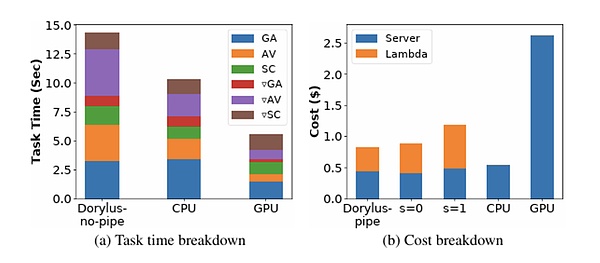
from: UCLA
信じられないかもしれませんが、UCLAの最新の研究によると、分散型コンピューティングを使用することで、同じコストで従来のGPUクラスターの最大2.75倍のパフォーマンス、具体的には1.22倍速く、4.83倍安くなることがわかりました。4.83倍安い。
謙虚な始まり:AIxDePINの課題は何か?
私たちがこの10年で月に行き、他のことをすることを選んだのは、それが簡単だからではなく、難しいからです。
-- ジョン・フィッツジェラルド・ケネディ
DePINによる分散ストレージ分散コンピューティングで信頼性のないAIモデルを構築するには、まだ多くの課題があります。
作業の検証
本質的に、深層学習モデルの計算とPoWマイニングは、どちらも汎用計算であり、一番底にあるのはゲート回路間の信号変化です。マクロに見れば、PoWマイニングは無数の乱数生成とハッシュ関数計算によってn個のゼロを前置したハッシュ値を生成しようとする「無駄な計算」であり、ディープラーニングの計算は前方導出と後方導出によってディープラーニングの各層の各パラメータの値を計算する「有用な計算」である。ディープラーニングの計算が「有用な計算」であるのに対し、ディープラーニングの計算は、ディープラーニングの各層のパラメータ値を前方導出と後方導出によって計算し、効率的なAIモデルを構築する「有用な計算」である。
実は、PoWマイニングはハッシュ関数を使う「役に立たない計算」であり、元画像から画像を計算するのは簡単で、画像から元画像を計算するのは難しいため、誰でもすぐに検証できるのに対し、ディープラーニングモデルの場合は、計算の階層性により、画像の計算は非常に簡単です。ディープラーニングモデルの場合、階層構造のため、各層の出力が次の層の入力として使用されるため、計算の妥当性を検証するには、それまでの作業をすべて行う必要があり、簡単かつ効率的に行うことはできません。
from: AWS
ジョブの検証は非常に重要です。そうでなければ、計算のプロバイダーはまったく計算を行わず、ランダムに生成された結果を提出した可能性があります。
アイデアの1つのクラスは、異なるサーバーに同じ計算タスクを実行させ、それを繰り返して同じであることをチェックすることで作業を検証することです。しかし、モデル計算の大部分は非決定論的であり、同一の計算環境であっても同じ結果を再現することはできない。加えて、反復的な計算は急激なコスト上昇を招き、コスト削減と効率化というDePINの主要目標とは矛盾する。
もう1つのタイプのアイデアは楽観的メカニズムで、結果が有効に計算されているという楽観的な信念から出発する一方で、誰でも計算をテストすることができ、エラーが見つかった場合は不正証明を提出することができ、プロトコルは不正者を没収し、内部告発者に報酬を与えます。
並列化
前述したように、DePINは主にロングテールのコンシューマーグレードのコンピューティング市場に参入しています。大規模なAIモデルの場合、単一のデバイスでのトレーニングには非常に長い時間がかかるため、並列化によってトレーニングに必要な時間を短縮する必要があります。
ディープラーニングのトレーニングを並列化する際の主な難点は、フロントタスクとバックタスクの依存関係にあり、並列化が困難になる可能性があります。
現在、深層学習トレーニングの並列化は主にデータ並列化とモデル並列化に分けられます。
データ並列とは、複数のマシンにデータを分散させることを指し、各マシンはモデルの全パラメータを保存し、ローカルデータを学習に使用し、最後に各マシンからのパラメータを集約します。データ並列は大量のデータでうまく機能しますが、パラメータを集約するために同期通信が必要になります。
モデル並列は、モデルサイズが大きすぎて1台のマシンに収まらない場合、モデルを複数のマシンに分割し、各マシンがモデルのパラメータの一部を保持することができます。異なるマシン間の通信は、順伝播と逆伝播のために必要となる。モデルの並列性は、モデルが非常に大きい場合に有利ですが、順伝播と逆伝播では通信のオーバーヘッドが大きくなります。
異なるレイヤー間の勾配情報については、さらに同期更新と非同期更新に分けることができます。同期更新はシンプルで簡単ですが、待ち時間が増加します。非同期更新アルゴリズムは待ち時間が短いですが、安定性の問題が発生します。
from: Stanford University, Parallel and Distributed Deep Learning
Privacy.strong>
世界的に個人のプライバシーを保護する動きがあり、各国政府は個人データのプライバシーとセキュリティの保護を強化しています。AIが公共データセットを多用しているにもかかわらず、異なるAIモデルを本当に分けているのは、各組織が独自に保有するユーザーデータなのです。
トレーニング中にプライバシーを暴露することなく、専有データの利点を得るにはどうすればよいでしょうか?構築したAIモデルのパラメータが危険にさらされないようにするにはどうすればよいでしょうか?
これらはプライバシーの2つの側面、データプライバシーとモデルプライバシーです。データプライバシーはユーザーを保護し、モデルプライバシーはモデルを構築する組織を保護します。現在の状況では、データプライバシーはモデルプライバシーよりもはるかに重要です。
複数のスキームがプライバシーに対処しようとしている。
複数のスキームがプライバシーに対処しようとしています。フェデレーテッド学習は、データのソースで学習することでデータのプライバシーを保証し、モデルのパラメータが送信される間、データをローカルに保ちます。
ケーススタディ:市場における質の高いプロジェクトとは?
Gensyn
Gensynは、AIモデルを訓練するための分散コンピューティングネットワークです。このネットワークは、ディープラーニングタスクが正しく実行されたことを検証するために、Polkadotに基づくブロックチェーンのレイヤーを使用し、コマンドを介して支払いをトリガーする。2020年に設立され、2023年6月にa16zが主導する4300万ドルのシリーズA資金調達ラウンドを公開した。
Gensynは、勾配ベースの最適化プロセスからのメタデータを使用して、実行された作業の証明書を構築する。この証明書は、検証作業を再実行して一貫性を比較できるようにするために、多粒子のグラフベースの精度プロトコルと相互評価器によって一貫して実行され、最終的にチェーン自体によって検証され、計算の妥当性を保証する。作業検証の信頼性をさらに高めるために、Gensynはインセンティブを生み出す誓約を導入している。
システムには、提出者、解答者、検証者、報告者という4種類の参加者がいる。
-提出者はシステムのエンドユーザーであり、計算されるタスクを提供し、完了したワークユニットに対して支払いを行う。
-ソルバーはシステムの主要な作業者であり、モデルの学習を行い、検証者がチェックするための証明を生成する。
-検証者は、非決定論的な訓練プロセスを決定論的な線形計算にリンクさせる鍵であり、ソルバーの証明の一部をコピーし、予想される閾値との距離を比較する。
- 内部告発者は最後の防衛ラインであり、検証者の作業をチェックし、挑戦状を提示する。
解答者は誓約する必要があり、内部告発者は解答者の仕事を調べ、いたずらを見つけたら挑戦し、挑戦がパスされると解答者の誓約したトークンは没収され、内部告発者は報酬を受け取る。
Gensynの予測によると、このソリューションにより、トレーニングのコストは集中型プロバイダーの1/5になると予想されています。
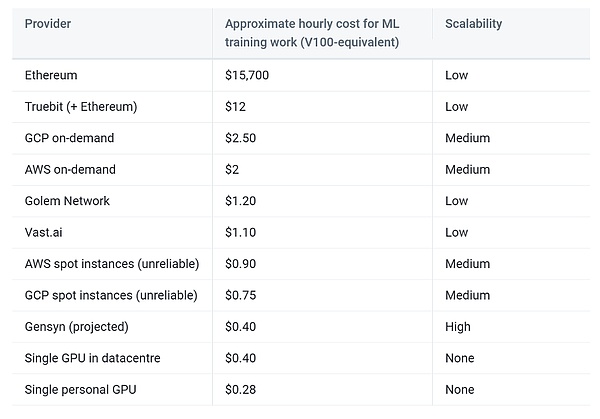
from: Gensyn
FedML
FedMLは、分散型で協調的な機械学習プラットフォームです。機械学習モデルの訓練、導入、監視、継続的改善を行いながら、プライバシーを保護する方法でデータ、モデル、計算リソースを組み合わせて共同作業を行う。2022年に設立されたFedMLは、2023年3月に600万ドルのシードラウンドを公表した。
FedMLは2つの主要コンポーネント、FedML-APIとFedML-coreで構成されており、それぞれハイレベルAPIと基礎となるAPIを表しています。
FedML-coreは分散通信とモデルトレーニングのための2つの独立したモジュールで構成されています。とモデルトレーニングの2つの独立したモジュールから構成されています。
FedML-APIはFedML-coreの上に構築されています。FedML-core を使えば、新しい分散アルゴリズムをクライアント指向のプログラミングインターフェースを使って簡単に実装することができます。
FedMLチームによる最新の研究では、コンシューマー向けGPU RTX 4090上のAIモデル推論にFedML Nexus AIを使用することで、A100よりも20倍安く、1.88倍高速であることが実証されました。
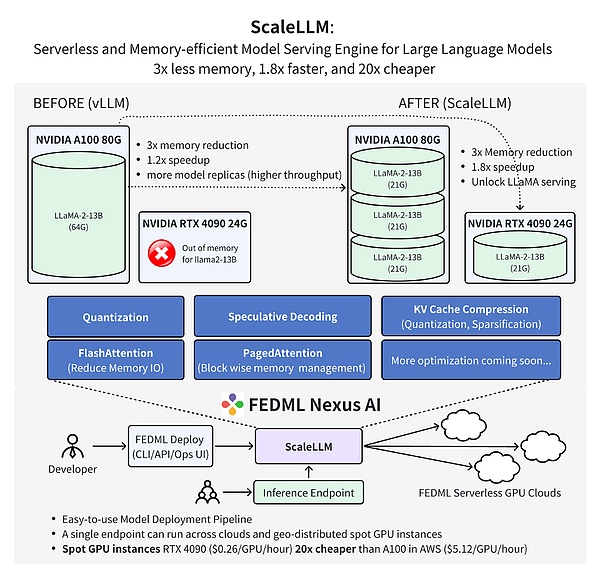
from: FedML
Future vision: dePIN brings democratisation of AI
いつの日か、AIはさらにAGIへと進化し、その時点で算術が事実上の世界共通通貨となるでしょうが、DePINはこのプロセスをより早く実現します。
AIとDePINの融合は、まったく新しい技術の成長点を開き、AIの発展に多大な機会を提供する。 DePINはAIに大量の分散演算とデータを提供し、より大きなモデルを訓練してより高い知性を達成するのに役立つ。同時に、DePINはAIがよりオープンでセキュアで信頼性の高い方向で発展することを可能にし、単一の集中型インフラへの依存を低減します。
今後、AIとDePINは共に進化し続けるでしょう。分散型ネットワークは、メガモデルをトレーニングするための強力な基盤となり、DePINの応用において重要な役割を果たすことになるでしょう。AIはまた、プライバシーとセキュリティを保護しながら、DePINネットワークのプロトコルとアルゴリズムを最適化するのに役立つだろう。我々は、AIとDePINによって、より効率的で、より公平で、より信頼できるデジタル世界が実現することを期待している。
ライブピアにAIビデオ・コンピューティングを導入する時が来た
JinseFinanceWeb3ゲーム「Axie Infinity」との関連で最も有名なRoninは、数百万人のデイリーアクティブユーザーにサービスを提供し、これまでに40億ドルを超えるNFT取引量を管理することで、その信頼性を証明してきました。
 BrianJinseFinance
BrianJinseFinance米国、ブロックチェーンと暗号通貨における中国の役割を制限する法案を提出。
 Hui Xin
Hui XinOP Labsが楽天のGoerliテストネットに耐障害システムを導入、分散型スーパーチェーンエコシステムへの道を開く。
 Bitcoinworld
Bitcoinworld昨日、Mastercard は、Mastercard マルチトークン ネットワーク (MTN) のベータ版を開始する計画を発表しました。
 Ledgerinsights
LedgerinsightsSOL 価格は 2021 年 3 月以来の最低点に急落しました。
 Beincrypto
Beincryptoイーサリアムは、新しいブロックチェーン プロトコルの突破口であり、制約要因でもあることが証明されています。
 Cointelegraph
Cointelegraphビットコイン ネットワークは、2022 年の最低電力需要である 10.65 ギガワット (GW) を記録しました。ピーク時には、BTC ネットワークは 16.09 GW の電力を必要としました。
Cointelegraphビットコインの第 2 層スケーリング ソリューションであるライトニング ネットワークでの支払いは、実際に導入が進むにつれて 400% 以上増加しました。
Cointelegraph