{kind=link}
{kind=link}
ポリゴン推ポリゴンIDリリース6 レイヤーゼロ上线西
ゴールデンファイナンスは、暗号通貨とブロックチェーン業界の朝のニュースレター「ゴールデンモーニング8」2244号を創刊し、最新かつ最速のデジタル通貨とブロックチェーン業界のニュースをお届けします。
 JinseFinance
JinseFinance

Written by PREDA Source: chainfeeds
コンピュータにおける並列性の歴史を通して:並列処理の最初のレベルは、命令レベルの並列処理でした。命令レベルの並列処理は、20 世紀最後の 20 年間でアーキテクチャがパフォーマンスを向上させた主な方法でした。命令レベルの並列処理は、プログラマが特に好む、プログラムのバイナリ互換性を維持しながら性能を向上させます。命令レベル並列性には2つのタイプがある。ひとつは時間的並列処理、すなわち命令パイプライン処理である。命令パイプラインは、自動車を生産する工場の組み立てラインのようなもので、1台の車がロードされるのを待ってから次の車の生産を開始するのではなく、自動車生産工場では複数のパスで同時に複数の車を生産する。空間的並列性のもう1つのタイプは、マルチ発進(スーパースカラ)である。マルチ発進は複数車線のある道路のようなもので、複数車線での追い越しを可能にするのがアウトオブオーダー実行であり、スーパースカラとアウトオブオーダー実行は効率向上のために併用されることが多い。1980年代にRISCが登場した後、命令レベル並列の開発はその後の20年でピークに達し、2010年以降は命令レベル並列をさらに掘り下げる余地はほとんどなくなっていた。
2番目の並列レベルはデータレベル並列で、主に単一命令ストリーム複数データストリーム (SIMD) ベクター構造を指します。最古のデータレベル並列は ENIAC に登場し、1960 年代から 1970 年代にかけて、Cray に代表されるベクトルマシンは Cray-1、Cray-2、そして後の Cray X-MP、Cray Y-MP に至るまで非常に人気がありました。 SIMD は Cray-4 以降しばらく休眠状態にありましたが、現在では活性化し始め、ますます一般的に使用されるようになっています。例えば、X86のAVXマルチメディア命令は、256ビットのパスで4つの64ビット演算または8つの32ビット演算を行うことができます。 SIMDは、命令レベルの並列性を効果的に補完するものとして、ストリーミングメディアで重要な役割を果たしており、初期には主に専用プロセッサで使用されていましたが、現在では汎用プロセッサの標準となっています。
第 3 の並列レベルは タスク レベル並列 です。タスクレベルの並列性は、インターネット アプリケーションに多く存在します。タスクレベルの並列処理は、マルチコア プロセッサやマルチスレッド プロセッサに代表され、現在のコンピュータ アーキテクチャのパフォーマンスを向上させる主な方法です。タスクレベルの並列処理は並列度の粒度が高く、1つのスレッドに数百以上の命令が含まれます。
並列コンピューティングの発展という観点から見ると、今日のブロックチェーンは第1レベルから第2レベルへの変容の過程にあります。主流のブロックチェーンシステムは通常、シングルチェーンかマルチチェーンのいずれかのアーキテクチャを採用している。ビットコインやイーサリアムのようなシングルチェーンシステムは単一のチェーンを持ち、チェーン内の各ノードが全く同じスマートコントラクトトランザクションを実行し、全く同じオンチェーン状態を維持する。各ブロックチェーン・ノード内では、スマート・コントラクト・トランザクションは通常シリアルに実行されるため、システム全体のスループットは低くなります。
最近、シングルチェーンアーキテクチャを使用しながらも、スマートコントラクトトランザクションの並列実行をサポートする高性能なブロックチェーンシステムも登場しています。ブラウン大学とイェール大学のThomas Dickerson氏とMaurice Herlihy氏らは、PODC'17の論文の中で、STM(Software Transactional Memory)アプローチに基づく並列実行モデルを最初に提案しました。このアプローチは、楽観的並列性によって複数のトランザクションを並列実行し、並列実行中にトランザクションが状態アクセスの競合に遭遇した場合、STMを介して状態をロールバックし、競合するトランザクションをシリアルに実行する。このアプローチは、Aptos、Sei、Monadなど、多くの高性能ブロックチェーン・プロジェクトに適用されている。これとは対照的に、別の並列実行モデルは悲観的並列実行に基づいており、トランザクションは並列実行される前に競合する状態アクセスがないかテストされ、競合しないトランザクションのみが並列実行される。このアプローチは通常、スマートコントラクトコードを静的に分析し、有向無サイクルグラフ(DAG)のような状態依存関係を構築するプログラム分析ツールを使用して事前に計算される。同時実行トランザクションがシステムに提出されると、システムはトランザクションがアクセスする必要のあるステートとステート間の依存関係に基づいて、トランザクションを並列実行できるかどうかを判断する。互いに状態依存関係のないトランザクションのみが並列実行される。この種のアプローチは、Zilliqa(CoSplit版)やSuiなどの高性能ブロックチェーン・プロジェクトで使用されている。上記の並列実行モデルはいずれも、システムのスループット率を大幅に向上させることができる。これら2つの方式は、上述の命令レベルの並列実行に相当する。しかし、これらの取り組みは、1)スケーラビリティの問題、2)並列意味表現の問題、という2つの問題に悩まされており、以下に詳しく説明する。
典型的なSolana、Monadプロジェクトの技術的ソリューションの例を用いて、並列分類を含む並列アーキテクチャ設計を分解します。これには、並列化の分類、データ依存性、および並列性とTPSに影響するその他の重要なメトリクスが含まれます。
ソラーナ
高いレベルで言えば、ソラーナの設計哲学は、ブロックチェーンのイノベーションはハードウェアの進歩に合わせて進化すべきだということです。ムーアの法則に従ってハードウェアが改良され続ける中、ソラーナはより高いパフォーマンスとスケーラビリティの恩恵を受けることを目指している。 Solanaの共同設立者であるAnatoly Yakovenkoは、5年以上前にSolanaの並列化アーキテクチャを設計しており、今日、並列化はブロックチェーンの設計理念として急速に広まっている。
Solanaは決定論的並列化を使用しています。これは、開発者が通常すべての状態を事前に宣言する、アナトリーの組み込みシステムでの過去の経験に由来する。これにより、CPUはすべての依存関係を認識し、メモリの必要な部分をプリフェッチすることができる。その結果、システムの実行は最適化されるが、やはり開発者側には余分な作業が必要になる。Solanaでは、プログラムのすべてのメモリ依存関係が必要とされ、構築されたトランザクション(すなわち、アクセスリスト)で説明されるため、ランタイムは複数のトランザクションを効率的にスケジューリングし、並列実行することができます。
Solanaアーキテクチャの次の主要コンポーネントは、 Sealevel VMであり、バリデータが所有するコア数に基づいて、複数のコントラクトとトランザクションの並列処理をサポートする。ブロックチェーンにおけるバリデータは、トランザクションの検証と妥当性確認、新しいブロックの提案、ブロックチェーンの整合性とセキュリティの維持を担うネットワーク参加者である。トランザクションは、どのアカウントが読み取りと書き込みのロックを必要とするかを事前に宣言するため、Solanaスケジューラーはどのトランザクションが同時に実行できるかを決定することができる。このため、検証時に「ブロックプロデューサー」またはリーダーは、保留中の何千ものトランザクションを選別し、重複しないトランザクションを並行してスケジュールすることができる。
モナドはチューリング完全並列EVMのレイヤー1を構築しています。 Monadは並列化エンジンだけでなく、バックグラウンドで構築される最適化エンジンもユニークです。
Seiと同様に、Monadブロックチェーンは楽観的並行性を使用しています。strong>「楽観的同時実行制御(Optimistic Concurrency Control:OCC)」を使用してトランザクションを実行します。同時実行トランザクション処理は、複数のトランザクションが同時にシステム内に存在する場合に発生する。このトランザクション方式には、実行と検証の2つの段階がある。
実行フェーズでは、トランザクションは楽観的に処理され、すべての読み取り/書き込みはトランザクション固有のストレージに一時的に格納される。その後、各トランザクションは、一時記憶操作の情報が前のトランザクションによって行われた状態変更と照合される検証フェーズに入る。トランザクションは独立していれば並行して実行される。あるトランザクションが他のトランザクションによって変更されたデータを読むと、衝突が生じる。
モナドの設計における重要な革新の1つは、わずかなオフセットを持つパイプラインです。このオフセットにより、複数のインスタンスを同時に実行することで、より多くのプロセスを並列化することができます。その結果、パイプラインは、ステート・アクセス・パイプライン、トランザクション実行パイプライン、コンセンサスと実行のパイプライン、コンセンサス・メカニズム自体のパイプラインなど、多くの機能を最適化するために使用される。

Monadでは、トランザクションはブロック内で線形に順序付けられますが、並列実行を活用することで、より速く最終状態に到達することが目標です。 Monadは楽観的並列化アルゴリズムを使って実行エンジンを設計している。 Monadのエンジンはトランザクションを同時に処理し、それらを分析することで、トランザクションを次々に実行しても結果が同じになるようにする。衝突があれば、再実行する必要がある。ここでの並列実行は比較的単純なアルゴリズムだが、Monadの他の主要な革新技術と組み合わせることで、このアプローチが斬新なものになる。ここで注意すべき点は、再実行が発生したとしても、無効なトランザクションに必要な入力はほとんど常にキャッシュに保持されているため、通常は単純なキャッシュ検索で済むということである。ブロック内の前のトランザクションをすでに実行しているので、再実行は間違いなく成功する。
実行を遅らせることに加えて、Monadはまた、SolanaやSeiと同様に、実行とコンセンサスを分離することでパフォーマンスを向上させます。コンセンサスが完了したときに実行を完了するという条件を緩和すれば、2つを並行して実行することができ、それによって両方に余分な時間をもたらすということだ。もちろん、Monadはこの状況を処理するために決定論的アルゴリズムを使用して、一方が追いつくために先行しすぎないようにしている。
楽観的並列実行であろうと悲観的並列実行であろうと、上述のシステムは基礎となるデータモデルの抽象化として共有メモリーを使用しています。異なる並列実行ユニットが直接アクセスできる(つまり、すべてのオンチェーンデータを並列実行ユニットが直接読み書きできる)。基礎となるデータモデルとして共有メモリを使用するブロックチェーンシステムは、通常、その並行性が単一の物理ノード(Solana)に制限され、各物理ノードの並行性は、ノードの計算能力、すなわち物理スレッド数(各スレッドが仮想マシンをサポートすると仮定)によって制限されます。
このノード内並列性は、スマートコントラクト実行レイヤーのアーキテクチャを変更するだけでよく、システムコンセンサスレイヤーのロジックを変更する必要はありません。その結果、データストレージのシャーディングがないため、ブロックチェーンネットワークの各ノードは、すべてのトランザクションを実行し、すべての状態を保存する必要があります。一方、分散スケーリングにより適したシェアードナッシング・アーキテクチャと比較すると、基盤となるデータモデルの抽象化として共有メモリを使用するこれらのシステムは、処理能力の点で水平方向にスケールすることができません。つまり、システムの状態ストレージの拡張だけでなく、実行能力の拡張を達成するために物理マシンの数を増やすことができるため、ブロックチェーンの根本的なスケーラビリティに対処することができません。問題は、ブロックチェーンがスケーラブルではないということだ。
では、既製の解決策はあるのでしょうか?
PREDAを紹介する前に、当然の質問をしたいと思います。並列プログラミングを使うのか?1970年代、1980年代、そして1990年代の一部でさえ、私たちはシングルスレッド・プログラミング(あるいはシリアル・プログラミングと呼ばれていました)にとても満足していました。あるタスクを実行するプログラムを書くことができた。実行が終わると結果が返ってくる。タスクは完了し、誰もがハッピーになる!
2004年以前、CPUメーカーのIBM、Intel、AMDは、より高速なプロセッサを提供することができました。プロセッサーのクロックは、16MHz、20MHz、66MHz、100MHz、200MHz、333MHz、466MHz......と、どんどん速くなり、つまり、どんどん良くなっていくように見えた。しかし2004年になると、技術的な限界からCPUの高速化は維持できないことが明らかになった。CPUメーカーの解決策は、1つのCPUの中に2つのCPUを搭載することであった。たとえ両方のCPUが1つのCPUよりも低速で動作したとしても、である。たとえば、200MHzで動作する2つのCPU(メーカーはこれをコアと呼ぶ)を一緒に使えば、300MHzで動作するシングルコアCPUよりも1秒間に多くの計算(つまり、1秒間に多くの演算)を行うことができる。たとえば、200MHzで動作する2つのCPU(メーカーはコアと呼ぶ)を一緒に使えば、300MHzで動作する1つのCPUよりも1秒間に多くの計算を行うことができる(つまり、直感的には2×200 >300)。
「シングルCPU、メニーコア」という夢のような話が現実のものとなり、プログラマーは両方のコアを活用するための並列プログラミング手法を学ばなければならなくなった。もし1つのCPUで2つのプログラムを同時に実行できるのであれば、プログラマーは両方のプログラムを書かなければならない。しかし、これはプログラムを2倍速く実行することにつながるのだろうか?そうでないなら、2 x 200 >300のアイデアには欠陥がある。一方のコアが十分な仕事を得られない場合はどうなるのか?つまり、1つのコアだけが本当に忙しく、もう1つのコアは何もしていない場合だ。その場合は、300MHzのコアを1つ使う方がいいだろう。マルチコアの導入により、多くの似たような問題が非常に顕著になり、これらのコアを効率的に使用する唯一の方法はプログラミングです。

下の画像では、ボブとアリスを2人の金鉱夫と想像しています。paddingleft-2">
鉱山への運転
採掘
鉱石を積む
貯蔵して磨く

採掘プロセス全体は、4つの別々の、しかし順序付けられた作業で構成されており、それぞれ15分かかります。
ボブとアリスが同時にそれらを行うと、彼らは1時間で2倍の採掘を行うことができます。
しかし、ある日ボブの採掘車が故障したらどうでしょう。
しかし、ある日、ボブの採掘車が故障し、修理工場に置き忘れた。作業場に戻るには遅すぎるが、まだ仕事は残っている。アリスの採掘車と1本のツルハシだけで、1分間に2個の鉱石を採れるでしょうか?
上の例えでは、採掘の4つのステップはスレッドであり、採掘カートはコアであり、鉱石はスマートコントラクトが実行する必要があるデータの単位であり、つるはしは実行の単位であり、プログラムは互いに依存し合う2つのスレッドで構成されています。性能が高ければ高いほど、ボブとアリスはより多くの鉱物を掘り出すことができる。鉱山をメモリとして考え、そこからデータの単位(金の鉱石)を取り出します。スレッド1で鉱石を選ぶことは、メモリからデータの単位を読み出すことに似ています。
さて、ボブの採掘トラックが故障したらどうなるか見てみましょう。ボブとアリスはトラックを共有する必要があり、最初は問題ありませんが、採掘効率を確保するために採掘装置がアップグレードされた後は、事情が変わってきます。鉱山に積み込める鉱石の量が全体的な効率のボトルネックになります。使用する採掘機がどんなに効率的でも、粉砕機に送れる鉱石は効率が悪いからです。使用される採掘機がいかに効率的であっても、粉砕に送ることができる鉱石の量は「鉱山のカートの最大鉱物容量」によって制約される。
これはソラーナの並列VM、コア共有の性質でもあります。
コア共有
Solanaの究極の設計要素は「パイプライン化」です。パイプライン化は、データが一連のステップを通して処理される必要があり、異なるハードウェアが各ステップを担当する場合に発生します。ここでの重要なアイデアは、シリアルに実行する必要があるデータを、パイプラインを使って並列化することです。これらのパイプラインは並列に実行することができ、各パイプライン・ステージは異なるトランザクションのバッチを処理することができる。ハードウェアの処理速度(マイニングトラックの積載能力)が高ければ高いほど、並列化のスルーレートは高くなる。今日、Solanaのハードウェアノード要件は、そのノードオペレータに1つの選択肢しか残していない--データセンターである。
マイニングトラックをアップグレードした後、採掘能力が追いつかず、しばしば容量不足に陥りました。そこでBobは採掘効率を上げるため、より高いコストで採掘機を購入しました(実行ユニットのアップグレード)。この例でも、10部の鉱石を15分で生産することができるが、鉱石の粉砕は以前と同じように手作業で行われているため、単位時間当たりの鉱石はより多くの金に変換されず、より多くの鉱石が倉庫に押し込められている。この例は、メモリへのアクセスがプログラムの実行速度の制限要因となった場合に何が起こるかを示している。この例は、メモリへのアクセスがプログラムの実行速度の制限要因になった場合に何が起こるかを示している。もはや、データの処理速度(すなわちコアの実行速度)は問題ではない。データへのアクセス速度が制限されるのです。
I/Oはコンピュータの中で最も遅い部分であり、データの非同期I/Oが重要になるため、I/O速度の低下は深刻な問題になります。
仮にボブが15分で10ミネラルを採掘できるマイニングマシンを持っていたとしても、メモリアクセスの競合があれば、15分ごとに2ミネラルを採掘するのが限界でしょう。この問題に対する既存の並列ブロックチェーン・ソリューションは、悲観的実行と楽観的実行の2つの流派に分かれます。
前者は、データを書き込んだり読み込んだりする前に、データ状態の依存関係を明確に定義する必要があり、開発者は先手を打って静的制御の依存関係を仮定する必要がありますが、スマートコントラクトのプログラミングの領域では現実から乖離する傾向があります。後者は、データの書き込みに仮定や制限を設けず、競合が発生した場合はロールバックします。
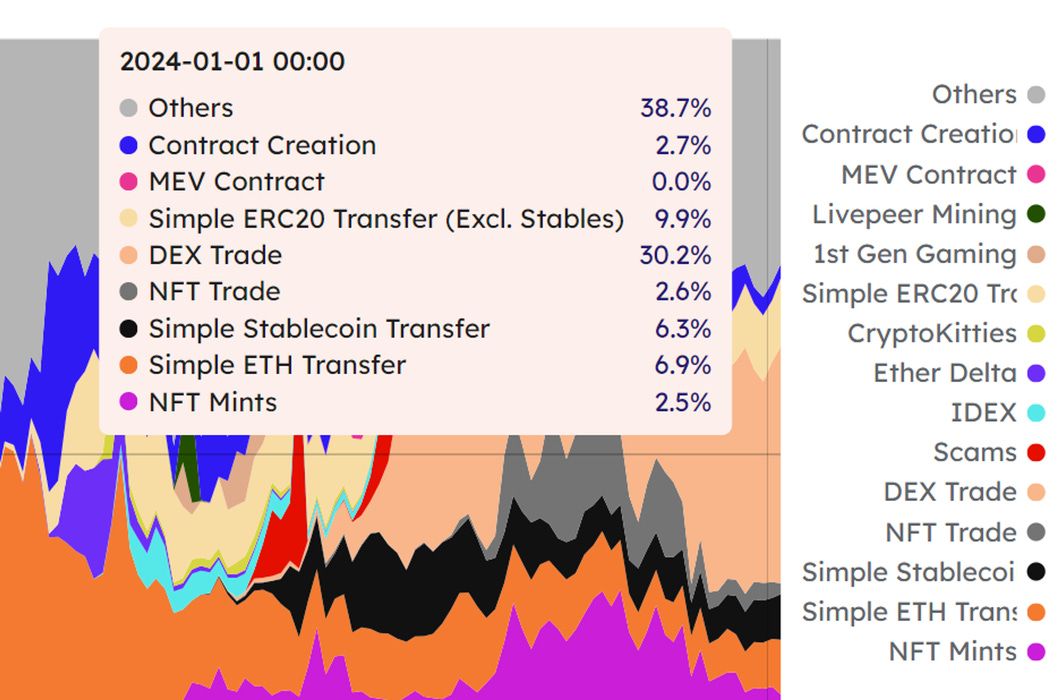
Monadの楽観的実行シナリオを例にとると、現実には作業負荷のほとんどはトランザクション実行であり、並列発生は思ったほど起こりません。下のグラフは、イーサネットの1日に消費されるGas Feeのソースの種類を示しています。一般的なスマートコントラクトほど分布は高くありませんが、実際には異なる種類のトランザクションがあまり均等に分布していないことがわかります。なぜなら、Web2アプリケーションのリクエストの大部分はアクセスであり、変更ではないからだ。例えば、タオバオやジッターバグは、これらのAPPの状態を変更する機会があまりない。しかし、Web3空間ではその逆で、ほとんどのスマート・コントラクトのリクエストは、まさに状態を変更すること--台帳を更新すること--であり、実際に予想以上のロールバックを引き起こし、チェーンが利用できなくなる可能性がある。

つまり、結論として、Monad は並列性を実現しますが、並行性には理論的な上限があり、それは 2x と 3x の間になります。第2に、VMを追加することでこれをスケールアップする方法はありません。つまり、コアの増加イコール処理能力の向上というポイントに到達する方法はないということです。最後になるが、Monadはデータをスライスしないため、チェーンの膨張状態がもたらすノード要件に対する答えがないというのも決まり文句だ。 ここにあるのは、家庭用コンピューターが搭載できる限界を超えるノード要件であり、メインネットの立ち上げに伴い、データをスライスしないのであれば、MonadがSolanaの道を歩むのは必然だろう。そして、最後に。そして最後だが、楽観的実行はブロックチェーン空間での並列処理には向かない。

マイニングを一定期間行った後、ボブは自問しました。彼が研磨している間、私は車に荷物を積むことができる。車に荷物を積むのにかかる時間は研磨するのとまったく同じだから、研磨が可能になるのを待たなければならない状態には確かにならない。アリスが採掘を終えるまで、私が車で採掘に行くから、2人とも100%忙しくできる」。この天才的なアイデアによって、彼らは採掘トラックを追加する必要さえなく、2倍の効率に戻ることができた。重要なのは、ボブがプロセス、つまりスレッドの実行順序を再設計したことで、すべてのスレッドが採掘車やストーンピックのようなコア内の共有リソース待ちで立ち往生することがなくなったことだ。
これは、スマートコントラクトの状態を分割することで、共有リソースにアクセスしてもスレッドがキューに入ることも、データI/Oのためのパイプラインが最終的な原子性に到達する速度を制限することもない、並列性の正しいバージョンです。
PREDAモデルは、コントラクトコード実行時のコントラクト状態へのアクセス構造を実行レイヤーに公開することで、実行レイヤーが適切なスケジュールを立てやすくし、実行結果のロールバックを完全に回避します。この並列モデルは、非同期並列としても知られています。

なぜなら、並列性が非同期の場合のみ、スレッドの追加は線形ブーストとして届くからです。先ほどの例のように、採掘トラックの能力をアップグレードしても、採掘装置が古くなっているために空運転になるのではなく、PREDAの並列実行環境はMoandやSolanaのそれとは根本的に異なります。マルチコアCPUとGPUの違いのように、共有コアの処理効率が並列性のボトルネックになるわけではありません。並列性にボトルネックはなく、I/Oの読み書きにおけるデータ依存性の問題もない。さらに重要なのは、PREDAの並列モデルの並列性はスレッド数が増えるにつれて高くなる点で、これはGPUと同様である。ブロックチェーンのロジックでは、スレッド(VM)の増加により、フルノードのハードウェア要件が削減され、分散化を確保しながらパフォーマンスが向上します。


ようやくこの並列ブロックチェーンの終盤に差し掛かったが、業界には、アーキテクチャ設計に加えて、次のようなものも欠けている。並列プログラミング言語のセマンティック表現も不足している。
NvidiaがCUDAを必要としたように、並列ブロックチェーンも新しいプログラミング言語:PREDAを必要としました。 今日のスマートコントラクトの開発者は、そのセマンティクスを並列で表現し、基礎となるマルチチェーンを効果的に活用することができません。つまり、一般的なスマートコントラクトのトランザクションを効果的に並列化するために、基盤となるマルチチェーンアーキテクチャが提供するサポート(データシャーディングまたは実行シャーディング、あるいはその両方)を効果的に活用することができないのです。すべてのシステムで使用されているプログラミング言語は、Solidity、Move、Rustなどの従来の一般的なスマートコントラクトプログラミング言語です。これらのプログラミング言語には並列セマンティクスを表現する能力がありません。つまり、CUDAのような高性能コンピューティングやビッグデータで使用される並列プログラミングモデルやプログラミング言語と同様に、並列ユニット間の制御やデータの流れを表現する能力がありません。
スマートコントラクト用の並列プログラミングモデルやプログラミング言語がないため、アプリケーションやアルゴリズムをシリアルから並列に再構成することができず、その結果、アプリケーションやアルゴリズムを並列実行機能を持つ基礎となるブロックチェーンシステムに適応させることができず、アプリケーションの実行効率やブロックチェーンシステム全体のスループットを向上させることができません。
PREDAは、コントラクトの状態がプログラム上のコントラクトスコープを通じてきめ細かなレベルで分割され、トランザクションの実行フローがFunctional Relayセマンティクスを通じて複数の並列実行エンジンに分解・分散される分散プログラミングモデルを提案しています。
このモデルはまた、プログラマブルスコープを通じてコントラクト状態の分割スキームを定義し、開発者がアプリケーションのアクセスパターンに基づいて最適化できるようにします。非同期関数リレーにより、トランザクションの実行フローを状態にアクセスする必要のある実行エンジンに移動させることができ、データではなく実行フローを移動させることができます。
このモデルは、開発者が基礎となるマルチチェーンシステムの詳細を気にすることなく、コントラクトステートの分散パーティショニングとトランザクショントラフィックの共有を可能にします。実験結果によると、PREDAモデルは256の実行エンジンで最大18倍のスループット向上を達成でき、これは理論的な並列限界に近い。並列性は、パーティションカウンターやスワップ可能な命令などのテクニックを使用することでさらに向上します。
ブロックチェーンシステムは、伝統的に単一の逐次実行エンジン(EVMなど)を使用してすべてのトランザクションを処理してきたため、スケーラビリティが制限されていました。マルチチェーンシステムは並列実行エンジンを実行するが、各エンジンがスマートコントラクトの全トランザクションを処理するため、コントラクトレベルでのスケーラビリティが妨げられる。この投稿では、Solanaに代表される決定論的並列実行の本質的なコア共有と、Monadに代表される楽観的並列実行が実際のブロックチェーンアプリケーションシナリオで安定的に実行できない理由、そして高頻度のロールバックの可能性について議論する。PREDAチームは、スマートコントラクトの状態を分割し、トランザクションのトラフィックを実行エンジンに分散させることで、個々のスマートコントラクトをスケールさせる新しいプログラミングモデルを提案している。PREDAチームは、コントラクトの状態をどのように分割するかを定義するために、プログラム可能なコントラクトスコープを導入している。各スコープは専用の実行エンジン上で実行される。非同期機能リレーは、トランザクションの実行フローを分解し、必要な状態が別の場所に存在する場合に実行エンジン間でそれを移動させるために使用されます。

これにより、トランザクション・ロジックがコントラクト状態のパーティショニングから切り離され、データ移動のオーバーヘッドなしに固有の並列処理が可能になります。その並列モデルは、スマート・コントラクト・レベルで状態を分割し、データ・パブリッシング・レベルで依存関係を切り離し、Moveのようなマルチスレッド実行エンジン・クラスター・アーキテクチャを提供します。さらに重要なのは、PREDAという新しいプログラミングモデルを革新したことで、これはブロックチェーンの並列化パズルの最後のピースになるかもしれない。

ゴールデンファイナンスは、暗号通貨とブロックチェーン業界の朝のニュースレター「ゴールデンモーニング8」2244号を創刊し、最新かつ最速のデジタル通貨とブロックチェーン業界のニュースをお届けします。
JinseFinanceParticle Network People's Launchpadは、2月5日午前0時(UTC)に公開され、BTC保有者とALLYコミュニティーにマーリン・チェーンのトークン配布に参加する特別な機会を提供します。
JinseFinance世界のイーサETF27銘柄のうち、20銘柄がイーサ・スポットETF、7銘柄がイーサ先物ETFである。
JinseFinanceルクセンブルク、セントヘレナ、シンガポール、スイスは、Google Trendsの検索関心スコアが90パーセンタイルで、ビットコインETFに対する世界の関心をリードしている。
JinseFinance多くの著名人がThreadsのトレンドに飛びついているにもかかわらず、そうでない人も多い。詐欺師のアカウントが出現したり、ユーザーが自分のアカウントを削除できなかったりすることから、スレッドは単に急ごしらえの試みなのだろうか?
 Catherine
Catherineこれはまた新たな檻の中の戦いなのだろうか?最近のTwitterの苦境を受け、Metaは最新のイノベーションであるThreadsアプリを発表した。
Catherine貧しい国は、ビットコインを法定通貨として使用し、投資を呼び込み、独自のメタバースを作成することを含む、野心的な暗号プロジェクトを開始しました。
 Cointelegraph
Cointelegraph発展途上国の 2 倍以上の人々が、メタバースが自分たちの生活に影響を与えると考えており、彼らはメタバースを毎日使用しています。
Cointelegraph開発途上国では、先進国と比較して、メタバースが自分たちの生活に影響を与え、メタバースを日常的に使用することに前向きな人が 2 倍以上います。
Cointelegraphカナダの石油・ガス採掘会社であるベンガル・エナジーは、ポータブルなビットコイン採掘装置を使って、以前は「立ち往生していた」ガス井にアクセスする試験プロジェクトを開始する予定です。
Cointelegraph