NYCBの波乱:シグネチャー・バンク買収から金融不安まで
NYCBによるシグネチャー・バンクの買収は当初は利益をもたらしたが、2億6,000万ドルの第4四半期の損失と減配はより深い課題を反映しており、暗号の役割をめぐる議論を巻き起こしている。
 Miyuki
Miyuki

著者:AI Edge;翻訳:Peggy、BlockBeats
本記事では、Claude CodeとObsidianを基盤として構築された個人用ナレッジシステムについて紹介します。その核心は、従来のRAGモデルにおける「都度検索・一時的な情報取得」という使い方ではなく、AIに進化可能なナレッジベース(Wiki)を継続的に構築・維持させる試みにあります。
構造的には、このシステムは3つの層に分解できます:
・第一に、ノート、記事、文字起こしなど、変更不可能な入力ソースを含む原始データ層;
・第二に、AIによって維持される構造化ナレッジベースで、継続的な更新を通じて相互参照と関係構築を行います;
・第三に、知識の組織化方法とシステムの動作ロジックを規定するスキーマ規則層です。
この構造を中心に、システムは3つのコア操作を通じて動作します:Ingest(取り込み)は外部情報を継続的に体系に取り込み、Query(検索)は知識の即時呼び出しを実現し、Lint(検証)は構造の一貫性をチェックし、潜在的な問題を修正します。
このメカニズムの下では、知識は単発の対話結果にとどまることなく、「書き込み—整理—再利用」のサイクルを通じて、徐々に再利用可能な長期資産として蓄積されていきます。著者はこれに基づき、このモデルが知識に「複利」のような蓄積効果をもたらすと提唱しています。一方で個人の認知的負荷を軽減し、他方でモデルの出力精度と文脈の一貫性を高めるのです。
しかし、このシステムが効果的に機能するためには、継続的な入力とメンテナンスという前提が必要です。安定したデータの投入と構造の更新が欠如すれば、この「第二の脳」は真の蓄積効果を生み出すことが難しくなり、その優位性も失われてしまうでしょう。
以下が原文です:
Claude Code + Obsidianは、私がこれまで使った中で最も強力なAIの組み合わせだ。
私はほぼ「AIによる第二の脳」を構築し、自分の思考、読書、執筆、オンラインリサーチなどのすべてをそこに組み込んだ。そこには、私のビジネスプラン、公開したすべてのYouTube動画、執筆した記事、そして私にとって重要なあらゆるコンテンツが含まれている。
Claude Code + Obsidianは、すでに様々なプラットフォームで急速に人気を集めていますが、これは決して偶然ではありません。
私個人にとって、このAIシステムは認知的負荷を大幅に軽減し、ビジネスであれ私生活であれ、本当に重要なことに集中できるようにしてくれました。

私の Claude Code + Obsidian システム
このシステムは一見複雑に見えるかもしれませんが、実際に構築するのにかかるのはわずか5分です。さらに重要なのは、記憶機能を備えており、使い続けることで絶えず自己最適化される点です。
これから、この「AIセカンドブレイン」システムを段階を追って再現する方法を解説します。これは間違いなく、あなたの生産性を確実に向上させてくれるでしょう。
記事の最後までお読みになることをお勧めします。記事の最後には、完全な「Claude Code + Obsidian」操作クイックリファレンス表と、記事内で言及したすべてのリソース(すべて無料)を添付します。
このシステムは私一人のオリジナルではなく、数日前にAndrej Karpathy氏が投稿した「LLMナレッジベース」に関する大反響を呼んだツイートから着想を得たものです。
関連記事:https://x.com/karpathy/status/2039805659525644595
このツイートが急速に拡散した理由は、現在のAI開発における重要な課題の解決策を示唆していたからです。
その問題とは、新しい会話を始めたり、新しいAIツールに切り替えたりするたびに、プロンプトを再入力したり文脈を補足したりしなければならず、事実上ゼロからのスタートを強いられるという点です。
しかし、この一連のシステムプロンプトをObsidianやClaude Codeと組み合わせることで、この問題は根本的に解決され、同時にAIの出力品質も大幅に向上させることができます。
システム全体は4つのコアモジュールで構成されています:
1、あなたのデータ:記事、ノート、文字起こし、アイデアや思考などを含みます
2、整理方法:Claude Code を通じて Obsidian 内で自動的に整理されます
3、即時呼び出し:この「データベース」にいつでも質問して、答えを得ることができます
4、進化する記憶:システムは使い続けるほど賢くなっていきます
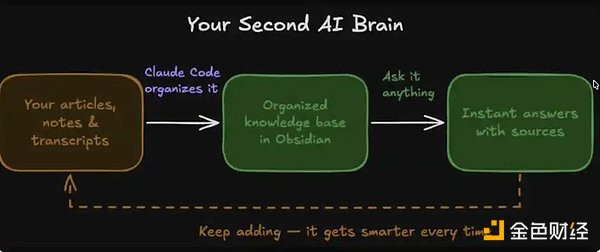
あなたのAIセカンドブレイン
このシステムの真の力はどこにあるのでしょうか?
人間として、私たちの認知能力には限界があります。私たちは物事を忘れてしまうし、時には異なる考えをつなぎ合わせるのが難しいこともあり、同時に追跡・処理できる情報には結局のところ上限があります。
しかし、4つのモジュールで構成されるこのシステムを活用することで、あなたは実質的に自身の認知的負荷を軽減し、「情報の接続、整理、理解」という作業をObsidianとClaude Codeに任せることができるのです。
あなたの考えは体系的に結びつけられ始め、あるノートが別のノートと自動的に関連付けられるようになります。そして、あなたはいつでもClaudeを通じて、これらの内容を再抽出、再構成、呼び出すことができます。
この構造の下では、あなたの知識はもはや断片的なものではなく、絶えず呼び出しや再構成が可能なネットワークとなります――その可能性はほぼ無限大です。
公式サイト: https://obsidian.md/
https://obsidian.md/
ダウンロードが完了すると、Obsidianは「Vault」を作成するよう促します。
これはパソコン上のフォルダのようなものと考えてください。ここにすべてのコンテンツを保存し、Claude Codeがこれらのデータにアクセスして管理できるようにします。
このVaultの名前は自由に設定できます。例えば、私はこれを「Obsidian Vault」と名付けています。
Obsidian Vault(ナレッジベース)
この Vault は、Obsidian がすべてのデータやノートを保存する場所であり、すべてのコンテンツは MD(Markdown)ファイルとして保存されます。
次に、Claude Codeにアクセスする方法を設定する必要があります。私にとって(そしておそらく大多数の人にとっても)、最も簡単な方法はデスクトップクライアントを直接使用することです。
メインのチャット画面で「Select Folder(フォルダを選択)」をクリックし、先ほど作成した Obsidian Vault を見つけて選択してください。
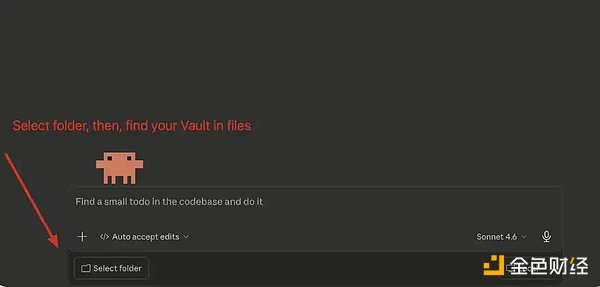
Claude Code:Vaultの接続
フォルダを選択したら、次はAndrej Karpathyのシステムプロンプトをメインチャットボックスに貼り付けます。
こちらのリンクからプロンプトをコピーできます:https://gist.github.com/karpathy/442a6bf555914893e9891c11519de94f

入力内容は以下のようになります:
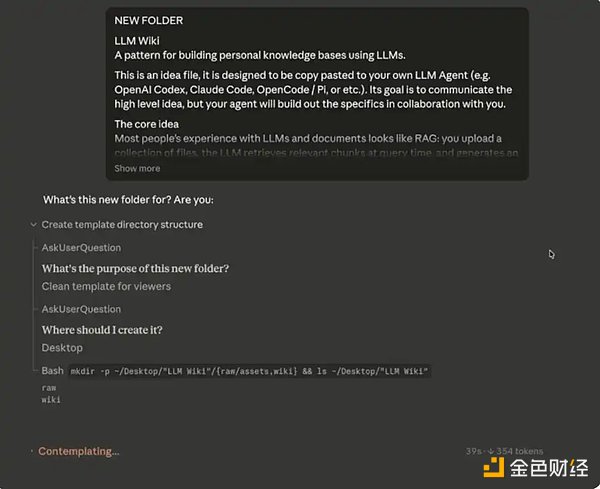
Claude Code の初期入力
ヒント:必要がなければ、Obsidianを手動で開く必要は全くありません。MDフォルダ(つまりあなたのVault)と関連データをClaude Codeに渡すだけで、これらのファイルに対して直接読み書きや修正を行うことができ、その内容は自動的にあなたのObsidian「第二の脳」に同期されます。
上記のシステムプロンプトを入力し終えると、Claude Codeは「セカンドブレイン」を初期化し、徐々にデータを充実させるために、いくつかのデータソースについて尋ねてきます。
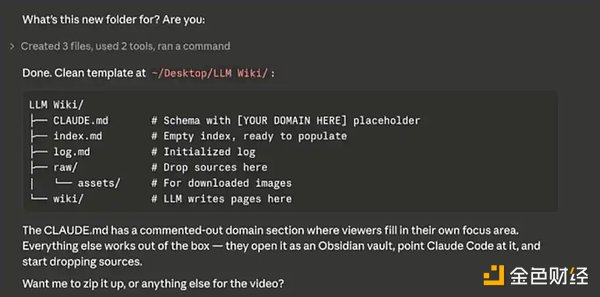
データベースの構築
Obsidianを「白紙のノート」のようなものだと考えてください。最初は自らコンテンツを入力することで、データベースが徐々に構築されていきます。インポート可能なコンテンツには、ノート、CSVファイル、Markdown / テキストファイルなどがあります。
実用的なアドバイス:
・現在使用しているノートツールからデータをエクスポートする
・Notionを使用している場合は、CSVファイルとしてエクスポートできます
・Claude(または他の大規模モデル)に自分の情報を整理させ、「セカンドブレイン」の初期化に活用する
・既存の記事、ブックマーク、アイデアなどを一括でインポートしましょう——これは初期データを構築する絶好の機会であり、その後も随時追加できます
注意すべき点は、私のようにデータ量の多いデータベースは、一朝一夕に完成するものではなく、時間をかけて継続的に入力し、徐々に蓄積されて形成されるということです。

私のデータベース
以上です。これであなたの「AIセカンドブレイン」の構築は完了し、運用を開始できます。続いて、さらに効率的に活用するための上級テクニックをいくつかご紹介します。
システムへのデータ追加をもっと簡単にしたい場合は、ObsidianのChrome拡張機能をインストールするだけです。これを使えば、ウェブページを閲覧中に「Add to Obsidian(Obsidianに追加)」をクリックするだけで、コンテンツをワンクリックでナレッジベースに保存できます。これにより、「セカンドブレイン」を構築するプロセスを非常にスムーズにしてくれます。
私自身も、記事やウェブページのデータ、研究資料などを収集するために、この機能を頻繁に利用しています。
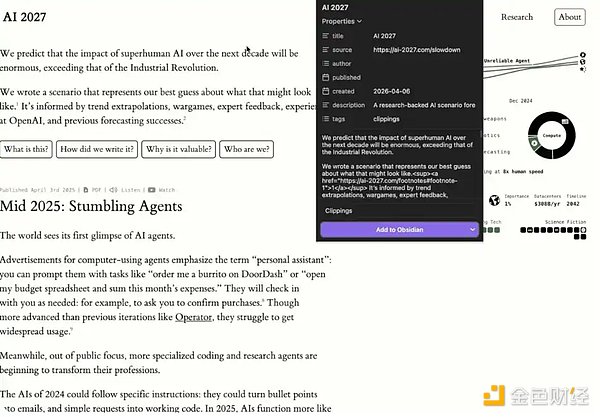
例:Obsidian Chrome拡張機能の使用
注意すべき点は、拡張機能を通じて追加されたデータは、最初は単なる「孤立したデータソース」に過ぎないということです。
次に、Claude Code に「Obsidian に [x] を追加しました。この内容を私の Wiki に統合してください」と指示することができます。
Claude Code は、これらの新しいデータを既存のコンテンツと自動的に関連付け、リンクを生成し、それをあなたの「セカンドブレイン」に真に統合します。これこそが、このツールセットが強力である理由です。
Andrej Karpathyは、2つの独立したフォルダ(Vault)を使用することを推奨しています:
・1つは仕事/ビジネス用
・もう1つは私生活/目標管理用
私自身の使用体験からも、この構造が最も明確で効果的だと感じています。
このシステムで最も価値のある使い方は、実はとてもシンプルです。LLMのプロンプトをより正確にすることです。
モデルがあなたの個人情報、ビジネスプラン、執筆の背景などのコンテキスト全体にアクセスできるようになると、より「カスタマイズされた」、現実の状況に近い高品質なプロンプト(さらには「スーパープロンプト」)を生成できるようになります。
もちろん、このシステムの用途はこれだけではありませんが、最も実用的なシナリオから始めたいのであれば、まずは「プロンプトの品質向上」から着手することを強くお勧めします。
Obsidianにおいて、「Orphans」とは、他のノートとリンクされていないデータポイントを指します。
この機能は、以下の点で非常に役立ちます:
・まだ統合されていないアイデアを見つける
・データベース内の「弱点」を発見する
・どの内容をさらに拡張または深める価値があるかを判断する
言い換えれば、これは単なる整理ツールであるだけでなく、思考の盲点を発見する手助けとなる仕組みでもあります。

Orphans(孤立ノード)
右上の「3つの点」をクリックして、Orphansのスイッチを見つけ、オンにすることで、まだ関連付けられていないコンテンツを確認できます。
これまで多くの利点、使用シーン、最適化方法について説明してきましたが、ではその欠点は何でしょうか?どのような状況では、このシステムの使用が適していないのでしょうか?
1、可視化に慣れていない人
このシステムの核心的な利点は、データを可視化して表示できることです。もしあなたがこの手法に依存していない、あるいは慣れていない場合、その恩恵は限定的になる可能性があります。
2、一定のメンテナンスコストが必要
データベースの継続的なメンテナンスを望まない場合、このシステムは適していないかもしれません。メンテナンスコストはそれほど高くありませんが、「セカンドブレイン」に継続的にデータを入力しなければ、その価値を十分に発揮することは困難です。
3、ストレージ容量の消費
すべてのコンテンツはMarkdownファイルとしてローカルに保存されるため、デバイスのストレージ容量を消費します。この点についても事前に考慮する必要があります。
NYCBによるシグネチャー・バンクの買収は当初は利益をもたらしたが、2億6,000万ドルの第4四半期の損失と減配はより深い課題を反映しており、暗号の役割をめぐる議論を巻き起こしている。
Miyukiルガノは、ビットコイン、CBDC、ステーブルコインを統合したデジタル金融のパイオニアであり、多様なデジタル通貨が共存し、伝統的な経済構造を変革する未来を提示している。
 Alex
AlexPixelmonはNFTの大失敗から、800万ドルの資金調達、戦略的パートナーシップ、ゲームの刷新、そしてMONトークンによるコミュニティ主導の未来で、有望な暗号プロジェクトへと変貌を遂げる。
 Brian
BrianインドのRBIは、暗号通貨課税の調整やCBDC開発における新興企業との協力に前向きな姿勢を示す一方で、イノベーションとプライバシーや規制の慎重さのバランスを取りながら、デジタル・ルピーの開発を慎重に進めている。
 Weiliang
WeiliangワルキューレはビットコインETFのカストディアンとしてBitGoと提携し、業界全体のカストディアン多様化の先駆けとなり、スポットビットコインETFの競争環境を激化させる。
MiyukiジェネシスとSECの和解金2100万ドルは、暗号規制の極めて重要な転換を意味し、ジェネシスとその関連会社に影響を与え、業界全体の規制遵守の先例となる。
AlexBybitは香港のライセンスを申請し、急成長するアジアの暗号通貨市場における戦略的拡大と競争激化を示唆。
Brianプロト・ダンク・シャーディングを特徴とするイーサリアムDencunのアップグレードは、コストの削減と効率性の向上を約束し、イーサリアムのスケーラビリティとブロックチェーンの革新における大きな飛躍を意味する。
WeiliangCybertraceは、アンドリュー・フォレストが偽の暗号プラットフォームを宣伝するディープフェイクビデオについて警告し、巧妙なデジタル詐欺の脅威が高まっていることを強調している。
Miyuki中国の暗号通貨取り締まりにもかかわらず、2023年のKyros Venturesのレポートによると、中国の投資家の33.3%がステーブルコインを支持しており、ベトナムの58.6%に次いで2位で、高いリスク選好を示している。70%は暗号通貨がポートフォリオの半分以上を占めているとしている。
 Joy
Joy