NYDIG:ドイツ、Mt.Goxとマイナーの売却がBTC下落を大げさに引き起こしている
NYDIGのグレッグ・シポラロは、最近のブロックチェーンの動きは「非合理的」な恐怖を呼び起こし、投資家に買い場を提供したと言う。
 JinseFinance
JinseFinance

2022年、私(anna)は、インターネットから公にクロールされたデータではなく、プライベートなデータを使ってトレーニングされるユーザー所有のベースモデルについての提案を書いた。私は、公開データ(例えばウィキペディアや4ちゃんねる)を使ってベースモデルを訓練することは可能だが、それらを次のレベルに引き上げるには、アクセスするための許可やログインが必要な、隔離されたプラットフォーム(例えばツイッター、個人的なメッセージング、企業情報)にのみ存在する高品質のプライベートデータが必要だと主張した。RedditやTwitterのような企業は、自分たちのプラットフォームデータの価値に気づいたため、開発者APIをロックダウンし(1、2)、他の企業がベースモデルを訓練するために自分たちのテキストデータを自由に使えないようにしています。
これは2年前からの大きな変化だ。ベンチャーキャピタリストのサム・レッシンは、この変化を次のように要約している:「(プラットフォームは)すべてのゴミを、無人のまま奥に放り出すだけだ。大量にあるんだ。ゴミ箱に鍵をかけなきゃ」。例えば、GPT-3は、少なくとも3つの好意的な投票(3, 4)を持つすべてのRedditコミットリンクのテキストを集約するWebText2で学習された。Redditの新しいAPIでは、これはもはや不可能です。
インターネットはますます開かれたものではなくなりつつあり、孤立したプラットフォームは貴重なトレーニングデータを守るために大きな壁を築きつつあります。
開発者はもはやこのデータに大規模にアクセスすることはできませんが、データプライバシー規制により、個人はまだプラットフォーム間で自分のデータにアクセスし、エクスポートすることができます(5, 6 )。プラットフォームが開発者向けAPIをロックダウンしている一方で、個人ユーザーはまだ自分のデータにアクセスできるという事実は、1億人のユーザーが自分のプラットフォーム・データをエクスポートして、世界最大のデータの宝庫を作ることができるという機会を提示している。このデータの宝庫は、共有に消極的な大手ハイテク企業やその他の企業が収集したすべてのユーザーデータを集約することになる。それは、今日の主要なベースモデルのトレーニングに使用されているデータセットの100倍もある、これまでに作成された中で最大かつ最も包括的なトレーニングデータセットになるでしょう1
ベースモデルのトレーニングデータセットと例のユーザーデータセットを比較した大まかな推定値。ソースと計算。

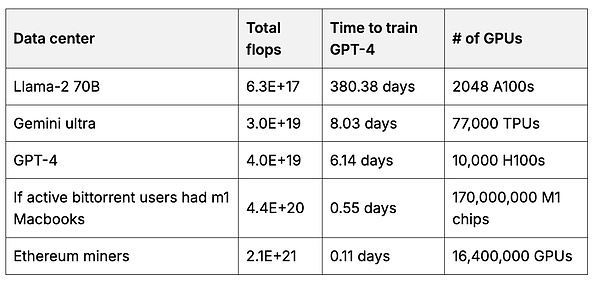
その後、ユーザーは、どのデータセットよりも多くのデータを使用する、ユーザー独自のベースモデルを作成することができます。ベースモデルのトレーニングには、多くのGPU計算が必要です。しかし、各ユーザーは自分のハードウェアを使用して、モデルの小さな部分のトレーニングを支援し、それらの部分をマージして、より大規模で強力なモデルを作成することができます(7、8、9 )2 インセンティブが適切な場合、ユーザーは大量の計算をプールすることができます。例えば、イーサネットの採掘者は、主要な基本モデルを訓練するために使用される総計算量の50倍を持っています。
イーサネットマイナーのGPUと比較した、ベースモデルのトレーニングに使用されたデータセンターで実行された浮動小数点計算の総数(1秒あたりの浮動小数点計算=0.すべてのGPUの「思考」速度の合計)をイーサネットマイナGPUと比較したものです。
モデルに貢献するユーザーは、共同でモデルを所有し、管理します。モデルを管理する。彼らはモデルの使用料を、彼らのデータがどれだけモデルを向上させたかに比例して支払うことができる。その集団は、誰がモデルにアクセスできるか、どのような種類の管理を行うべきかといった使用に関するルールを設定することができる。おそらく各国のユーザーは、それぞれのイデオロギーや文化を代表する独自のモデルを作るだろう。あるいは、1つの国が適切な境界線ではなく、各ネットワーク国がメンバーのデータに基づいた独自の基礎モデルを持つ世界を見ることになるかもしれない。
ベースモデルのどの部分を持ちたいのか、また、使用しているプラットフォームからどのようなトレーニングデータを提供できるのか、時間をかけて考えることをお勧めします。研究論文、未発表のアートワーク、Googleドキュメント、デートプロフィール、医療記録、Slackのメッセージなど、おそらくあなたが思っている以上に多くのデータを持っているはずだ。これらすべてのデータをまとめる方法のひとつが、個人サーバーを利用することで、あなたの個人データをローカルLLMで簡単に利用できるようになります。将来的には、あなたの個人サーバーは、あなたが持っているユーザーベースモデルの一部になるように訓練することもできます。
ベースモデルは、データと計算に大きな先行投資を必要とするため、独占的になりがちです。大手AI企業の残党である数世代遅れたオープンソースのモデルを、できる限り使うという安易な選択肢を選ぶのは簡単だ。しかし、数世代遅れで、ただ残飯を食べることに満足すべきではない!ユーザーとして、私たちは自分たちで最高のモデルを作り上げるべきなのです。
AIが経済的に価値のある仕事をこなせるようになるにつれ、大きな経済的変化が起きている。大手のハイテク企業は、あなたの公的な仕事、文章、アート作品、写真、その他のデータや他人のデータに基づいてAIモデルを訓練し、年間数十億ドルを稼ぎ始めている(1)。彼らは今、あなたが公共のインターネット上でアクセスできないデータを狙っており、Redditのような企業からあなたの個人データを購入することで、AIの収益を年間数兆ドルにまで増やそうとしている(2、3)。
そこでデータDAOの登場です。データDAOは、ユーザーが自分のデータを集約して管理し、特定のデータセットの所有権を表すデータセット固有のトークンで貢献者に報酬を与えることを可能にする分散型エンティティです。データのための組合みたいなものだ。これらのデータセットは、大手テック企業が数億ドルで販売するデータセットを複製し、凌駕することさえできる( 4 )。DAOはデータセットを完全に管理し、貸し出すことも、匿名化したコピーを販売することもできる。例えば、Redditのデータは、友人や過去の投稿など、新しいプラットフォームですぐに利用できるデータを使って、新しいユーザー所有のプラットフォームの種を蒔くために使うこともできる。
技術的な詳細に興味があるなら:データDAOには2つの主要コンポーネントがある:1)データ貢献によってトークンが得られるオンチェーンガバナンス、2)公開鍵と秘密鍵のペアを使用して暗号化された安全なサーバー、コミュニティ所有のデータセットが存在する。貢献するには、まずデータを検証して所有権を証明し、その価値を見積もる。その後、データはブラウザ上でサーバーの公開鍵を使って暗号化され、暗号化されたデータはクラウドに保存される。データはDAOがアクセスを許可する申し出を承認したときにのみ復号化される。例えば、AI企業がモデルを訓練するためにデータを借りることができる。データセットとモデルの集団所有権を可能にするために設計されたVanaネットワークのアーキテクチャについては、こちらで詳細を読むことができる。
データDAOはユーザーに利益をもたらすだけでなく、オープンソースソフトウェアのようにAIを構築することを可能にすることでAIを進歩させ、貢献するすべての人に利益をもたらします。オープンソースのAIは、実行可能なビジネスモデルを見つけるのに苦労している:GPU、データ、研究者に支払う費用は高額だ。さらに、一旦モデルが訓練されると、オープンソースである場合、これらのコストを回収することは不可能である。データDAOの技術的なアーキテクチャはモデルDAOに適用することができ、ユーザーと開発者はモデルの所有権と引き換えに、データ、計算、研究を提供することができます。
現代社会におけるデフォルトの選択肢は、大企業が私たちのデータにアクセスし、それを使って私たちのために働くAIモデルを訓練することだ。私たちが私たちのデータで訓練されたモデルに取って代わられると、彼らはこうしたAIモデルから利益を得る。これは社会にとっては非常に悪いことだが、大手ハイテク企業にとっては良いことだ。これを防ぐ唯一の方法は、集団行動である。データは通貨であり、集合的なデータは力である。ぜひ参加してほしい。レディットのデータに特化した世界初のデータDAOが本日、Vanaネットワーク上で始動した。少数の特権階級が支配するデータの堀を崩すことで、データDAOは真にユーザー所有のインターネットへの道を切り開く。
NYDIGのグレッグ・シポラロは、最近のブロックチェーンの動きは「非合理的」な恐怖を呼び起こし、投資家に買い場を提供したと言う。
JinseFinance台帳ユーザーはソーシャルメディアの検閲に抗議します。
 Beincrypto
BeincryptoRedditは数量限定の無料のラビッツアバターNFTをリリースし、ユーザーはそれらをすくい上げており、すでに複数の種類が枯渇しています。

300 万を超える Reddit Vault ウォレットが作成されました。
Beincryptoマイナーは、その取引の支払いに約 3,000 万 gwei を使用しました。
 Coindesk
Coindesk中国は昨年、仮想通貨の取引とマイニングを禁止した。
CoindeskBeincrypto同社は、このプロジェクトは、分散型取引とサードパーティの販売に Polygon (MATIC) ブロックチェーンを利用するように設定されていると述べました。
 Cointelegraph
Cointelegraph人気のソーシャル メディア プラットフォームである Reddit は、Collectible Avatars と呼ばれる新機能をローンチします。これらのブロックチェーンに裏打ちされたアイテムは、代替不可能なトークン(NFT)です...
 Bitcoinist
Bitcoinistデータによると、Bitcoinマイナーの収益は最近、現在よりも61%少なくなっているため、ストレスにさらされています...
Bitcoinist