
프랑스 암호화폐 마켓 메이커 플로우데스크, 시리즈 B 성공으로 2억 5천만 달러로 기업가치 상승
프랑스의 암호화폐 마켓 메이커인 Flowdesk가 캐세이 이노베이션이 주도한 시리즈 B 라운드에서 2억 5천만 달러의 가치를 인정받았습니다. 글로벌 확장, 규제 준수, 전략적 리더십 변화를 계획하고 있는 Flowdesk는 강력한 성장 지표와 긍정적인 전망으로 반등하는 암호화폐 시장에서 수익을 창출하는 것을 목표로 하고 있습니다.
 Sanya
Sanya

Gerry Wang @ Arweave Oasis 작성, 원래 @ArweaveOasis 트위터에 처음 게시됨
해석 (III) 기사에서 우리는 수학적 추론을 통해 #SPoRes의 실행 가능성을 주장했습니다. 이 기사에서 밥은 앨리스와 함께 이 증명 게임에 참여합니다. 그런 다음 #Arweave 마이닝에서 프로토콜은 이 SPoRes 게임의 수정된 버전을 배포합니다. 채굴 과정에서 프로토콜은 밥의 역할을 하고, 네트워크의 모든 채굴자는 총체적으로 앨리스의 역할을 수행합니다. SPoRes 게임에서 유효한 각각의 증명은 Arweave에서 다음 블록을 생성하는 데 사용됩니다. 구체적으로 Arweave 블록은 다음 매개변수를 사용하여 생성됩니다.
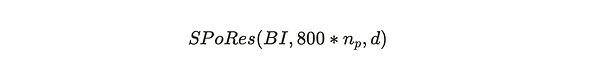
Where:
BI = Arweave 네트워크 블록의 블록 인덱스. Index;
800*n_p = 체크포인트당 파티션당 최대 800개의 잠금 해제 해시, n_p는 채굴자가 저장한 3.6TB 크기의 파티션 수, 이 둘을 곱하면 채굴자가 초당 시도할 수 있는 최대 해시 수.
800*n_p는 채굴자의 해시 해시 수입니다.
d = 네트워크의 난이도.
성공적이고 유효한 증명은 난이도 값보다 큰 것으로, 평균적으로 120초마다 블록이 채굴되도록 시간이 지남에 따라 조정됩니다. 블록 i와 블록 (i+10) 사이의 시간 차이가 t인 경우, 이전 난이도 d_i에서 새로운 난이도 d_{i+10}으로의 조정은 다음과 같이 계산됩니다:
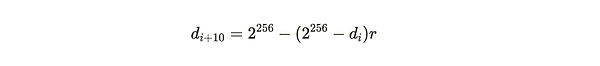
위치:
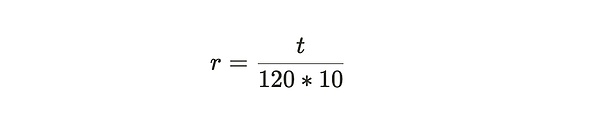
공식 참고: 위의 두 가지로부터 위의 두 공식에서 볼 수 있듯이 네트워크 난이도는 주로 매개 변수 r에 의해 조정되며, 이는 시스템의 예상 표준 시간인 블록당 120초 대비 실제 블록 생성에 필요한 시간에 대한 오프셋 매개 변수를 의미합니다.
새로운 계산의 난이도는 다음과 같이 생성된 각 SPoA 증명에 따라 블록 채굴 성공 확률을 결정합니다.

방정식 참고: 위의 식은 새로운 난이도에서의 채굴 성공 확률을 이전 난이도에서의 성공 확률에 매개변수 r을 곱한 값입니다.
마찬가지로, VDF의 난이도는 초당 1회 발생할 수 있도록 체크포인트 주기를 유지하기 위해 다시 계산됩니다.
완전한 사본에 대한 인센티브
Arweave의 SPoRes 메커니즘을 통한 각 블록 생성은 다음과 같은 가정에 기반합니다.
인센티브가 있다면, 개별 채굴자나 또는 협동 채굴자 그룹은 채굴을 위한 최선의 전략으로 데이터의 전체 사본을 유지하는 것을 실행할 것입니다.
앞서 설명한 SPoRes 게임에서는 저장된 데이터 세트의 동일한 부분에 대한 두 개의 복사본이 저장된 전체 데이터 세트의 전체 복사본과 동일한 수의 SPoA 해시를 방출하므로 채굴자들의 투기적 행동이 발생할 가능성이 열려 있습니다. 그래서 Arweave는 실제로 배포할 때 메커니즘을 일부 수정했으며, 프로토콜은 초당 해제되는 SPoA 챌린지 수를 두 부분으로 나누어 작동합니다.
한 부분은 채굴자의 스토리지에서 특정 수의 SPoA 챌린지를 해제하도록 파티션을 지정하고,
한 부분은 채굴자의 스토리지에서 특정 수의 SPoA 챌린지를 해제하도록 파티션을 지정하고,<...>
다른 부분은 모든 Arweave의 데이터 파티션 중 임의의 파티션을 할당하여 SPoA 챌린지를 해제하고, 채굴자가 이 파티션의 복사본을 저장하지 않으면 이 부분의 챌린지 수를 잃게 됩니다.
SPOA와 SPoRes의 정확한 관계에 대해 다소 혼란스러울 수 있습니다. 합의 메커니즘은 SPoRes인데 왜 공개되는 것은 SPoA의 챌린지인가요? SPoRes는 합의 메커니즘의 포괄적인 용어이며, 여기에는 채굴자가 수행해야 하는 일련의 SPoA 증명 챌린지가 포함되어 있습니다.
이를 이해하기 위해 이전 섹션에서 설명한 VDF가 어떻게 SPoA 챌린지를 해제하는 데 사용되는지 살펴보겠습니다.
이미지 src="https://img.jinse.cn/7202350_image3.png">
위 코드는 특정 수의 SPoA로 구성된 스토리지 파티션의 백트래킹을 해제하는 데 VDF(암호화 시계)를 사용하는 방법을 자세히 보여줍니다. 범위로 구성된 스토리지 파티션의 백트래킹을 해제하는 방법을 자세히 설명합니다.
약 1초마다 VDF 해시 체인은 Check를 출력합니다.
이 Check는 채굴 주소(addr), 파티션의 인덱스(index(p)), 원본 VDF의 시드(VDF 시드)와 함께 채굴 주소(addr), 파티션 인덱스(index(p)), 원본 VDF 시드를 RandomX 알고리즘을 사용하여 256비트 숫자인 해시값 H0을 계산합니다.
C1은 역추적 오프셋으로, H0의 나머지 부분을 파티션의 크기(size(p)로 나눈 값으로 첫 범위의 시작 오프셋이 되며,
이 시작 오프셋에서 체크포인트 Check는 첫 번째 범위의 역추적 체크포인트가 됩니다.
이 시작 오프셋에서 연속된 100MB 범위의 데이터 400개의 256KB 블록이 잠금 해제되는 첫 번째 역방향 범위 SPoA 챌린지입니다.
C2는 두 번째 역방향 범위의 시작 오프셋으로, H0의 나머지 부분을 모든 파티션 크기의 합으로 나눈 값이며, 두 번째 역방향 범위의 400개 SPoA 챌린지도 잠금 해제됩니다.
이러한 챌린지에 대한 제약 조건은 두 번째 범위의 SPoA 챌린지에는 첫 번째 범위의 해당 위치에도 SPoA 챌린지가 있어야 한다는 것입니다.
패킹된 파티션당 성능
패킹된 파티션당 성능은 각 VDF 체크포인트에서 각 파티션이 생성한 SPoA 챌린지 수를 나타냅니다. 채굴자가 동일한 데이터의 여러 백업 복사본을 저장하는 경우보다 파티션의 고유 복제본을 저장하는 경우 SPoA 챌린지 수가 더 많아집니다.
여기서의 "고유 복제본"의 개념은 과거 기사 Arweave 2.6이 다음과 더 부합할 수 있다는 글에서 읽을 수 있듯이 "백업"의 개념과는 매우 다릅니다. 사토시 나카모토의 비전"에서 자세한 내용을 확인할 수 있습니다.
채굴자가 파티션 데이터의 고유한 사본만 저장하는 경우, 패킹된 각 파티션은 첫 번째 역방향 범위 챌린지를 모두 생성한 다음 저장된 파티션의 사본 수에 따라 해당 파티션 내에 속하는 두 번째 역방향 범위를 생성합니다. 전체 Arweave 네트워크에 m개의 파티션이 있고 채굴자가 그 중 n개의 고유한 복사본을 저장하는 경우, 패킹된 각 파티션의 성능은 다음과 같습니다."
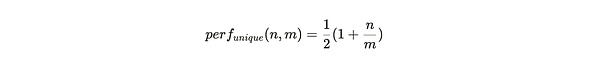
채굴자가 저장한 파티션이 동일한 데이터의 백업인 경우, 각 패킹된 파티션은 여전히 모든 첫 번째 역방향 범위 문제를 생성합니다. 그러나 1/m 배수의 경우에만 두 번째 역방향 범위가 이 파티션 내에 위치하게 됩니다. 그러면 이 스토리지 정책 동작에 상당한 성능 페널티가 부과되며, 생성되는 SPoA 챌린지 수의 비율은 다음과 같습니다.
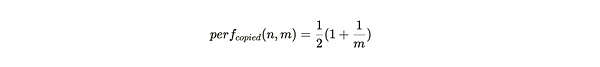

그림 1: 마이너(또는 협력하는 마이너 그룹)가 포장을 완료할 때 데이터 세트의 패킹을 완료하면, 주어진 파티션의 성능이 향상됩니다.
그림 1의 파란색 선은 파티션의 고유 복사본을 저장할 때의 성능 perf_{unique}(n,m)을 보여주며, 마이너가 파티션의 복사본을 아주 적게 저장할 때 파티션당 마이닝 효율은 50%에 불과하다는 것을 시각적으로 보여줍니다. 모든 데이터 세트 부분이 저장되고 유지될 때(즉, n=m) 마이닝 효율은 1로 최대화됩니다.
총 해시율
총 해시율(그림 2에 표시)은 각 파티션(파티션당)의 값에 n을 곱하여 구하는 다음 공식으로 주어집니다:
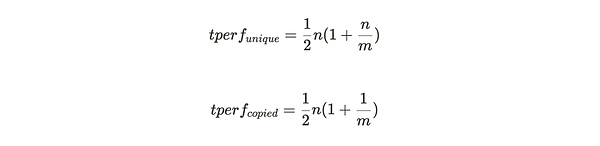
위 방정식은 위브 네트워크의 크기가 커질수록 고유 복사 데이터가 저장되지 않은 경우 저장된 파티션 수에 따라 페널티 함수가 커진다는 것을 보여줍니다. 함수)는 저장 파티션의 수에 따라 4제곱으로 증가합니다.
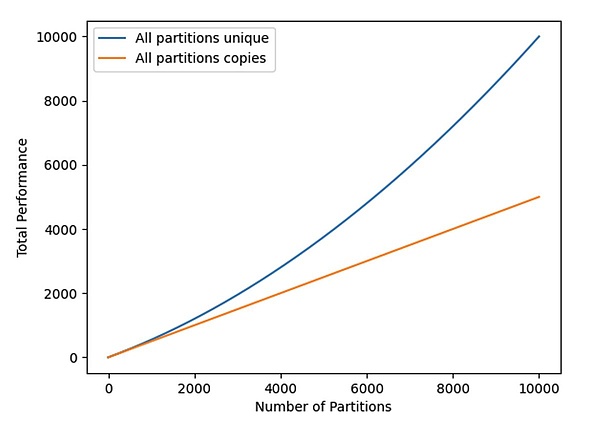
그림 2: 고유 및 백업 데이터 세트의 총 채굴 해시율
한계 파티셔닝 효율성
이 프레임워크를 기반으로 채굴자가 새 파티션을 추가할 때 직면하는 결정 문제, 즉 복제 파티션의 선택에 대해 살펴봅시다. 즉, 이미 가지고 있는 파티션의 복사본을 만들 것인지, 아니면 다른 채굴자로부터 새로운 데이터를 가져와 고유한 복사본에 담을 것인지의 결정 문제입니다. 채굴 해시율은 가능한 최대 M개의 파티션 중 이미 N개의 파티션의 고유 복사본을 저장하고 있을 때 비례합니다:
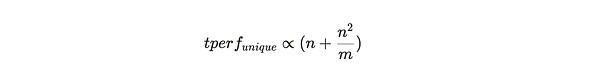
. 따라서 새 파티션의 고유 복사본을 추가할 때의 추가 이점은 다음과 같습니다:
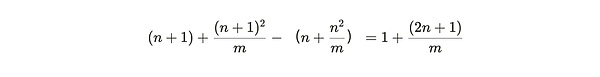
그리고 패킹된 파티션을 복사할 때의 (더 작은) 이점은 다음과 같습니다. >
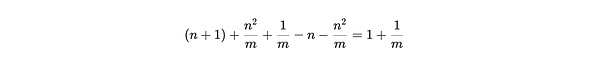
첫 번째 숫자를 두 번째 숫자로 나누면 마이너의 상대적 한계 파티션 효율을 얻을 수 있습니다 :
첫 번째 숫자를 두 번째로 나누면, 마이너의 상대적 한계 파티션 효율을 얻을 수 있습니다. 파티션 효율성)
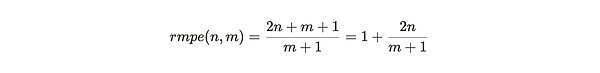
그림 3: 채굴자는 추가 복사본(옵션 2)을 만드는 대신 전체 복사본(옵션 1)까지 만들도록 인센티브를 받습니다.
채굴자가 데이터 세트의 전체 복사본을 거의 다 가지고 있을 때 복사 완료에 대한 보상이 가장 높습니다. 이는 n이 m에 가까워지고 m이 무한대에 가까워지면 rmpe의 값이 3이 되기 때문입니다. 즉, 거의 완전한 사본은 기존 데이터를 다시 패킹하는 것보다 새로운 데이터를 찾는 데 3배 더 효율적이라는 뜻입니다.
예를 들어, 마이너가 위브 네트워크의 절반을 저장할 때(n= 1/2 m), rmpe는 2입니다. 이는 새로운 데이터를 찾는 마이너의 이득이 기존 데이터를 복사하는 것보다 2배 더 크다는 것을 의미합니다.
n의 값이 낮을수록 rmpe 값은 항상 1보다 큰 경향이 있습니다. 이는 고유한 사본을 저장함으로써 얻는 이득이 기존 데이터를 복사함으로써 얻는 이득보다 항상 크다는 것을 의미합니다.
네트워크가 성장함에 따라(m은 무한대가 되는 경향이 있음) 마이너가 전체 사본을 생성하려는 인센티브는 증가합니다. 이로 인해 적어도 하나의 데이터 세트의 완전한 사본을 저장하기 위해 협력하는 협력 마이닝 그룹의 생성이 촉진되었습니다.
이 백서는 물론 이 핵심 섹션의 첫 장에 불과한 Arweave 합의 프로토콜의 구성에 대한 세부 사항에 초점을 맞추고 있습니다. 메커니즘 소개와 코드를 통해 프로토콜의 구체적인 세부 사항을 매우 직관적으로 이해할 수 있습니다. 이해에 도움이 되셨기를 바랍니다.
프랑스의 암호화폐 마켓 메이커인 Flowdesk가 캐세이 이노베이션이 주도한 시리즈 B 라운드에서 2억 5천만 달러의 가치를 인정받았습니다. 글로벌 확장, 규제 준수, 전략적 리더십 변화를 계획하고 있는 Flowdesk는 강력한 성장 지표와 긍정적인 전망으로 반등하는 암호화폐 시장에서 수익을 창출하는 것을 목표로 하고 있습니다.
Sanya퍼플렉시티는 IVP가 주도한 시리즈 B 펀딩에 성공하여 기업가치를 5억 2천만 달러로 평가받았습니다. 퍼플렉시티는 사용자 선택에 대한 독특한 접근 방식과 떠오르는 AI 분야로 두각을 나타내고 있습니다. 하지만 마이크로소프트의 코파일럿과 같은 기존 기술 제품과의 기능적 유사성을 고려할 때 면밀한 검토가 필요합니다.
 Bernice
Bernice Coinlive
Coinlive 查看过去24小时币圈重要新闻。
Coinlive 마이크로스트레티지(MicroStrategy)는 현재 진행 중인 시장 혼란에도 불구하고 가격이 급락하는 동안 추가로 301개의 비트코인을 인수했다고 발표한 후 화요일 헤드라인을 장식했습니다.
 Bitcoinist
Bitcoinist오늘 밤 추천 자료: 1. A16Z: 메타버스 구성을 위한 7가지 기본 요소 2. 뱅크 오브 아메리카: 비트코인은 인플레이션 헤지 역할을 하지 않음 3. 메타버스의 꿈과 현실에 대해 논의하는 10,000단어 길이의 기사.
 Ftftx
FtftxLayer 2 스케일링 솔루션 Optimism은 새로운 개발자를 고용하고 이더리움 네트워크에서 수수료를 줄이는 데 사용할 자금으로 1억 5천만 달러를 확보했습니다.
 Cointelegraph
Cointelegraph채택 및 TVL 측면에서 레이어 2 스케일링 솔루션은 계속해서 큰 폭으로 암호화폐 산업을 주도하고 있습니다.
Cointelegraph2019년 출시 후 Binance.US는 45억 달러의 사전 자금 가치에 도달했으며 48개 주와 8개 지역에서 서비스를 출시했습니다.
Cointelegraph인상은 Avalanche 블록체인에 고정된 총 가치가 약 146억 달러로 안정적으로 유지됨에 따라 이루어집니다.
Cointelegraph