IMF Shifts Stance: Bitcoin is an Important International Financial Tool for "Wealth Preservation"!
The International Monetary Fund has revealed in its latest report that Bitcoin has become an essential financial tool for preserving wealth.
 Miyuki
Miyuki

Source: Machine Heart
After suddenly announcing the end of its cooperation with OpenAI in February, the well-known robotics startup Figure AI disclosed the reason behind it on Thursday night: they have created their own general embodied intelligence model Helix.

Helix is a general vision-language-action (VLA) model that unifies perception, language understanding, and learning control to overcome multiple long-standing challenges in robotics.
Helix has created many firsts:
Full body control: It is the first high-speed continuous control VLA model of the upper body of a humanoid robot in history, covering the wrist, torso, head and individual fingers;
Multi-robot collaboration: Two robots can collaborate with one model to complete unprecedented tasks;
Grasp any object: It can pick up any small object, including thousands of objects they have never encountered before, just by following natural language instructions;
Single neural network: Helix uses a set of neural network weights to learn all behaviors - grab and place objects, use drawers and refrigerators, and interact across robots - without any task-specific fine-tuning;
Localization: Helix is the first robot VLA model in history to run on a local GPU, and it has the ability to be commercialized.
In the field of intelligent driving, this year, all car manufacturers are promoting the large-scale implementation of end-to-end technology. Now that VLA-driven robots have entered the countdown to commercialization, Helix can be regarded as a major breakthrough in embodied intelligence.
A set of Helix neural network weights runs on two robots at the same time, and they work together to store groceries that have never been seen before.
Figure said that the home environment is the biggest challenge facing robotics. Unlike controlled industrial environments, homes are full of countless irregular objects, such as fragile glassware, wrinkled clothes, and scattered toys. The shape, size, color and texture of each item are difficult to predict. In order for robots to play a role in the home, they need to be able to generate new intelligent behaviors on demand.
Current robotics technology cannot be expanded to the home environment - currently, even teaching a robot a single new behavior requires a lot of manpower investment. Either hours of manual programming by PhD-level experts or thousands of demonstrations are required, both of which are prohibitively expensive.
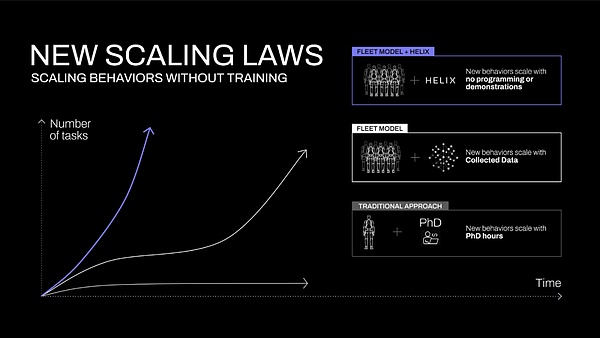
Figure 1: Expansion curves of different methods for acquiring new robot skills. In traditional heuristic operations, skill growth relies on experts manually writing scripts. In traditional robot imitation learning, skill expansion relies on collected data. With Helix, new skills can be specified instantly through language.
Currently, other areas of artificial intelligence have mastered this ability to generalize instantly. If the rich semantic knowledge captured in the visual-language model (VLM) can be simply converted directly into robot actions, a technological breakthrough may be achieved.
This new capability will fundamentally change the expansion trajectory of robotics (Figure 1). The key question then becomes: how do you extract all this commonsense knowledge from the VLM and turn it into generalizable robotic control? Figure built Helix to bridge this gap.
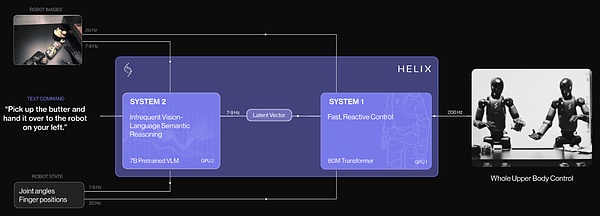
Helix is the first "System 1 + System 2" VLA model in robotics for high-speed, dexterous control of the entire humanoid upper body.
Figure shows that previous approaches face a fundamental trade-off: VLM backbones are general but not fast, while robotic visual-motor policies are fast but not general enough. Helix resolves this tradeoff through two complementary systems that are trained end-to-end to communicate:
System 1 (S1): a fast-acting visuomotor policy that converts latent semantic representations produced by S2 into precise continuous robot actions at 200 Hz;
System 2 (S2): an onboard internet-pretrained VLM running at 7-9 Hz for scene understanding and language understanding, achieving broad generalization across objects and contexts.
This decoupled architecture allows each system to operate at its optimal timescale. S2 can “think slowly” about high-level goals, while S1 can “think fast” about actions that the robot executes and adjusts in real time. For example, in collaborative behavior (see figure below), S1 can quickly adapt to the changing actions of the partner robot while maintaining the semantic goals of S2.
 Helix enables robots to quickly make fine-grained motion adjustments, which are required to respond to collaborative partners when executing new semantic goals.
Helix enables robots to quickly make fine-grained motion adjustments, which are required to respond to collaborative partners when executing new semantic goals.
Helix's design has several key advantages over existing methods:
Speed and generalization: Helix is comparable in speed to behavioral cloning strategies specialized for a single task, while being able to generalize to thousands of new test subjects with zero-shot;
Scalability: Helix directly outputs continuous control in a high-dimensional action space, avoiding the complex action tokenization schemes used in previous VLA methods. These schemes have achieved some success in low-dimensional control settings (such as binary parallel grippers), but face scaling challenges in high-dimensional humanoid control;
Architectural simplicity: Helix uses a standard architecture - an open source, open-weight VLM for System 2, and a simple Transformer-based visual motion policy for System 1;
Separation of concerns: Decoupling S1 and S2 allows us to iterate each system separately without being constrained by finding a unified observation space or action representation.
Figure introduces some model and training details, which collects a high-quality, multi-robot, multi-operator diverse teleoperation behavior dataset totaling about 500 hours. To generate training pairs under natural language conditions, engineers used an automatically annotated visual language model (VLM) to generate post-hoc instructions.
The VLM is fed segmented video clips from the robot’s onboard camera and prompted: “What instructions would you give the robot to make it perform the action it sees in the video?” All items processed during training are excluded from evaluation to prevent data contamination.
The Helix system consists of two main components: S2, a VLM backbone network, and S1, a latent conditional visual motion Transformer.
S2 is built on a 7 billion parameter open-source, open-weight VLM pre-trained on internet-scale data. It processes monocular robot images and robot state information (including wrist pose and finger positions) and projects them into a visual-language embedding space. Combined with natural language instructions specifying the desired behavior, S2 distills all semantic task-relevant information into a continuous latent vector that is passed to S1 to condition its low-level actions.
S1 is an 80 million parameter cross-attention encoder-decoder Transformer responsible for low-level control. It relies on a fully convolutional multi-scale vision backbone network for visual processing, which is initialized with pre-training entirely in simulation. While S1 receives the same image and state inputs as S2, it processes these inputs at a higher frequency for more responsive closed-loop control. The latent vectors from S2 are projected into the label space of S1 and concatenated along the sequence dimension with the visual features extracted by the S1 vision backbone network, providing task conditioning.
When operating, S1 outputs full upper-body humanoid control at a frequency of 200 Hz, including desired wrist pose, finger flexion and abduction control, and trunk and head direction goals. Figure A synthetic "task completion percentage" action is appended to the action space, allowing Helix to predict its own termination condition, making it easier to sequence multiple learned behaviors.
Helix is trained fully end-to-end: mapping from raw pixels and text commands to continuous actions with a standard regression loss.
The back-propagation path of gradients is from S1 to S2 via the implicit communication vectors used to regulate S1’s behavior, allowing the two components to be jointly optimized.
Helix does not need to be tuned for a specific task; it maintains a single training phase and set of neural network weights, without the need for separate action heads or fine-tuning phases for each task.
During training, they also add a time offset between S1 and S2 inputs. This offset is calibrated to match the gap between inference latency for S1 and S2 deployments, ensuring that real-time control requirements during deployment are accurately reflected in training.
Helix’s training design enables efficient parallel deployment of models on Figure robots, each equipped with dual low-power embedded GPUs. The inference pipeline is split into S2 (high-level implicit planning) and S1 (low-level control) models, each running on a dedicated GPU.
S2 runs as an asynchronous background process to process the latest observations (onboard camera and robot state) and natural language commands. It continuously updates a shared memory latent vector that encodes the high-level behavioral intent.
S1 executes as a separate real-time process with the goal of maintaining the critical 200Hz control loop required for smooth execution of full upper body movements. Its inputs are the latest observations and the latest S2 latent vector. Due to the inherent speed difference between S2 and S1 inference, S1 naturally runs at a higher temporal resolution on the robot observations, creating a tighter feedback loop for reactive control.
This deployment strategy intentionally reflects the temporal offset introduced in training, thereby minimizing the training-inference distribution gap. This asynchronous execution model allows both processes to run at their optimal frequencies, allowing Helix to run as fast as the fastest single-task imitation learning policies.
Interestingly, after Figure released Helix, Yanjiang Guo, a doctoral student at Tsinghua University, said that its technical ideas are quite similar to one of their CoRL 2024 papers, which interested readers can also refer to.

Paper address: https://arxiv.org/abs/2410.05273
Fine-grained VLA full upper body control
Helix can coordinate a 35-degree-of-freedom action space at a frequency of 200Hz, controlling everything from single finger movements to end-effector trajectories, head gaze, and torso posture.
Head and torso control presents unique challenges—when the head and torso move, it changes what the robot can reach and what it can see, creating feedback loops that have historically led to instability.
Video 3 demonstrates this coordination in action: the robot smoothly tracks its hands with its head while adjusting its torso for optimal reach while maintaining precise finger control for grasping. Previously, achieving this level of precision in such a high-dimensional action space has been difficult, even for a single, known task. Figure says no previous VLA system has been able to exhibit this degree of real-time coordination while maintaining the ability to generalize across tasks and objects.

Helix’s VLA can control the entire upper body of a humanoid robot, the first model in the field of robot learning to do so.
Zero-Shot Multi-Robot Collaboration
Figure said they pushed Helix to its limits in a challenging multi-agent manipulation scenario: two Figure robots collaborated to perform zero-shot grocery storage.
Video 1 shows two fundamental advances: Both robots successfully manipulated novel cargo (items never encountered during training), demonstrating robust generalization to a wide range of shapes, sizes, and materials.
In addition, both robots operated using the same Helix model weights, requiring no robot-specific training or explicit role assignments. Their collaboration was enabled by natural language prompts, such as "pass the bag of cookies to the robot on your right" or "take the bag of cookies from the robot on your left and place it in the open drawer" (see Video 4). This is the first time that flexible, scalable collaborative manipulation between multiple robots has been demonstrated using VLA. This achievement is particularly remarkable considering that they successfully handled completely new objects.

Helix enables precise multi-robot collaboration
Emerging “pick up anything” capabilities


With just a “pick up [X]” command, the Figure robot equipped with Helix can pick up virtually any small household object. In systematic testing, without any prior demonstration or custom programming, the robot successfully handled thousands of new objects in a cluttered environment—from glassware and toys to tools and clothing.
Of particular note, Helix can make the connection between internet-scale language understanding and precise robotic control. For example, when prompted to “pick up a desert object,” Helix not only determines that a toy cactus matches this abstract concept, but also selects the nearest hand and can safely pick it up with precise motion commands.
“This general “language-to-action” grasping capability opens up exciting new possibilities for deploying humanoid robots in unstructured environments,” Figure said.

Helix can translate high-level instructions such as “pick up [X]” into low-level actions.
Helix is highly efficient to train
Helix achieves strong object generalization with very few resources. Figure says, “We trained Helix using a total of ~500 hours of high-quality supervised data, which is only a small fraction (<5%) of previously collected VLA datasets and does not rely on multi-robot embodied collection or multiple training epochs.” They note that this collection size is closer to modern single-task imitation learning datasets. Despite the relatively small data requirements, Helix can scale to more challenging action spaces, namely full upper-body humanoid control, with high-rate, high-dimensional outputs.
Single Set of Weights
Existing VLA systems typically require specialized fine-tuning or dedicated action heads to optimize performance for executing different high-level behaviors. Remarkably, Helix can perform actions such as picking and placing items in various containers, operating drawers and refrigerators, coordinating dexterous multi-robot handoffs, and manipulating thousands of novel objects using only one set of neural network weights (7B for System 2 and 80M for System 1).

"Pick up Helix" (Helix means spiral)
Helix is the first "vision-language-action" model to directly control the entire upper body of a humanoid robot through natural language. Unlike earlier robotic systems, Helix is able to instantly generate long-view, collaborative, dexterous manipulation without any task-specific demonstrations or extensive manual programming.
Helix demonstrates strong object generalization, being able to pick up thousands of novel household items of varying shapes, sizes, colors, and material properties that it had never encountered during training, simply using natural language commands. The company said: "This represents a transformative step for Figure in expanding the behavior of humanoid robots - a step we believe will be critical as our robots increasingly assist in everyday home environments."
While these early results are indeed exciting, overall, what we have seen above are still proofs of concept and just show the possibilities. The real change will happen when Helix can be actually deployed on a large scale. Look forward to that day coming soon!
Finally, by the way, the release of Figure may be just a small step in the many breakthroughs in embodied intelligence this year. Early this morning, 1X Robot also officially announced the upcoming launch of new products.
The International Monetary Fund has revealed in its latest report that Bitcoin has become an essential financial tool for preserving wealth.
MiyukiChina and Russia have almost entirely abandoned the US dollar in all bilateral trade, paving a profitable path for the yuan.
 Weiliang
WeiliangTether announces the integration of its USDT into Telegram's TON network; Apple's App Store in China has removed the app.
 Brian
BrianInvestors have waited 10 years for the now-bankrupt cryptocurrency exchange Mt. Gox to announce that it will repay creditors nearly $9.5 billion in Bitcoin by this October, which could put short-term selling pressure on Bitcoin.
 Weatherly
WeatherlyCosmos swiftly addressed a critical vulnerability in its IBC protocol, averting a potential theft of over $126 million across multiple blockchain ecosystems.
 Alex
AlexGrayscale and BlackRock refine their Ethereum ETF proposals, facing regulatory delays and low approval expectations, with decisions expected in May.
MiyukiIndividuals engaging in airdrop squatting are fabricating accounts across platforms with the sole intent of harvesting airdrop tokens, potentially depriving genuine users of their fair share.
 Catherine
CatherineTigran Gambaryan, a Binance executive, faces prolonged detention in Nigeria due to postponed bail hearing and impending trial on money laundering charges. His family and experts argue he's being unfairly targeted, potentially as a scapegoat for Nigeria's economic struggles, while Binance's compliance practices are under scrutiny.
 Anais
AnaisChinese unicorn Hashkey Capital, in collaboration with Bosera Funds, announces the trading commencement of their Bitcoin and Ethereum spot ETFs on April 30.
WeiliangSince adopting crypto donations, two out of the three leading charities based in the US have amassed over $2 billion in contributions since the beginning of the year.
 Kikyo
Kikyo