Huang Renxun's trillion-dollar AI empire: written before Nvidia's market value surpassed Apple
This Monday, Nvidia's stock price hit a new record high, with a market value of over $3.5 trillion, approaching the world's number one Apple.
 JinseFinance
JinseFinance

Source: Tencent Technology
Nvidia co-founder and CEO Huang Renxun delivered a keynote speech at Computex 2024 (2024 Taipei International Computer Show), sharing how the era of artificial intelligence will promote the global new industrial revolution.
The following are the key points of this speech:
① Huang Renxun demonstrated the latest mass-produced version of the Blackwell chip, and said that the Blackwell Ultra AI chip will be launched in 2025. The next-generation AI platform will be named Rubin, and Rubin Ultra will be launched in 2027. The update rhythm will be "once a year", breaking "Moore's Law".
② Huang Renxun claimed that Nvidia promoted the birth of large language models. It changed the GPU architecture after 2012 and integrated all new technologies on a single computer.
③ Nvidia's accelerated computing technology helped achieve a 100-fold rate increase, while power consumption only increased to 3 times the original and the cost was 1.5 times the original.
④ Huang Renxun expects that the next generation of AI will need to understand the physical world. The method he gave is to let AI learn through videos and synthetic data, and let AI learn from each other.
⑤ Huang Renxun even finalized a Chinese translation for token in the PPT - word yuan.
⑥ Huang Renxun said that the era of robots has arrived, and all moving objects will be able to operate autonomously in the future.

The following is the full text of the two-hour speech compiled by Tencent Technology:
Dear guests, I am very honored to be here again. First of all, I would like to thank National Taiwan University for providing us with this gymnasium as a venue for the event. The last time I came here was when I received my degree from National Taiwan University. Today, we are about to discuss a lot of content, so I must speed up and convey the information in a fast and clear way. We have a lot to talk about, and I have a lot of exciting stories to share with you.
I am very happy to be in Taiwan, China, where we have so many partners. In fact, this place is not only an integral part of NVIDIA's development, but also a key node in our cooperation with partners to bring innovation to the world. We have built AI infrastructure on a global scale with many partners. Today, I want to discuss several key topics with you:
1) What progress are we making together and what does this progress mean?
2) What exactly is generative AI? How will it affect our industry and even every industry?
3) A blueprint for how we move forward and how we will seize this incredible opportunity?
What will happen next? Generative AI and its profound impact, our strategic blueprint, these are all exciting topics we will discuss. We are at the starting point of the restart of the computer industry, a new era forged and created by you is about to begin. Now, you are ready for the next important journey.
But before we get into that, I want to emphasize that NVIDIA sits at the intersection of computer graphics, simulation, and artificial intelligence, which is the soul of our company. Everything I'm going to show you today is based on simulation. These are not just visual effects, but behind them is the essence of mathematics, science, and computer science, as well as amazing computer architecture. None of the animations are pre-made, everything is the masterpiece of our own team. This is NVIDIA's understanding, and we put it all into the Omniverse virtual world that we are so proud of. Now, please enjoy the video!
The power consumption of data centers around the world is rising sharply, and the cost of computing is also rising. We are facing a severe challenge of computing expansion, which is obviously unsustainable in the long run. Data will continue to grow exponentially, while CPU performance will not scale as fast as before. However, a more efficient way is emerging.
For nearly two decades, we have been committed to the research of accelerated computing. CUDA technology enhances the capabilities of the CPU, offloading and accelerating tasks that special processors can complete more efficiently. In fact, as CPU performance expansion slows or even stagnates, the advantages of accelerated computing are becoming more and more obvious. I predict that every processing-intensive application will be accelerated, and in the near future, every data center will be fully accelerated.

It has now become an industry consensus that choosing accelerated computing is a wise move. Imagine that an application requires 100 time units to complete. Whether it is 100 seconds or 100 hours, we often cannot afford to run AI applications for days or even months.
Of these 100 time units, 1 time unit involves code that needs to be executed sequentially, and the importance of single-threaded CPUs is self-evident. The control logic of the operating system is indispensable and must be executed strictly according to the instruction sequence. However, there are many algorithms, such as computer graphics, image processing, physics simulation, combinatorial optimization, graph processing, and database processing, especially linear algebra, which is widely used in deep learning, which are very suitable for acceleration through parallel processing. To achieve this goal, we invented an innovative architecture that perfectly combines GPU and CPU.
The dedicated processor can accelerate the original time-consuming tasks to incredible speeds. Because the two processors can work in parallel, they operate independently and autonomously. This means that a task that originally took 100 time units to complete may now be completed in only 1 time unit. Although this acceleration effect sounds incredible, today I will verify this statement through a series of examples.

The benefits of this performance improvement are amazing, 100 times faster, while the power only increases by about 3 times, and the cost only increases by about 50%. We have long practiced this strategy in the PC industry. Adding a $500 GeForce GPU to a PC can dramatically increase its performance while increasing its overall value to $1,000. We’ve taken the same approach in the data center. A billion-dollar data center can be transformed into a powerful AI factory by adding a $500 million GPU. This transformation is happening around the world today.
The cost savings are equally astounding. For every dollar invested, you get up to 60x performance improvement. 100x speedup, while only increasing power by 3x and cost by only 1.5x. The savings are real!
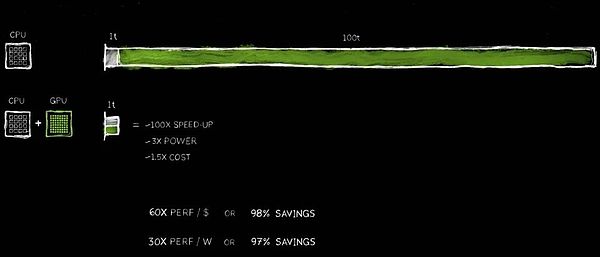
Obviously, many companies spend hundreds of millions of dollars processing data in the cloud. When data is accelerated, it makes sense to save hundreds of millions of dollars. Why is this the case? The simple reason is that we have experienced a long-term efficiency bottleneck in general-purpose computing.
Now, we have finally realized this and decided to accelerate. By using specialized processors, we can recapture a lot of previously overlooked performance gains, saving a lot of money and energy. That’s why I say, the more you buy, the more you save.
Now, I’ve shown you the numbers. They’re not accurate to the decimal point, but they accurately reflect the facts. You can call it “CEO math.” CEO math is not extremely accurate, but the logic behind it is correct - the more accelerated computing power you buy, the more money you save.
The results of accelerated computing are indeed extraordinary, but the implementation process is not easy. Why didn’t people adopt this technology earlier when it can save so much money? The reason is that it is too difficult to implement.
There is no off-the-shelf software that can simply be run through an accelerated compiler and the application will suddenly be 100 times faster. It is neither logical nor realistic. If it were that easy, the CPU manufacturers would have done it long ago.
In fact, to achieve acceleration, the software must be completely rewritten. This is the most challenging part of the whole process. The software needs to be redesigned and recoded to convert the algorithms that originally ran on the CPU into a format that can run in parallel on the accelerator.
This computer science research is difficult, but we have made significant progress in the past 20 years. For example, we launched the popular cuDNN deep learning library, which specifically deals with neural network acceleration. We also provide a library for AI physics simulation, which is suitable for applications such as fluid dynamics that need to obey the laws of physics. In addition, we have a new library called Aerial, which uses CUDA to accelerate 5G radio technology, allowing us to define and accelerate telecommunications networks with software in the same way that software defines Internet networks.

These acceleration capabilities not only improve performance, but also help us transform the entire telecommunications industry into a computing platform similar to cloud computing. In addition, the Coolitho computational lithography platform is also a good example, which greatly improves the efficiency of mask making, the most computationally intensive part of the chip manufacturing process. Companies such as TSMC have already started using Coolitho for production, achieving significant energy savings and cost reductions. Their goal is to accelerate the technology stack to prepare for the further development of algorithms and the massive computing power required to manufacture deeper and narrower transistors.
Pair of Bricks is our proud gene sequencing library, which has the world's leading gene sequencing throughput. Co OPT is an impressive combinatorial optimization library that can solve complex problems such as route planning, optimizing itineraries, and travel agency problems. It is generally believed that these problems require quantum computers to solve, but we have created an extremely fast algorithm through accelerated computing technology, successfully breaking 23 world records, and we still hold every major world record to this day.
Coup Quantum is a quantum computer simulation system we developed. For researchers who want to design quantum computers or quantum algorithms, a reliable simulator is essential. In the absence of actual quantum computers, NVIDIA CUDA - what we call the world's fastest computer - has become their tool of choice. We provide a simulator that can simulate the operation of quantum computers to help researchers make breakthroughs in the field of quantum computing. This simulator has been widely used by hundreds of thousands of researchers around the world and has been integrated into all leading quantum computing frameworks, providing strong support for scientific supercomputer centers around the world.
In addition, we have launched Kudieff, a data processing library specifically designed to accelerate data processing. Data processing accounts for the vast majority of today's cloud spending, so accelerating data processing is critical to saving costs. QDF is an acceleration tool we developed that can significantly improve the performance of the world's major data processing libraries, such as Spark, Pandas, Polar, and graph processing databases such as NetworkX.
These libraries are key components in the ecosystem that enable the widespread use of accelerated computing. Without our carefully crafted domain-specific libraries such as cuDNN, deep learning scientists around the world may not be able to fully utilize the potential of CUDA alone, because there are significant differences between CUDA and the algorithms used in deep learning frameworks such as TensorFlow and PyTorch. This is just as impractical as designing computer graphics without OpenGL or doing data processing without SQL.
These domain-specific libraries are the treasure of our company, and we currently have more than 350 such libraries. It is these libraries that keep us open and ahead in the market. Today, I will show you more exciting examples.
Just last week, Google announced that they have deployed QDF in the cloud and successfully accelerated Pandas. Pandas is the world's most popular data science library, used by 10 million data scientists worldwide and downloaded 170 million times per month. It is like Excel for data scientists and a powerful assistant for them to process data.
Now, with just one click on Colab, Google's cloud data center platform, you can experience the powerful performance of Pandas accelerated by QDF. The acceleration effect is really amazing, just like the demonstration you just saw, it completes the data processing task almost instantly.
CUDA has reached a so-called critical point, but the reality is better than this. CUDA has achieved a virtuous cycle of development. Looking back at history and the development of various computing architectures and platforms, we can find that such a cycle is not common. Take the microprocessor CPU, for example. It has been around for 60 years, but the way it accelerates computing has not changed fundamentally over that long period of time.
Creating a new computing platform often faces a "chicken or egg" dilemma. Without developer support, it is difficult for the platform to attract users; without widespread user adoption, it is difficult to form a large installed base to attract developers. This dilemma has plagued the development of multiple computing platforms for the past 20 years.
However, we have successfully broken this dilemma by continuously launching domain-specific libraries and acceleration libraries. Today, we have 5 million developers around the world who use CUDA technology to serve nearly every major industry and scientific field, from healthcare and financial services to the computer industry and the automotive industry.
As our customer base continues to expand, OEMs and cloud service providers have also become interested in our systems, which has further driven more systems to market. This virtuous cycle creates a huge opportunity for us to expand our scale and increase our R&D investment to accelerate more applications.
Every application acceleration means a significant reduction in computing costs. As I showed earlier, a 100x speedup can result in a cost savings of 97.96%, or nearly 98%. As we go from 100x to 200x to 1,000x, the marginal cost of computing continues to fall, showing a remarkable economic benefit.
Of course, we believe that by significantly reducing the cost of computing, the market, developers, scientists, and inventors will continue to find new algorithms that consume more computing resources. At some point, a profound change will quietly occur. When the marginal cost of computing becomes so low, a whole new way of using computers will emerge.
In fact, this change is happening right before our eyes. In the past decade, we have reduced the marginal cost of computing by a staggering 1 million times using certain algorithms. Today, it is no longer a question of logic and choice to use all the data on the Internet to train a large language model.
This idea - to build a computer that can process huge amounts of data to program itself - is the cornerstone of the rise of artificial intelligence. The rise of AI was made possible only by our belief that if we made computing cheaper and cheaper, someone would find a great use for it. Today, the success of CUDA has proven that this virtuous cycle is possible.
As the installed base continues to grow and the cost of computing continues to fall, more and more developers are able to unleash their innovative potential and come up with more ideas and solutions. This innovation drives a surge in market demand. Now we are at a major turning point. However, before I go further, I want to emphasize that what I am about to show you would not be possible without breakthroughs in CUDA and modern AI technology, especially generative AI.
This is Project Earth2 - an ambitious vision to create a digital twin of the Earth. We will simulate the operation of the entire planet to predict its future changes. Through such simulations, we can better prevent disasters and better understand the impacts of climate change, so that we can better adapt to these changes and even start changing our behaviors and habits now.
Project Earth2 is probably one of the most challenging and ambitious projects in the world. We make significant progress in this field every year, but this year's results are particularly outstanding. Now, let me show you some of these exciting developments.
In the not too distant future, we will have continuous weather forecasting capabilities covering every square kilometer on Earth. You will always know how the climate will change, and this forecast will run continuously because we trained the AI, and the energy required for the AI is extremely limited. This will be an incredible achievement. I hope you will like it, but more importantly, this forecast was actually made by Jensen AI, not me. I designed it, but the final forecast was rendered by Jensen AI.
As we strive to continuously improve performance and reduce costs, researchers discovered CUDA in 2012, which was NVIDIA's first contact with artificial intelligence. That day was crucial for us because we made a wise choice and worked closely with scientists to make deep learning possible. The emergence of AlexNet achieved a huge breakthrough in computer vision.
But the more important wisdom is that we took a step back and deeply understood the nature of deep learning. What is its foundation? What is its long-term impact? What was its potential? We realized that this technology had tremendous potential to continue to scale the algorithms invented and discovered decades ago, and with more data, bigger networks, and crucially, more compute resources, deep learning suddenly could do things that human algorithms could not.
Now, imagine what would happen if we scaled up the architecture even further, with bigger networks, more data, and more compute resources? So we set out to reinvent everything. Since 2012, we’ve changed the architecture of the GPU, added tensor cores, invented NV-Link, launched cuDNN, TensorRT, Nickel, acquired Mellanox, and launched the Triton inference server.
All of this technology came together in a completely new computer that was beyond anyone’s imagination at the time. No one expected it, no one asked for it, and no one even understood its full potential. In fact, I wasn’t sure if anyone would want to buy it.
But at GTC, we officially launched the technology. A startup called OpenAI in San Francisco quickly took notice of our work and asked us for a device. I personally delivered the world’s first AI supercomputer, DGX, to OpenAI.
In 2016, we continued to scale up our R&D. From a single AI supercomputer, a single AI application, to an even larger and more powerful supercomputer launched in 2017. As technology continued to advance, the world witnessed the rise of the Transformer. The advent of this model allows us to process massive amounts of data and recognize and learn continuous patterns over long time spans.
Today, we have the ability to train these large language models to achieve major breakthroughs in natural language understanding. But we didn’t stop there, we continued to move forward and built larger models. By November 2022, we were training on extremely powerful AI supercomputers using tens of thousands of NVIDIA GPUs.
Just 5 days later, OpenAI announced that ChatGPT had 1 million users. This amazing growth rate, climbing to 100 million users in just two months, created a record of the fastest growth in the history of applications. The reason is very simple - ChatGPT is easy to use and magical.
Users can interact with the computer naturally and smoothly, just like communicating with real people. Without cumbersome instructions or explicit descriptions, ChatGPT can understand the user's intentions and needs.
The emergence of ChatGPT marks an epoch-making change, and this slide captures this key turning point. Please allow me to show you.
Until the advent of ChatGPT, it truly revealed to the world the unlimited potential of generative artificial intelligence. For a long time, the focus of artificial intelligence has been mainly on the field of perception, such as natural language understanding, computer vision, and speech recognition, which are committed to simulating human perception. But ChatGPT has brought a qualitative leap. It is not limited to perception, but for the first time demonstrated the power of generative artificial intelligence.
It generates tokens one by one, which can be words, images, charts, tables, or even songs, text, voice and video. Tokens can represent anything with a clear meaning, whether it is chemicals, proteins, genes, or the weather patterns we mentioned earlier.
The rise of this generative AI means that we can learn and simulate physical phenomena, allowing AI models to understand and generate various phenomena in the physical world. We are no longer limited to narrowing down the scope for filtering, but exploring infinite possibilities through generative methods.
Today, we can generate tokens for almost anything of value, whether it is the steering wheel control of a car, the joint movement of a robotic arm, or any knowledge we can currently learn. Therefore, we are no longer just in an era of artificial intelligence, but a new era led by generative AI.
What's more, this device, which originally appeared as a supercomputer, has now evolved into a highly efficient AI data center. It continues to produce, not only generating tokens, but also an AI factory that creates value. This AI factory is generating, creating and producing new commodities with huge market potential.
Just as Nikola Tesla invented the AC generator in the late 19th century, bringing us a steady stream of electrons, Nvidia's AI generator is also continuously generating tokens with infinite possibilities. Both have huge market opportunities and are expected to bring about changes in every industry. This is indeed a new industrial revolution!
We now have a new factory that can produce new and valuable goods for all industries that have never been seen before. This method is not only extremely scalable, but also completely repeatable. Note that various AI models, especially generative AI models, are emerging every day. Now, every industry is competing to participate in it, which is unprecedented.
The $3 trillion IT industry is about to produce innovations that can directly serve the $100 trillion industry. It is no longer just a tool for information storage or data processing, but an engine for generating intelligence in every industry. This will become a new type of manufacturing, but it is not traditional computer manufacturing, but a new model of manufacturing using computers. Such a change has never happened before, and it is indeed a remarkable thing.
This has ushered in a new era of computing acceleration, which has promoted the rapid development of artificial intelligence, and has given rise to the rise of generative AI. And now, we are experiencing an industrial revolution. Let's take a deeper look at its impact.
For our industry, the impact of this change is equally profound. As I said before, for the first time in the past sixty years, every layer of computing is changing. From general computing on CPUs to accelerated computing on GPUs, each change marks a leap in technology.
In the past, computers needed to follow instructions to perform operations, but now they are more about processing LLMs (large language models) and artificial intelligence models. The computing model in the past was mainly based on retrieval. Almost every time you use your mobile phone, it will retrieve pre-stored texts, images, or videos for you and reassemble these contents according to the recommendation system to present them to you.
But in the future, your computer will generate as much content as possible and only retrieve necessary information, because generating data consumes less energy when obtaining information. Moreover, the generated data has higher contextual relevance and can more accurately reflect your needs. When you need an answer, you no longer need to explicitly instruct the computer to "get me that information" or "give me that file", just simply say: "Give me an answer."
In addition, computers are no longer just tools we use, they begin to generate skills. It performs tasks, and is no longer an industry that produces software, which was a subversive concept in the early 1990s. Remember, Microsoft revolutionized the PC industry with the idea of software packaging? Without packaged software, our PCs would lose most of their functionality. This innovation drove the entire industry forward.
Now we have a new factory, a new computer, and on top of that runs a new type of software - we call it Nim (NVIDIA Inference Microservices). The Nim running in this new factory is a pre-trained model, it's an AI.

This AI itself is quite complex, but the computing stack that runs AI is incredibly complex. When you use a model like ChatGPT, there is a huge software stack behind it. This stack is complex and large because the model has billions to trillions of parameters and is not just running on one computer, but working together on multiple computers.
To maximize efficiency, the system needs to distribute the workload to multiple GPUs, doing all kinds of parallel processing, such as tensor parallelism, pipeline parallelism, data parallelism, and expert parallelism. This allocation is to ensure that work is completed as quickly as possible, because in a factory, throughput is directly related to revenue, service quality, and the number of customers that can be served. Today, we live in an era where data center throughput utilization is critical.
In the past, throughput was considered important but not a decisive factor. However, now, every parameter, from startup time, running time, utilization, throughput to idle time, is accurately measured because data centers have become real "factories." In this factory, operational efficiency is directly related to the company's financial performance.
Given this complexity, we are well aware of the challenges most companies face when deploying artificial intelligence. Therefore, we have developed an integrated AI container solution that encapsulates AI in a box that is easy to deploy and manage. This box includes a large collection of software such as CUDA, CUDACNN and TensorRT, as well as the Triton inference service. It supports cloud-native environments, allows automatic scaling in Kubernetes (a distributed architecture solution based on container technology) environments, and provides management services to facilitate users to monitor the operating status of AI services.
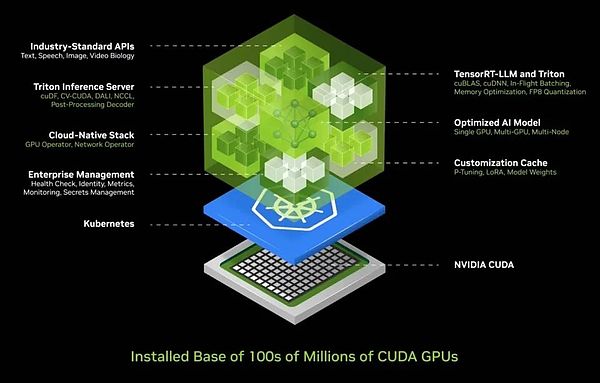
What's even more exciting is that this AI container provides a universal, standard API interface, allowing users to interact directly with the "box". Users only need to download Nim and run it on a CUDA-enabled computer to easily deploy and manage AI services. Today, CUDA is ubiquitous, supporting major cloud service providers, almost all computer manufacturers provide CUDA support, and even in hundreds of millions of PCs.
When you download Nim, you instantly have an AI assistant that can communicate as smoothly as talking to ChatGPT. Now, all the software has been streamlined and integrated into a container, and the original cumbersome 400 dependencies are all optimized centrally. We have conducted rigorous testing on Nim, and each pre-trained model has been fully tested on our cloud infrastructure, including different versions of GPUs such as Pascal, Ampere, and even the latest Hopper. These versions are varied and cover almost all needs.
The invention of Nim is undoubtedly a feat, and it is one of my proudest achievements. Today, we have the ability to build large language models and various pre-trained models covering multiple fields such as language, vision, and images, as well as customized versions for specific industries such as healthcare and digital biology.

To learn more or try these versions, just visit ai.nvidia.com. Today, we released the fully optimized Llama 3 Nim on Hugging Face, which you can try immediately or even take it away for free. It is easy to run it on any cloud platform of your choice. Of course, you can also download this container to your data center, host it yourself, and serve it to your customers.
As I mentioned earlier, we have versions of Nim covering different fields, including physics, semantic search, visual language, etc., supporting multiple languages. These microservices can be easily integrated into large applications, and one of the most promising applications is customer service agents. It is a standard in almost every industry and represents a global customer service market worth trillions of dollars.
It is worth mentioning that nurses, as the core of customer service, play an important role in industries such as retail, fast food, financial services, and insurance. Today, tens of millions of customer service personnel have been significantly enhanced with the help of language models and artificial intelligence technology. The core of these enhancement tools is what you see as Nim.
Some are called Reasoning Agents, and they can clarify goals and make plans after being given tasks. Some are good at retrieving information, some are good at searching, and others may use tools such as Coop, or need to learn specific languages such as ABAP that run on SAP, or even execute SQL queries. These so-called experts are now organized into a team that works efficiently and collaboratively.
The application layer has also undergone a transformation: in the past, applications were written by instructions, but now they are built by assembling artificial intelligence teams. Although writing programs requires professional skills, almost everyone knows how to break down problems and form teams. Therefore, I firmly believe that every company in the future will have a large collection of Nims. You can select experts as needed and connect them into a team.
What's even more amazing is that you don't even need to figure out how to connect them. Just give the agent a task, and Nim will intelligently decide how to break it down and assign it to the most suitable expert. They are like the central leader of an application or team, able to coordinate the work of team members and finally present the results to you.
The whole process is as efficient and flexible as human teamwork. This is not just a trend of the future, but it will soon become a reality around us. This is the new look that future applications will present.
When we talk about interaction with large-scale artificial intelligence services, we can currently do it through text and voice prompts. But looking forward to the future, we hope to interact in a more human way - that is, digital people. NVIDIA has made significant progress in the field of digital human technology.

Digital people not only have the potential to be excellent interactive agents, they are also more attractive and may show higher empathy. However, to cross this incredible gap and make digital humans look and feel more natural, we still need to make great efforts. This is not only our vision, but also our unremitting pursuit.
Before I show you what we have achieved so far, please allow me to express my warm greetings to Taiwan, China. Before we explore the charm of the night market, let's take a look at the cutting-edge dynamics of digital human technology.
It is really incredible. ACE (Avatar Cloud Engine, NVIDIA digital human technology) can not only run efficiently in the cloud, but also compatible with PC environments. We proactively integrate Tensor Core GPUs into all RTX series, which marks that the era of AI GPUs has arrived and we are fully prepared for it.
The logic behind it is very clear: to build a new computing platform, you must first lay a solid foundation. With a solid foundation, applications will naturally emerge. Without such a foundation, there is no application. So, only when we build it, the prosperity of applications is possible.
So we've integrated Tensor Core processing units into every RTX GPU, and there are now 100 million GeForce RTX AI PCs in use worldwide, and that number is growing, expected to reach 200 million. At the recent Computex show, we launched four new AI laptops.
All of these devices have the ability to run AI. The laptops and PCs of the future will become carriers of AI, and they will quietly help and support you in the background. At the same time, these PCs will also run applications enhanced by AI, whether you are doing photo editing, writing, or using other tools, you will enjoy the convenience and enhancements brought by AI.

In addition, your PC will also be able to host digital human applications with AI, allowing AI to be presented and applied on PCs in a more diverse way. Obviously, the PC will become a critical AI platform. So, how will we develop next?
I talked about the expansion of our data centers earlier, and each expansion is accompanied by new changes. As we scaled from DGX to large AI supercomputers, we achieved efficient training of Transformer on huge datasets. This marked a major shift: in the beginning, data required human supervision and human labeling to train AI. However, the amount of data that humans can label is limited. Now, with the development of Transformer, unsupervised learning is possible.
Today, Transformer can explore massive amounts of data, videos, and images on its own, learn from them, and discover hidden patterns and relationships. To push AI to a higher level, the next generation of AI needs to be rooted in an understanding of the laws of physics, but most AI systems lack a deep understanding of the physical world. In order to generate realistic images, videos, 3D graphics, and simulate complex physical phenomena, we urgently need to develop physics-based AI, which requires it to understand and apply the laws of physics.
There are two main ways to achieve this goal. First, by learning from videos, AI can gradually accumulate knowledge of the physical world. Second, using synthetic data, we can provide AI systems with a rich and controllable learning environment. In addition, mutual learning between simulated data and computers is also an effective strategy. This approach is similar to AlphaGo's self-playing mode, where two entities of the same ability learn from each other over a long period of time, thereby continuously improving their intelligence. Therefore, we can foresee that this type of artificial intelligence will gradually emerge in the future.
When artificial intelligence data is generated synthetically and combined with reinforcement learning technology, the rate of data generation will be significantly increased. As data generation grows, the demand for computing power will also increase accordingly. We are about to enter a new era in which artificial intelligence will be able to learn the laws of physics and understand and make decisions and actions based on data from the physical world. Therefore, we expect that artificial intelligence models will continue to expand and the requirements for GPU performance will become higher and higher.
To meet this demand, Blackwell came into being. This GPU is designed to support the next generation of artificial intelligence and has several key technologies. This chip size is second to none in the industry. We took two chips as large as possible and connected them tightly together through a high-speed link of 10 terabytes per second, combined with the world's most advanced SerDes (high-performance interface or connection technology). Furthermore, we put two such chips on a computer node and coordinate them efficiently through the Grace CPU.
The Grace CPU is widely used, not only for training scenarios, but also plays a key role in reasoning and generation processes, such as fast checkpoints and restarts. In addition, it can store context, allowing the AI system to have memory and understand the context of the user's conversation, which is crucial to enhancing the continuity and fluency of the interaction.
Our second-generation Transformer engine has further improved the computing efficiency of AI. This engine can dynamically adjust to lower precision according to the accuracy and range requirements of the computing layer, thereby reducing energy consumption while maintaining performance. At the same time, Blackwell GPUs also have secure AI features to ensure that users can ask service providers to protect them from theft or tampering.
In terms of GPU interconnection, we use the fifth-generation NV Link technology, which allows us to easily connect multiple GPUs. In addition, Blackwell GPUs are also equipped with the first-generation reliability and availability engine (Ras system), an innovative technology that can test every transistor, trigger, memory and off-chip memory on the chip to ensure that we can accurately determine whether a specific chip has reached the mean time between failures (MTBF) standard on the spot.
Reliability is particularly critical for large supercomputers. The mean time between failures for a supercomputer with 10,000 GPUs may be measured in hours, but when the number of GPUs increases to 100,000, the mean time between failures will be reduced to minutes. Therefore, in order to ensure that supercomputers can run stably for a long time to train complex models that may take months, we must improve reliability through technological innovation. And improved reliability not only increases system uptime, but also effectively reduces costs.
Finally, we have also integrated an advanced decompression engine into the Blackwell GPU. When it comes to data processing, decompression speed is crucial. By integrating this engine, we can pull data from storage 20 times faster than existing technology, greatly improving data processing efficiency.
The above features of the Blackwell GPU make it an attractive product. I showed you the prototype of Blackwell at the previous GTC conference. Now, we are happy to announce that this product has been put into production.

Here, folks, this is Blackwell, and it's incredible technology. It's our masterpiece, the most complex, highest-performance computer in the world today. And we're specifically talking about the Grace CPU, which is the powerhouse of computing. Look, these two Blackwell chips, they're linked together. Did you notice? This is the largest chip in the world, and we've linked two of them together with a link that runs at A10TB per second.
So what is Blackwell? It's incredible how powerful it is. Look at these numbers. In just eight years, we've grown our computing power, our floating-point computing power, and our AI floating-point computing power by a factor of 1,000. That's almost more than the growth of Moore's Law at its best.
The growth in computing power is just staggering. And what's even more remarkable is that every time we've grown computing power, the cost has been falling. Let me show you. By increasing computing power, we have reduced the energy used to train the GPT-4 model (2 trillion parameters and 8 trillion tokens) by 350 times.
Imagine that if the same training is done using Pascal, it will consume up to 1,000 GWh of energy. This means that a gigawatt data center is needed to support it, but such a data center does not exist in the world. Even if it exists, it will need to run continuously for a month. If it is a 100-megawatt data center, the training time will be as long as a year.
Obviously, no one is willing or able to create such a data center. This is why eight years ago, large language models like ChatGPT were still an unattainable dream for us. But now, we have achieved this goal by improving performance and reducing energy consumption.
Using Blackwell, we have reduced the energy required from up to 1,000 GWh to only 3 GWh, which is undoubtedly an astonishing breakthrough. Imagine using 1,000 GPUs, and the energy they consume is only equivalent to the calories of a cup of coffee. And 10,000 GPUs can complete the same task in just about 10 days. These advances in eight years are simply incredible.

Blackwell is not only suitable for reasoning, but its improvement in token generation performance is even more remarkable. In the Pascal era, each token consumed up to 17,000 joules of energy, which is about the energy of two light bulbs running for two days. And generating a GPT-4 token requires almost two 200-watt light bulbs to run continuously for two days. Considering that it takes about 3 tokens to generate a word, this is indeed a huge energy consumption.
However, the situation is now completely different. Blackwell makes it only take 0.4 joules of energy to generate each token, generating tokens at an amazing speed and extremely low energy consumption. This is undoubtedly a huge leap. But even so, we are still not satisfied. For a bigger breakthrough, we must build a more powerful machine.
This is our DGX system, in which the Blackwell chip will be embedded. This system uses air cooling technology and is equipped with 8 such GPUs inside. Look at the heatsinks on these GPUs, they are amazingly large. The whole system consumes about 15 kilowatts of power, all through air cooling. This version is compatible with X86 and has been used in the servers we have shipped.
However, if you prefer liquid cooling technology, we also have a brand new system - MGX. It is based on this motherboard design and we call it a "modular" system. The core of the MGX system is two Blackwell chips, and each node integrates four Blackwell chips. It uses liquid cooling technology to ensure efficient and stable operation.
There are nine such nodes in the whole system, with a total of 72 GPUs, forming a huge computing cluster. These GPUs are closely connected through the new NV link technology to form a seamless computing network. The NV link switch is a technological miracle. It is the most advanced switch in the world and has an astonishing data transmission rate. These switches enable each Blackwell chip to be efficiently connected to form a huge 72 GPU cluster.
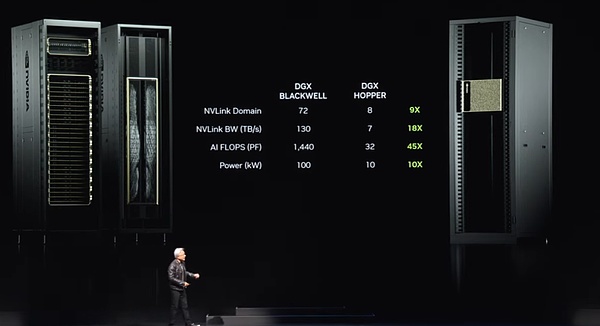
What is the advantage of this cluster? First, in the GPU domain, it now behaves like a single, super-scale GPU. This "super GPU" has the core power of 72 GPUs, which is 9 times the performance of the previous generation of 8 GPUs. At the same time, the bandwidth has increased by 18 times, and the AI FLOPS (floating point operations per second) has increased by 45 times, while the power has increased by only 10 times. In other words, one such system can provide 100 kilowatts of power, while the previous generation only used 10 kilowatts.
Of course, you can also connect more of these systems together to form a larger computing network. But the real miracle is this NV link chip, which is becoming more and more important as large language models become larger and larger. Because these large language models are no longer suitable for running on a single GPU or node, they need the coordination of an entire GPU rack. Like the new DGX system I just mentioned, it can accommodate large language models with tens of trillions of parameters.
The NV link switch itself is a technological miracle, with 50 billion transistors, 74 ports, and a data rate of 400 GB per port. But more importantly, the switch also has math built into it, so it can do reductions directly, which is extremely important in deep learning. That's the new face of the DGX system now.
A lot of people are curious about us. They question what Nvidia does. People wonder how Nvidia could have gotten so big just by making GPUs. So a lot of people get the impression that a GPU should look a certain way.
And now I'm going to show you that this is a GPU, but it's not what you think it is. This is one of the most advanced GPUs in the world, but it's used primarily for gaming. But we all know that the real power of a GPU is much more than that.
Look at this, folks. This is a real GPU. This is a DGX GPU designed for deep learning. The back of this GPU is connected to the NV Link Backbone, which is 5,000 wires and is 3 kilometers long. These wires, the NV Link Backbone, connect 70 GPUs to form a powerful computing network. It's an electro-mechanical marvel, with transceivers that allow us to drive signals across the entire length of the copper wire.
So this NV Link switch transmits data over copper wires through the NV Link backbone, allowing us to save 20 kilowatts of power in a single rack, and this 20 kilowatts can now be used entirely for data processing, which is indeed an incredible achievement. This is the power of the NV Link backbone.
But this is not enough to meet the needs, especially for large-scale AI factories, then we have another solution. We must use high-speed networks to connect these AI factories. We have two network options: InfiniBand and Ethernet. Among them, InfiniBand has been widely used in supercomputing and AI factories around the world, and it is growing rapidly. However, not every data center can use InfiniBand directly because they have made a lot of investments in the Ethernet ecosystem, and managing InfiniBand switches and networks does require certain expertise and technology.
So our solution is to bring the performance of InfiniBand to the Ethernet architecture, which is not an easy task. The reason is that each node, each computer is usually connected to different users on the Internet, but most of the communication actually happens inside the data center, that is, the data transmission between the data center and the user on the other side of the Internet. However, in the deep learning scenario of the AI factory, the GPUs are not communicating with users on the Internet, but are frequently and intensively exchanging data with each other.
They communicate with each other because they are all collecting partial results. Then they have to reduce and redistribute these partial results. This communication pattern is characterized by highly bursty traffic. What matters is not the average throughput, but the last data that arrives, because if you are collecting partial results from everyone and I try to receive all your partial results, if the last packet arrives late, then the whole operation will be delayed. For the AI factory, latency is a critical issue.
So, our focus is not on average throughput, but on ensuring that the last packet arrives on time and without error. However, traditional Ethernet is not optimized for this highly synchronized, low-latency requirement. To meet this need, we creatively designed an end-to-end architecture that enables NICs (network interface cards) and switches to communicate. To achieve this goal, we used four key technologies:
First, NVIDIA has industry-leading RDMA (Remote Direct Memory Access) technology. Now we have RDMA at the Ethernet network level, and it works very well.
Second, we introduced congestion control mechanisms. The switches have real-time telemetry capabilities that can quickly identify and respond to congestion in the network. When the amount of data sent by the GPU or NIC is too large, the switch will immediately send a signal to tell them to slow down the sending rate, effectively avoiding the generation of network hotspots.
Third, we used adaptive routing technology. Traditional Ethernet transmits data in a fixed order, but in our architecture, we can flexibly adjust according to real-time network conditions. When congestion is found or some ports are idle, we can send packets to these idle ports, and then the Bluefield device on the other end will reorder them to ensure that the data is returned in the correct order. This adaptive routing technology greatly improves the flexibility and efficiency of the network.
Fourth, we implemented noise isolation technology. In the data center, the noise and traffic generated by multiple models training at the same time may interfere with each other and cause jitter. Our noise isolation technology can effectively isolate these noises and ensure that the transmission of key data packets is not affected.
By adopting these technologies, we have successfully provided high-performance, low-latency network solutions for AI factories. In data centers worth billions of dollars, if the network utilization rate is improved by 40% and the training time is reduced by 20%, it actually means that a data center worth $5 billion is equivalent to a data center worth $6 billion in performance, revealing the significant impact of network performance on overall cost-effectiveness.
Fortunately, Ethernet technology with Spectrum X is the key to our goal. It greatly improves network performance and makes the network cost almost negligible relative to the entire data center. This is undoubtedly a great achievement in the field of network technology.
We have a series of powerful Ethernet product lines, the most notable of which is Spectrum X800. This device provides efficient network connection for thousands of GPUs with a speed of 51.2 TB per second and the ability to support 256 paths (radix). Next, we plan to launch X800 Ultra a year later, which will support 512 radix with up to 512 paths, further improving network capacity and performance. The X1600 is designed for larger data centers, able to meet the communication needs of millions of GPUs.

With the continuous advancement of technology, the era of data centers with millions of GPUs is just around the corner. There are profound reasons behind this trend. On the one hand, we are eager to train larger and more complex models; but more importantly, the future Internet and computer interactions will increasingly rely on generative AI in the cloud. These AIs will work and interact with us to generate videos, images, texts and even digital people. Therefore, almost every interaction we have with computers is inseparable from the participation of generative AI. And there is always a generative AI connected to it, some of which runs locally, some runs on your device, and many may run in the cloud.
These generative AIs not only have powerful reasoning capabilities, but also can iteratively optimize answers to improve the quality of answers. This means that we will have a huge demand for data generation in the future. Tonight, we have witnessed the power of this technological innovation together.
Blackwell, as the first generation of the NVIDIA platform, has attracted much attention since its launch. Today, the world has ushered in the era of generative artificial intelligence, which is the beginning of a new industrial revolution, and every corner is realizing the importance of artificial intelligence factories. We are deeply honored to have received extensive support from all walks of life, including every OEM (original equipment manufacturer), computer manufacturer, CSP (cloud service provider), GPU cloud, sovereign cloud and telecommunications company.
Blackwell's success, widespread adoption and industry enthusiasm have reached unprecedented heights, which makes us deeply gratified and we would like to express our sincere gratitude to everyone. However, our pace will not stop there. In this era of rapid development, we will continue to work hard to improve product performance, reduce the cost of training and inference, and continuously expand the capabilities of artificial intelligence so that every enterprise can benefit from it. We firmly believe that as performance increases, costs will be further reduced. The Hopper platform may undoubtedly be the most successful data center processor in history.
This is indeed a stunning success story. As you can see, the birth of the Blackwell platform is not a stack of single components, but a complete system that integrates multiple elements such as CPU, GPU, NVLink, NICK (specific technology component) and NVLink switch. We are committed to using large, ultra-high-speed switches to closely connect all GPUs through each generation of products to form a large and efficient computing domain.
We integrate the entire platform into the artificial intelligence factory, but more importantly, we provide this platform to global customers in a modular form. The original intention of doing this is that we expect each partner to create a unique and innovative configuration according to their own needs to adapt to different styles of data centers, different customer groups and diverse application scenarios. From edge computing to telecommunications, as long as the system remains open, all kinds of innovation will become possible.
In order to allow you to innovate freely, we have designed an integrated platform, but at the same time provide it to you in a decomposed form, so that you can easily build a modular system. Now, the Blackwell platform is here.
NVIDIA has always been committed to an annual update cadence. Our core philosophy is very clear: 1) build solutions that cover the entire data center scale; 2) break these solutions into individual components and launch them to customers around the world once a year; 3) we spare no effort to push all technologies to the limit, whether it is TSMC's process technology, packaging technology, memory technology, or optical technology, we pursue the ultimate performance.
After completing the hardware limit challenge, we will go all out to ensure that all software can run smoothly on this complete platform. Software inertia is crucial in computer technology. When our computer platform is backward compatible and the architecture fits perfectly with existing software, the speed of product launch will be significantly improved. Therefore, when the Blackwell platform comes out, we can fully utilize the software ecosystem foundation that has been built to achieve amazing market response speed. Next year, we will usher in Blackwell Ultra.
Just as we launched the H100 and H200 series, Blackwell Ultra will also usher in the wave of a new generation of products and bring unprecedented innovative experiences. At the same time, we will continue to push the limits of technology and launch the next generation spectrum switch, which is the first attempt in the industry. This major breakthrough has been successfully achieved, although I am still a little hesitant to make this decision public.
Inside NVIDIA, we are used to using code names and maintaining a certain degree of confidentiality. Many times, even most employees in the company do not know these secrets. However, our next generation platform has been named Rubin. I will not say too much about Rubin here. I understand your curiosity, but please allow me to keep it a little mysterious. You may be eager to take pictures or study the fine print, so please feel free.
We not only have the Rubin platform, but also the Rubin Ultra platform will be launched in a year. All the chips shown here are in the full development stage to ensure that every detail has been carefully polished. Our update cadence is still once a year, always pursuing the ultimate in technology, while ensuring that all products maintain 100% architectural compatibility.

Looking back over the past 12 years, from the moment Imagenet was born, we foresaw that the future of computing would undergo tremendous changes. Today, all of this has become a reality, just as we envisioned. From GeForce before 2012 to NVIDIA today, the company has undergone a huge transformation. Here, I would like to sincerely thank all partners for their support and companionship along the way.
This is NVIDIA's Blackwell platform. Next, let's talk about the future of artificial intelligence and robots.
Physical AI is leading a new wave in the field of artificial intelligence. They are well versed in the laws of physics and can be easily integrated into our daily lives. To this end, physical AI not only needs to build an accurate world model to understand how to interpret and perceive the world around it, but also needs to have excellent cognitive abilities to deeply understand our needs and perform tasks efficiently.
Looking ahead, robotics will no longer be a distant concept, but will become increasingly integrated into our daily lives. When people think of robotics, they often think of humanoid robots, but in fact, its applications are much more than that. Mechanization will become the norm, factories will be fully automated, and robots will work together to produce a range of mechanized products. They will interact more closely and create a highly automated production environment.
To achieve this goal, we need to overcome a number of technical challenges. Next, I will show these cutting-edge technologies in the video.
This is not just a vision of the future, it is gradually becoming a reality.
We will serve the market in many ways. First, we are committed to building platforms for different types of robotic systems: dedicated platforms for robotic factories and warehouses, object manipulation robots, mobile robots, and humanoid robots. These robotic platforms, like many of our other businesses, rely on computer-accelerated libraries and pre-trained models.
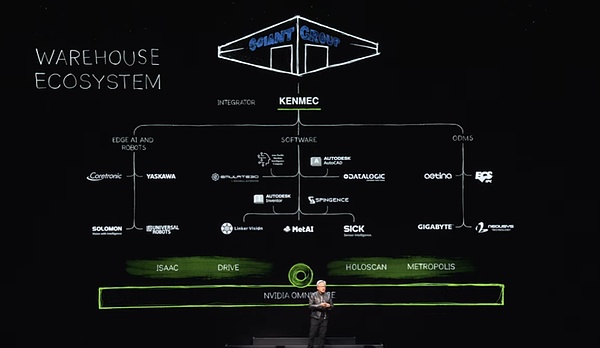
We use computer-accelerated libraries, pre-trained models, and conduct comprehensive testing, training, and integration in Omniverse. As shown in the video, Omniverse is where robots learn how to better adapt to the real world. Of course, the ecosystem of robotic warehouses is extremely complex, and it takes many companies, tools, and technologies to work together to build a modern warehouse. Today, warehouses are gradually moving towards full mechanization and will one day be fully automated.
In such an ecosystem, we provide SDK and API interfaces for the software industry, the edge artificial intelligence industry, and companies, and also design dedicated systems for PLC and robotic systems to meet the needs of specific fields such as the Department of Defense. These systems are integrated through integrators to ultimately create efficient and intelligent warehouses for customers. For example, Ken Mac is building a robotic warehouse for Giant Giant Group.
Next, let's focus on the factory field. The ecosystem of the factory is completely different. Take Foxconn as an example. They are building some of the most advanced factories in the world. The ecosystem of these factories also covers edge computers, robotics software for designing factory layouts, optimizing workflows, programming robots, and PLC computers for coordinating digital factories and artificial intelligence factories. We also provide SDK interfaces for each link in these ecosystems.
Such changes are taking place around the world. Foxconn and Delta are building digital twins for their factories, achieving a perfect fusion of reality and digital, and Omniverse plays a vital role in this. It is also worth mentioning that Pegatron and Wistron are also following the trend and building digital twins for their respective robot factories.
This is really exciting. Next, please enjoy a wonderful video of Foxconn's new factory.
The robot factory consists of three main computer systems. The artificial intelligence model is trained on the NVIDIA AI platform. We ensure that the robots run efficiently on the local system to orchestrate the factory process. At the same time, we use Omniverse, a simulation collaboration platform, to simulate all factory elements including robotic arms and AMRs (autonomous mobile robots). It is worth mentioning that these simulation systems all share the same virtual space for seamless interaction and collaboration.
When the robotic arms and AMRs enter this shared virtual space, they can simulate the real factory environment in Omniverse to ensure that they are fully verified and optimized before actual deployment.
To further enhance the integration and application scope of the solution, we provide three high-performance computers equipped with acceleration layers and pre-trained AI models. In addition, we have successfully combined NVIDIA Manipulator and Omniverse with Siemens' industrial automation software and systems. This collaboration enables Siemens to achieve more efficient robot operation and automation in factories around the world.
In addition to Siemens, we have also established partnerships with many well-known companies. For example, Symantec Pick AI has integrated NVIDIA Isaac Manipulator, and Somatic Pick AI has successfully run and operated robots from well-known brands such as ABB, KUKA, and Yaskawa Motoman.
The era of robotics and physical artificial intelligence has arrived, and they are being widely used everywhere. This is not science fiction, but reality, which is very exciting. Looking forward to the future, robots in factories will become mainstream and they will manufacture all products. Among them, two high-volume robot products are particularly eye-catching. First up are self-driving cars or cars with highly autonomous capabilities, where NVIDIA again plays a central role with its comprehensive technology stack. Next year, we plan to work with Mercedes-Benz Racing, followed by Jaguar Land Rover (JLR) Racing in 2026. We offer a full solution stack, but customers can choose any part or layer of it based on their needs, as the entire drive stack is open and flexible.
Next, another product that may be manufactured in high volumes by robotic factories is humanoid robots. In recent years, there have been huge breakthroughs in cognitive capabilities and world understanding, and the prospects for development in this area are exciting. I am particularly excited about humanoid robots because they have the greatest potential to adapt to the world we build for humans.
Training humanoid robots requires a lot of data compared to other types of robots. Since we have similar body shapes, the large amount of training data provided by demonstrations and video capabilities will be extremely valuable. Therefore, we expect to make significant progress in this area.

Now, let's welcome some special robot friends. The era of robots has arrived, and it is the next wave of artificial intelligence. Computers manufactured in Taiwan, China, are of various types, including traditional models with keyboards, small and light mobile devices that are easy to carry, and professional equipment that provides powerful computing power for cloud data centers. But looking to the future, we will witness an even more exciting moment - making computers that walk and roll around, that is, smart robots.
These smart robots have a striking similarity in technology to the computers we are familiar with, and they are all built on advanced hardware and software technologies. Therefore, we have reason to believe that this will be a truly extraordinary journey!
This Monday, Nvidia's stock price hit a new record high, with a market value of over $3.5 trillion, approaching the world's number one Apple.
JinseFinanceBut in a country where billionaires often mysteriously disappear, how long can Colin Huang last before he faces the same predicament as his predecessors? CEO of Renaissance, Bao Fan; real estate tycoon, Ren Zhiqiang, and most prominently, Alibaba founder, Jack Ma, all went missing from the face of the earth during their prime.
 XingChi
XingChiArtificial intelligence, meta, transcript of Huang Renxun and Zuckerberg's summit conversation: a 10,000-word article reveals Meta's future AI landscape. Golden Finance, how do Huang Renxun and Zuckerberg view the future of AI?
JinseFinanceGolden Finance launches the 2340th issue of "Golden Morning 8", a morning report on the cryptocurrency and blockchain industry, to provide you with the latest and fastest news on the digital currency and blockchain industry.
JinseFinanceNvidia's stock hit a new all-time high yesterday, closing at $1139.01, up 7%. Currently in Taiwan, Jensen Huang stated in an interview that Taiwan is at the center of AI, and he looks forward to further promoting Taiwan's AI industry development.
 Sanya
SanyaHuang Licheng's Memecoin Bobaoppa raised 195,000 SOL ($36M) with staking and transfers, but his past projects, including Mithril and Formosa, raise concerns of dubious practices.
 Alex
AlexLICHENG HUANG's $25 million dispute with Blur and the 3000 ETH deposit into Blast creates ripples in the crypto world, sparking intense speculation and anticipation for the unfolding drama
 Cheng Yuan
Cheng YuanHuang acknowledged Zach's contributions to the crypto community and expressed that taking legal action was a last resort.
 Davin
DavinCrypto legal cases have exploded in recent years.
 Beincrypto
BeincryptoAccording to news on June 17, according to an article issued by encrypted KOL zachxbt, Jeffrey Huang (Jeffrey Huang) has successively launched dozens of tokens such as Mithril (MITH), Formosa Financial (FMF), Machi X, Cream Finance (CREAM), and Swag Finance (SWAG). rubbish item.
 链向资讯
链向资讯