アストラゼネカとアブシ社のがん抗体研究におけるAI提携
アストラゼネカがAI企業アブスキーと提携し、2億4700万ドルを投じてがんと闘う先進的な抗体を開発する画期的なベンチャー企業となる。
 YouQuan
YouQuan

ソース: Silicon Planet Pro
DeepSeek の「サーバーが混み合っているので、後で再試行してください」という頻繁な返信は、世界中のユーザーをイライラさせています。
以前は一般にはあまり知られていませんでしたが、DeepSeekは2024年12月26日にGPT 4oをベンチマークする言語モデルであるV3を発表して有名になりました。1月20日、DeepSeekはOpenAI o1をベンチマークとする言語モデルR1をリリースした。ディープシンキングモードによって生成された回答の質の高さと、そのイノベーションがモデルトレーニングの初期コストの急激な低下につながる可能性があるというポジティブな兆候により、同社とそのアプリが世に出る前であった。それ以来、DeepSeek R1は混雑に見舞われ、インターネット検索機能では断続的に故障が発生し、ディープ・シンキング・モードでは「サーバーがビジー状態です」というアラートが高頻度で表示される現象が発生し、多くのユーザーを悩ませています。
DeepSeekは10年以上前からサーバーの停止に見舞われるようになり、27日正午にはDeepSeekの公式サイトに「deepseek webpage/api is unavailable」と何度も表示され、DeepSeekは週末にiPhoneで最もダウンロードされたアプリとなった。
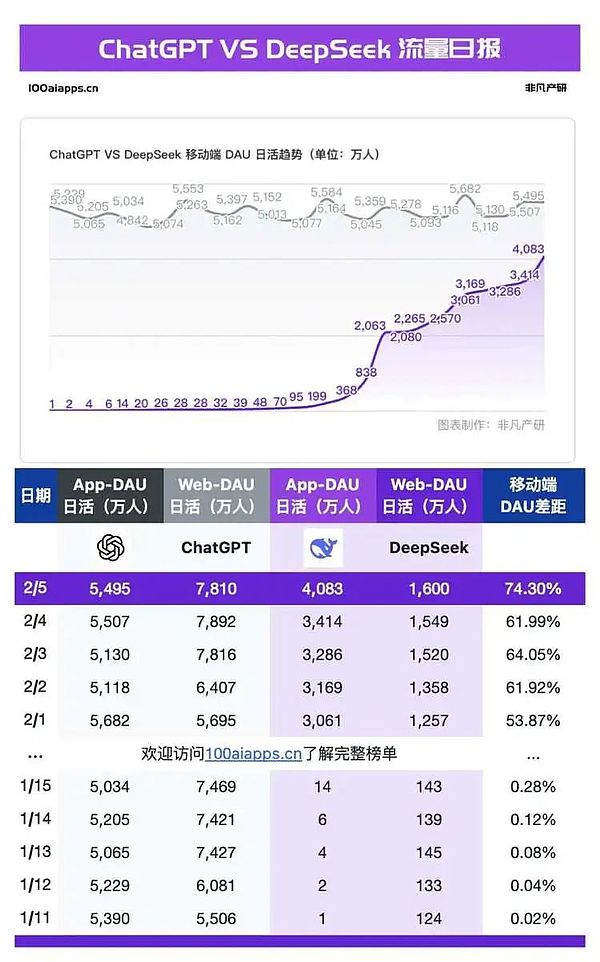
DeepSeekのモバイルローンチから26日後の2月5日には、1日のアクティビティが4,000万件を突破し、ChatGPTのモバイル1日のアクティビティは5,495万件、DeepSeekはChatGPTの74.3%でした。DeepSeekが急成長曲線を踏み出したのとほぼ同時に、サーバーが混雑しているとのツイートが相次ぎ、世界中のユーザーがちょっとした質問でダウンタイムが発生する不便さを体験するようになり、DeepSeekのピンタイサイトなどあらゆる代替アクセスが登場し始め、大手クラウドプロバイダー、チップメーカー、インフラ企業でライブ配信が行われ、個人向けの導入チュートリアルがあちこちで見られるようになった。しかし、その熱狂から解放されることはありませんでした。世界中のほぼすべての主要ベンダーがDeepSeekの導入をサポートしていると主張していますが、それでもなお、どこのユーザーもサービスの不安定さを口にしています。
舞台裏で何が起こっているのでしょうか?
「混雑するDeepSeekサーバー」に対する人々の不満は、以前のChatGPTベースのAIトップストリーミングアプリがほとんどラグを経験しなかったという事実から来ています。
このような「DeepSeekのサーバーが混雑している」という不満は、以前のChatGPTベースのAIトップストリーミングアプリではほとんどラグが発生しなかったことに起因しています。
OpenAIサービスの開始以来、ChatGPTはP0レベル(最も深刻なインシデントレベル)のダウンタイムインシデントを数回経験していますが、全体的には比較的信頼性が高く、イノベーションと安定性のバランスを見出し、徐々に同様の従来のクラウドサービスの重要な構成要素となっています。

ChatGPTの広範なダウンタイムはそれほど多くありません
ChatGPTの推論プロセスは比較的安定しており、エンコードとデコードの2つのステップがあります。2つのステップをデコードし、エンコード段階は、入力テキストをベクトルに変換し、ベクトルは、入力テキストの意味情報を含んでいるデコード段階は、ChatGPTは、要件を満たす完全な文の生成まで、次の単語やフレーズを生成するためにTransformerモデルを介して、コンテキストとして、以前に生成されたテキストを使用し、大きなモデル自体はデコーダ(デコーダ)アーキテクチャに属し、デコードステージデコーディングステージは、1トークン(テキストを処理するときのビッグモデルの最小単位)の出力プロセスであり、ChatGPTに質問があるたびに、推論プロセスが開始されます。
例えば、ChatGPTに「今日の気分はどうですか」と質問された場合、ChatGPTはこの文章をエンコードし、各レイヤーの注目表現を生成し、過去の全てのトークンの注目表現に基づいて、最初の出力トークン「I」を予測し、その後にデコードします。デコード後、"I "は "How are you feeling today? "にスプライスされる。その後、"私 "をデコードし、"I "を "How are you feeling today? "にスプライスする。I "を解読し、新しい注意表現を得て、次のトークン:"of "を予測し、第1ステップ、第2ステップのサイクルを経て、最終的に "How is your mood today? "を得る。私は上機嫌です。"
コンテナをオーケストレーションするツールであるKubernetesは、ChatGPTの「司令塔」として、サーバーリソースのスケジューリングと割り当てを行う。ユーザーの流入がKubernetesコントロールプレーンの処理能力を超えると、ChatGPTシステムの完全なシャットダウンにつながる可能性があります。
ChatGPTがダウンした回数の合計はそれほど多くはありませんが、その背後にはそれを支える強力なリソースがあり、安定した運用を維持する背後には強力な演算があり、これは人々が見落としている分野です。
一般に、推論処理ではデータサイズが小さくなりがちなので、演算能力への要求はトレーニングほど高くない。いくつかの業界の試算では、大規模モデルの推論の通常のプロセスでは、メモリモデルパラメータ重みの主な占有率が頭の大部分、おそらく80%以上を占めると指摘されています。現実には、ChatGPTの内蔵モデルはDeepSeek-R1の671Bよりも小さく、ChatGPTはDeepSeekよりもはるかにGPUパワーがあるため、当然DS-R1よりも安定したパフォーマンスを示します。
DeepSeek-V3もR1も671Bモデルで、モデルの起動過程は推論過程であり、演算予備の推論はユーザー量に並ぶ必要があり、例えば1億人のユーザーが1億枚のグラフィックカードを装備する必要があるなど、巨大なだけでなく、演算予備の訓練とは過程から独立しており、関係がない。すべての情報から、DSのグラフィックカードと演算準備金は明らかに不十分であるため、頻繁に遅れている。
この比較は、ChatGPTの絹のように滑らかなエクスペリエンスに順応してきたユーザーにとっては、特にR1への関心が高まっている今、慣れたものではありません。
そして、慎重に比較すると、OpenAIとDeepSeekは非常に異なる状況に遭遇します。
前者はマイクロソフトの後ろ盾があり、OpenAIの独占プラットフォームとして、ChatGPT、Dalle-E 2イメージジェネレーター、GitHub Copilot自動コーディングツールを備えたMicrosoft Azureクラウドサービスを提供しています。は、サードパーティのクラウド・プロバイダーに依存するのではなく、グーグルと同様に自社で構築したデータセンターに依存している。Silicon Planetが公開情報を確認したところ、DeepSeekはいかなるレベルでもクラウドベンダーのチップメーカーとの協力関係をオープンにしていないことが明らかになった(クラウドベンダーは春節の間、DeepSeekのモデルを自社上で走らせることを発表しているが、実際に意味のある協力は行っていない)。
そして、DeepSeekが前例のないユーザー数の伸びを経験しているということは、ChatGPTよりもストレスの多い状況に対するリードタイムが短いということでもあります。
DeepSeekの良好なパフォーマンスは、ハードウェアとシステムの両レベルで行った全体的な最適化から来ています。DeepSeekの親会社であるPhantom Quantitativeは、2019年にFirefly Iスーパーコンピューティングクラスターを構築するために2億ドルを費やし、22年までに10,000枚のA100グラフィックカードを黙々と格納していました。より効率的な並列トレーニングのために、DeepSeekは独自のHAI LLMトレーニングフレームワークを開発しました。業界では、Fireflyクラスタは数千から数万の高性能GPU(NVIDIA A100/H100や国産チップなど)を使用して、強力な並列計算機能を提供していたのではないかと考えられている。現在、FireflyクラスタはDeepSeek-R1、DeepSeek-MoE、その他のモデルトレーニングをサポートしており、数学やコードなどの複雑なタスクにおいてGPT-4レベルに近い性能を発揮します。
ファイアフライ・クラスタは、新しいアーキテクチャとアプローチにおけるDeepSeekの発見の旅を象徴しており、このようなイノベーションを通じて、DSはトレーニングのコストを削減し、最先端の欧米モデルの数分の一の演算で、トップクラスのAIモデルの性能に匹敵するR1をトレーニングできると確信するに至りました。DeepSeekは、1万台のA100、1万台のH100、1万台の "特別仕様 "H800、3万台の "特別仕様 "H20を含む、6万台のNVIDIA GPUカードを搭載しています。
これは、R1が十分な量のカードを持っていることを暗示しているようだ。しかし実際には、推論モデルとしてのR1は、OpenAIのO3に対してベンチマークされており、O3は回答のためにより多くのコンピューティングパワーを配置する必要がありますが、DSのトレーニングコスト側で節約されたコンピューティングパワーと、推論コスト側で突然増加したコンピューティングパワーのどちらが高いかは明らかではありません。
DeepSeek-V3とDeepSeek-R1はどちらも大規模な言語モデルですが、その動作方法に違いがあることは言及に値します:DeepSeek-V3はChatGPTに似たコマンドモデルで、プロンプトを受信し、対応するテキストを生成して返答します。しかし、DeepSeek-R1は推論モデルであり、ユーザーがR1に質問をすると、最初に多くの推論プロセスを行い、最終的な答えを生成します。R1によって生成されたトークンの最初のものは、思考プロセスの多くのチェーンであり、モデルは答えを生成する前に質問を説明し、質問を分解し、これらの推論プロセスのすべてが迅速にトークンの形で生成されます。
Youtubeキャピタルの副社長である温廷涵の見解によると、前述のDeepSeekの膨大な演算備蓄は訓練段階を指しており、訓練段階の演算チームは計画的で、予測可能で、演算不足に陥りにくいが、推論演算は主にユーザーの規模と使用状況に依存するため、より不確実であり、比較的弾力的であり、「推論演算は一定の規則性に従って成長するが、推論演算は一定のパターンに従って成長するため、ユーザーの規模と使用状況にとって容易ではない。一定の法則性に沿って成長するが、DeepSeekが驚異的な製品になったことで、ユーザーの規模や利用率が短期間で爆発的に伸び、推論段階の演算の需要が爆発的に伸びたため、タイムラグが生じた。"
インスタントアクティブモデルのプロダクトデザイナーで、独立系開発者の桂扎は、カードの量がDeepSeekの遅れの主な原因であることに同意し、彼は、DSは、世界中の140の市場で最もダウンロード数の多い現在のモバイルアプリケーションとして、現在のカードは、新しいカードでも、どのような場合でも持ちこたえることができないと考えている。"新しいカードでクラウドを作るには時間がかかるので"
"NVIDIA A100、H100と公正な市場価格のコストの1時間を実行するために他のチップは、出力トークンの推論コストからDeepSeekはOpenAI同様のモデルo1よりも安いです90%以上、これは皆の計算バイアスとあまりないので、モデルアーキテクチャMOE自体が主な問題ではありませんが、DSはGPUを持っています。しかし、DSが所有するGPUの数によって、1分あたりに生成・提供できるトークンの最大数が決まってしまう。"たとえ、より多くのGPUを、事前訓練研究の代わりにユーザーにサービスを提供するための推論に使用できたとしても、上限は存在する。AIネイティブアプリ「Kitten Fill Light」の開発者であるYunfei Chen氏も同様の見解を持っている。
一部の業界関係者はまた、DeepSeekの遅れの本質は、プライベートクラウドが良い仕事をしていないことだとSilicon Star Peopleに言及している。
しかし、R1自身のサービスにおけるこのラグに対する一見明白な解決策の1つは、サードパーティがサービスを提供することである。それが、旧正月に目撃した最も活気のある風景です。ベンダーはDeepSeekの需要を取り込むためにサービスを展開しています。
1月31日、NVIDIAは、DeepSeekの結果としてNVIDIAの市場価値が一夜にして6000億ドル近く蒸発した後、NVIDIA NIMでDeepSeek-R1が利用可能になったと発表しました。同日、アマゾンクラウドAWSのユーザーは、同社のAIプラットフォームであるAmazon BedrockとAmazon SageMaker AIにDeepSeekの最新のR1ベースモデルを導入できるようになった。これには、Perplexity、Cursor、DeepSeekへの一括アクセスなど、AIアプリケーションの新規参入者が続いた。一方、microsoftは、AmazonとNvidiaに先駆けて、自社のクラウドサービスAzureとGithubでDeepSeek-R1を展開した。
旧正月4日目の2月1日からは、Huawei Cloud、Ali Cloud、ByteDanceのVolcano Engine、Tencent Cloudがこれに加わり、DeepSeekのフルシリーズ、フルサイズモデルのデプロイサービスをおおむね提供している。その後、Wallen Technology、Hanbo Semiconductor、Rise、MuXiといったAIチップベンダーが登場し、彼らはオリジナルのDeepSeekや、より小型の蒸留版を適応させたと主張した。ソフトウェア会社、UFIDA、Kingdeeなどは、製品の一部のDeepSeekモデルにアクセスし、製品のパワーを強化し、最終的にレノボ、華為技術などの端末メーカーは、その製品の一部の栄光は、DeepSeekモデルにアクセスし、パーソナルアシスタントや車のインテリジェントコックピットのエンド側として使用されます。
これまでのところ、DeepSeekは、国内外のクラウドベンダー、演算子、証券会社、国家プラットフォーム国家スーパーコンピューティングインターネットプラットフォームを含む友人の包括的かつ大規模なサークルを誘致するために、独自の価値に依存しています。DeepSeek-R1は完全なオープンソースモデルであるため、アクセスするサービスプロバイダーはすべてDSモデルの受益者となっている。これは、DSの評判を大幅に高めましたが、同時に、より頻繁にラグ現象を引き起こし、サービスプロバイダーとDS自体がますますユーザーの流入に閉じ込められているが、トリックの安定的な使用の問題を解決するための鍵を見つけていない。
DeepSeek V3とR1のオリジナルモデルは、クラウド上で実行するのに適した6710億パラメータを、クラウドベンダー自身が十分すぎるほどのコンピューティングパワーと推論能力を持っていることを考慮すると、彼らは企業の使用のしきい値を減らすために、オンラインDeepSeek関連の展開サービスであり、DeepSeekモデルの展開は、DSのモデルの外部APIを提供するために、DS自体に比べて。APIを提供することで、DSの公式使用よりも優れたエクスペリエンスを提供できると考えられていました。
しかし、現実には、DeepSeek - R1モデルは、サービス内の独自の経験の問題が解決されていない上で実行されるということです、サービスプロバイダは、カードが不足していないことを外界が、実際には、彼らはR1を展開し、不安定なフィードバックの経験への応答に開発者は、推論のためにR1に割り当てることができるカードの量に多くにあるR1とまったく同じの頻度は、あまりにも多くありません。
"R1の熱は高いままであり、サービスプロバイダーは他のモデルへのアクセスをやりくりする必要があり、R1に提供できるカードは非常に限られており、R1の熱は非常に高いため、R1に乗って比較的安い価格で提供する人は洗脳されてしまう。"モデル製品のデザイナーであり、インディーズ開発者でもあるGouzou氏は、その理由をSilicon Star Peopleに説明した。
モデル展開の最適化は、トレーニングの完了から実際のハードウェアの展開まで、さまざまな側面をカバーする広い分野であり、何重もの作業を伴いますが、DeepSeekの遅延事件の場合、原因はおそらく、大きすぎるモデルや、本番前の最適化の準備不足など、もっと単純なものでした。
人気のある大規模モデルが本番稼働する前には、トレーニングデータと本番環境データの整合性、モデルの推論効果に影響するデータ遅延とリアルタイム性、オンライン推論効率とリソース消費が高すぎること、モデルの汎化能力が不十分であること、サービスの安定性、API、システム統合などのエンジニアリング面など、テクノロジー、エンジニアリング、ビジネスに関わる複数の課題に遭遇します。
オンラインの前に赤い大きなモデルの多くは、推論の最適化の良い仕事をすることが高く評価され、これは、計算時間とメモリの問題のためであり、前者は、推論の遅延が長すぎることを指し、その結果、貧しいユーザーエクスペリエンス、さらには遅延の需要を満たすことができない、つまり、遅れやその他の現象は、後者は、大規模なモデルのパラメトリック数を指し、メモリを消費し、さらに単一のGPUカードを置くことができない、また遅れにつながる。
温Tingcanは、シリコンスターの人々に理由を説明し、彼はサービスプロバイダは、R1のサービスが課題に遭遇言及提供するために、本質は、DSのモデル構造が特殊である、モデルが大きすぎる+ MOE(専門家のハイブリッド構造、効率的なコンピューティングの方法)アーキテクチャは、"(サービスプロバイダ)最適化には時間が必要ですが、市場の熱は、時間窓なので、最初にされ、最適化されたのではなく、完全に最適化され、その後、ライブになります。完全に最適化してから本稼働させるのではなく。
同時に、この遅れはまた、DS自身の演算埋蔵量がおそらくSemiAnalysisが説明したほど大きくないことを示しており、幻のファンド会社はカードを使用する必要があり、DeepSeekのトレーニングチームはカードを使用する必要があり、ユーザーに排出できるカードは多くありませんでした。現在の開発状況によると、短期的には、DeepSeekは、サービスをレンタルするためにお金を費やすインセンティブを持っていない可能性があり、その後、より良い経験をユーザーに提供するために無料、彼らはビジネスモデルのCエンドの最初の波が明確に整理されるまで待つ可能性が高く、その後、サービスレンタルの問題を検討し、また、カードが短い期間ではありません続けることを意味します。
"彼らはおそらく2段階のアクションが必要です:1)無料ユーザーモデルの使用量を制限するために支払いメカニズムを作る、2)協力し、他の人のGPUリソースを使用するクラウドサービスベンダーを探す。"開発者のChen Yunfeiが示した暫定的な解決策は、業界ではかなりコンセンサスとなっています。
しかし、今のところ、ディープシークは「ビジーサーバー」問題をあまり心配していないようだ。AGIを追い求める企業として、ディープシークはユーザーの流入にあまり注力したくないようだ。近い将来、ユーザーは「サーバーが混雑しています」という画面に慣れなければならなくなりそうだ。
アストラゼネカがAI企業アブスキーと提携し、2億4700万ドルを投じてがんと闘う先進的な抗体を開発する画期的なベンチャー企業となる。
YouQuanFTXとSBFは昨年の有力なドナーだったが、この業界はワシントンから去ってはいないようだ。
 Alex
AlexAIによって蘇ったジミー・スチュワートの声は、伝統と革新を融合させながら、Calmで就寝前の物語をナレーションする。Respeecherの倫理的アプローチは、技術の進歩とレガシーボイスへの敬意との微妙なバランスを強調している。
 Joy
Joy暗号通貨業界の著名な支持者であるパトリック・マクヘンリー議員が引退を表明し、2025年1月をもって現職を終える。
 Aaron
Aaron2023年、イーサリアムのレイヤー2ネットワークはユーザーエンゲージメントを高め、戦略的な進歩を遂げるが、トークン価値はセクター全体の成長と一致しないままである。
YouQuanインターネット上で人気のイヌをモチーフにしたミーム通貨Dogecoinが、X(旧Twitter)の決済オプションとして重要な役割を果たすかもしれない。
AaronNostrアセット・プロトコルはクレームに反論し、ライトニング・ネットワークとNostrエコシステムにおいて、開発者に力を与え、金融アプリケーションを革新することへのコミットメントを再確認した。
 Hui Xin
Hui Xin韓国の小・中・高等学校の生徒たちは、Non-Fungible Tokens(NFT)やブロックチェーンなどのデジタル資産に関する知識を再定義している。こうした若い頭脳を対象とした最近の教育イニシアティブは、彼らの理解力を高めただけでなく、資産化を通じて個人の考えやコンテンツを価値ある資産に変える能力を高めている。
JoyソフトウェアとITコンサルティングの雄であるIBMは、Hyper Protect Offline Signing Orchestratorの導入により、Web3の分野で波紋を広げている。
AaronCoinbase Walletの最新機能は、メッセージングアプリやソーシャルメディアを含む複数のプラットフォーム上の共有リンクを通じて送金できるようにすることで、暗号通貨の送金を簡素化する。
Joy