RSS3 is regarded as a promising project in the web3 field. Recently, I have been experiencing web3 applications and trying to find some definition paradigms of the core elements of web3. When I was looking at RSS3, I found a protocol I was looking for. It can be defined as a data specification protocol, the protocol is RFC3986 Uniform Resource Identifier, and it can also be understood as a general grammar.
The original text of the document is more than 3w words, which is not easy to read, so I made a lot of deletions and changes in the document, and made an example to understand the data format of web3.
What you need to know is that this specification is an Internet information standard, and it has been applied for a long time. RSS3 is based on some development practices made on this basis for application in the web3 field.
RSS3
RSS3 is an open information syndication protocol designed to support efficient and decentralized information distribution in Web3. It defines a format for information presentation and communication so that other consumers can easily access various content sources in a unified format without extensive compatibility logic.
In the RSS3 protocol, information is divided into four types: configuration files, links, assets, comments
RSS3 applications use RSS3SDK to access and publish data in the format defined by the RSS3 protocol. RSS3 SDK acquires data from the RSS3 network and publishes the data to the network supported by RSS3. RSS3 Network crawls data from various RSS3 Supported Networks and caches the data to itself In the high-efficiency database, do some preprocessing, such as applying artificial intelligence recommendation algorithms to provide search functions.
In such a product design, the most original data specification is completed by defining some details of the network transmission data. Once the data is defined, the basic data availability part is completed. Upper-layer applications can be implemented more easily. Let's look at this protocol: RFC3986 Uniform Resource Identifier. After deleting and modifying the content, the author strives to meet some relevant requirements for a brief understanding of Internet data processing.
RFC3986: Uniform Resource Identifier
This specification is derived from RFC2396 [RFC2396], RFC1808 [RFC1808], and RFC1738 [RFC1738], and includes updates (and corrections) for IPv6 literals in host syntax.
A Uniform Resource Identifier (URI) is a compact sequence of characters identifying abstract or representing physical resources, providing a simple and extensible method for identifying resources. The specification defines the generic URI syntax and the procedural resolution of URI references in relative forms, as well as guidelines and security considerations for using URIs.
The URI grammar defines a syntactic superset. Effective URIs allow common component parsing, enabling the use of URIs to refer to every possible identifier when not required by a specific scheme. The specification does not define a URI generation grammar.
The Uniform Resource Identifier (URI) semantics are derived from the concept introduced by the World Wide Web Global Information Initiative, and the syntax is designed to meet the requirements of the Resource Locator [RFC1736] and Uniform Resource Name functions listed in the "Internet Functionality Recommendations" [RFC1737] .
This document obsoletes [RFC2396] and merges "Uniform Resource Locators" [RFC1738] and "Relative Uniform Resource Locators" [RFC1808] to define a single common syntax for all URIs. Obsolete [RFC2732], which introduced the syntax for IPv6 addresses.
Features of URIs
Uniformity
It allows different types of resources to use the same resource identifier in the same context, even though the mechanisms used to access those resources may be different.
It allows a unified semantic interpretation of common sentences to complete the agreement across different types of resource identifiers.
It allows new types of resource identifiers to be introduced without interfering with how existing identifiers are used.
It allows identifiers to be reused in many different contexts, allowing new applications or protocols to leverage an existing, large and widely used set of resource identifiers.
resource
The term "resource" refers in a general sense to any content that may be identified by a URI. Familiar examples include electronic documents, images, information sources, services, and other collections of resources. Resources are not necessarily accessible via the Internet. Likewise, abstractions can be resources, such as operators and operands of mathematical equations, types of relationships (eg, "parent" or "employee"), or numeric values (eg, zero, one, infinity).
identifier
Identifiers embody the content authentication process that distinguishes the desired information from all other things within its scope. But these definitions should not be mistaken for definitions of identifiers or embodying the identity of the referenced content. In many cases, URIs are used to indicate resources, but not to indicate that they can be accessed. Likewise, "a" resource identified may not be singular in nature (for example, a resource may be a named set or a mapping over time).
URIs have global scope and are used to interpret the context consistently no matter what, although the results of this interpretation may be relative to the end user's context. For example, "http://localhost/" has the same interpretation for every user referenced, even though the network interface corresponding to "localhost" may be a different user, which means: Interpretation is independent of access.
common grammar
URI syntax is a federated and extensible naming system in which the specification of each scheme can further restrict the syntax and semantics of identifiers using that scheme.
URI references use an independent resolution mechanism by which protocols and data using the format of URI references can define URIs with reference to the full range of syntax allowed by this specification, including those schemes that have not yet been defined.
A parser for the generic URI grammar can parse any URI reference into its principal components. After the plan is determined, further
Scenario-specific parsing can be performed on components. In other words, URI generic syntax is a superset of all URI syntax
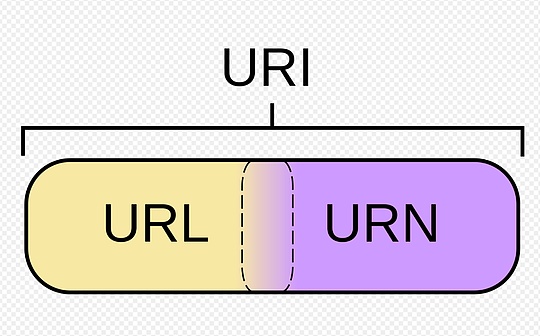
URIs, URLs, and URNs
URIs can be further classified as locators, names, or both.
"Uniform Resource Locator" (URL) refers to a subset of URI. In addition to identifying a resource, it also provides a way to locate a resource by describing its access mechanism (eg, its network "location").
"Uniform Resource Name" (URN) was used to refer to any other URI that remained globally unique even after the resource ceased to exist or became unavailable.
URIs are drawn from a very limited set: Latin letters, numbers, and some special characters.
A URI can be represented in many ways; for example, ink on paper, pixels on a screen, or a sequence of character-encoding octets. The interpretation of a URI depends only on the characters used. In a local or regional environment, as technology advances, users are able to use a wider range of characters.
Separation of recognition and interaction
A common misconception about URIs is that they are only used to refer to accessible resources. The URI itself only provides authentication, and does not guarantee the presence of URI access to resource hints. Instead, any relevant URI references are defined by protocol elements, such as data format attributes or the natural language text in which it appears.
Given a URI, the system may attempt to perform various operations on the resource, perhaps characterized by words such as "access", "update", "replace", or "find a property". Such operations are defined by the protocol using the URI.
hierarchical identifier
The URI syntax is organized hierarchically, with components in descending order of importance from left to right.
Generic syntax uses slash ("/"), question mark ("?"), and number sign ("#") characters to separate components, important to generic parser's hierarchical interpretation, except that readable identifiers of this class are consistent Using a familiar syntax, a unified representation of hierarchies across naming schemes allows scheme-independent references to be made relative to that hierarchy.
Typically, a set or "tree" of documents has been constructed to serve a common purpose, and the vast majority of URI references in these documents point to resources within the tree rather than outside of it. A documentation site at a specific location is more likely to reference other resources on that site than resources at a remote site. References to URIs allow document tree parts to be independent of their location and access scheme.
grammatical symbols
Using the notation of ABNF [RFC2234], including the following core ABNF syntax rules:
ALPHA (letter), CR (carriage return), DIGIT (decimal number), DQUOTE (double quotation mark), HEXDIG (hexadecimal digit), LF (line feed), and SP (space), etc.
URI syntax provides a way to encode data, presumably in order to identify a resource as a sequence of characters. URI characters, in turn, are often encoded into octets for transmission or presentation.
ABNF notation defines its terminal value as a non-negative, integer (code point) based on the US-ASCII coded character set [ASCII]. Because a URI is a sequence of characters, we have to invert that relationship in order to understand URI syntax. Therefore, integer values used by ABNF must be mapped back to US-ASCII counterparts to complete the syntax rules.
reserved characters
A URI consists of "reserved" characters separating components and subcomponents.
The purpose of reserved characters is to provide a set of characters that distinguish delimiters from other data in the URI. A subset (gen-delims) of reserved characters are used as delimiters for generic URI components. ABNF grammar rules for a component do not use reserved or gen-delims directly named, instead, each grammar rule lists the characters allowed within that component (i.e., not delimited), and other subcomponents can be specified by the URI scheme definition.
no reserved characters
Characters that are allowed but not reserved in URIs, including uppercase and lowercase letters, decimal digits, hyphens, periods, underscores, and tildes.
Unreserved=ALPHA/DIGIT/"-"/"."/"_"/"~"
Substitute non-reserved characters for different URIs, but their corresponding percent-encoded US-ASCII octets are equivalent: they identify the same resource. For consistency, percent-encoded octets (%41-%5A and %61-%7A), DIGIT (%30-%39), hyphens (%2D), periods (%2E) in the ALPHA range , URI should not create underscore (%5F) or tilde (%7E) producers, which when found in a URI, should be decoded to the corresponding unreserved characters of the URI normalizer.
identification data
The URI character provides an identifying data component for each URI, as an identified system external interface.
Production and transmission of URIs: local name and data encoding, public interface encoding, URI character encoding, data format encoding, and protocol encoding.
Local names (such as filesystem names) are stored in the local character encoding. URI-generating applications (eg, origin servers) typically use local encodings as the basis for generating meaningful names. The URI producer will convert the local encoding to an encoding suitable for the public interface, and then convert the public interface encoding to the restricted set of URI characters (reserved, unreserved, and percent-encoded).
In turn, these characters are encoded into octets for use as references in data formats such as document character sets, which are often then encoded for transmission over Internet protocols.
In some cases, URI components and identifying the data it represents are much less straightforward than character encoding translations.
grammatical components
The generic URI syntax consists of a hierarchical sequence of scheme, authority, path, query, and fragment.
The scheme and path components are required, although the path may be empty (no characters). When permissions are present, the path must either be empty or start with a slash ("/") character. When permissions are not present, the path must not start with two slash characters ("//"). These restrictions result in five different ABNF path rules, only one of which matches any given URI reference.
plan
Every URI begins with a scheme name that references a specification for assigning identifiers within that scheme.
A scheme name consists of a sequence of characters beginning with a letter, followed by any combination of letters, numbers, and a plus sign ("+"), period ("."), or hyphen ("-").
Scheme=ALPHA*(ALPHA/DIGIT/"+"/"-"/".")
permissions
Many URI schemes include hierarchical element authority for naming, so that management is delegated to that authority by the rest of the URI. The generic syntax provides a generic registry-based name or server address, and optionally port and user information.
The authority component is preceded by a double slash ("//") and is followed by a slash ("/"), question mark ("?"), or end-of-number ("#") character, or at the end of the URI.
permissions = [userinfo "@"]host[":"port]
the host
The host subcomponent of the authority is identified by an IP literal enclosed in square brackets. In many cases, the host syntax is simply used to create and deploy existing registries in DNS, thereby obtaining a globally unique name without the cost of deploying another registry.
host=IP field/IPv4address/reg-name
IP field = "["(IPv6Address/IPvFuture)"]"
IPvFuture="v"1*HEXDIG"."1*(unreserved/sub-separator/":")
Inquire
The query component contains non-hierarchical data, as well as data in the path component that identifies resources within the scope of the URI scheme and naming authority.
Query components are represented by question mark ("?") characters and terminated by number sign ("#") characters.
query=*(pchar/"/"/"?")
usage
When applications refer to a URI, they do not always use the full referencing form defined by the "URI" syntax rules. Conserving space and taking advantage of hierarchical locality, many Internet protocol element and media type formats allow abbreviated URIs, while others restrict the syntax to specific forms of URIs.
Build the base URI
In addition to fragment-only references, base URIs are known to be required. The resolver must establish a base URI. The base URI must conform to the syntax rules of <absolute-URI>.
A base URI can be established in one of four ways
Base URI embedded in content
Encapsulates the base URI of the entity
The URI used to retrieve the entity
Default base URI (depends on application)
Normalize and Compare
The most common operations on URIs are simple comparisons: determining whether two URIs access their respective resources equivalently without using URIs. Extensive normalization is usually done before comparing URIs. URI comparisons are performed for some specific purposes.
equivalence
Because URIs exist to identify resources, they are considered equivalent when they identify the same resource. However, this definition of equivalence is not of much practical use, since there is no way to compare two resources unless one has full knowledge or control over them.
Even if two URIs can be determined to be equivalent, URI comparison is not sufficient to determine that the two URIs identify different resources.
Syntax-based normalization
Syntax-based normalization includes the following techniques case normalization, percent-encoded normalization, and dot segment removal.
Safety Precautions
URIs by themselves do not pose a security threat. But URIs are often used to provide a compact set of instructions to access
For web resources, care must be taken to correctly interpret the data in the URI to prevent that data from being accessed accidentally, and to avoid including data text that should not be made public.
Sensitive information
URI producers should not provide passwords containing usernames or intended to be kept secret. URIs are often displayed by browsers, stored in plaintext bookmarks, and by user agent history and intermediary applications (proxy).
semantic attack
Because the userinfo subcomponent is rarely used, hosts appearing in the authority component can be used to construct a URI that misleads the user to trust, e.g.
ftp://cnn.example.com&[email protected]/top_story.htm
May cause users to assume the host is 'cnn.example.com' when it is actually '10.0.0.1'. A misleading URI can be an attack on the user, which attacks the user's preconceived notions. Regarding the software itself, such attacks can be avoided by differentiating between the individual components of the URI.

 JinseFinance
JinseFinance


