アリペイの親会社、中国で日常業務を効率化するAI「ライフアシスタント」を発表
アント・グループは、アリペイを通じた決済、注文、予約など様々なサービスを統合したAI搭載の生活アシスタントアプリ「支付宝」を発表した。この動きは、2023年に規制上の課題と多額の罰金に直面した後の、アントによるAI主導のソリューションへのシフトを反映している。
 Weatherly
Weatherly

出典:PermaDAO
AOはオンチェーンAIのために設計された非同期通信ネットワークで、Arweaveとの組み合わせにより高性能なオフチェーン計算と永続的なデータ保存を可能にします。記事では、AO上でAIプロセスを実行する手順が説明されており、現在は小規模なモデルしかサポートしていませんが、将来的にはより複雑な計算機能をサポートし、AIオンチェーンの将来が期待されています。
AOは本来、オンチェーンAIのために設計されています
2023年はAIの年と呼ばれており、AIのさまざまなビッグモデルやアプリケーションが登場しています。
AIの開発は、Web3の世界でも重要な位置を占めています。
AIの開発もWeb3の世界の重要な部分です。しかし長い間、「ブロックチェーンの不可能な三角形」によって、ブロックチェーンコンピューティングは高価で混雑した状態に置かれ、Web3上でのAIの発展を妨げてきました。しかし今、この状況はAOで最初に改善され、無限の可能性を見せている。
AOは、メッセージ駆動型の非同期通信ネットワークとして設計されています。Stored Consensus Paradigm (SCP)に基づき、AOはArweaveの上で動作し、Arweaveとのシームレスな統合を可能にします。この革新的なパラダイムでは、ストレージ(コンセンサス)と計算が効果的に分離され、オフチェーンでの計算とオンチェーンでのコンセンサスが可能になります。
高性能コンピューティング:スマートコントラクトの計算はオフチェーンで実行され、オンチェーンブロックコンセンサスプロセスによる制約を受けなくなるため、計算性能が大幅に向上します。Arweaveは、すべての命令、中間状態、計算結果の永続的なストレージをAOに提供し、AOのデータ可用性とコンセンサス層の役割を果たします。その結果、GPUを使用したコンピューティングを含む、高性能コンピューティングが可能になります。
永続的なデータ:これは、Arweaveが長い間取り組んできたことです。AIのトレーニングで重要なのはトレーニングデータの収集であり、それがアーウィーブの強みであることを知っています。少なくとも200年分のデータを永続的に保有しているAO + Arweaveは、そのエコシステムに豊富なデータセットを有している。
さらに、AOとArweaveの創設者であるサムは、6月のローンチ・イベントで、aos-llamaに基づく最初のAIプロセスをデモした。
使用されたモデルはllama 2で、huggingfaceでオープンソース化されています。
Llama land
Llama Landは、AI技術を核とした先進的なAOプラットフォーム上に構築された、最先端の多人数同時参加型オンライン(MMO)ゲームです。また、AO + Arweaveエコシステム初のAIアプリケーションでもあります。最大の特徴は、ラマコインの発行が100%AI制御であることです。つまり、ユーザーはラマ王に祈りを捧げ、ラマ王からラマコインの報酬を得ることができ、マップ内のラマジョーカーとラマオラクルもAIプロセスに基づいたNPCです。img src="https://img.jinse.cn/7295195_image3.png">
では、AOでAIプロセスを実行する方法を見てみましょう。
1.全体的な紹介
私たちは、独自のAIアプリを実装するために、AO上にすでに展開されているSamのAIサービスを使用しています。SamによってデプロイされたAIサービスは、llama-herdとllama-worker(複数のllama-worker)の2つの部分から構成されています。llama-herdはAIタスクの割り当てとAIタスクの価格設定を担当し、llama-workerは実際に大きなモデルを実行するプロセスだ。そして、私たちのAIアプリケーションは、llama-herdをリクエストし、リクエスト時に一定額のwarを支払うことで、AI機能を実装します。
注:なぜ、私たちのAIアプリケーションを実装するために、私たち自身のllama-workerを実行しないのか不思議に思うかもしれませんね?なぜなら、AIモジュールはプロセスとしてインスタンス化されるときに15GBのメモリを必要とし、自分自身でインスタンス化するとメモリ不足エラーになるからです。
2.プロセスの作成とwARのトップアップ
最初に、プロセスを作成し、先に進む前にそれらを最新バージョンにアップグレードしてみる必要があります。いくつかのミスを避け、多くの時間を節約することができます。

AIプロセスを実行するには、わずかなコストがかかります。AIプロセスを実行するには少量のwARが必要で、arconnect経由で転送に成功すると、プロセス内にAction = Credit-Noticeというメッセージが表示されます。AIプロセスを1回実行するにはwARが必要ですが、それほど多くないので、デモ目的であれば0.001wARをプロセスに転送することができます。
注意:wARはAOXクロスチェーンブリッジ経由で取得でき、3~30分かかります。
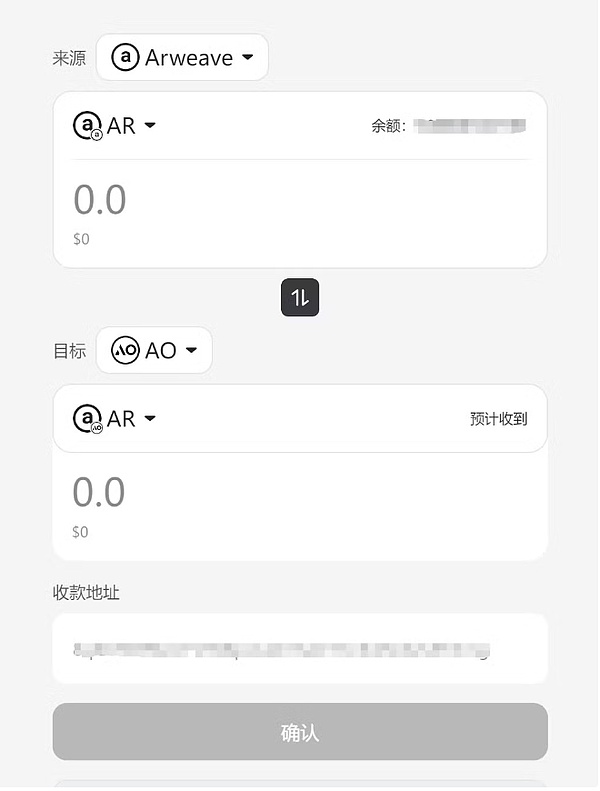
以下のコマンドで、現在のプロセスのwARのバランスを見ることができます。下記は5回ほど実行した後に残ったwARです。消費された量は、トークンの長さだけでなく、ビッグモデルの1回の実行のための現在のリアルタイムの価格にも関連しています。また、現在のリクエストが混雑している状態であれば、追加コストも発生する。(この投稿の最後に、興味のある方のために、料金計算をコードでより詳しく説明します。)
注:ここでの小数点は12桁です。つまり、999999673は0.000999999673 wARです。

3.img src="https://img.jinse.cn/7295201_image3.png" title="7295201" alt="M4af1mDbuTj2JBAET3UP2RA1VheGGnrQ2cDqeVIk.jpeg">
APMはasoパッケージとして知られています。APMはaoパッケージ管理として知られています。 AIプロセスを構築するには、APMを通じて対応するパッケージをインストールする必要があります。上記のコマンドを実行し、対応するプロンプトが表示されれば、APMのインストール/更新は成功です。
4.Install Llama Herder

実行が完了すると、プロセス内にLlamaオブジェクトが存在し、Llamaと入力することでアクセスできるようになり、 Llama Herderが正常にインストールされます。

注意: 実行中のプロセスに十分なwARがない場合、Llama.runメソッドは実行されず、Transfer Errorが発生します。
5.Hello Llama
次に、簡単なインタラクションを行います。
次に、簡単なインタラクションを行います。AIプロセスに "人生の意味は何ですか?"と尋ねてください。AIプロセスの実行には数分かかり、AIタスクがキューに入っている場合はそれ以上かかる。
下のコードで返されるように、AIは "人生の意味は、常に人間を魅了してきた深く哲学的な質問です "と答える。

注意: 実行中のプロセスに十分なwARがない場合、Llama.runメソッドは実行できず、転送エラーが発生します。 wARをトップアップする最初のステップに従う必要があります。
6.ラマジョーカーを作る
もう一歩踏み込んで、ラマジョーカーの実装を見てみましょう。(スペースの都合上、コアとなるAI関連のコードのみを示しています)。
Llama Jokerの作り方は、Web 2のAIアプリでチャットボットを作る方法に似ていて、実はとてもシンプルです。
まず、ビルドしたプロンプトで、<|system|> / <|user|> / <|assistant|>で異なる役割を区別します。
次に、プロンプトの固定部分を特定します。Llama Jokerの例では、それは<|system|>で、内容は「与えられたトピックについてジョークを言ってください」です。
最後に、Llama Joker Npcを作って、ユーザーと対話させます。しかし、ここではスペースの都合上、変数 local userContent = "cats" が直接定義されています。これは、ユーザーが猫に関連したジョークを聞きたいことを示しています。
とても簡単ではないでしょうか。


オンチェーンでAIを実装する能力は、以前には想像もできなかったものでした。現在では、AO上のAIに基づくアプリケーションの高い完成度を達成することが可能であり、その見通しは期待されており、すべての人に想像のための無限のスペースを与えています。
しかし今のところ、限界は明らかだ。現時点では、2GB程度の「小さな言語モデル」しかサポートできず、GPUを演算に使うこともまだできない。ありがたいことに、AOのアーキテクチャはこれらの欠点に対処するように設計されている。例えば、GPU対応のwasm仮想マシンのコンパイルなどだ。
近い将来、AOチェーン上でAIが開花するのを楽しみにしています。
付録
前回は、Llama AIのコスト計算の様子とともに、落とし穴を残しました。
以下は初期化後のLlamaオブジェクトで、それぞれ重要なものについての私の理解を示しています。
M.herder: ラマ牧童サービスの識別子またはアドレスを格納します。
M.token: AIサービスの支払いに使用されるトークン
M.feeBase: 基本料金。
M.feeToken:トークンあたりの料金。リクエストのトークン数に基づいて追加料金を計算するために使用されます。
M.lastMultiplier:最後のトランザクションのコストに対する乗数。
M.queueLength:料金計算に影響する、現在のリクエストキューの長さ。
M.feeBump:料金増加係数。デフォルトでは1.005に設定されており、毎回0.5%増加します。

M.feeBase の初期値は0です。
M.getPrices関数でLlama Herderに最新の価格情報を要求します。
M.feeBase、feeToken、M.lastMultiplier、M.queueLengthはすべてM.herderから要求され、リアルタイムで変化するInfo-Responseメッセージを受け取ります。これにより、最新の価格関連フィールドの値が常に維持されます。
料金を計算する正確な手順:
M.feeBase にfeeTokenとトークン数の積を加えたものに基づいて初期料金を取得する。
その後、初期料金にM.lastMultiplierを掛けます。
最後に、リクエストのキューがある場合、M.feeBump(1.005)を掛けて最終的な料金を得ます。
引用リンク
1.Arweaveのモデルアドレス:
https://arweave.net/。ISrbGzQot05rs_HKC08O_SmkipYQnqgB1yC3mjZeEo
2.left;">https://github.com/samcamwilliams/aos-llama
3.AOXクロスリンクブリッジ:
https://aox.arweave.dev/
アント・グループは、アリペイを通じた決済、注文、予約など様々なサービスを統合したAI搭載の生活アシスタントアプリ「支付宝」を発表した。この動きは、2023年に規制上の課題と多額の罰金に直面した後の、アントによるAI主導のソリューションへのシフトを反映している。
Weatherlyウォレットは、暗号市場参加者にとって不可欠なツールの1つとして、インフラ分野で非常に重要な位置を占めている。
 JinseFinance
JinseFinanceチャーリー・マンガーの遺産には、暗号通貨に対する不屈の批判、暗号通貨を "crypto crappo "と断じること、米国での禁止を主張することなどがある。彼の率直な見解は、進化する金融業界における対話の火付け役となっている。
 Huang Bo
Huang Boバークシャー・ハサウェイのチャーリー・マンガー副会長が2023年11月28日、カリフォルニア州ロサンゼルスの病院で99歳の生涯を閉じた。
 Olive
Oliveバークシャー・ハサウェイの副会長であり、ウォーレン・バフェットの長年のビジネス・パートナーであったチャーリー・マンガーが99歳で亡くなった。辛辣な批評で知られるマンガー氏は、一貫してビットコインを「ネズミの毒」とレッテルを貼り、米国への影響に軽蔑の念を示した。
 Bernice
Berniceカンボジア国立銀行(NBC)はこのほどアリペイとの提携を固め、NBCのデジタル通貨バコンを利用するユーザーにとって国境を越えた取引を可能にする極めて重要な一歩を踏み出した。
 Jasper
Jasperバークシャー ハサウェイの副会長は、水曜日のデイリー ジャーナルの年次株主総会でコメントしました。
 CryptoSlate
CryptoSlateウォーレン・バフェット氏の右腕でバークシャー・ハサウェイ副会長の暗号通貨に関する想像力豊かな説明が話題になった。
 Cointelegraph
Cointelegraph