暗号化のパラドックスを解く:「コード・イズ・ロー」から「モデル・イズ・トラスト」へ
暗号市場,BTC,Cracking Crypto Paradox: Beyond Code is Law Towards Model is Trust Golden Finance,私たちは望ましい未来に向かって大きく前進しているのか?
 JinseFinance
JinseFinance

M31キャピタルのDavid Attermann氏による

サブスクイド・ネットワークは、業界初のモジュール式ブロックチェーンデータ索引作成・照会ソリューションであり、開発者がチェーン上の情報に効率的にアクセスして分析できるようにします。独自のモジュール式でスケーラブルなアーキテクチャにより、高度にカスタマイズされたデータ処理パイプラインとリアルタイムの更新が可能です。市場ではほとんど知られていないため、投資家にとっては貴重で魅力的な投資機会となります。
ブロックチェーンデータ管理の現状
現在、Web3の開発者が直面している最大の課題の1つは、スケールでデータにアクセスすることです。現在、ブロックチェーン(トランザクションと状態データ)、アプリケーション(スマートコントラクトの状態のデコード)、関連するオフチェーンデータ(IPFSやArweaveに保存された価格データなど)へのクエリと集約は非常に複雑です。このデータは多くの場合、複数のエコシステム、チェーン、テクノロジーに分散しており、標準化されていない構造やデータサイロの出現につながっています。
Web2では、データはBigQuery、Snowflake、Apache、Icebergのような集中型のデータレイクに保存され、簡単にアクセスできるようになっていました。しかし、Web3のデータを同様の中央集権的なデータレイクに保存することは、オープンで弾力的なアクセスという本来の目的を失うことになる。Web3アプリケーションデータを集約し、フィルタリングし、簡単に抽出する能力は、マルチチェーンパラダイムで次世代のアプリケーション機能を推進する業界の可能性を解き放つでしょう。
ソリューション:Subsquid ネットワーク
Subsquidは大量のデータを効率的に抽出するために最適化されたデセントリック・クエリー・エンジンです。現在、100を超えるEVMとSubstrateネットワーク、そしてベータ版であるSolanaとStarknetの過去のオンチェーンデータを処理しています。このデータには、EVMのイベントログ、トランザクションのレシート、トラッキング、トランザクションごとのステータスの違いなどの詳細情報が含まれます。また、ゼロ知識プルーフ・オブ・マーケットや信頼された実行環境(Trusted Execution Environment:TEE)を介してオフチェーンデータレイクリソースネットワークにトラストレスで接続するためのマルチチェーンインデキシング機能を利用したコプロセッサやRAG機能も開発しています。
従来のブロックチェーンデータクエリ方法は、時間がかかり、断片化され、コストがかかるため、開発者が意味のある洞察を抽出するのは困難です。
Subsquidの分散型クエリエンジンは、カスタマイズされたデータパイプラインとリアルタイム更新を可能にするスケーラブルなモジュラーアーキテクチャを提供し、データ抽出の速度を最大100倍向上させ、コストを最大90%削減します。90%削減することができます。
現在の製品スイート
これらのツールにより、開発者は大量のブロックチェーンデータに効率的にアクセスして分析できるようになり、複雑な分散型アプリケーションの構築と拡張が容易になります。アプリケーションの構築と拡張を容易にします。
1. Subsquidネットワーク: 100以上のEVMとSubstrateネットワーク、ベータ段階のSolanaとStarknetから過去のオンチェーンデータを処理する分散クエリーエンジン。.
2. SquidSDK:Subsquidネットワーク上にインデクサーを構築するためのTypeScriptツールキットで、データ抽出、変換、ロードのための高レベルライブラリを提供します。
3. Subsquidクラウド:Squid SDKインデクサをデプロイするためのPlatform-as-a-Service(PaaS)であり、Postgresリソース、ゼロダウンタイムマイグレーション、高性能RPCエンドポイントを提供します。
4. Subsquid Firehose: 大規模なセットアップなしでサブグラフの開発とデプロイを容易にする、オープンソースの軽量アダプターです。
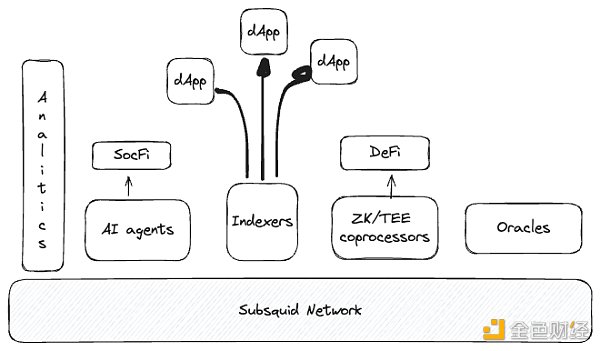
モジュラーアーキテクチャ
市場にある他のソリューションとは異なり、Subsquid独自のモジュラーアーキテクチャは、開発者による最適な柔軟性とカスタマイズを可能にします。.これは、Web3 開発の次の段階に移行し、アプリケーションやユースケースをより複雑で豊富な機能にする際の重要な差別化要因となります。
1. カスタマイズ:開発者は、データ処理パイプラインの各コンポーネントを特定のニーズに合わせてカスタマイズできるため、より効率的で効果的なデータ処理が可能になります。
2. スケーラビリティ: モジュラー性により、処理ノードを追加するだけで、水平方向の拡張やデータ負荷の増加に対応することが容易になります。
3. 柔軟性:パイプラインのさまざまな段階を独立して開発および最適化できるため、Subsquidはさまざまなユースケースやパフォーマンス要件に適応できます。
4. 効率:データフローと処理ロジックをきめ細かく制御することで、Subsquidはインデックス作成とクエリタスクでより高いパフォーマンスと効率を達成できます。
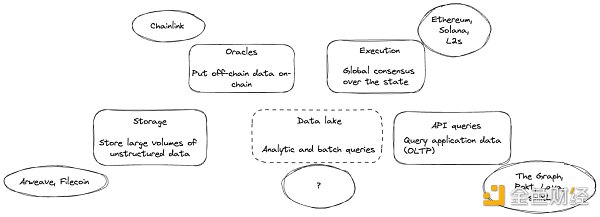
モジュラーデータアクセスアプローチのパワーを説明するために、アナリティクスとリアルタイムデータアクセスのユースケースを比較します。どちらも効率的なオンチェーンデータソース(Subsquidネットワーク)を必要としますが、パイプラインの残りの部分はまったく異なる技術を必要とします。Web2 の世界では、アプリケーションのリアルタイム・データ・アクセスは通常、比較的小規模なトランザクション・データベース(Postgres、SQLite)でサポートされますが、分析には Snowflake、BigQuery、Trino などのビッグデータ・ソリューションが必要です。同じ区別がWeb3のユースケースにも当てはまり、Subsquidは、両方の垂直方向から価値の有意義なシェアを獲得するために独自の位置にあります。
ターゲット市場とユースケース
Subsquidのテクノロジーは、以下のような高い関連性を持っています。
1. Decentralised Application Projects (dApp Projects):DeFi、NFT、ゲーム、ソーシャルメディア、その他の分野の分散型アプリケーションのパフォーマンスとユーザーエクスペリエンスを向上させる。パフォーマンスやユーザーエクスペリエンスを向上させる。
2. ブロックチェーンネットワーク:L1およびL2ネットワークのデータインフラを改善し、開発者がより効率的なデータ駆動型アプリケーションを構築できるようにします。アプリケーションを構築できるようにします。
3. アナリティクスとリサーチ:企業が大量のブロックチェーンデータを処理して、洞察と傾向を抽出できるようにします。
オンチェーンデータとWeb3データは、1バイトあたりの価値がWeb2よりも桁違いに高く、スマートコントラクト、インデクサ、分析API、AIエージェントのようなエッジテクノロジーによって消費されます。
顧客ケーススタディ
1. Railgun:プライバシー重視のEVMウォレット基盤
。-Railgunは直接RPCコールを使って残高をスキャンする内部ツールを使っていましたが、遅かったのです。すべてのチェーンで機能的に一貫していないグラフを使用しようとした後、Subsquidは新しい「プライバシープール」製品で残高スキャンの速度を改善しました。
2. CoinList:主要なトークン立ち上げプラットフォーム
- CoinListは定期的に新しいプロジェクトを扱っているため、サポートする予定のチェーンに適したプラットフォームを見つけることが重要です。そのため、サポートしようとするチェーンに適したノードプロバイダーを見つけるのは、しばしば面倒な作業となる。大規模なプロバイダーは新しい小規模なチェーンをサポートしないし、小規模なプロバイダーに頼るのは困難で信頼性に欠ける。プロジェクトチーム自身からデータを入手することも、このインフラが改ざんされたり、メンテナンスが不十分であったりする可能性があるため、望ましくありません。Subsquidは、CoinListがこの問題を完全に回避することを可能にします。
- The platform is very interested in Subsquid's upcoming native support for hot blocks in data lakes, because this will completely eliminate RPC constraints.これは、CoinListのようなトークン発行プラットフォームだけでなく、ゲームやソーシャルなどのさまざまなdAppsやマルチチェーンプラットフォームにもデフラグの機会を開くもので、あらゆる規模のエコシステムからの情報を必要とする可能性があります。
見落とされ、誤解されている
サブスクが現在市場で過小評価されている主な理由は、その知名度の低さです。その技術的な違い、機能的な価値、初期のユーザーへのアピール、大きな可能性にもかかわらず、このプロジェクトは相応の注目を浴びていません。
- Weak brand marketing:Subsquidは、最初の数年間は製品開発と顧客獲得のみに注力し、ブランドマーケティングへの投資が不十分だったことを認めています。
- Token Offering Lacklustre:マーケティング努力が不十分であったため、SQDトークン提供は他のブロックチェーン・プロジェクトほど話題を集めず、その結果、最初の評価額は低くなりました。
- 洗練された技術的な違い:Subsquidの製品の洗練された技術性は、より広い市場からは理解されにくく、評価されにくいかもしれません。
現在、チームはブランド認知に注力しており、M31キャピタルのような戦略的パートナーの助けを借りて、プロジェクトは市場によりよくその価値を伝えることができ、短期的な評価の大幅な上昇につながると考えています。
競合の状況
サブスクの主な競合には、ザ・グラフ、ゼッタブロック、スペース&タイムなどがあります。Time.各プラットフォームには独自の強みと弱みがあり、選択は特定のプロジェクトのニーズによって決まります。私たちは、Web3データレイク/ウェアハウス市場は、長期的には複数の大きな勝者によって巨大なものになると考えています。
グラフ:
- Predefined Subgraphs: グラフは以下のものに依存しています。サブグラフは、データのインデックス付けとクエリのための事前定義された命令セットです。このアプローチは構造化されたユーザーフレンドリーなアプローチを提供しますが、Subsquidモジュールプロセッサによって提供される深いカスタマイズが欠けています。
- Indexing Mechanisms: Graph はより厳密なインデックス作成メカニズムを使用しており、インデックス作成ロジックを変更するには、通常、サブグラフの大幅な調整や再展開が必要です。
- Performance: サブグラフの複雑さとネットワーク負荷に応じて、中程度から高いパフォーマンスを提供します。クエリのレイテンシーが低く、インデクサを追加することで水平方向に拡張できます。
-
ゼッタブロック:
- Centralised Control, Decentralised Intent: ZettaBlockは中央集権化されたインフラと分散化された信頼メカニズムを組み合わせています。このアプローチは、リアルタイムのデータ索引付けとクエリ機能を提供しますが、Subsquidに見られるようなモジュラーカスタマイズのレベルは提供しません。
- Data Pipelines: ZettaBlockは、カスタマイズ可能なETL(抽出、変換、ロード)プロセスを備えたリアルタイムのデータパイプラインに重点を置いていますが、Subsquidの完全に分散化されたモジュラーアプローチよりも中央集権的な制御フレームワークを使用しています。中央集権的な制御フレームワーク
- Performance: 短いクエリ応答時間でリアルタイムのデータインデックスを作成するように設計されています。リアルタイムのデータパイプラインを必要とするアプリケーションに対して高いスケーラビリティを発揮します。
Space and Time:
- SQL Proofing and Hybrid Processing:スペースと時間。SQL Proofによるデータ整合性を重視し、トランザクションと分析のハイブリッド処理をサポートします。データ整合性と処理のための高度な機能を提供する一方で、そのアーキテクチャはインデックスパイプラインという点ではSubsquidほどモジュール化されておらず、カスタマイズもできません。
- Data Warehousing: Space and Timeのアーキテクチャは分散型データウェアハウスを中心としており、大規模なデータクエリに威力を発揮しますが、Subsquidの柔軟なモジュール式パイプラインに比べるとモノリシックです。
- Performance: ブロックチェーンとオフチェーンデータの高パフォーマンスのために最適化されています。ハイブリッドトランザクションとアナリティクス処理をサポートし、低レイテンシーとスケーラビリティを確保します。strong>Subsquidの差別化
データ処理に対するSubsquid独自のモジュール式でカスタマイズ可能なアプローチは、柔軟性、パフォーマンス、スケーラビリティへの注力と相まって、他のブロックチェーンデータインデキシングおよびクエリプラットフォームとは一線を画しています。業界が成熟し、アプリケーションがよりマルチチェーンで複雑になるにつれ、この機能の価値はますます高まるでしょう。
1. Customised indexers and processors:
- Flexible indexing(柔軟なインデクシング):開発者は、高度にカスタマイズ可能なインデクサーとプロセッサーを構築できます。複雑なデータ統合タスクを容易にし、ブロックチェーンデータから意味のある洞察を抽出します。
- Performance Optimisation: カスタムプロセッサは、インデクシングとクエリが効率的でスケーラブルであることを保証するために、パフォーマンスを最適化できます。
2. Multi-Stage Processing Pipeline:
- Data Flow Architecture: Multi-Stage Processing Pipelineは、データの抽出、変換、保存を別々のプロセスに分割します。データ処理タスクの管理性と拡張性を向上させます。
- Modular: パイプラインの各ステージは独立して開発および最適化できるため、データ処理ワークフローをより詳細に制御できます。
3. Support for Multiple Data Sources:
- Diverse Blockchain Integration: 様々なブロックチェーンをサポートし、様々なデータベースと統合することができます。をサポートし、さまざまなデータベースと統合できるため、さまざまなブロックチェーンエコシステムで働く開発者にとって汎用性の高いツールとなっています。
- Adaptability: プラットフォームは複数のデータソースを扱えるため、ブロックチェーン業界のニーズの変化に確実に対応できます。
4.開発者に優しいツールとSDK
- 統合SDK:以下を提供します。カスタムデータインデクサーおよびプロセッサーの開発を簡素化するためのツールとライブラリを含むソフトウェア開発キット(SDK)です。
- APIサポート: GraphQLやSQLなど、データクエリ用のさまざまなAPIをサポートし、開発者に柔軟性を提供します。
5.分散型でスケーラブルなアーキテクチャ
- 分散処理: The GraphやSpace and Timeと同様に、Subsquidは分散型のノードネットワークを活用してデータを処理し、インデックスを作成します。データを処理しインデックスを作成するノードの集中型ネットワークにより、高い可用性とフォールトトレランスを保証します。
- Scalability: プラットフォームは、増大するデータとクエリを効率的に処理するために水平方向に拡張できるように設計されています。
6. パフォーマンスと効率
- ハイパフォーマンス:プラットフォームは、データ処理パイプラインの各段階でカスタマイズを使用することで、ハイパフォーマンスを実現するように設計されています。データ処理パイプラインの各段階で、Subsquidはデータのインデックス作成とクエリタスクで高いパフォーマンスを実現します。
- Resource Efficiency: プラットフォームアーキテクチャは、計算リソースの効率的な使用を保証し、データ処理のコストと複雑さを軽減します。
この最後のポイントは、Subsquidとこの分野で最も確立された競合であるThe Graphを比較する際に特に重要です。

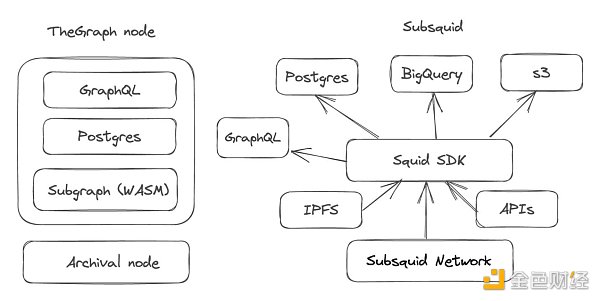
相対的な評価額
Subsquidの最も流動性の高いトークンはGRTで、SQDのFDVプレミアムの18倍で取引されています。SQDがWeb3ビッグデータ・スペースの価値に市場の注目を集めるきっかけになるはずだ。
長期的には、Web3業界が成熟するにつれて、Subsquidを現在の同様のWeb2企業と比較することは理にかなっている。
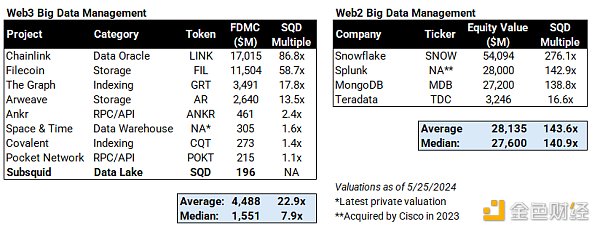
TAM2030とアップサイドの可能性
ブロックチェーンデータ管理とWeb3全般はまだ発展途上ですが、Subsquidの長期的なTAMの参考としてWeb2を見ることができます。私は以前、2030 Web3市場全体の潜在的なアップサイドを見積もり、Web3のGDP(総収入)は2030年までに5.6兆ドルに達するとした。Web2のデータレイクとウェアハウス市場がWeb2のGDP全体に占める割合をとれば、Web3のGDP予測に当てはめることができ、2030年には236億ドルに達するでしょう。
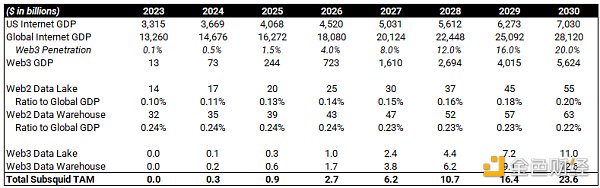
(出典:omnoblack!="https://omnida.substack.com/p/quantifying-the-thesis-web3">オムニチャインの観測、フューチャー・マーケット・インサイト、expert-market-research)
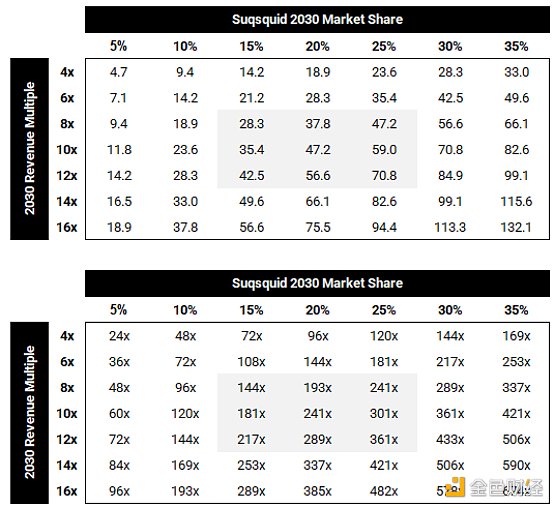
2030年のサブスクの市場シェアを20%と仮定し、売上高倍率を10倍(以下で詳しく説明するように、高成長資産としては合理的)とすると、SQDの価値は470億ドルとなり、現在のFDVの240倍となる!
なぜ20%の市場シェアなのか?Web2データ管理プロバイダーの競争力学を見ると、市場リーダーは長い間40%以上のシェアを維持してきました。Web3のより細分化された性質を考えると、Subsquidの上昇シナリオでは20%が妥当な想定だと考えています。
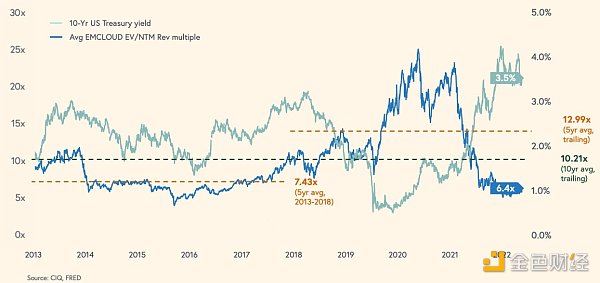
なぜ10倍の収益なのか?これはパブリック・クラウド企業の10年平均です(2020年には最高22倍に達します!)。.
サブスクイッド2030年のFDV s(数十億ドル)とリターン・マルチプルの感度表は以下の通りです:
- Highly Asymmetric Risk/Reward Investment Opportunity; Subsquid's Current FDV Offers 18x Upside to Achieve Valuation Parity With The Graph (GRT).テクノロジーとネットワーク経済性において客観的に劣ると思われるThe Graph (GRT)には、240倍以上の長期的なアップサイドがあります。
- Web3 技術スタック(データレイクとリポジトリ)の非常に価値のある部分におけるユニークで差別化された資産であり、アプリの複雑さが加速し続け、分散型AIが普及し、一般的な業界の採用が拡大し、オンチェーンデータが指数関数的に増加するにつれて、その重要性はさらに高まるでしょう。成長につながります。
- Ignored and grossly mispriced because ineffective branding, lacklustre token launch campaigns, and esoteric technology differentiation.
-
- 市場の関心が低いにもかかわらず、Subsquidは大手既存企業を凌駕するネットワークアーキテクチャ、印象的な初期の顧客牽引力、完全なデータウェアハウス機能、共同処理やRAG機能を提供するエキサイティングなロードマップを持っています。
-
- 6月のメインネット立ち上げ、今後のウェブサイトの刷新とブランド再構築、マーケティングと戦略的パートナープログラムへの新たな注力など、複数の短期的なきっかけがあります。
技術設計
サブスクイッドは、無制限の水平スケーラビリティ、パーミッションレスデータアクセス、信頼できるクエリの最小化、低メンテナンスコストを提供するように設計されています。
- raw data is uploaded into permanent storage by the data provider.
- The data is compressed and distributed among the network nodes.
-
- ノードオペレータは保証金を支払います。
- 各ノードはDuckDBを使用して、効率的にローカルデータを照会します。
- Queries can be validated by submitting a signed response to an on-chain smart contract.
ネットワークアーキテクチャ
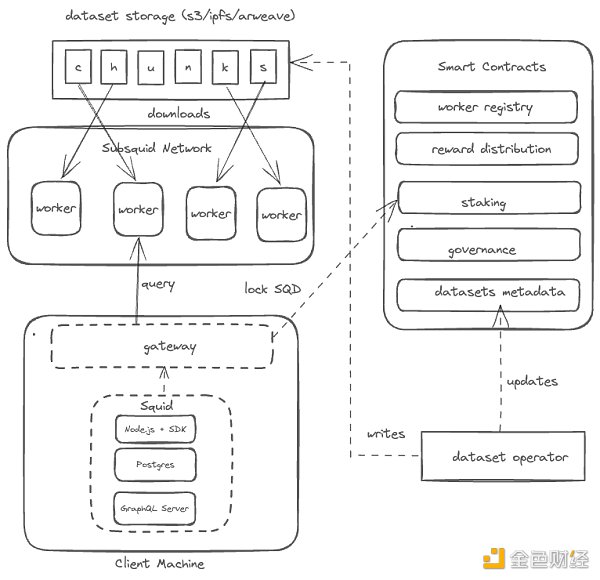
1. データプロバイダー:データプロバイダーは、データが高品質でタイムリーに利用できることを保証します。スタートアップ段階では、Subsquid Labs GmbH が唯一のデータプロバイダーとして、個々のチェーンからブロックごとに抽出されたデータの代理を務めます。このデータはハッシュを比較することで検証され、小さな圧縮ブロックに分割されて永続ストレージに保存される。これらのブロックはランダムにワーカーに割り当てられる。
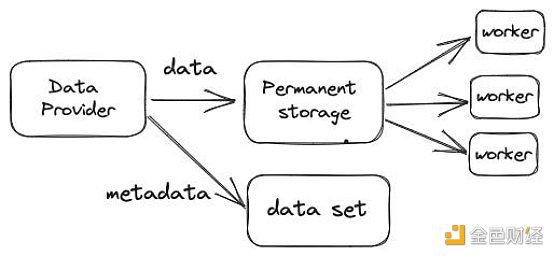
2. <。strong>ワーカー:ネットワークにストレージとコンピューティングリソースを提供し、ピアツーピアでデータを提供し、報酬としてSQDトークンを受け取ります。SQDホルダーは特定のワーカーにトークンを委任することもでき、信頼性を示して報酬の一部を受け取ることができる。
3. スケジューラー:データプロバイダーから提出されたデータブロックをワーカーに割り当てる。データセットとワーカーセットの更新を監視し、容量と冗長性の目標に基づいて、新しいブロックをダウンロードしたり、既存のブロックを再配置したりするリクエストをワーカーに送ります。更新要求を受け取ると、ワーカーは永続ストレージから不足しているデータブロックをダウンロードします。
4. Log Collector: ワーカーからアクティブな ping とクエリ実行ログを収集し、バッチ処理してパブリック永続ストレージに保存します。これらのログはワーカーの P2P ID によって署名され、IPFS 上に固定されます。他のネットワーク参加者が使用できるように、少なくとも6ヶ月間保存されます。
5. 報酬マネージャー:ログにアクセスし、報酬を計算し、サイクルごとに請求可能な約束を提出する。労働者はその後、一定期間後に期限切れとなる報酬を個別に受け取ります。
6. データコンシューマー:ゲートウェイを操作するか、外部提供のサービス(パブリックまたはプライベート)を使用してネットワークに問い合わせる。各ゲートウェイはチェーン上のアドレスにバインドされる。ゲートウェイが送信できるリクエストの数は、ロックされたSQDトークンの数によって決まり、ロック期間が長ければ長いほど、仮想的な「計算ユニット」(CU)が増えます。複雑なSQLクエリが実装されるまでは、すべてのクエリのコストは1CUです。
クエリの検証
Subsquidネットワークは、経済的保証と、場合によってはオンチェーン検証を通じて、クエリデータの妥当性を提供します。すべてのクエリ応答は、応答へのコミットメントとして、クエリを実行するワーカーによって署名されます。もしそれが正しくないことがわかれば、ワーカーのマージンは減らされる。
1. Authoritative Proof: オンチェーンIDのホワイトリストがレスポンスの妥当性を決定します。
2. Optimistic on-chain validation: リクエストを検証した後、誰でも不正なレスポンスの証明を提出できます。
3. ゼロ知識証明: ゼロ知識証明は、レスポンスがリクエストに正確にマッチすることを検証します。この証明はチェーンの下のプローバーによって生成され、スマートコントラクトによってチェーン上で検証されます。
今後の製品開発
私たちは、Subsquidプラットフォームの現在のインデックス作成とクエリ機能、およびユーザーの魅力が過小評価されていると強く信じていますが、長期的な成長の可能性は、次のような今後の製品によって牽引されるでしょう。により、TEE/ZK コプロセッシングや RAG 機能のような、将来の高性能 Web3 アプリケーションに不可欠なインフラストラクチャとなる製品によって牽引されるでしょう。
1. TEE/ZKコプロセッサ:
- Subsquid は、次のようなコプロセッサソリューションを開発しています。Subsquidは、強力なマルチチェーンインデキシング機能とサードパーティのTEEおよびZK認証機能(Brevis、Polyhedra、Phalaなど)を組み合わせたコプロセッサソリューションを開発しており、オンチェーンのスマートコントラクトとデータレイクリソースのオフチェーンネットワーク間の信頼性のない接続を可能にしています。単一のZKソリューションを開発するのではなく、複数の認証オプションを提供することが、特定のユースケースやワークロードのパフォーマンスを最適化する理想的な方法だとサブスクイドは考えています。
- This opens the door for highly computational and data-driven on-chain applications such as order book DEX, lending agreements, and perpetual contracts, even on blockchains with low TPS and strict programming languages.
2. AIエージェント/RAG機能:
- 今後10年以内に、インターネットトラフィックの大半が生成され、RAG機能によって生成されることが予測できます。インターネットトラフィックの大部分は、AIエージェントによって生成され、消費されることが予測されます。反論によれば、すぐに使えるAIエージェント・プラットフォームが市場を支配する可能性はなく、特定の趣味のドメインにのみサービスを提供するウェブサイト構築プラットフォーム(Wordpressなど)と同様である。一方、2000年以降の成長で最大のシェアを獲得したのは、インフラ側のアマゾン・クラウド・サービス(AWS)だ。
- AI & ブロックチェーン分野でも同様の動きが予想されます。Subsquidの目標は、データアクセスを成長のフライホイールにするために、高いスループットで実行可能な最小限のインターフェイスを提供することです。
顧客誘致と戦略的パートナー

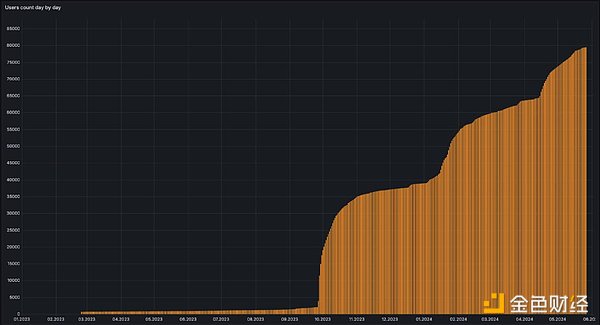
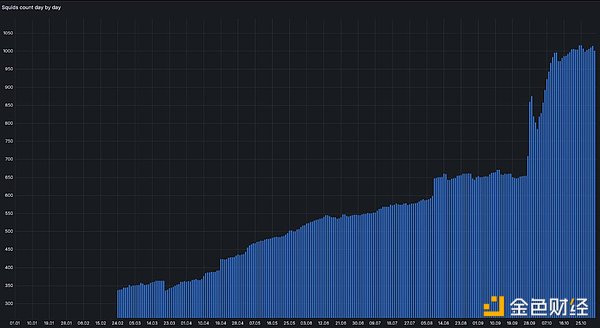
昨年末のテストネットワーク開始以来、加入者数、Squids(クラウドインデクサー)、アーカイブクエリ(ウェブ検索)、ウェブデータトラフィックは増加傾向にあります。
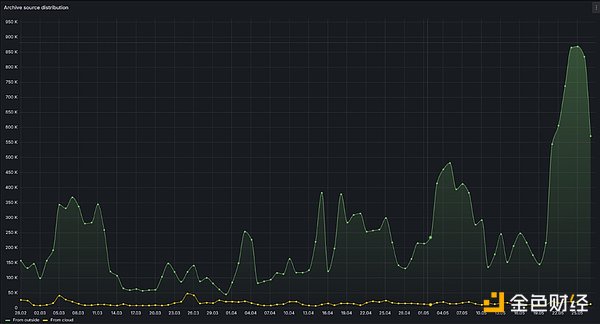
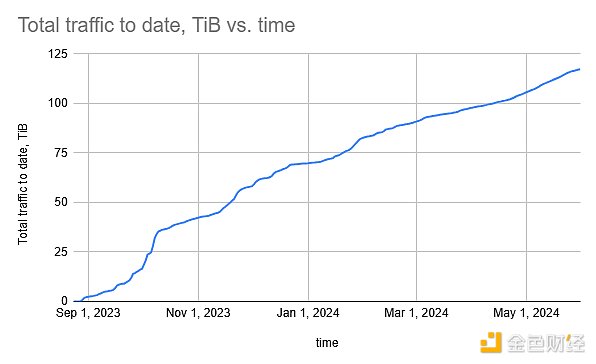
Google Cloud Partnerships ()BigQueryの統合)
GoogleクラウドのBigQueryは、企業や個人がペタバイト級のデータを保存・分析できる強力なエンタープライズデータウェアハウスソリューションです。大規模なデータ分析向けに設計されたBigQueryは、マルチクラウドのデプロイメントをサポートし、組み込みの機械学習機能を備えているため、データサイエンティストはシンプルなSQLを使用してMLモデルを作成できます。
マルチチェーン・プロジェクトでは、BigQueryと連携してSubsquidを活用することで、さまざまなチェーンでの使用状況を迅速に分析し、経費、運用コスト、傾向に関する洞察を得ることができます。カスタム化したデータをBigQueryに保存することで、開発者はGoogleの分析ツールを活用し、単一のチェーンやプラットフォームのコンテキストを超えて、製品の使用状況を理解することができます。
ロードマップと今後の展開
1. メインサイト:6月3日に公開。7月には参加規模を拡大するため、SQDインセンティブの強化が予定されている。

2. Rebranding.strong>リブランディング:ウェブサイトを刷新し、新しいブランド戦略を数週間以内に立ち上げる予定です。
3. コスモス・サポート:コスモスのエコシステムの機能を拡張し、ユーザーベースを広げる。
4. License-free datasetdataset submission: データセットは現在Subsquid GmbHによって管理されており、分散型の投稿とキュレーションが計画されている。
5. 分散型SQLデータベース・ストリーミング:データレイク内のデータベースを分散・同期し、正確性と適時性を確保する。
6. Enterprise tools: リアルタイムのデータ処理にKafkaを、ビッグデータの分析と保存にSnowflakeを導入する。
7. Co-processing and RAG機能: 現在PoC中ですが、チームは近い将来、より具体的な製品ロードマップを発表する予定です。
短期的な再評価と長期的な成長ストーリー
SQDは、私が見た中で最も魅力的な流動性トークン投資機会の1つです。今後複数のカタリストがあり、トークンは短期的に10~20倍の再評価が可能ですが、長期的なTAMは240倍以上のエキサイティングな上昇ポテンシャルを提供すると考えています。
暗号市場,BTC,Cracking Crypto Paradox: Beyond Code is Law Towards Model is Trust Golden Finance,私たちは望ましい未来に向かって大きく前進しているのか?
JinseFinanceWeb 3.0,コード・ネイション:「コードは法律」黄金金融の小史,コード・エラーの結果は、ヒューマン・エラーよりも深刻になる可能性がある。
JinseFinanceこの祝日は、ビットコインの歴史を振り返るだけでなく、そのコミュニティ精神を祝う日でもある。
JinseFinanceCoinListのSubsquid(SQD)コミュニティセールの開始は、分散型データソリューションにおける重要な一歩であり、ブロックチェーン領域における魅力的な投資機会を提供する。
 Kikyo
KikyoETH の上海アップグレードは非常に期待されています。なぜなら、この変更が実行されると、ユーザーはステークされたイーサリアムを引き出すことができるからです。
 Catherine
CatherineJack Dorsey の Web5 に対するビジョンを際立たせる要素がいくつかあります。たとえば、Web2 を完全に置き換えるのではなく、Web2 と連携させたいということです。
 Coindesk
CoindeskFTX の最初の破産公聴会の予定を立てるのに 1 週間以上かかりましたが、ついに実現しました。ライブツイートは何が起こったのかを詳しく説明しました.
Catherine現在、合計267万人の膨大な数のユーザーがおり、一般的な暗号通貨市場で毎日平均95.56Kの意見が収集されています.
 Nulltx
Nulltx参加証明 (PoP) について聞いたことがありますか? XEN暗号の紹介!その価値が市場参加者の数に基づいている暗号。
 NellNulltx
NellNulltx