MetaMask and Robinhood Connect: reduce redundant user operations
The MetaMask-Robinhood partnership revolutionizes web3, merging seamless crypto transactions with user-centric design for a simplified, secure digital asset experience.
 Weiliang
Weiliang

Source: Fairy, ChainCatcher
Editor's note: The author sees the multiple obstacles such as capital and hardware faced by Web3 projects in promoting the development of AI through the halo of technology. Although the original intention of Web3 is to break centralization and realize the ideal of decentralization, in actual operation, it is often influenced by market narratives and token incentives and deviates from the original intention.
ChainCatcher translates the original text as follows:
The call for the combination of AI and Web3 is getting louder and louder, but this is no longer an optimistic venture capital article. We are optimistic about merging the two technologies, but the text below is a call. Otherwise, this optimism will not be realized.
Why? Because developing and running the best AI models requires huge capital expenditures, the most advanced hardware is often difficult to obtain, and requires research and development in very specific fields. Crowdsourcing these resources through crypto incentives, as most Web3 artificial intelligence projects are doing, is not enough to offset the tens of billions of dollars invested by large companies that control the development of AI. Given the hardware limitations, this may be the first large-scale software paradigm that smart and creative engineers outside of existing organizations cannot break.
Software is eating the world at an increasing rate, and will soon grow exponentially with AI accelerating. All of this pie is going to the tech giants, while end users, including governments and large corporations, are even more constrained by their power.
All of this is happening at a very inopportune time — 90% of decentralized network participants are busy chasing the “golden egg” of easy fiat gains driven by narratives.
Developers are following the investors in our industry, not the other way around. This takes various forms, from open admissions to more subtle subconscious motivations, but narratives and the markets that form around them drive many decisions in Web3. As with traditional reflexive bubbles, participants are too focused on the internal world to notice the external world unless it helps further the narrative of this cycle. And AI is clearly the biggest narrative, as it is in a booming phase itself.
We have spoken to dozens of teams at the intersection of AI and crypto, and can confirm that many of them are very capable, mission-driven, and passionate builders. But human nature being what it is, when faced with temptations, we tend to give in to them and then rationalize those choices after the fact.
The path to easy liquidity has been the historical curse of the crypto industry - at this point, it has delayed development and valuable adoption for years. It has caused even the most devoted crypto believers to veer in the direction of “pumping the token.” The rationalization is that builders who hold onto the token may have a better chance.
The low complexity of both institutional and retail capital provides builders with the opportunity to make claims divorced from reality while benefiting from valuations as if those claims have already been fulfilled. The result of these processes is actually entrenched moral hazard and capital destruction, and few such strategies work in the long term. Necessity is the mother of all inventions, and when the need is gone, the invention is gone.
The timing of this could not have been worse. While all the smartest tech entrepreneurs, state actors, and businesses large and small were racing to secure a piece of the AI revolution, crypto founders and investors chose to “10x fast.” And that, in our view, is the real opportunity cost.
Given the incentives above, the taxonomy of Web3 AI projects can really be broken down into:
Reasonable (also subdivided into realists and idealists)
Semi-reasonable
Fake
Fundamentally, we believe that project builders should have a clear idea of how to keep up with their Web2 competitors, and know which areas are competitive and which are wishful thinking, despite the fact that these wishful thinking areas may be marketed to VCs and the public.
The goal is to be able to compete here and now. Otherwise, the pace of AI development may leave Web3 behind, and the world will leap to "Web4" between Western enterprise AI and Chinese national AI. Those who are not able to be competitive in time and rely on distributed technologies to catch up over a longer time frame are too optimistic to be taken seriously.
Obviously, this is a very rough generalization, and even among the “fakers” there are at least a few serious teams (and perhaps more are just delusional). But this post is a call to action, so we are not trying to be objective, but rather to call on readers to have a sense of urgency.
Reasonable:
There are not many solution founders developing “AI on-chain” middleware who understand that it is not feasible or even impossible to decentralizedly train or infer the models that users actually need (i.e. cutting-edge technology) at the moment.
Therefore, finding a way to connect the best centralized models with an on-chain environment that benefits from sophisticated automation is a good enough first step for them. At present, hardware-isolated TEEs (“air-gapped” processors) that can host API access points, bidirectional oracles (for bidirectionally indexing on-chain and off-chain data), and coprocessor architectures that provide proxies with a verifiable off-chain computation environment seem to be the best solutions at the moment.
There is also a coprocessor architecture that uses zero-knowledge proofs (ZKPs) to take snapshots of state changes (rather than verifying full computations), which we think is also feasible in the medium term.
For the same problem, a more idealistic approach would be to try to verify off-chain inference to make it consistent with on-chain computation in terms of trust assumptions.
We believe that the goal should be to allow AI to perform on-chain and off-chain tasks in a unified runtime environment. However, most proponents of verifiability of inference talk about thorny goals like “trusting the model weights” that will not actually become relevant for several years (if ever). Recently, founders of this camp have begun to explore alternative ways to verify inference, but initially all based on ZKPs. While a lot of smart teams are working on ZKML (i.e. zero-knowledge machine learning), they expect cryptographic optimizations to outpace the complexity and computational requirements of AI models, taking too big a risk. As a result, we believe they are not currently suitable for competition. However, some recent progress is interesting and should not be ignored.
Semi-reasonable:
Consumer applications use wrappers that encapsulate closed-source and open-source models (e.g. Stable Diffusion or Midjourney for image generation). Some of these teams are first to market and have gained acceptance from real users. So it’s not fair to call them all fakers, but only a few teams are thinking deeply about how to evolve their underlying models in a decentralized way and innovating in incentive design. On the token side, there are also some interesting governance/ownership designs. However, most of these projects are just slapping a token on an otherwise centralized wrapper like the OpenAI API to get a valuation premium or faster liquidity for the team.
The problem that neither of the above camps has solved is the training and inference of large models in a decentralized environment. Currently, it is impossible to train basic models in a reasonable time without relying on a tightly connected hardware cluster. Given the level of competition, "reasonable time" is the key factor.
There have been some promising research results recently, and in theory, methods such as "Differential Data Flow" may be extended to distributed computing networks in the future to increase their capacity (as network capabilities catch up with data flow requirements). However, competitive model training still requires communication between localized clusters, rather than a single distributed device and cutting-edge computing (retail GPUs are increasingly uncompetitive).
Research into localized inference (one of the two approaches to decentralization) by reducing model size has also made progress recently, but there are no existing protocols that take advantage of it in Web3.
The question of decentralized training and inference logically brings us to the last of the three camps, and by far the most important, and therefore the most emotionally triggering one for us.
Fake:
Infrastructure applications are mainly concentrated in the field of decentralized servers, providing bare hardware or decentralized model training/hosting environments. There are also software infrastructure projects that are promoting protocols such as federated learning (decentralized model training), or those that combine software and hardware components into a platform where people can basically train and deploy their decentralized models end-to-end. Most of them lack the complexity required to actually solve the described problems, and the naive idea of "token incentives + market forces" prevails here. None of the solutions we have seen in the public and private markets can achieve meaningful competition here and now. Some of them may develop into viable (but niche) products, but what we need now is fresh, competitive solutions. And this can only be achieved through innovative designs that solve the bottlenecks of distributed computing. Not only is speed a big issue in training, but so is verifiability of completed work and coordination of training workloads, which adds bandwidth bottlenecks.
We need a competitive set of truly decentralized foundational models, and they require decentralized training and inference to work. Losing AI could completely negate everything that has been achieved with the “decentralized world computer” since the advent of Ethereum. If computers become AI, and AI is centralized, there will be no world computer except in some dystopian version.
Training and inference are at the core of AI innovation. While the rest of the AI world is moving toward tighter architectures, Web3 needs some orthogonal solutions to compete with them, as head-on competition is becoming less and less viable.
It’s all about compute. The more you put into training and inference, the better the results. Yes, there may be some tweaks and optimizations here and there, and compute itself is not homogeneous. There are all sorts of new ways to overcome the bottlenecks of traditional von Neumann architecture processing units, but it all still comes down to how many matrix multiplications you can do on how big a chunk of memory, and how fast.
This is why we’re seeing such a strong buildout in datacenters by the so-called “hyperscalers,” all looking to create a full stack with AI models at the top and the hardware to power them at the bottom: OpenAI (models) + Microsoft (compute), Anthropic (models) + AWS (compute), Google (both), and Meta (both increasingly, by doubling down on building their own datacenters). There are many more nuances, interaction dynamics, and parties involved, but we won’t list them all. In summary, the hyperscalers are investing billions of dollars in datacenter buildouts like never before and creating synergies between their compute and AI offerings that are expected to yield huge gains as AI becomes more ubiquitous across the global economy.
Let’s look at the expected construction levels of these 4 companies this year alone:
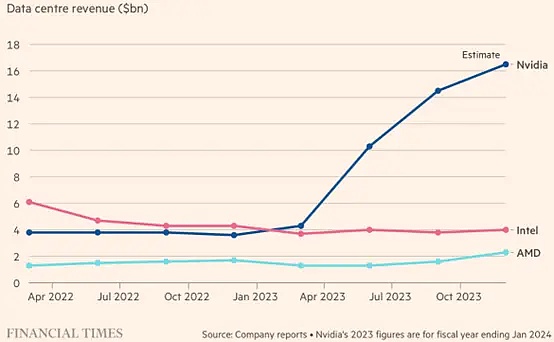
NVIDIA ™ (NVIDIA ®) CEO Jensen Huang has suggested that a total of $1 trillion will be invested in AI acceleration in the next few years. He recently doubled that forecast to $20,000, allegedly because he is seeing interest from sovereign enterprises.
Analysts at Altimeter expect global AI-related data center spending to reach $160 billion and more than $200 billion in 2024 and 2025, respectively.
Now compare these numbers to the incentives Web3 is offering independent datacenter operators to ramp up capex on the latest AI hardware:
The total market cap of all decentralized physical infrastructure (DePIn) projects is currently around $40 billion, made up mostly of relatively illiquid and speculative tokens. Basically, the market cap of these networks is equal to an upper-bound estimate of the total capex of their contributors, as they incentivize this construction with tokens. However, the current market cap is of little use, as it has already been issued.
So let’s assume that another $80 billion (2x the current value) of private and public DePIn token capital comes to the market as an incentive over the next 3-5 years, and assume that 100% of these tokens are used for AI use cases. Even if we divide this very rough estimate by 3 (years), and compare its dollar value to the value of cash invested by hyperscalers in 2024 alone, it’s clear that foisting token incentives on a bunch of “decentralized GPU network” projects is not enough.
Additionally, billions of dollars of investor demand will be needed to absorb these tokens, as the operators of these networks sell off large amounts of mined tokens to cover significant costs of capital and operating expenses. Even more will be needed to drive these tokens up and incentivize expanded construction to outpace the hyperscalers.
However, someone with a good understanding of how Web3 servers currently operate might assume that a large portion of the “decentralized physical infrastructure” is actually running on the cloud services of these hyperscalers. Of course, the surge in demand for GPUs and other AI-specific hardware is driving more supply, which will eventually make cloud rental or purchase cheaper. At least that’s the expectation.
But also consider this: Now Nvidia needs to prioritize customer demand for its latest generation of GPUs. Nvidia is also starting to compete with the largest cloud computing providers on its own turf — offering its AI platform services to enterprise customers that have already locked into these supercomputers. This will eventually force it to either build its own data centers over time (essentially eating into the fat profits they enjoy now, so it’s unlikely) or to significantly limit its AI hardware sales to its partner network cloud providers.
In addition, Nvidia’s competitors that are launching additional AI-specific hardware mostly use the same chips as Nvidia, which are manufactured by TSMC. As a result, essentially all AI hardware companies are currently competing for TSMC’s capacity. TSMC also needs to prioritize certain customers. Samsung and potentially Intel (which is trying to get back into state-of-the-art chipmaking as soon as possible to make chips for its own hardware) may be able to absorb the additional demand, but TSMC is currently producing most AI-related chips, and scaling and calibrating cutting-edge chipmaking (3 and 2 nanometers) takes years.
Finally, China is essentially shut out of the latest generation of AI hardware due to US restrictions on NVIDIA and TSMC. Unlike Web3, Chinese companies actually have their own competitive models, especially LLMs from companies like Baidu and Alibaba, which require large quantities of previous-generation equipment to operate.
There is a non-material risk that hyperscalers will restrict external access to their AI hardware as the battle for AI supremacy intensifies and takes precedence over cloud businesses, due to one or a combination of the above reasons. Basically, it’s a scenario where they take all AI-related cloud capacity for themselves and don’t offer it to anyone else, while gobbling up all the latest hardware. This leaves other big players, including sovereign nations, with a higher demand for the remaining compute supply. Meanwhile, the remaining consumer-grade GPUs become less and less competitive.
Obviously, this is just an extreme case, but if hardware bottlenecks persist, the big players will back off due to excessive prizes. This will exclude decentralized operators like secondary data centers and retail-grade hardware owners (which make up the majority of Web3 DePin providers) from the competition.
While the founders of cryptocurrencies are still asleep, the AI giants are keeping a close eye on cryptocurrencies. Government pressure and competition could push them to adopt cryptocurrencies to avoid being shut down or heavily regulated.
One of the first public hints came when the founder of Stability AI recently resigned in order to start “decentralizing” his company. He previously made no secret in public appearances that he planned to launch a token after the company successfully went public, which somewhat exposed the real motivation behind the expected move.
Similarly, while Sam Altman is not involved in the operations of Worldcoin, the crypto project he co-founded, its tokens are undoubtedly traded as proxies for OpenAI. Whether there is a way to link Internet token projects with AI R&D projects, only time will tell, but the Worldcoin team also seems to be aware that the market is testing this hypothesis.
It makes a lot of sense for us that the AI giants are exploring different paths to decentralization. The problem we see here again is that Web3 has not produced meaningful solutions. "Governance tokens" are mostly just a meme, and currently only those tokens that explicitly avoid direct connections between asset holders and the development and operation of their networks, such as BTC and ETH, are truly decentralized tokens.
The incentive mechanism that leads to slow technological development has also affected the development of different governance crypto network designs. Startup teams simply put a "governance token" on their products, hoping to find a new path in the process of gathering momentum, but ultimately they can only be stuck in the "governance theater" around resource allocation.
The AI race is on, and everyone is taking it very seriously. We can’t find any holes in the thinking of big tech giants to scale computing power — more computing means better AI, and better AI means lower costs, new revenue, and greater market share. To us, this means that the bubble is justified, but all the fakers will still be eliminated in the inevitable future shuffle.
Centralized big enterprise AI is dominating the space, and startups are having a hard time keeping up. The Web3 space is also joining the fray, albeit late. The market has overly rewarded crypto AI projects compared to startups in the Web2 space, causing founders to shift their focus from product delivery to driving token prices up at a critical juncture that is closing quickly. So far, no innovation has been able to circumvent scaling computing to compete.
There is now a credible open source movement around consumer-facing models, and initially only a few centralized enterprises chose to compete for market share against larger closed-source opponents (e.g. Meta, Stability AI). But now the community is catching up, putting pressure on leading AI companies. These pressures will continue to impact closed-source development of AI products, but not much until open-source products catch up. This is another big opportunity in the Web3 space, but only if it solves the problem of decentralized model training and inference.
So while on the surface the “classic” disruptor opportunity is there, the reality is far from it. AI is deeply tied to computation, and nothing can change that without breakthrough innovations in the next 3-5 years, which is a critical period for determining who controls and guides AI development.
The computational market itself, while demand drives supply-side efforts, is also unlikely to “let a hundred flowers bloom” as competition between manufacturers is constrained by structural factors such as chip manufacturing and economies of scale.
We remain optimistic about human ingenuity and are convinced that there are enough smart and noble people who can try to crack the AI puzzle in a way that benefits the free world rather than top-down corporate or government control. However, the chances of this appear to be very slim, at best a coin toss, but the founders of Web3 are busy tossing coins to reap economic benefits rather than making a real impact on the world.
The MetaMask-Robinhood partnership revolutionizes web3, merging seamless crypto transactions with user-centric design for a simplified, secure digital asset experience.
WeiliangPolkadot sets a new record in NFT minting, surpassing Solana and Polygon with 4,930 NFTs per minute. Its innovative architecture and impending upgrades position it as a key player in the blockchain race, but challenges in network security persist.
 Joy
JoyThe B² Network revolutionizes blockchain with its unique Layer-2 solution, leveraging zero-knowledge proofs and a strategic airdrop campaign, backed by significant capital ventures, fostering community and innovation.
 Miyuki
MiyukiDymension storms into the crypto arena with a staggering £390 million airdrop and a 58% surge in its native token, DYM, following its mainnet launch. Pioneering modular blockchain technology, Dymension aims to revolutionise DeFi while cautioning investors to navigate its meteoric rise with care.
JoyEigenlayer's cap lift catalyzes a TVL surge, embodying the delicate balance between growth and decentralization in the evolving landscape of Ethereum's staking and shared security protocols.
 Alex
AlexHong Kong's Securities and Futures Commission issues a deadline for crypto exchanges to obtain licenses or face shutdown, leaving only two licensed exchanges in operation. The move aims to regulate the crypto market, but challenges lie ahead in balancing innovation with regulatory compliance.
JoyThe dispute between BlockFi and 3AC over lending led to a New Jersey bankruptcy court's intervention, causing widespread repercussions and signaling an end to crypto lending and hedge funds.
 Brian
BrianERC404 merges NFT uniqueness with cryptocurrency liquidity, introducing Replicants to revolutionize trading and ownership on the Ethereum blockchain, marking a pivotal evolution in digital assets.
WeiliangOobit secured $25M in Series A funding to expand its crypto payment app globally, enabling transactions at over 100 million retailers, aiming for mainstream cryptocurrency adoption.
MiyukiWalmart and VeChain's collaboration achieved over 200 million transactions, showcasing blockchain's potential in revolutionising retail sustainability. This milestone underscores the importance of transparency and accountability in the food industry's journey towards a safer, more ethical future.
Joy