Subverting the money printing machine in the currency circle
Guy chose ETH because of the native yields provided by the Ethereum network.
 JinseFinance
JinseFinance

Author: Jeff Amico; Translated by: TechFlow
During the COVID-19 pandemic, Folding@home achieved a major milestone. The research project obtained 2.4 exaFLOPS of computing power, provided by 2 million volunteer devices around the world. This represented fifteen times the processing power of the world's largest supercomputer at the time, enabling scientists to simulate COVID protein dynamics on a large scale. Their work has advanced our understanding of the virus and its pathological mechanisms, especially in the early stages of the epidemic.
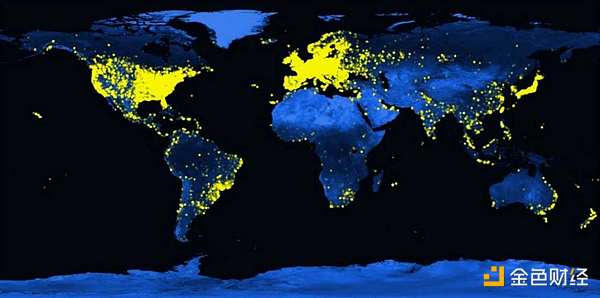
Global distribution of Folding@home users, 2021Folding@home is based on a long history of volunteer computing, where projects crowdsource computing resources to solve large-scale problems. The idea gained widespread attention in the 1990s with SETI@home, a project that brought together more than 5 million volunteer computers to search for extraterrestrial life. Since then, the concept has been applied to multiple fields, including astrophysics, molecular biology, mathematics, cryptography, and gaming. In each case, the collective power has enhanced the capabilities of individual projects far beyond what they could achieve alone. This has driven progress and enabled research to be conducted in a more open and collaborative way.
Many have wondered if we can apply this crowdsourcing model to deep learning. In other words, can we train a large neural network on the crowd? Training cutting-edge models is one of the most computationally intensive tasks in human history. As with many @home projects, the current costs are beyond the reach of only the largest players. This could hinder future progress as we become dependent on fewer and fewer companies to find new breakthroughs. It also concentrates control of our AI systems in the hands of a few. Regardless of your views on this technology, this is a future worth watching.
Most critics dismiss the idea of decentralized training as incompatible with current training techniques. However, this view is increasingly outdated. New techniques have emerged that reduce the need for communication between nodes, allowing for efficient training on devices with poor network connectivity. These techniques include DiLoCo, SWARM Parallelism, decentralized training of base models in lo-fi and heterogeneous environments, and many others. Many of these are fault-tolerant and support heterogeneous computing. There are also new architectures designed specifically for decentralized networks, including DiPaCo and decentralized hybrid expert models.
We are also seeing the maturation of various cryptographic primitives that enable networks to coordinate resources on a global scale. These technologies support use cases such as digital currencies, cross-border payments, and prediction markets. Unlike early volunteer projects, these networks are able to aggregate staggering amounts of computing power, often orders of magnitude larger than the largest cloud training clusters currently envisioned.
Together, these elements form a new paradigm for model training. This paradigm fully exploits the world's computing resources, including the vast number of edge devices that can be used if connected together. This will reduce the cost of most training workloads by introducing new competition mechanisms. It can also unlock new forms of training, making model development collaborative and modular rather than isolated and monolithic. Models can source compute and data from the crowd and learn in real time. Individuals can own a portion of the models they create. Researchers can also re-share novel research results publicly without having to monetize their discoveries to make up for high computing budgets.
This report examines the current state of large-scale model training and the associated costs. It reviews previous distributed computing efforts—from SETI to Folding to BOINC—as inspiration to explore alternative paths. The report discusses the historical challenges of decentralized training and turns to recent breakthroughs that may help overcome these challenges. Finally, it summarizes the opportunities and challenges for the future.
The cost of training frontier models has become prohibitive for non-large players. This trend is not new, but it is getting worse as frontier labs continue to challenge scaling assumptions. OpenAI reportedly spent more than $3 billion on training this year. Anthropic predicts that by 2025, we will start training $10 billion models, and $100 billion models will not be far behind.
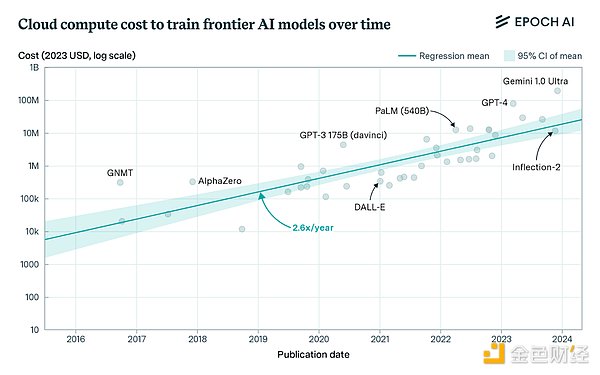
This trend has led to the concentration of the industry, as only a few companies can afford to participate. This raises core policy questions for the future - can we accept a situation where all leading AI systems are controlled by one or two companies? This also limits the rate of progress, which is obvious in the research community because smaller labs cannot afford the computing resources required to scale experiments. Industry leaders have also mentioned this many times:
Meta's Joe Spisak: To really understand the power of [model] architectures, you have to explore them at scale, and I think this is what is missing in the current ecosystem. If you look at academia - there are a lot of brilliant people in academia, but they lack access to computing resources, which becomes a problem because they have these great ideas but don't have the means to really implement them at the level they need.
Together’s Max Ryabinin: The need for expensive hardware is putting a lot of pressure on the research community. Most researchers cannot participate in large neural network development because it is too expensive for them to conduct the necessary experiments. If we continue to increase the size of models by scaling them up, we will eventually be able to compete
Google’s Francois Chollet: We know that large language models (LLMs) have not yet achieved general artificial intelligence (AGI). At the same time, progress towards AGI has stalled. The limitations we face on large language models are exactly the same as we faced five years ago. We need new ideas and breakthroughs. I think it is very likely that the next breakthrough will come from external teams while all the large labs are busy training even larger large language models. Some people are skeptical of these concerns, believing that hardware improvements and cloud computing capital expenditures will solve this problem. But this seems unlikely. On the one hand, by the end of this decade, the number of FLOPs of newer Nvidia chips will increase significantly, perhaps to 10 times that of today’s H100. This will reduce the price per FLOP by 80-90%. Similarly, total FLOP supply is expected to increase by about 20 times by the end of this decade, while improving networks and related infrastructure. All of this will increase training efficiency per dollar.
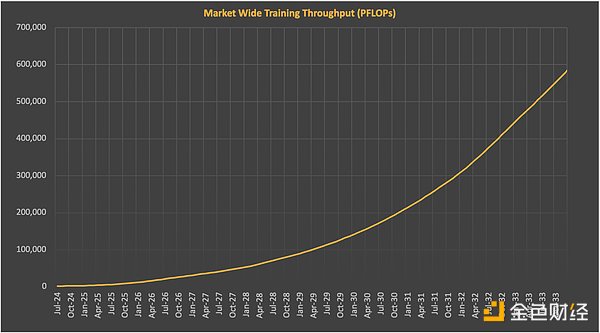
Source: SemiAnalysis AI Cloud TCO Model
At the same time, total FLOP demand will also rise sharply as labs look to scale further. If the decade-long training compute trend remains unchanged, the FLOPs for cutting-edge training are expected to reach about 2e29 by 2030. Training at this scale would require about 20 million H100-equivalent GPUs, based on current training runtimes and utilization. Assuming there are still multiple cutting-edge labs in this field, the total number of FLOPS required will be several times that number, as the overall supply will be divided among them. EpochAI predicts that we will need about 100 million H100-equivalent GPUs by then, about 50 times the number shipped in 2024. SemiAnalysis makes a similar prediction, believing that cutting-edge training demand and GPU supply will grow roughly in tandem during this period.
The capacity situation may become even tighter for a variety of reasons. For example, if manufacturing bottlenecks delay expected shipping cycles, which is often the case. Or if we fail to produce enough energy to power data centers. Or if we have trouble connecting those energy sources to the grid. Or if increasing scrutiny on capital expenditures ultimately causes the industry to scale back, and so on. In the best case, our current approach will only allow a few companies to continue to push research forward, and that may not be enough.
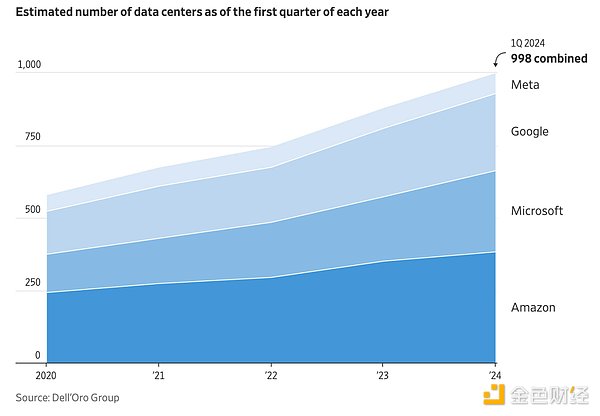
Obviously, we need a new approach. This approach does not require the continuous expansion of data centers, capital expenditures, and energy consumption to find the next breakthrough, but rather makes efficient use of our existing infrastructure and can flexibly expand as demand fluctuates. This will allow for more experiments in research, as training runs no longer need to ensure a return on investment of hundreds of millions of dollars in computing budgets. Once freed from this limitation, we can move beyond the current large language model (LLM) model, which many believe is necessary to achieve general artificial intelligence (AGI). To understand what this alternative might look like, we can draw inspiration from past distributed computing practices.
SETI@home popularized the concept in 1999, allowing millions of participants to analyze radio signals in the search for extraterrestrial intelligence. SETI collected electromagnetic data from the Arecibo telescope, divided it into batches, and sent it to users over the internet. Users analyzed the data in their daily activities and sent their results back. There was no need for users to communicate with each other, and batches could be reviewed independently, allowing for a high degree of parallel processing. At its peak, SETI@home had more than 5 million participants and more processing power than the largest supercomputers at the time. It ultimately shut down in March 2020, but its success inspired the volunteer computing movement that followed.
Folding@home continued the idea in 2000, using edge computing to simulate protein folding in diseases such as Alzheimer's, cancer, and Parkinson's. Volunteers performed protein simulations in their PC's idle time, helping researchers study how proteins misfold and cause disease. At various times in its history, its computing power has exceeded that of the largest supercomputers of the time, including in the late 2000s and during COVID, when it became the first distributed computing project to exceed one exaFLOPS. Since its inception, Folding researchers have published more than 200 peer-reviewed papers, each of which relied on the computing power of volunteers.
The Berkeley Open Infrastructure for Networked Computing (BOINC) popularized the idea in 2002, providing a crowdsourced computing platform for a variety of research projects. It supports multiple projects such as SETI@home and Folding@home, as well as new projects in fields such as astrophysics, molecular biology, mathematics, and cryptography. By 2024, BOINC lists 30 ongoing projects and nearly 1,000 published scientific papers, all produced using its computing network.
Outside of the research community, volunteer computing is used to train game engines such as Go (LeelaZero, KataGo) and chess (Stockfish, LeelaChessZero). LeelaZero was trained from 2017 to 2021 using volunteer computing, enabling it to play more than 10 million games against itself, creating one of the strongest Go engines available today. Similarly, Stockfish has been continuously trained on a network of volunteers since 2013, making it one of the most popular and powerful chess engines.
But can we apply this model to deep learning? Can we network together edge devices around the world to create a low-cost public training cluster? Consumer hardware—from Apple laptops to Nvidia gaming graphics cards—is getting better and better at deep learning. In many cases, the performance of these devices even exceeds the performance per dollar of data center graphics cards.
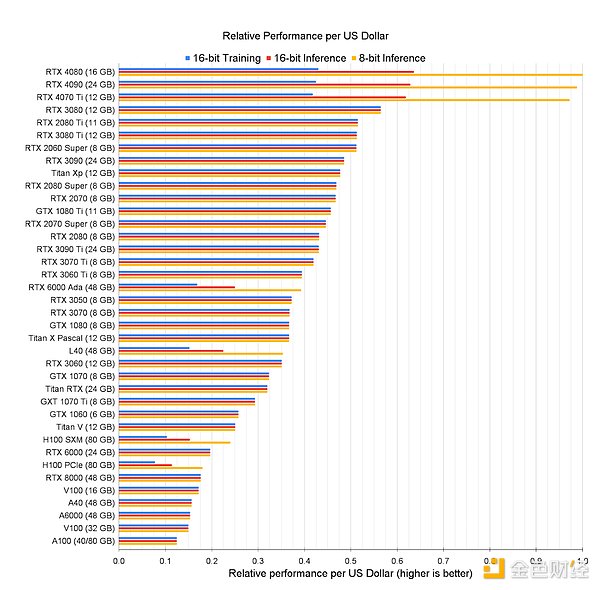
However, to effectively utilize these resources in a distributed environment, we need to overcome various challenges.
First, current distributed training techniques assume frequent communication between nodes.
Current state-of-the-art models have become so large that training must be split among thousands of GPUs. This is achieved through a variety of parallelization techniques, typically splitting the model, the dataset, or both between available GPUs. This typically requires a high-bandwidth and low-latency network, otherwise the nodes will be idle, waiting for data to arrive.
For example, distributed data parallelism (DDP) distributes the dataset across GPUs, with each GPU training a full model on its specific piece of data and then sharing its gradient updates to generate new model weights at each step. This requires relatively limited communication overhead, as nodes only share gradient updates after each backpropagation, and collective communication operations can partially overlap with computation. However, this approach is only suitable for smaller models because it requires each GPU to store the weights, activations, and optimizer states of the entire model in memory. For example, GPT-4 requires more than 10TB of memory when training, while a single H100 has only 80GB.
To address this issue, we also use various techniques to split the model for distribution across GPUs. For example, tensor parallelism splits individual weights within a single layer, allowing each GPU to perform the necessary operations and pass the output to other GPUs. This reduces the memory requirements of each GPU, but requires constant communication back and forth between them, so high-bandwidth, low-latency connections are needed for efficiency.
Pipeline parallelism distributes the layers of the model across the GPUs, with each GPU performing its work and sharing updates with the next GPU in the pipeline. While this requires less communication than tensor parallelism, it can result in "bubbles" (e.g., idle time) where GPUs later in the pipeline wait for information from earlier GPUs in order to begin their work.
Various techniques have been developed to address these challenges. For example, ZeRO (Zero Redundancy Optimizer) is a memory optimization technique that reduces memory usage by increasing communication overhead, allowing larger models to be trained on a specific device. ZeRO reduces memory requirements by splitting model parameters, gradients, and optimizer state between GPUs, but relies on a lot of communication in order for the devices to get the split data. It is the basis for popular techniques such as Fully Sharded Data Parallelism (FSDP) and DeepSpeed.
These techniques are often combined in large model training to maximize resource utilization, which is called 3D parallelism. In this configuration, tensor parallelism is often used to distribute weights across GPUs within a single server, as a lot of communication is required between each split layer. Pipeline parallelism is then used to distribute layers across different servers (but within the same island in the data center) because it requires less communication. Next, data parallelism or Fully Sharded Data Parallelism (FSDP) is used to split the dataset across different server islands because it can accommodate longer network latencies by asynchronously sharing updates and/or compressing gradients. Meta uses this combined approach to train Llama 3.1, as shown in the figure below.
These approaches present core challenges for decentralized training networks that rely on devices connected via (slower and more volatile) consumer-grade internet. In such environments, the cost of communication quickly outweighs the benefits of edge computing, as devices are often idle, waiting for data to arrive. As a simple example, training a half-precision model with 1 billion parameters with distributed data parallelism requires each GPU to share 2GB of data at each optimization step. With typical internet bandwidth (e.g., 1 gigabit per second), assuming that computation and communication do not overlap, transmitting gradient updates takes at least 16 seconds, resulting in significant idleness. Techniques like tensor parallelism (which require more communication) will of course perform worse.
Second, current training techniques lack fault tolerance. Like any distributed system, training clusters become more prone to failures as they scale. However, this problem is exacerbated in training because our current techniques are primarily synchronous, meaning that GPUs must work together to complete model training. The failure of a single GPU among thousands of GPUs can bring the entire training process to a halt, forcing the other GPUs to start training from scratch. In some cases, the GPU does not fail completely, but becomes sluggish for various reasons, slowing down the thousands of other GPUs in the cluster. Given the size of today’s clusters, this can mean tens to hundreds of millions of dollars in additional costs.
Meta elaborated on these issues during their Llama training process, where they experienced over 400 unexpected interruptions, an average of about 8 interruptions per day. These interruptions were mainly attributed to hardware issues, such as GPU or host hardware failures. This resulted in their GPU utilization being only 38-43%. OpenAI performed even worse during GPT-4 training, at only 32-36%, also due to frequent failures during training.
In other words, leading-edge labs still struggle to achieve 40% utilization when training in a fully optimized environment (including homogeneous, state-of-the-art hardware, networking, power, and cooling systems). This is largely attributed to hardware failures and network issues, which are exacerbated in edge training environments because devices have uneven processing power, bandwidth, latency, and reliability. Not to mention, decentralized networks are vulnerable to malicious actors who may try to undermine the overall project or cheat on specific workloads for a variety of reasons. Even the purely volunteer network SETI@home has seen cheating by different participants.
Third, cutting-edge model training requires massive computing power. While projects like SETI and Folding have achieved impressive scale, they pale in comparison to the computing power required for cutting-edge training today. GPT-4 was trained on a cluster of 20,000 A100s with a peak throughput of 6.28 ExaFLOPS at half precision. This is three times more computing power than Folding@home had at its peak. Llama 405b uses 16,000 H100s for training, with a peak throughput of 15.8 ExaFLOPS, 7 times the peak of Folding. This gap will only widen as multiple labs plan to build clusters of more than 100,000 H100s, each with a staggering 99 ExaFLOPS of computing power.
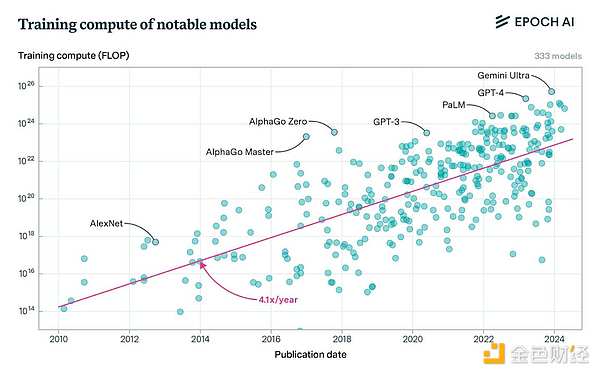
This makes sense because the @home project is volunteer-driven. Contributors donated their memory and processor cycles and covered the associated costs. This naturally limits their scale relative to commercial projects.
While these issues have historically plagued decentralized training efforts, they no longer appear to be insurmountable. New training techniques have emerged that reduce the need for inter-node communication, allowing for efficient training on internet-connected devices. Many of these techniques originate from large labs that want to add greater scale to model training and therefore require efficient communication techniques across data centers. We are also seeing progress in fault-tolerant training methods and cryptographic incentive systems that can enable larger scale training to be performed at the edge.
DiLoCo is recent research from Google that reduces communication overhead by performing local optimizations before passing updated model state between devices. Their approach (building on earlier federated learning research) shows comparable results to traditional synchronous training while reducing the amount of communication between nodes by 500x. The approach has since been replicated by other researchers and scaled to train larger models (over 1 billion parameters). It also scales to asynchronous training, meaning nodes can share gradient updates at different times rather than all at once. This better accommodates edge hardware with varying processing power and network speeds.
Other data parallel approaches, such as lo-fi and DisTrO, aim to further reduce communication costs. Lo-fi proposes a fully local fine-tuning approach, meaning nodes train independently and only pass weights at the end. This approach performs comparable to the baseline when fine-tuning language models with over 1 billion parameters, while completely eliminating communication overhead. In a preliminary report, DisTrO claims to use a new type of distributed optimizer that they believe can reduce communication requirements by four to five orders of magnitude, although this approach has yet to be confirmed.
New model parallel approaches have also emerged that make it possible to achieve even greater scale. DiPaCo (also from Google) divides the model into multiple modules, each containing different expert modules to facilitate training for specific tasks. The training data is then sharded by “paths,” which are sequences of experts corresponding to each data sample. Given a shard, each worker can train a specific path almost independently, except for the communication required to share modules, which is handled by DiLoCo. This architecture reduces the training time of billion-parameter models by more than half.
SWARM Parallelism and Decentralized Training of Grounded Models in Heterogeneous Environments (DTFMHE) also proposed a model parallel approach to enable large model training in heterogeneous environments. SWARM found that as the model size increases, the pipeline parallelism communication constraint decreases, which makes it possible to effectively train larger models at lower network bandwidth and higher latency. To apply this idea in heterogeneous environments, they use temporary “pipeline connections” between nodes, which can be updated in real time at each iteration. This allows a node to send its output to any peer node in the next pipeline stage. This means that if a peer node is faster than the others, or any participant is disconnected, the output can be dynamically rerouted to ensure that training continues as long as there is at least one active participant in each stage. They used this approach to train a model with over 1 billion parameters on low-cost heterogeneous GPUs with slow interconnects (as shown in the figure below).
DTFMHE similarly proposed a novel scheduling algorithm, as well as pipeline and data parallelism, to train large models on devices across 3 continents. Although their network was 100x slower than standard Deepspeed, their approach was only 1.7-3.5x slower than using standard Deepspeed in a datacenter. Similar to SWARM, DTFMHE showed that communication costs can be effectively hidden as the model size increases, even in geographically distributed networks. This allows us to overcome weak connections between nodes through various techniques, including increasing the size of hidden layers and adding more layers per pipeline stage.
Many of the above data parallel methods are fault-tolerant by default, because each node stores the entire model in memory. This redundancy usually means that nodes can still work independently even if other nodes fail. This is very important for decentralized training, because nodes are often unreliable, heterogeneous, and may even behave maliciously. However, as mentioned earlier, pure data parallel methods are only suitable for small models, so the model size is constrained by the memory capacity of the smallest node in the network.
To address the above issues, some people have proposed fault-tolerant techniques suitable for model parallel (or hybrid parallel) training. SWARM copes with peer node failures by giving priority to stable peer nodes with low latency and rerouting tasks of pipeline stages in the event of failure. Other methods, such as Oobleck, take a similar approach to provide redundancy by creating multiple "pipeline templates" to cope with partial node failures. Although tested in data centers, Oobleck's approach provides strong reliability guarantees that are also applicable to decentralized environments.
We have also seen some new model architectures (such as Decentralized Mixture of Experts (DMoE)) to support fault-tolerant training in decentralized environments. Similar to traditional mixture of experts models, DMoE consists of multiple independent networks of "experts" distributed across a set of worker nodes. DMoE uses a distributed hash table to track and consolidate asynchronous updates in a decentralized manner. This mechanism (also used in SWARM) is resilient to node failures because it can exclude certain experts from the average computation if some nodes fail or fail to respond in a timely manner.
Finally, cryptographic incentive systems like those used by Bitcoin and Ethereum can help achieve the required scale. Both networks crowdsource computation by paying contributors a native asset that increases in value as adoption grows. This design incentivizes early contributors by giving them generous rewards that can be gradually reduced as the network reaches a minimum viable scale.
Indeed, there are various pitfalls with this mechanism that need to be avoided. Chief among them is over-incentivizing supply without creating a corresponding demand. Additionally, this could raise regulatory issues if the underlying network is not sufficiently decentralized. However, when designed properly, decentralized incentive systems can achieve significant scale over extended periods of time.
For example, Bitcoin consumes approximately 150 terawatt hours (TWh) of electricity per year, which is more than two orders of magnitude higher than the power consumption of the largest AI training cluster currently conceived (100,000 H100s running at full capacity for a year). For reference, OpenAI’s GPT-4 was trained on 20,000 A100s and Meta’s flagship Llama 405B model was trained on 16,000 H100s. Similarly, at its peak, Ethereum’s power consumption was approximately 70 TWh, spread across millions of GPUs. Even accounting for the rapid growth of AI data centers in the coming years, incentivized computing networks like these will be outstripped many times over.
Of course, not all computation is fungible, and training has unique requirements relative to mining that need to be considered. Nonetheless, these networks demonstrate the scale that can be achieved through these mechanisms.
Putting these pieces together, we can see the beginnings of a new path forward.
Soon, new training techniques will allow us to exceed the limits of data centers, as equipment no longer needs to be co-located to function. This will take time, as our current decentralized training methods are still at a relatively small scale, mostly in the 1 billion to 2 billion parameter range, much smaller than models like GPT-4. We will need further breakthroughs to increase the scale of these methods without sacrificing key properties such as communication efficiency and fault tolerance. Alternatively, we’ll need new model architectures that are different from today’s large, monolithic models—perhaps smaller, more modular, and run on edge devices rather than in the cloud.
In any case, it’s reasonable to expect further progress in this direction. The costs of our current approaches are unsustainable, which provides a strong market incentive for innovation. We’re already seeing this trend, with manufacturers like Apple building more powerful edge devices to run more workloads locally, rather than relying on the cloud. We’re also seeing growing support for open source solutions—even within companies like Meta, to foster more decentralized research and development. These trends will only accelerate over time.
At the same time, we’ll also need new network infrastructure to connect edge devices so that they can be used in this way. These devices include laptops, gaming desktops, and eventually perhaps even mobile phones with high-performance graphics cards and large amounts of memory. This would allow us to build a “global cluster” of low-cost, always-on computing power that can handle training tasks in parallel. This is also a challenging problem that requires progress in multiple areas.
We need better scheduling techniques for training in heterogeneous environments. Currently there is no way to automatically parallelize models to achieve optimization, especially when devices can be disconnected or connected at any time. This is a key next step to optimize training while retaining the scale advantages of edge-based networks.
We must also deal with the general complexity of decentralized networks. To maximize scale, the network should be built as an open protocol - a set of standards and instructions that dictate the interactions between participants, like TCP/IP but for machine learning computations. This will enable any device that follows a specific specification to connect to the network, regardless of owner and location. It also ensures that the network remains neutral, allowing users to train the models they like.
While this maximizes scale, it also requires a mechanism to verify the correctness of all training tasks without relying on a single entity. This is critical because there is an inherent incentive to cheat - for example, claiming to have completed a certain training task in order to be paid, but in fact not doing so. This is particularly challenging given that different devices often perform machine learning operations differently, making it difficult to verify correctness using standard replication techniques. Correctly addressing this problem will require deep research in cryptography and other disciplines.
Fortunately, we continue to see progress on all of these fronts. These challenges no longer seem insurmountable compared to past years. They also seem quite small compared to the opportunities. Google summarized this best in their DiPaCo paper, pointing out the negative feedback mechanism that decentralized training has the potential to break:
Advances in distributed training of machine learning models could lead to simplified infrastructure construction, ultimately leading to more widespread availability of compute resources. Currently, infrastructure is designed around standard methods for training large monolithic models, while machine learning model architectures are designed to take advantage of current infrastructure and training methods. This feedback loop can lead the community into a misleading local minimum where compute resources are more limited than they actually are.
Perhaps most exciting is the growing enthusiasm in the research community to solve these problems. Our team at Gensyn is building the network infrastructure described above. Teams like Hivemind and BigScience are applying many of these techniques in practice. Projects like Petals, sahajBERT, and Bloom demonstrate the power of these techniques, as well as the growing interest in community-based machine learning. Many others are also driving research progress with the goal of building a more open and collaborative model training ecosystem. If you are interested in this work, please contact us to get involved.
Guy chose ETH because of the native yields provided by the Ethereum network.
JinseFinanceOn April 15-16, the international forum Blockchain Life 2024 will be at the main event of the year in Dubai.
 Joy
Joy91Porn官推显示AVAV即将在Bitget创新区上架交易
 铭文老幺
铭文老幺The BONK token giveaway by Solana's Saga mobile phone has astonishingly surpassed the phone's sale price, igniting a surge in demand and market valuation, showcasing the volatile crypto-technology synergy.
 Alex
Alex Coinlive
Coinlive The poll came from one of El Salvador's leading opposition newspapers, prompting a self-congratulatory Tweet from the 'Bitcoin President'.
 CryptoSlate
CryptoSlateMeta has engaged Chinese software firm Tencent to distribute its Meta Quest VR headset despite Meta's Reality Labs losing 17% of revenue in Q4 last year.
 Beincrypto
Beincrypto Nulltx
NulltxDespite the overwhelming approval of the proposal as of Wednesday, many Terra users on social media suggested the network burn its LUNA tokens.
 Cointelegraph
CointelegraphThe official introduction of Cointelegraph France is taking place at the Paris Blockchain Week Summit, a flagship European blockchain event.
Cointelegraph