DeepSeek's frequent replies of "Server busy, please try again later" are driving users everywhere crazy.
DeepSeek, which was not well known to the public before, became famous for launching the language model V3 that competes with GPT 4o on December 26, 2024. On January 20, DeepSeek released the language model R1 that competes with OpenAI o1. Later, because of the high quality of the answers generated by the "deep thinking" mode and its innovations that revealed positive signals that the initial cost of model training may drop sharply, the company and the application completely became popular. After that, DeepSeek R1 has been experiencing congestion, its online search function has been intermittently paralyzed, and the deep thinking mode has frequently prompted "server busy", which has troubled a large number of users.
More than a dozen days ago, DeepSeek began to experience server outages. At noon on January 27, DeepSeek's official website had displayed "deepseek webpage/api is unavailable" several times. On that day, DeepSeek became the most downloaded iPhone app during the weekend, surpassing ChatGPT in the US download list.
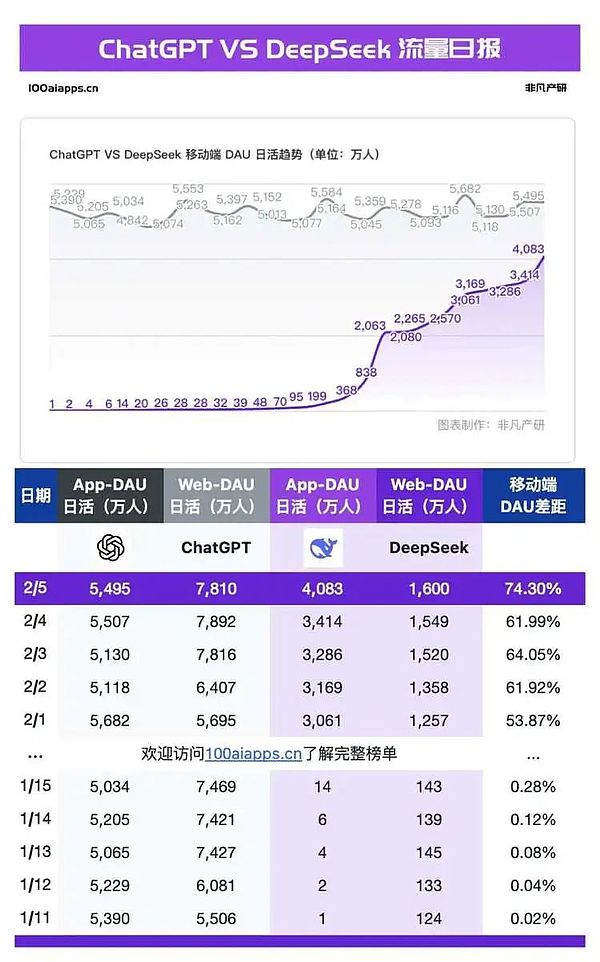
On February 5, DeepSeek's mobile terminal was online for 26 days, with daily active users exceeding 40 million. ChatGPT's mobile terminal had daily active users of 54.95 million, and DeepSeek accounted for 74.3% of ChatGPT. Almost at the same time when DeepSeek stepped out of the steep growth curve, complaints about its busy servers came one after another. Users all over the world began to encounter the inconvenience of downtime after asking a few questions. Various alternative access methods also began to appear, such as DeepSeek's alternative website. Major cloud service providers, chip manufacturers and infrastructure companies have all gone online, and personal deployment tutorials are everywhere. But people's madness has not eased: almost all major manufacturers in the world claim to support the deployment of DeepSeek, but users everywhere are still complaining about the instability of the service.
What happened behind this?
1.People who are used to ChatGPT can't stand DeepSeek that can't be opened
People's dissatisfaction with "DeepSeek's busy server" comes from the fact that the top AI applications that were mainly based on ChatGPT rarely had freezes.
Since the launch of OpenAI services, ChatGPT has experienced several P0-level (the most serious accident level) outages, but overall, it is relatively reliable, has found a balance between innovation and stability, and has gradually become a key component similar to traditional cloud services.
ChatGPT's large-scale downtime is not too frequent
ChatGPT's reasoning process is relatively stable, including two steps: encoding and decoding. The encoding stage converts the input text into a vector, which contains the semantic information of the input text. In the decoding stage, ChatGPT uses the previously generated text as context and generates the next word or phrase through the Transformer model until a complete sentence that meets the requirements is generated. The large model itself belongs to the Decoder architecture. The decoding stage is the output process of tokens (the smallest unit when the large model processes text). Each time a question is asked to ChatGPT, an inference process is started.
For example, if you ask ChatGPT, "How are you feeling today?", ChatGPT will encode this sentence, generate attention representations for each layer, and predict the first output token "I" based on the attention representations of all previous tokens. Then it will decode and splice "I" to "How are you feeling today?", and then get "How are you feeling today? I", get a new attention representation, and then predict the next token: "的", and then follow the first and second steps to loop, and finally get "How are you feeling today? I'm in a good mood."
Kubernetes, the tool for orchestrating containers, is the "behind-the-scenes commander" of ChatGPT, which is responsible for scheduling and allocating server resources. When the influx of users completely exceeds the capacity of the Kubernetes control plane, it will cause the ChatGPT system to be completely paralyzed.
The total number of times ChatGPT has been paralyzed is not too many, but behind this is the powerful resources it relies on as support, and the powerful computing power behind maintaining stable operation is what people ignore.
In general, since the scale of data processed by inference is often small, the computing power requirements are not as high as those for training. Some industry insiders estimate that in the normal large model reasoning process, the main weight of the model parameters occupied by the video memory accounts for the majority, accounting for more than 80%. The reality is that among the multiple models built into ChatGPT, the default model size is smaller than the 671B of DeepSeek-R1. In addition, ChatGPT has much more GPU computing power than DeepSeek, so it naturally shows a more stable performance than DS-R1.
DeepSeek-V3 and R1 are both 671B models. The model startup process is the reasoning process. The computing power reserve during reasoning needs to be matched with the number of users. For example, if there are 100 million users, it is necessary to equip the graphics card with 100 million users. It is not only huge, but also independent of the computing power reserve during training and has nothing to do with it. Judging from information from all sides, the graphics card and computing power reserve of DS are obviously insufficient, so it frequently freezes.
This comparison makes users who are accustomed to the smooth experience of ChatGPT unaccustomed, especially when their interest in R1 is growing.
2.Stuck, stuck, and stuck
Moreover, a careful comparison shows that the situations encountered by OpenAI and DeepSeek are very different.
The former is backed by Microsoft. As OpenAI's exclusive platform, Microsoft Azure cloud service is equipped with ChatGPT, Dalle-E 2 image generator, and GitHub Copilot automatic encoding tool. Since then, this combination has become a classic paradigm of cloud + AI and has quickly become the industry standard; although the latter is a startup, it relies on self-built data centers in most cases, similar to Google, and does not rely on third-party cloud computing providers. After consulting public information, Silicon Stars found that DeepSeek has not started cooperation with cloud vendors and chip manufacturers at any level (although cloud vendors announced during the Spring Festival that they would let DeepSeek models run on them, they did not carry out any real cooperation).
Moreover, DeepSeek has encountered unprecedented user growth, which means that it has less time to prepare for stressful situations than ChatGPT.
DeepSeek's good performance comes from its overall optimization at the hardware and system levels. DeepSeek's parent company, Magic Square Quant, spent 200 million to build the Firefly No. 1 supercomputing cluster as early as 2019, and quietly stored tens of thousands of A100 graphics cards in 2022. In order to train more efficiently in parallel, DeepSeek developed its own HAI LLM training framework. The industry believes that the Firefly cluster may use thousands to tens of thousands of high-performance GPUs (such as NVIDIA A100/H100 or domestic chips) to provide powerful parallel computing capabilities. At present, the Firefly cluster supports the training of models such as DeepSeek-R1 and DeepSeek-MoE, which perform close to the level of GPT-4 in complex tasks such as mathematics and code.
The Firefly cluster represents DeepSeek's exploration of new architectures and methods, and it also makes the outside world believe that through such innovative technologies, DS has reduced the cost of training and can train R1 with performance comparable to that of top AI models with only a fraction of the computing power of the most advanced Western models. SemiAnalysis calculated that DeepSeek actually has a huge reserve of computing power: DeepSeek has a total of 60,000 NVIDIA GPU cards, including 10,000 A100s, 10,000 H100s, 10,000 "special edition" H800s, and 30,000 "special edition" H20s.
This seems to mean that R1 has a sufficient number of cards. But in fact, as an inference model, R1 is benchmarked against OpenAI's O3. This type of inference model requires more computing power to be deployed for the response link, but it is not clear whether the computing power saved by DS on the training cost side is higher or lower than the computing power that suddenly increases on the inference cost side.
It is worth mentioning that DeepSeek-V3 and DeepSeek-R1 are both large language models, but they operate differently. DeepSeek-V3 is an instruction model, similar to ChatGPT, which receives prompt words and generates corresponding text for reply. However, DeepSeek-R1 is a reasoning model. When users ask questions to R1, it will first perform a large number of reasoning processes before generating the final answer. The tokens generated by R1 first appear with a large number of thought chain processes. Before generating answers, the model will first explain and decompose the questions. All these reasoning processes will be quickly generated in the form of tokens.
In the view of Wen Tingcan, vice president of Yaotu Capital, the aforementioned huge computing power reserve of DeepSeek refers to the training phase. The computing power team can plan and predict during the training phase, and it is not easy to have insufficient computing power. However, the inference computing power is more uncertain because it mainly depends on the user scale and usage, and is relatively flexible. "The inference computing power will grow according to a certain rule, but as DeepSeek has become a phenomenal product, the user scale and usage have exploded in a short period of time, which has led to an explosive growth in the demand for computing power in the inference phase, so there is jamming."
Gui Zang, an active model product designer and independent developer on Jike, agrees that the jamming is the main reason for DeepSeek's jamming. He believes that as the mobile application with the highest download volume in 140 markets around the world, DS cannot be sustained by the current cards anyway, even with new cards, because "it takes time to build a cloud with new cards."
"The cost of running Nvidia A100, H100 and other chips for one hour has a fair market price. From the perspective of the inference cost of outputting tokens, DeepSeek is more than 90% cheaper than OpenAI's similar model o1. This is not much different from everyone's calculations. Therefore, the model architecture MOE itself is not the main problem, but the number of GPUs owned by DS determines the maximum number of tokens they can produce and provide per minute. Even if more GPUs can be used for inference service users instead of pre-training research, the upper limit is there." Chen Yunfei, the developer of AI native application Kitten Fill Light, holds a similar view.
Some industry insiders also mentioned to Silicon Star that the essence of DeepSeek's jamming is that the private cloud is not well done.
Hacker attacks are another driving factor for R1 jamming. On January 30, the media learned from the network security company Qi'anxin that the intensity of attacks on DeepSeek's online services suddenly escalated, and its attack instructions increased by hundreds of times compared with January 28. Qi'anxin Xlab Laboratory observed that at least two botnets participated in the attack.
However, there is a seemingly obvious solution to the lag of R1's own services, which is third-party service provision. This is also the most lively scene we witnessed during the Spring Festival - various manufacturers have deployed services to meet people's demand for DeepSeek.
On January 31, NVIDIA announced that NVIDIA NIM can already use DeepSeek-R1. Previously, NVIDIA's market value evaporated by nearly $600 billion overnight due to the impact of DeepSeek. On the same day, users of Amazon Cloud AWS can deploy DeepSeek's latest R1 basic model in its artificial intelligence platform, Amazon Bedrock and Amazon SageMaker AI. Subsequently, new AI applications including Perplexity and Cursor also connected to DeepSeek in batches. Microsoft was the first to deploy DeepSeek-R1 on cloud services Azure and Github before Amazon and NVIDIA.
Starting from February 1, the fourth day of the Chinese New Year, Huawei Cloud, Alibaba Cloud, Bytedance's Volcano Engine and Tencent Cloud also joined in. They generally provide DeepSeek full-series, full-size model deployment services. Then came AI chip manufacturers such as BiRen Technology, Hanbo Semiconductor, Ascend, and Muxi, who claimed to have adapted the original version of DeepSeek or a smaller distilled version. As for software companies, UFIDA, Kingdee, etc. have connected DeepSeek models to some of their products to enhance product strength. Finally, terminal manufacturers such as Lenovo, Huawei, and Honor have connected some products to DeepSeek models for use as end-side personal assistants and car smart cockpits.
So far, DeepSeek has attracted a comprehensive and huge circle of friends by relying on its own value, including cloud vendors, operators, securities companies, and national-level platforms such as the National Supercomputing Internet Platform at home and abroad. Since DeepSeek-R1 is a completely open source model, the service providers who have connected to it have become the beneficiaries of the DS model. This has greatly raised the voice of DS, but it has also caused more frequent freezes. Service providers and DS itself are increasingly trapped by the influx of users, and have not found the key trick to solve the problem of stable use.
Considering that the original versions of DeepSeek V3 and R1 models have up to 671 billion parameters, they are suitable for running on the cloud. Cloud vendors themselves have more sufficient computing power and reasoning capabilities. They launched DeepSeek-related deployment services to lower the threshold for enterprise use. After deploying the DeepSeek model, they provide the DS model API to the outside world. Compared with the API provided by DS itself, it is believed that it can provide a better user experience than the official DS.
But in reality, the experience problem of the DeepSeek-R1 model itself has not been solved in various services. The outside world believes that service providers are not short of cards, but in fact, the feedback from developers on the unstable experience of the R1 they deployed is exactly the same as that of R1. This is more because the number of cards that can be allocated to R1 for reasoning is not too much.
"R1 remains popular, and service providers need to take into account other models that can be connected. The cards that can be provided to R1 are very limited, and R1 is very popular. Once anyone launches R1 and offers it at a relatively low price, it will be overwhelmed." Gui Zang, a model product designer and independent developer, explained the reason to Silicon Star.
Model deployment optimization is a broad field that covers many links, from training completion to actual hardware deployment, involving multi-level work, but for DeepSeek's jamming incident, the reason may be simpler, such as too large a model and insufficient optimization preparation before going online.
Before a popular large model goes online, it will encounter multiple challenges involving technology, engineering, and business, such as the consistency of training data and production environment data, data latency and real-time performance affecting model reasoning effects, online reasoning efficiency and resource usage are too high, model generalization capabilities are insufficient, and engineering aspects such as service stability, API and system integration.
Many popular large models attach great importance to inference optimization before going online. This is because of the time-consuming calculation and memory problems. The former refers to the long inference delay, resulting in poor user experience, and even failing to meet the delay requirements, that is, jamming and other phenomena. The latter refers to the large number of model parameters, which consumes video memory, and even a single GPU card cannot fit, which will also cause jamming.
Wen Tingcan explained the reason to Silicon Star. He said that service providers encountered challenges in providing R1 services. The essence is that the DS model structure is special, the model is too large + MOE (mixed structure of experts, a way of efficient computing) architecture, "(Service providers) optimization takes time, but the market heat has a time window, so they are all launched first and then optimized, rather than fully optimized and then launched."
For R1 to run stably, the core now lies in the reserve and optimization capabilities on the inference side. What DeepSeek needs to do is to find a way to reduce the cost of inference, the output of the card, and the number of tokens output at a single time.
At the same time, the lag also shows that DS's own computing power reserves are probably not as large as SemiAnalysis said. Magic Square Fund Company needs cards, and DeepSeek's training team also needs cards. There are not many cards that can be allocated to users. According to the current development situation, DeepSeek may not have the motivation to spend money to rent services in the short term, and then provide users with a better experience for free. They are more likely to wait until the first wave of C-end business models are sorted out before considering the issue of service leasing. This also means that the lag will continue for a long time.
"They probably need two steps: 1) to create a payment mechanism to limit the use of free user models; 2) to find cloud service providers to cooperate and use other people's GPU resources." The temporary solution given by developer Chen Yunfei is quite a consensus in the industry.
But at present, DeepSeek does not seem to be too anxious about its "busy server" problem. As a company pursuing AGI, DeepSeek does not seem to be too focused on the influx of user traffic. Maybe users will still have to get used to facing the "busy server" interface in the future.
Preview
Gain a broader understanding of the crypto industry through informative reports, and engage in in-depth discussions with other like-minded authors and readers. You are welcome to join us in our growing Coinlive community:https://t.me/CoinliveSG



 JinseFinance
JinseFinance



