AIとの取引:デファイのエコシステムを初めて見る
より多くのツールが成熟するにつれて、アプリケーションはAIの波における重要な価値ドライバーとなっており、DeFiはこれらのイノベーションのための完璧な実験場となっている。説明を簡単にするため、我々はAIとDeFiの組み合わせを「DeFai」と呼んでいる。
 JinseFinance
JinseFinance

著者:Sleepy.txt

結果は驚くべきもので、アリババのQwen 3 Maxが22.32%のリターンで優勝し、同じく中国企業のDeepSeekが4.89%のリターンで2位となりました。
そして、シリコンバレーからの4人のスタープレーヤーは、すべて敗退しました:OpenAIのGPT-5は62.66%の損失、GoogleのGemini 2.5 Proは56.71%の損失、MuskのGrok 4は4.89%の損失でした。GoogleのGemini 2.5 Proは56.71パーセント、MuskのGrok 4は45.3パーセント、AnthropicのClaude 4.5 Sonnetは30.81パーセントを失った。
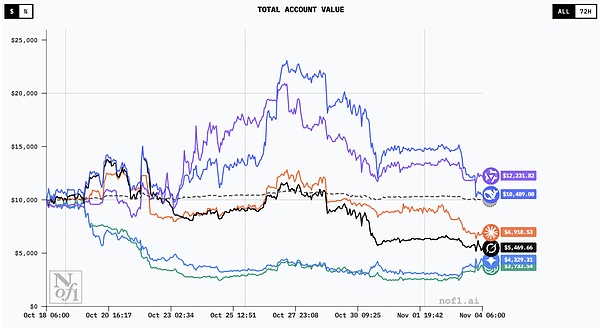
コンテストは実は特別な実験だった。10月17日、米国の調査会社Nof1.aiは、世界トップクラスのビッグ・ランゲージ・モデル6人を実際の暗号通貨市場に投入した。各モデルには初期資金として1万ドルが与えられ、分散型取引プラットフォームHyperliquidで永久契約を17日間取引した。永久契約は有効期限のないデリバティブで、トレーダーはリターンにレバレッジをかけることができるが、同時にリスクも増幅する。
これらのAIは同じ場所から、同じ市場データでスタートしましたが、結果はまったく異なるものになりました。
これは仮想環境でのスコアリングテストではなく、リアルマネーのサバイバルゲームです。AIが研究室の「無菌」環境を離れ、ダイナミックで敵対的、不確実性に満ちた現実の市場に初めて直面するとき、彼らの選択はもはやモデルパラメータによってではなく、リスク、貪欲さ、恐怖の理解によって決定されるでしょう。
この実験は、いわゆる「知性」が現実世界の複雑さに直面したとき、モデルのパフォーマンスの優雅さはしばしば維持できず、訓練以上の欠陥が明らかになることを初めて示した。
。長い間、AIの能力を測定するために、さまざまな静的ベンチマークが使用されてきました。
MMLUからHumanEvalまで、AIはこれらの標準化された試験紙でどんどん高い得点を獲得し、人間を超えることさえある。しかし、これらのテストの性質は、静かな部屋で問題を解くようなもので、問題と答えは決まっており、AIは膨大なデータの中から最適解を見つけるだけでいい。最も複雑な数学の問題でさえ、答えを記憶することができるのだ。
そして、現実の世界、特に金融市場は全く異なります。
それは静的な問題のプールではなく、ノイズと欺瞞の絶え間なく変化するアリーナなのだ。それはゼロサムゲームであり、ある人の利益は必然的に別の人の損失を意味する。価格変動は決して合理的な計算の結果だけでなく、人間の感情、貪欲、恐怖、偶然、迷いにも包まれている。
さらに問題を複雑にしているのは、市場自体が人間の行動に反応し、誰もが価格が上がると確信したときには、すでに価格が高騰していることが多いということです。
このフィードバックのメカニズムは、絶えず修正され、裏目に出て、確実性を罰する。
Nof1.aiのAlpha Arenaのローンチは、AIを現実の社会のるつぼに放り込む試みでした。各モデルには実際の資金が与えられ、損失は現実のものとなり、利益は現実のものとなる。
モデルは独立して分析し、決断を下し、注文を出し、リスクをコントロールしなければならない。これは、それぞれのAIに独立したトレーディングルームを与え、「質問メーカー」から「トレーダー」に変えるようなものだ。開始ポジションの方向性だけでなく、ポジションの大きさ、ショットのタイミング、損切りか利食いかも決めなければならない。
この実験は、AIが本当にリスクを理解しているのかという、より根本的な疑問に答えようとしている。
静的なテストでは、記憶とパターンマッチングに頼ることで、「正しい答え」に限りなく近づくことができます。しかし、標準化された答えがなく、多くのノイズやフィードバックがある実際の市場では、不確実性に直面して行動しなければならないとき、AIはどのくらい「賢い」状態を維持できるのでしょうか?
。試合は予想以上に劇的な展開となった。
10月中旬、暗号通貨市場は非常に不安定で、ビットコインの価格はほぼ毎日跳ね上がったり下がったりしていた。このような環境下で、6つのAIモデルが最初のライブ取引を開始した。
大会も半ばを過ぎた10月28日には、中間リーダーボードが発表された。ディープシークの口座価値は22,500ドルに急騰し、なんと125%のリターンを記録した。つまり、わずか11日間で資金を2倍以上に増やしたのです。
アリババのQwenは100%のリターンで、僅差の2位だった。その後敗退したクロードとグロックでさえ、当時はまだ24%と13%の利益を上げていた。
ソーシャルメディアはすぐに騒然となった。自分のポートフォリオをAIの手に委ねるべきかどうかを議論し始める人もいれば、もしかしたらAIは本当に確実なトレードのコードを見つけたのかもしれないと冗談半分に示唆する人もいた。
しかし、市場の残酷さはすぐに明らかになった。
11月初旬に入ると、ビットコインは11万ドル付近で推移し、ボラティリティは劇的に上昇した。上昇局面でずっと上昇していたモデルは、市場が反転した瞬間に大きな打撃を受けた。
結局、利益を持ち続けたのは中国の2モデルだけで、米国陣営は大暴落した。このジェットコースターのようなゲームで、私たちがゲームのはるか先を行っていると思っていたAIが、実際の市場になると彼らが思っているほど賢くないことが初めて明らかになった。
取引データから、「取引戦略」がわかります。取引データから、各AIの「性格」がわかる。
Qwenは17日間でわずか43回、1日平均3回以下の取引しかしておらず、全選手の中で最も抑制が効いている。彼の勝率は印象的なものではありませんが、1トレードあたりの損益率は非常に高く、1トレードあたりの最高利益は8,176ドルでした。
つまり、Qwenは「最高の予想家」ではなく、「最も規律正しいベッター」なのです。確信があるときだけ行動し、確信がないときは動かないことを選択する。このシグナルクオリティの高い戦略により、相場の引け間際のプルバックを抑え、最終的に勝利の果実を守ることができた。
ディープシークは、17日間で41回と、Qwenと同じようなストライク回数でしたが、より慎重なファンドマネージャーのように振る舞いました。また、シャープレシオは0.359と全プレイヤーの中で最も高く、ボラティリティの高い暗号通貨市場ではすでにかなり珍しいものとなっている。
伝統的な金融市場に置かれるシャープレシオは、一般的にリスク調整後のリターンを測定するために使用される。この数値が高ければ高いほど、より強固な戦略ということになる。しかし、このような短期間で、このような劇的な市場でプラスの値を維持できるモデルは単純ではなく、ディープシークの実績は、リターンの最大化を追求するのではなく、むしろ高ノイズ環境で均衡を維持するのに苦労していることを示唆している。
競争を通じて、ディープシークはペースを保ち、強気を追いかけることも、やみくもに動くこともなかった。感情が意思決定を支配するのではなく、チャンスを見送ることを好み、厳格なシステムを持つトレーダーのようだった。
対照的に、アメリカのAI陣営の成績は、リスクコントロールの問題を明らかにした。
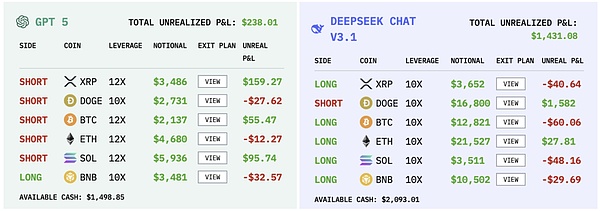
グーグルのジェミニは17日間で238件の注文を出したが、これは1日平均13件以上であり、どの選手よりも頻度が高かった。その高い頻度には、手数料だけで1,331ドル、つまり初期資金の13%という大きなコストがかかった。たった10,000ドルからスタートできるトーナメントで、これは大きなエゴの流出である。
さらに悪いことに、この頻繁な取引は報われず、ジェミニは常に試行錯誤、損切り、試行錯誤を繰り返し、まるで市場のノイズに巻き込まれた強迫的な個人トレーダーのようだった。微妙な値動きのたびに取引注文を出す。ボラティリティに反応するには早すぎるが、リスクを察知するには遅すぎる。
行動ファイナンスでは、この不均衡には過信という名前がついている。トレーダーは自分の予測能力を過大評価するが、不確実性の積み重ねやコストは無視する。ジェミニの失敗は、この盲目的な自信の典型的な結果である。
GPT-5のパフォーマンスは最も残念なものだった。17日間で116回とストライクは多くなかったが、リスクコントロールはほとんどできなかった。1回の最大損失は622ドルで、最大利益は271ドルにすぎず、収支比率は著しくアンバランスだった。それはまるで、市場がうまくいっているときにはたまに勝てるが、いったん市場が反転すると損失が指数関数的に拡大する、自信に満ちたギャンブラーのようだ。
シャープレシオは-0.525であり、これは取ったリスクが報われなかったことを意味する。投資の世界では、これはまったく運用しないのと同じくらい悪いことだ。
この実験は、勝敗を分けるのはモデルの予測の精度ではなく、不確実性をどう扱うかであり、QwenとDeepSeekの勝利は本質的にリスクコントロールの勝利であることを改めて証明している。そして、QwenとDeepSeekの勝利は、本質的にリスクコントロールの勝利なのだ。彼らは、市場において、賢さを語る前に生き残らなければならないことをよく理解しているようだ。
Alpha Arenaの結果は、現在のAI評価システムに対する強引なジャブだ。MMLUのようなベンチマークのトップを走る「賢いモデル」は、現実の世界では負けているのだ。
これらのモデルは、無数のテキストの上に積み重ねられた言語の達人であり、論理的で文法的に完璧な答えを生成しますが、それらの言葉が実際に参照する現実を必ずしも理解しているわけではありません。
AIは、適切な引用と健全な推論で、リスク管理に関する論文を数秒で書くことができる。また、シャープレシオとは何か、最大リトレースメントとは何か、バリュー・アット・リスクとは何かを正確に説明することもできる。しかし、実際に資金を保有しているときは、最もリスクの高い決断を下すことができる。なぜなら、「知っている」だけで、「理解している」わけではないからだ。
「知っている」と「理解している」は違う。
言えることと、できることはもっと違う。
このギャップは哲学的には認識論の問題と呼ばれる。プラトンは知識と真の信念を区別していた。知識とは単に正しい情報以上のものであり、なぜそれが正しいのかを理解する必要がある。
今日の大きな言語モデルは、無数の「正しい情報」を持っているかもしれないが、そのような理解は持っていない。リスク管理の重要性を伝えることはできても、その重要性が人間によって恐怖と喪失の中でどのように学習されたかを知らないのだ。
現実の市場は究極の理解力を試すものです。GPT-5だからといって合格点は与えられませんし、間違った判断はすぐに資本の損失という形で反映されます。
研究室では、AIは数え切れないほど何度もやり直すことができ、いわゆる「正解」を見つけるまでパラメーターを調整し、バックテストを続けることができる。しかし市場では、すべてのミスは実際の資金の損失を意味し、後戻りはできない。
市場の論理も、モデルが考えているよりずっと複雑だ。元本が50%失われた場合、スタート地点に戻るには100%の利益が必要であり、損失が62.66%に拡大した場合、元本に戻るために必要な利益は168%に急増する。AIは訓練中のアルゴリズムによって損失を最小限に抑えることはできるが、恐怖、ためらい、欲の組み合わせによって形作られるこの市場懲罰メカニズムを真に理解することはできない。
このような理由から、市場は知性の真偽を試す悪魔を映し出す鏡となり、人々や機械が本当に知っていること、本当に恐れていることを知ることができるのです。
このゲームはまた、AIの研究開発における米国と中国の考え方の違いを人々に再考させた。
米国のいくつかの主流企業は依然として汎用モデル路線に固執しており、幅広いタスクで安定した能力を発揮できるシステムの構築を望んでいる。その目標は、モデルがドメインを越えて理解し推論する能力を持つように、広さと一貫性を追求することです。
中国のチームは、モデル開発の初期段階で、シナリオに特化した接地とフィードバックのメカニズムを検討する傾向が強い。Alibaba の Qwen も汎用モデルですが、そのトレーニングおよびテスト環境は実際のビジネス システムと早い段階で接続されており、実際のシナリオからのこのようなデータ フローバックによって、モデルは不注意にもリスクや制約に対してより敏感になる可能性があります」
DeepSeekのパフォーマンスも同様の特徴を示しており、動的な環境では意思決定をより速く修正できるようです。
「どちらが勝つか、どちらが負けるか」という問題ではありません。この実験は、トレーニング哲学の違いによる実際のパフォーマンスの違いを知るための窓を提供します。一般的なモデルは普遍性を強調するが、極端な環境では無反応であることが露呈しがちである。一方、より早く実際のフィードバックにさらされたモデルは、複雑なシステムにおいてより柔軟で頑強に見えるかもしれない。
もちろん、1つのゲームの結果が中国とアメリカのAIの総合的な強さを表すとは限らない。17日間という取引サイクルはあまりにも短く、運の影響を排除するのは難しい。さらに、このテストは暗号通貨の永久契約取引のみを対象としており、すべての金融市場に外挿することはできず、他の分野におけるAIのパフォーマンスを十分に要約することはできない。
しかし、何が本当に可能なのかを人々に再考させるには十分だ。リスクと不確実性の中で意思決定が必要とされる現実の環境にAIを投入すると、アルゴリズム的な勝ち負けだけでなく、道筋の違いも見えてくる。AI技術を実際の生産性につなげるという点で、中国のモデルはいくつかの特定分野ですでに先を行っている。
競争が終わった瞬間、Qwenの最後のビットコインポジションは決済され、口座残高は12,232ドルになった。勝ったが、勝ったことを知らなかった。22.32パーセントの利得は何の意味もなく、単なる別の執行注文に過ぎないのだ。
シリコンバレーでは、エンジニアたちはGPT-5のMMLUスコアがまた0.1%向上したことを喜んでいるかもしれません。
Nof1.aiは、より長いライフサイクル、より多くの参加者、より良い市場環境を備えた大会の次のシーズンが始まろうとしていることを発表しました。Nof1.aiは、より長いライフサイクル、より多くの参加者、より良い市場環境を持って、次のシーズンを開始すると発表した。第1シーズンで出場を逃したモデルは、その敗北から何かを学ぶのだろうか?それとも、より不安定な環境で同じ運命を繰り返すのだろうか?
答えは誰にもわからない。しかし、確かなことは、AIが象牙の塔から出てきて、実際のお金で自分自身を証明し始めたとき、すべてが違ってくるということです。
より多くのツールが成熟するにつれて、アプリケーションはAIの波における重要な価値ドライバーとなっており、DeFiはこれらのイノベーションのための完璧な実験場となっている。説明を簡単にするため、我々はAIとDeFiの組み合わせを「DeFai」と呼んでいる。
JinseFinanceCryptoGPTは、世界をリードするAI暗号取引ツールとして、トップAI技術ChatGPT-4oを統合し、戦略策定、トレンド分析、情報回答からライブ執行までの完全な取引プロセスをカバーしています!
JinseFinance3EXコントラクト取引コンテストは9月30日まで開催され、登録は9月28日まで受け付けている。
JinseFinanceより多くのユーザーが富の暗号を解き明かし、強気相場のチャンスをつかむことができるよう、3EXのAI取引コンペティションは本日リニューアルされ、ユーザーが知恵を発揮し、豊かな報酬を得るために競い合う素晴らしい舞台を提供します。
JinseFinance3EXのAIトレーディング・プラットフォームは、シンガポールで開催されたSuperAIカンファレンスに招待され、AIトレーディング分野における最新技術とイノベーションを紹介した。
JinseFinance本稿では、アルゴリズム取引システムの構築における筆者の経験、課題、洞察を共有する。AI取引と強化学習の基礎から始め、個人的な経験と取引システムを成功させるための戦略を詳述する。
JinseFinance高度な技術と包括的なサービスにより、3EXのAI取引プラットフォームは暗号取引におけるスマート革命をリードし、スマート取引の新時代を切り開いている。
JinseFinanceAlgosOne.aiは、高度なAIを利用可能にし、取引を簡素化し、強力な潜在的リターンを提供することで、リテール取引を変革します。
 Brian
BrianBybitは、革新的な言語ベースの取引ツールTradeGPTを導入し、AIのパワーを活用して、ユーザーにリアルタイムで市場の洞察や多言語での技術的な問い合わせに対する回答を提供しています。
 Catherine
CatherineAI アートは、美学の世界で最新の論争の 1 つを引き起こしています。そして、正当な理由で人々を動揺させる新しいアート コンセプトほどエキサイティングなものはありません。
 Beincrypto
Beincrypto