AI on AOの発表会でラマランド、アプス・ネットワークのプロジェクトとは?
AI on AOの発表イベントでは、LlaMA LandとApus Networkの2つのプロジェクトが紹介された。
 JinseFinance
JinseFinance

ソース:Heart of the Metaverse
ロイターは2月28日、メタが7月に人工知能の大規模言語モデルの最新版「ラマ3(Llama 3)」をリリースする予定で、ユーザーが投げかけた物議を醸すような質問に対してより良い回答を提供するようになると報じた。
メタ社の研究者たちは、物議を醸す質問に対して相関性のある答えを提供できるようにモデルをアップグレードしようとしている。
Metaは、ライバルのGoogleがGeminiを立ち上げた後、画像生成機能を一時停止しました。

MetaのLlama 2はソーシャルメディアプラットフォームでチャットボットを動かすが、関連するテストによると、友だちにいたずらする方法、戦争に勝つ方法、車のエンジンを「殺す」方法など、あまり話題にならない質問には答えない。車のエンジンを "殺す "方法。
しかし、Llama 3は「車のエンジンを切る方法」といった質問には答えることができた。これは、ユーザーが実際にエンジンを「殺す」のではなく、車のエンジンを切る方法を聞きたがっていることを理解したことを意味する。
Metaはまた、モデルの応答をよりニュアンスのあるものにするための努力として、トーンと安全性のトレーニングを監督する社内担当者を今後数週間のうちに任命する予定だという。
実際、1月にメタ社のザッカーバーグCEOはINSビデオで、メタAIは最近ラマ3のトレーニングを開始したと発表した。これは、2023年2月にリリースされたLlama 1モデル(当初は「LLaMA」と呼ばれていた)と7月にリリースされたLlama 2モデルに続く、大規模言語モデルLLaMaファミリーの最新世代です。
具体的な詳細(モデルのサイズやマルチモーダル機能など)はまだ発表されていませんが、ザッカーバーグ氏は、MetaはLlamaベースモデルのオープンソースを継続するつもりだと述べています。

注目すべきは、Llama 1の訓練には3ヶ月、Llama 2の訓練には約6ヶ月かかったということです。は訓練に約6ヶ月かかった。次世代モデルも同様のスケジュールで進めば、今年の7月頃にはリリースされるだろう。
しかし、メタがモデルを正しく並べるための微調整に余分な時間を割く可能性もある。
オープンソースのモデルがより強力になり、生成AIモデルがより広く使われるようになるにつれて、悪意のある目的のために悪質な行為者によってモデルが使われるリスクを減らすために、私たちはより注意深くなる必要があります。ザッカーバーグはビデオリリースで、モデルの「責任ある安全なトレーニング」に対するメタのコミットメントを繰り返した。
ザッカーバーグ氏はまた、その後の記者会見で、オープンライセンスとAIの民主化に対するメタ社のコミットメントを繰り返した。The Vergeとのインタビューで、彼は「ここでの最大の課題のひとつは、本当に価値のあるものを作ると、それが非常に中央集権的で狭いものになってしまうことだと思う。もっとオープンにすれば、機会や価値の不平等が生み出す問題の多くを解決できる。ですから、これはオープンソース全体のビジョンの重要な部分なのです」。
ザッカーバーグ氏はまた、発表ビデオの中で、AGI(人工知能)を構築するというメタの長期的な目標を強調した。AGIとは、モデルが人間の知能に匹敵するか、それ以上の全体的なパフォーマンスを示す、AIの理論的な開発段階である。
ザッカーバーグはまた、「次世代のサービスは、包括的な一般知能で構築される必要があることがますます明らかになってきています。最高のAIアシスタント、クリエイター向けAI、企業向けAIなどを構築するには、推論、計画、コーディングから記憶やその他の認知能力に至るまで、AIのあらゆる分野での進歩が必要になります。"
ザッカーバーグの発言からわかるように、ラマ3モデルは必ずしもAGIの実現を意味するわけではありませんが、メタは意識的に、AGIを可能にするかもしれない方法でLLM開発やその他のAI研究にアプローチしています。
AIにおけるもう1つの新たなトレンドは、マルチモーダルAI、つまり、異なるデータ形式(またはモダリティ)を理解して処理できるモデルです。
たとえば、GoogleのGemini、OpenAIのGPT-4V、LLaVa、Adept、Qwen-VLなどのオープンソースモデルは、テキスト、コード、音声、画像、あるいは動画データを処理するモデルを個別に開発するのではなく、コンピュータビジョンと自然言語処理(NLP)のタスクをシームレスに切り替えることができます。
ザッカーバーグは、Llama 3がLlama 2と同様にコード生成機能を含むことを確認しましたが、他のマルチモーダル機能については明確に話しませんでした。
しかし、ザッカーバーグ氏はLlama 3の発表ビデオの中で、AIがメタバースとどのように交わることを想定しているかについて話しています。"

これは、次期バージョンのLlama 3でも、それ以降のバージョンでも、MetaがLlama 3を開発する計画があることを暗示しているようです。MetaのLlamaモデルに対する計画には、LLMがすでに処理しているテキストやコードデータに、視覚データや音声データを統合することも含まれています。
これはまた、AGIを追求する上での自然な流れでもあるようです。
ザッカーバーグは『ザ・ヴァージ』とのインタビューで、「一般的な知能が人間と同じレベルの知能なのか、人間+αの知能なのか、それとも遠い未来の超知能なのか、議論することはできる。しかし、私にとって重要なのは、その幅の広さです。つまり、知能にはさまざまな能力があり、理性的で直感的でなければならないのです」。
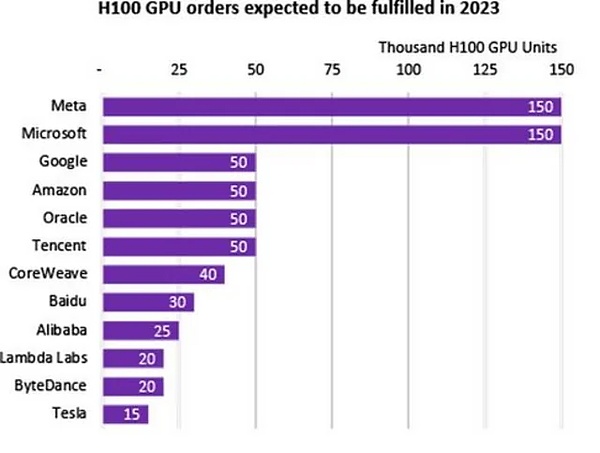
ザッカーバーグはまた、トレーニングインフラへの多額の投資を発表した。2024年の終わりまでに、Metaは約35万個のNVIDIA H100 GPUを持つつもりです。
これにより、Metaの利用可能なコンピューティングリソースは、すでに持っているGPUを含めて60万H100コンピュート相当となり、これは現在、Microsoftのコンピュートパワーの予備に匹敵するだけです。
つまり、たとえLlama 3モデルが前モデルより大きくないとしても、そのパフォーマンスは大幅に向上すると信じる理由があります。strong>その性能はLlama 2モデルよりも大幅に向上するでしょう。
Llamaのパフォーマンスが大幅に向上するというDeepmindの仮説は、2022年3月に発表された論文でなされ、その後、Metaのモデルや他のオープンソースのモデル(フランスのMistralのモデルなど)によって実証されました。パフォーマンスが得られることを示唆している。
Llama3モデルの規模はまだ発表されていませんが、つまり、70億~70億パラメータのモデル内でパフォーマンスが向上するという前任者のパターンを引き継ぐ可能性が高いです。Metaのインフラへの最近の投資は、どのような規模のモデルに対しても、さらに強力な事前学習機能を提供することは間違いないでしょう。
また、Llama 2はLlama 1のコンテキスト長を2倍にしました。これはLlama 2が推論中に2倍のコンテキストを「記憶」できることを意味し、Llama 3はこの分野でさらなる進歩を遂げる可能性を秘めています。
小さいLLaMAとLlama 2モデルは、いくつかのベンチマークで、より大きくパラメータ化された1750億GPT-3モデルのパフォーマンスを満たすか上回っていますが、ChatGPTで利用可能なGPT-3.5とGPT-4モデルには及びません。

この新世代のモデルで、Metaはオープンソースの世界に最先端のパフォーマンスをもたらすことに熱心なようです!.
ザッカーバーグはThe Vergeに「Llama 2は業界をリードするモデルではなかったが、最高のオープンソースモデルだった。Llama 3とそれ以降で、私たちの目標は、最先端の製品を作り、最終的に業界をリードするモデルになることです。"
新しいベースモデルには、アプリ、チャットボット、ワークフロー、自動化を改善することで、競争上の優位性を獲得する新しい機会が生まれます。
新たな開発の最前線に立つことは、遅れをとらないための最善の方法であり、新しいツールを採用することで、組織のサービスを差別化し、顧客と従業員に最高のエクスペリエンスを提供することができます。
AI on AOの発表イベントでは、LlaMA LandとApus Networkの2つのプロジェクトが紹介された。
JinseFinanceアリババは、Qwen-7B と Qwen-7B-Chat の多用途性を強調し、世界中の学者、研究者、商業機関がそのコーディング、モデルの重み、ドキュメントにアクセスできるようにしています。
 Coinlive
Coinlive 2022 年はテクノロジー業界にとって厳しい年でしたが、Meta は特に厳しい年でした。
 decrypt
decryptInstagramにはまもなくNFT作成および取引ツールが組み込まれますが、アプリ内購入は「該当するアプリストア料金の対象となります」.
 Others
OthersMicrosoft は、Teams と Office から始めて、Windows オペレーティング システムもヘッドセットを通じて将来利用できるようになると述べています。
 Beincrypto
BeincryptoMeta は 6 月に米国でブランド変更を開始し、現在はグローバルに変更を行っています。
Others
V God は、Meta がメタバースの革新に着手するのが早すぎたのは、「人々が何を望んでいるのかを知るには時期尚早だった」からだと述べました。
 Cointelegraph
Cointelegraphインターネットシティ、ドバイ、2022 年 7 月 29 日 – グローバルなデジタル資産取引プラットフォームである LBank Exchange は、META PROTOCOL (MPC) ... を上場しました。
 Bitcoinist
BitcoinistMeta のかつて野心的な暗号通貨プロジェクトの残骸は消えつつあります。そのウェブサイトの通知によると、パイロットプログラム...
Bitcoinist