Abstract
Network is a key link in the era of AI big models.In the era of big models, we have begun to see the acceleration of iterations of network equipment such as optical modules and switches, and the explosion of demand. However, the market has a shallow understanding of why graphics cards need to be equipped with a large number of optical modules and why communication has become a pain point for big models. In this article, we will start from the principle and explore why the network has become the new "C position" in the AI era, and will discuss the innovation and investment opportunities behind the future network side from the latest industrial changes.
Where does the demand for network come from?In the era of big models, the gap between the model size and the upper limit of a single card has rapidly widened. The industry has turned to multi-server clusters to solve the problem of model training, which also constitutes the basis for the "upward" of the network in the AI era. At the same time, compared with the past when it was simply used to transmit data, the network is now more used to synchronize model parameters between graphics cards, which puts higher requirements on the density and capacity of the network.
Increasingly large model size: (1) Training time = training data size x model parameter number / calculation rate (2) Calculation rate = single device calculation rate x number of devices x multi-device parallel efficiency. At present, the industry is pursuing both training data size and parameters. Only by accelerating the improvement of calculation efficiency can the training time be shortened. However, the update of the calculation rate of a single device has its cycle and limitations. Therefore, how to use the network to maximize the "number of devices" and "parallel efficiency" directly determines the computing power.
Complex communication of multi-card synchronization: During the training of large models, after the model is split into single cards, each time after a calculation, the single cards need to be aligned (Reduce, Gather, etc.) At the same time, in NVIDIA's communication primitive system NCCL, All-to-All (that is, all nodes can obtain values from each other and align) operations are more common, which puts higher requirements on transmission and exchange between networks.
Increasingly expensive failure costs:Large model training often lasts for more than several months, and once an interruption occurs in the middle, it is necessary to go back to the breakpoint a few hours or days ago for retraining. A failure in a certain hardware or software link in the entire network, or excessive latency, may cause an interruption. More interruptions represent lagging progress and increasingly high costs. Modern AI networks have gradually developed into the crystallization of human system engineering capabilities comparable to aircraft and aircraft carriers.
Where will network innovation go?Hardware moves with demand. After two years, the scale of global computing power investment has expanded to the level of tens of billions of dollars, and the expansion of model parameters and the fierce battle between giants are still fierce. Today, the balance between "cost reduction", "openness" and computing power scale will be the main issue of network innovation.
Changes in communication media:Light, copper and silicon are the three major media for human transmission. In the AI era, while optical modules pursue higher speeds, they have also taken the path of cost reduction such as LPO, LRO and silicon photonics. At the current point in time, copper cables occupy the connection within the cabinet due to factors such as cost performance and failure rate. New semiconductor technologies such as chiplets and wafer-scaling are accelerating the exploration of the upper limit of silicon-based interconnection.
Competition in network protocols:Inter-chip communication protocols are strongly bound to graphics cards, such as NVIDIA's NV-LINK, AMD's Infinity Fabric, etc., which determine the upper limit of the capacity of a single server or a single computing node. It is a very cruel battlefield for giants. The struggle between IB and Ethernet is the main theme of inter-node communication.
Changes in network architecture:The current inter-node network architecture generally adopts the leaf-spine architecture, which has the characteristics of convenience, simplicity and stability. However, as the number of nodes in a single cluster increases, the slightly redundant architecture of leaf-spine will bring greater network costs to super-large clusters. At present, new architectures such as Dragonfly architecture and rail-only architecture are expected to become the evolution direction for the next generation of super-large clusters.
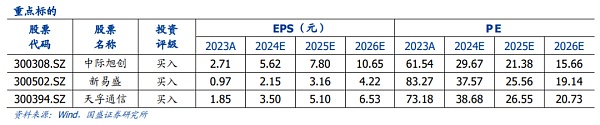
Investment advice: Core links of communication systems:Zhongji Xuchuan, Xinyi Sheng, Tianfu Communication, Industrial Foxconn, Invic, and Shanghai Electric.Innovative links of communication systems:Yangfei Optical Fiber, Taichen Optoelectronics, Yuanjie Technology, Centec Communication-U, Cambrian, and Dekeli.
Risk warning: AI demand is lower than expected, Scaling law becomes invalid, and industry competition intensifies.


1. Investment requirements
The market lacks understanding of the importance of communication networks in AI training. Since the AI market, the market has paid more attention to the research of the network industry chain from the logic of the industry chain. The main research direction is concentrated on the number of optical modules required for each generation of network architecture, and based on this, the output and performance of each link in the industry chain are measured. However, the market has less research on the underlying relationship between AI and communication. This article discusses the core position of communication networks in the AI era in more depth from three aspects: models, multi-card synchronization, and training cost performance.
In summary, there are three main reasons why communication has taken the C position in the AI era. First, With the increasingly large model volume, the number of graphics cards and the computing efficiency after connection directly determine the time required for training, and time is precisely the most precious resource in the increasingly fierce AI competition among giants. Second, Based on the principle of training, after the mainstream parallel mode shifts from model parallelism to data parallelism, after each layer of calculation, it is necessary to align the existing parameters between different NPUs in the cluster. The alignment process of thousands of chip times must ensure low latency and accuracy, which places extremely high requirements on the network. Third, the cost of network failure is extremely high. The current model training time often lasts for several months. Once there are many failures or interruptions, even if the training is rolled back to the save point a few hours ago, the overall training efficiency and cost will be greatly damaged, which is even more fatal for the AI product iteration of giants who are racing against time. At the same time, the current cluster scale has reached 10,000 cards, and the number of connected components may be hundreds of thousands. How to ensure the overall stability and yield rate of these components has become an extremely profound system engineering.
The marketdoes not have enough understanding of the future iteration direction of communication networks. The market's understanding of the iteration of communication networks is more at the research level of following the replacement of graphics cards. We believe that the update cycle and direction brought by hardware iteration are relatively fixed, while the iteration and innovation of the industrial chain in other directions are increasing day by day. At the same time, the current AI capital investment war of overseas giants has reached the level of tens of billions of dollars, and the expansion of model parameters and the fierce battle of giants are still fierce. Today, the balance between "cost reduction", "openness" and computing power scale will be the main issue of network innovation.
Overall, the industry chain's exploration of the frontier is mainly concentrated in three directions. First, the iteration of communication media, which includes the common progress of the three substrates of light, copper and silicon, as well as technical innovations in various media, such as LPO, LRO, silicon photonics, chiplet, wafer-scaling, etc. Second, the innovation of communication protocols, which also includes two aspects. First, the internal communication of nodes, such as NVLINK and Infinity Fabric, the barriers and innovation difficulties in this field are extremely high, and it belongs to the battlefield of giants. Second, the communication between nodes, the industry mainly focuses on the competition between the two major protocols of IB and Ethernet. Third, the update of network architecture, whether the leaf-spine architecture can adapt to the number of super nodes, whether Drangonfly can become the mainstream of the next-generation network architecture with the help of OCS, and whether Rail-only+ software optimization can mature, are all new highlights of the industry.
Industry Catalysis:
1. Scaling Law continues to be effective, cluster scale has been expanded, and communication network demand continues to rise.
2. Overseas AI positive cycle is accelerating, and Internet giants are accelerating capital expenditure competition.
Investment advice: Communication system core link: Zhongji Xuchuan, Xinyi Sheng, Tianfu Communication, Shanghai Electric Co., Ltd.
Communication system innovation link: Changfei Optical Fiber, Zhongtian Technology, Hengtong Optics, Centec Communication.
2.From the era of cloud computing to the era of AI, why is communication becoming more and more important?
The glory of the last round of communication can be traced back to the Internet era. The explosive demand for network traffic transmission allowed humans to build a switching system composed of massive servers, storage and switches for the first time. In this round of construction, Cisco stood out and became the leader of human technological progress. However, as the Internet wave tends to be peaceful, optical modules and switches fluctuate more with the macro economy, cloud spending, and product updates, and are more inclined to macroeconomic varieties. The changes in speed and technology are also relatively step-by-step, entering a period of cyclical fluctuations and upward steady-state development.
In the era of small models, the industry is more focused on algorithm innovation. Often the entire model volume can be borne by a single card, a single server or a relatively simple small cluster. Therefore, the network connection demand from the AI side is not prominent. But the emergence of large models has changed everything. OpenAI has proved that at present, the simpler Transformer algorithm can improve model performance by stacking parameters. Therefore, the entire industry has entered a period of rapid development with accelerated expansion of model size. Let us first look at two basic formulas that determine the model calculation speed, so that we can better understand why the computing power scale or the computing power hardware industry chain will benefit first in the era of large models. (1) Training time = training data scale x model parameter quantity / calculation rate (2) Calculation rate = single device calculation rate x number of devices x multi-device parallel efficiency In the current era of large models, we can see that the two factors on the numerator of training time are expanding at the same time. Under the condition of constant computing power, training time will be extended exponentially. In the increasingly fierce battlefield of giant models, time is the most precious resource. Therefore, the road to competition is very clear, and the only way is to accelerate the stacking of computing power.
In the second formula, we can see that with the increasing computing power, the computing power of a single card has degenerated from the whole to one of the links in the computing power composition due to the model volume and the upper limit of chip updates. The number of graphics cards and the parallel efficiency of multiple devices have also become two equally important links. This is also the reason why NVIDIA proactively acquired Mellanox, hoping to take the lead in every determinant of computing speed.
In our previous report "The ASIC Road of AI Computing Power-Starting from Ethereum Mining Machines", we elaborated on the various routes of single-card computing power in detail. This article will not repeat them. The latter two items we see, the number of devices and the parallel efficiency of multiple devices, are not simply achieved by stacking the number of graphics cards. The more devices there are, the more requirements for the reliability of the network structure and the degree of optimization of parallel computing will increase exponentially. This is also the ultimate reason why the network has become one of the important bottlenecks of AI. In this section, we will start from the training principle and explain why the stacking of devices and the increase in parallel sales are the most complex system engineering in human history.
2.1 Principles of multi-card cooperation in the era of large models, model parallelism and data parallelism
In model training, the process of splitting the model to multiple cards is not as simple as traditional pipeline or simple segmentation, but a more complex way to allocate tasks between graphics cards. In general, the task allocation method can be roughly divided into two types, model parallelism and data parallelism.
At the beginning, when the model size was small but the amount of data increased, the industry generally adopted the data parallel method. In data parallel computing, a complete model copy is retained on each GPU, and the training data is divided and entered into different graphics cards for training. After back propagation, the gradient of the model copy on each card will be reduced synchronously. However, as the model parameters expand, it is increasingly difficult for a single graphics card to accommodate the complete model. Therefore, in the training of top large models, data parallelism as a single parallel allocation method is gradually decreasing.
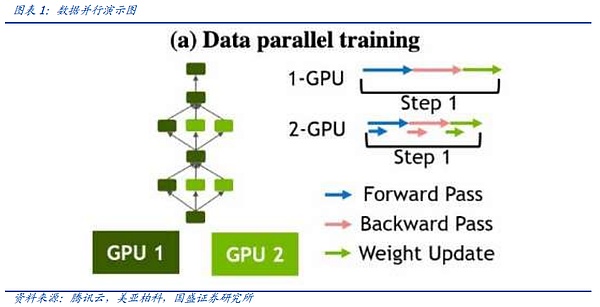
Model parallelism is a distribution method that is gradually emerging in the era of large models. Because the model is too large, different parts of the model are loaded into the graphics card, and the same data stream is fed into the graphics card to train the parameters of each part.
There are two mainstream modes of model parallelism, namely tensor parallelism and pipeline parallelism. In the underlying matrix multiplication of a model training operation (C=AxB), tensor parallelism means first splitting the B matrix into multiple vectors, each device holds a vector, and then multiplying the A matrix with each vector respectively, and then summarizing the results to summarize the C proof.
Pipeline parallelism is to divide the model by layer, and divide the model into several blocks by layer. Each block is handed over to a device. At the same time, in the forward propagation process, each device passes the intermediate activation to the next stage. In the subsequent backward propagation process, each device passes the gradient of the input tensor back to the previous pipeline stage.
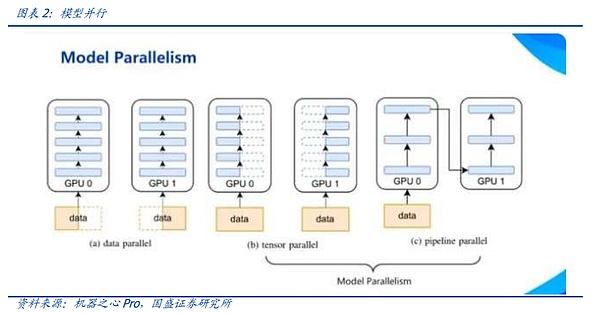
In the current large model training, no data parallelism can exist alone. In the head large model training, it is often necessary to mix the above-mentioned multiple technologies to achieve multi-dimensional hybrid parallelism. In actual connection, this AI cluster will be divided into several stages, each stage corresponds to a logical batch, and each stage consists of several GPU nodes. This meets the needs of multi-dimensional hybrid parallelism in architecture.
No matter what kind of parallel method is used, it is necessary to synchronize the parameters in each GPU through reverse broadcast after each round of calculation. Different parallel methods correspond to different broadcast delays, and also need to rely on different network protocols or communication media. From this we can see that the current network cluster construction is gradually evolving from "transmission" to a true "system engineering".
2.2 The core of multi-card interconnection in the era of large models: synchronization accuracy
An important function of AI network clusters is to align the results of the training of different graphics cards between computing units, so that the graphics cards can proceed to the next step. This work is also called reverse broadcast. Since the results are often processed by algorithms such as Reduce and Gather during the broadcast process, the global broadcast is called All to All. The All-to-All delay that we often see in AI cluster performance indicators refers to the time required for a global reverse broadcast.
In principle, it seems relatively easy to synchronize data through a reverse broadcast. It only requires each graphics card to send data to each other. However, in the construction of a real network cluster, many problems will be encountered, which makes shortening this delay a key direction pursued by various network solutions.
The first problem is that the time required for each graphics card to complete the current calculation is inconsistent. If the last graphics card in the same group is uniformly waited for to complete the task before reverse broadcasting, the graphics card that completed the task first will be idle for a long time, thereby reducing the performance of the entire computing cluster. Similarly, if an overly aggressive synchronization method is adopted, it is possible to cause errors during synchronization, resulting in training interruption. Therefore, a stable and efficient synchronization method has always been the direction pursued by the industry.
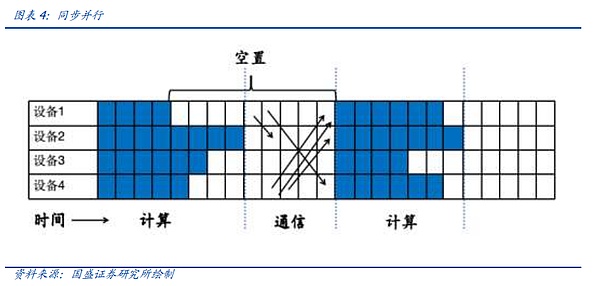
From the current point of view, the main synchronization methods can be divided into synchronous parallel, asynchronous parallel, All-Reduce, etc.
Let's first look at synchronous parallel. The idea of synchronous parallel has been mentioned in the previous article, that is, in the current unit, after all computing units complete the calculation, they will uniformly communicate once. Its advantages are stability and simplicity, but it will cause a large number of computing units to be idle. Take the following figure as an example. After computing unit 1 completes the calculation, it needs to wait for computing unit 4 to complete the calculation and wait for the collective communication time, resulting in a large number of vacancies and reducing the overall performance of the cluster.
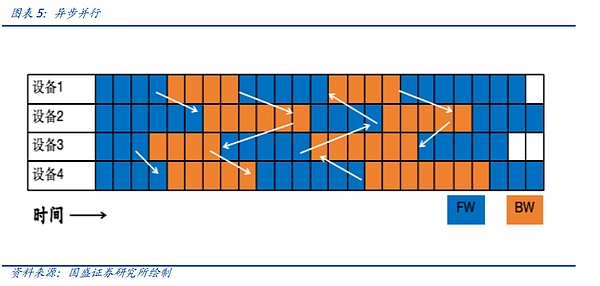
Asynchronous parallelism is the choice when facing non-generative large models such as interest promotion. When a device completes a round of forward and reverse calculations, it does not need to wait for the other device to complete the cycle, and directly synchronizes data. In this transmission mode, the network model training does not converge and is not suitable for large model training, but is more suitable for search models, recommendation models, etc.
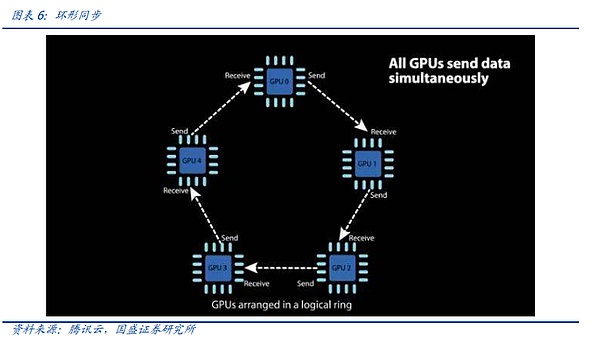
The third category, which is also the most commonly used category, All-Reduce or All-to-All-Reduce, is to summarize (Reduce) the information on all devices (All) to all devices (All). Obviously, direct All-Reduce will lead to a huge waste of communication resources, because the same data may be redundantly transmitted multiple times. Therefore, many optimized All-Reduce algorithms have been proposed, such as ring All-Reduce, binary tree-based All-Reduce, etc. These algorithms can greatly reduce the bandwidth and latency of All-Reduce.
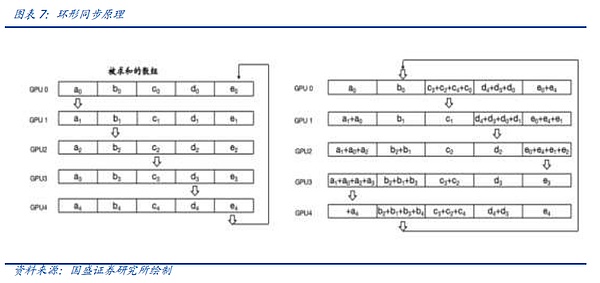
We take the Ring All-Reduce invented by Baidu, China's AI leader, as an example to illustrate how distributed computing engineers shorten the synchronization time through continuous iteration.
In Ring All-Reduce, each device only needs to communicate with two other devices, which is divided into two steps: Scatter-Reduce and All-Gather. First, multiple Scatter-Reduce operations are completed on adjacent devices, and each device obtains a part of the aggregated complete data. Subsequently, each device aligns with adjacent devices to complete multiple All-Gather operations to complete the complete data in each device. Ring All-Reduce can not only reduce bandwidth and latency, but also simplify the network topology and reduce the cost of building the network.
However, no matter what algorithm is used, it depends on the support of network communication hardware, whether it is supporting larger bandwidth from the chip native and protocol level, or switching from pure copper wire connection to NVLink, or the introduction of IB protocol, the explosion of RDMA demand is to meet the increasingly complex communication and synchronization needs, which we will expand on in the following text.
So far, we have a preliminary understanding of the principle-level logic of why AI needs high-density communication. First of all, the rapid switch from the era of small models to the era of large models has made multi-node clusters and distributed training a rigid demand. When splitting the model to different computing nodes for operation, how to split it and how to ensure synchronization are more complicated system engineering, and communication is the basis for the realization of all these software principles, high-quality, high-throughput, and high-stability communication components and communication networks.
2.3 System Engineering in the Era of Large Models: Monitoring-Summarizing-Innovation, Iteration is Always on the Road.
Above, we explained that the training principle determines the degree of dependence of large models on the communication system. Countless different and complex parallel and synchronization requirements together make up the data flow in AI clusters. Although the communication network is driven by such demands, the speed and product iteration are constantly accelerating, and the connection methods are constantly innovating, but to this day, there is still no perfect cluster that can solve all problems once and for all. At the same time, although the stability of the cluster is constantly optimized, breakpoints and interruptions still occur from time to time in a system composed of millions of precision components.
Therefore, the evolution direction of the large model communication system can be roughly divided into three. One is the monitoring capability of the large model system, which can perceive the data flow and operation status of the large model in real time, so as to detect faults in time. In this process, software and hardware packet capture based on network visualization has become the mainstream means. Through FPGA chips and special software, the data flow in the cluster is monitored, thus providing basic tools for perception.
Data packet capture implemented by software is the most commonly used. Well-known products at home and abroad include Wireshark (processing TCP/UDP), Fiddler (processing HTTP/HTTPS), tcpdump&windump, solarwinds, nast, Kismet, etc. Taking Wireshark as an example, its basic working principle is: the program sets the working mode of the network card to "promiscuous mode" (in normal mode, the network card only processes data packets belonging to its own MAC address, and in promiscuous mode, the network card will process all data packets flowing through), and Wireshark intercepts, retransmits, edits and transfers data packets.
Software packet capture will occupy part of the system performance. First, in promiscuous mode, the network card is in "broadcast mode" and will process all data packets sent and received by the lower layer of the network, which will consume part of the network card's performance; secondly, software packet capture is not serial or parallel capture at the link layer, but the data packets are copied and stored, which occupies part of the CPU and storage resources. At the same time, software like Wireshark can only monitor the traffic of a single network node in the system, and it is difficult to cover the global network. It is suitable for passive troubleshooting operations, but not for active risk monitoring.
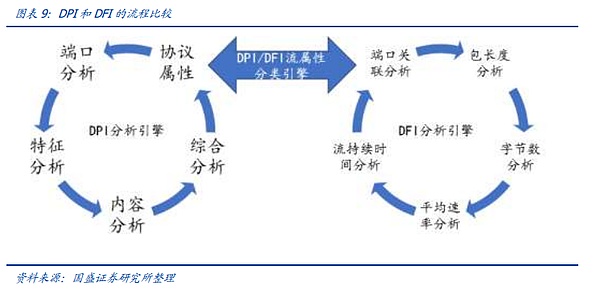
In order not to affect the overall performance of the system, parallel or serial access hardware and software combined tools came into being, and commonly used tools are DPI and DFI. DPI (Deep Packet Inspection) is a function that detects and controls traffic based on the application layer information of the message. DPI focuses on the analysis of the application layer and can identify various applications and their contents. When IP packets, TCP or UDP data streams pass through hardware devices that support DPI technology, the device will reassemble and analyze them by deeply reading the message payload to identify the content of the entire application, and then perform subsequent processing on the traffic according to the management policy defined by the device. DFI (Deep/Dynamic Flow Inspection) uses an application identification technology based on traffic behavior, that is, different application types are reflected in different states on session connections or data flows. DPI technology is suitable for environments that require fine and accurate identification and fine management; while DFI technology is suitable for environments that require efficient identification and extensive management.
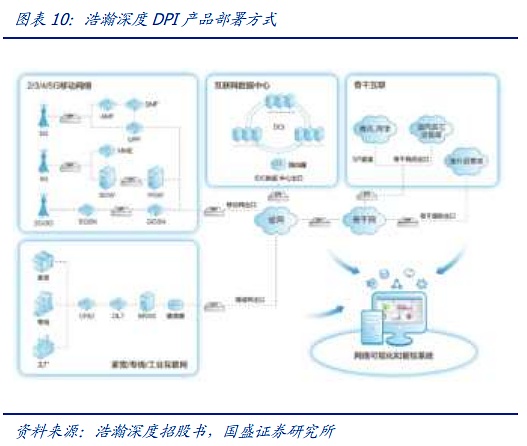
DPI/DFI is connected in series/parallel at the physical layer by independent hardware, which will not affect the performance of the physical layer. Taking Haohan Deepin's DPI software and hardware products as an example, it can be deployed at network nodes at all levels of the telecommunications network, and at the same time complete the data collection, analysis and presentation of monitoring nodes at all levels through SaaS/PaaS. DPI hardware is connected in series or parallel at the communication physical layer, and nearly lossless network monitoring is achieved through mirroring data packets. DPI software is embedded in DPI hardware, independent servers or switches/routers to achieve network monitoring.
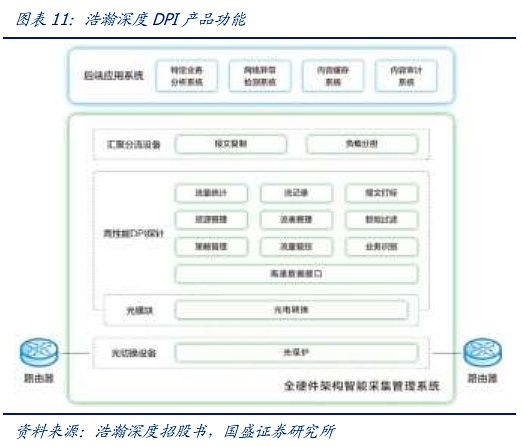
After solving the monitoring problem, the iterative path of large-scale model system engineering has a foundation. As mentioned earlier, in actual operation, what needs to be paid more attention to is the balance between system operation efficiency and stability. On the one hand, we have created new training methods and theories through the optimization of Reduce methods, innovation of parallel methods, etc., and the underlying innovation of distributed training. However, the underlying innovation always needs the support of related hardware. Switches with larger throughput, more suitable switching protocols, more stable and cheaper communication devices will always be an indispensable part of the upgrade of large-scale model systems.
3.Communication protocol competition and iteration: the right to speak for carrying AI data streams
In the previous chapter, we systematically explained the main roles of communication in AI clusters. In this section, we will systematically introduce the most basic part of the entire communication system - communication protocols.
Intuitively, the communication system is mainly composed of physical hardware such as switches, optical modules, cables, network cards, etc., but in fact, it is the communication protocol that flows inside the physical hardware that really determines the establishment, operation and performance characteristics of a communication system. Communication protocols are a series of agreements that must be followed by both parties in a computer network in order to ensure smooth and accurate data transmission. These agreements include data format, encoding rules, transmission rate, transmission steps, etc.
In the AI era, communication protocols are mainly divided into two categories. The first is the high-speed protocol used for communication between computing power cards inside computing power nodes. This type of protocol has the characteristics of fast speed, strong closedness, and weak scalability. It is often one of the core capability barriers of various graphics card manufacturers. Its speed, interface, etc. require support at the chip level. The second type of protocol is the protocol used to connect computing power nodes. This type of protocol has the characteristics of slow speed and strong scalability. There are currently two main mainstream protocols of the second type, the InfiniBand protocol and the RoCE protocol family under Ethernet. This type of protocol ensures the cross-node transmission capability of data and is also the basis for building super-large clusters. It also provides a solution for the intelligent computing unit to access the data center.
3.1 Intra-node communication - the core barrier of large manufacturers, the hope of "Moore's Law" of computing power
Intra-node communication, that is, the graphics card communication protocol within a single server, is responsible for the high-speed interconnection between graphics cards within the same server. To date, this protocol mainly includes three protocols: PCIe, NVLink, and Infinty Fabric.
Let's first look at the PCIe protocol with the longest history. The PCIe protocol is an open universal protocol. Different hardware in traditional server personal computers are connected through the PCIe protocol. In the computing power server assembled by a third party, the graphics cards are still interconnected through the PCIe slot and the PCIe line on the motherboard like traditional servers.
PCIe is the most widely used bus protocol. The bus is a pipeline for different hardware on the server motherboard to communicate with each other, which plays a decisive role in the data transmission speed. The most popular bus protocol is the PCIe (PCI-Express) protocol proposed by Intel in 2001. PCIe is mainly used to connect the CPU with other high-speed devices such as GPU, SSD, network card, graphics card, etc. In 2003, PCIe 1.0 version was released, and a new generation will be updated every three years. It has been updated to version 6.0, with a transmission rate of up to 64GT/s and a bandwidth of 16 channels reaching 256 GB/s. The performance and scalability are constantly improving.
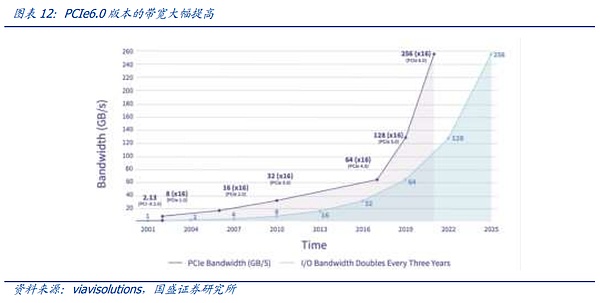
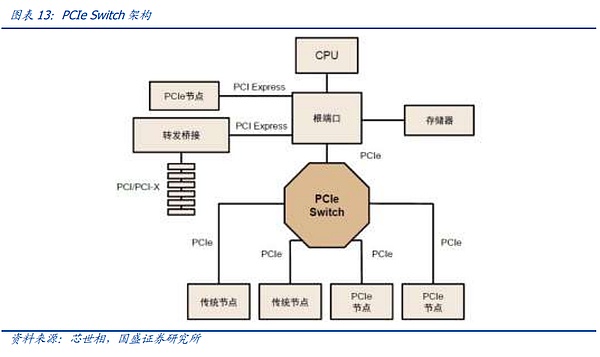
The tree topology and end-to-end transmission mode of the PCIe bus limit the number and speed of connections, and PCIe Switch is born. PCIe uses an end-to-end data transmission link. Only one device can be connected to each end of the PCIe link. The number of device recognition is limited, which cannot meet the scenarios where a large number of devices are connected or high-speed data transmission is required. Therefore, PCIe Switch was born. PCIe Switch has the dual functions of connection and switching, which allows a PCIe port to identify and connect more devices, solve the problem of insufficient number of channels, and connect multiple PCIe buses together to form a high-speed network to achieve multi-device communication. In short, PCIe Switch is equivalent to a PCIe expander.
However, as mentioned above, as the model scale gradually expands, and the synchronization cycle between NPUs becomes more and more complex, the low-speed PCIE that has not been specially optimized for the model operation mode can no longer meet the needs of the large model era. Therefore, the proprietary protocols of major graphics card manufacturers have rapidly emerged in the large model era.
We believe that the protocol with the highest industry attention and the fastest evolution is the NV-Link protocol, a high-speed GPU interconnection protocol proposed by NVIDIA. Compared with the traditional PCIe bus protocol, NVLINK has made major changes in three aspects: 1) Supporting mesh topology to solve the problem of limited channels; 2) Unified memory, allowing GPUs to share a common memory pool, reducing the need to copy data between GPUs, thereby improving efficiency; 3) Direct memory access, without the need for CPU participation, GPUs can directly read each other's memory, thereby reducing network latency. In addition, to solve the problem of unbalanced communication between GPUs, NVIDIA also introduced NVSwitch, a physical chip similar to a switch ASIC, which connects multiple GPUs at high speed through the NVLink interface to create a high-bandwidth multi-node GPU cluster.
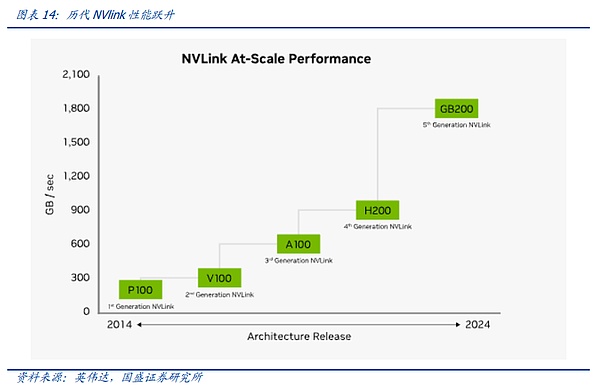
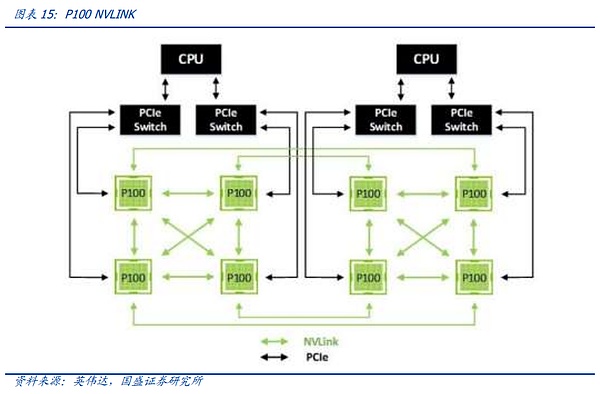
By reviewing the development history of NV-link, we can find that the NV-Link interconnection between nodes is gradually iterating with the changes in the synchronization requirements between graphics cards. The first generation of NV-Link appeared on the Pascal architecture. NVIDIA connected 8 card servers in a single server through high-speed copper wires on the PCB board and universal PCIE Switch. We can see from the connection method in the figure below that the 8 GPUs can use the shortest path to complete global data alignment by superimposing the external large ring of the graphics card and the internal X-shaped connection of four graphics cards, starting from any one of them.
However, with the expansion of the performance of a single graphics card, the improvement of throughput, and the increasingly complex synchronization methods between graphics cards, pure cable connections and fixed lines can no longer meet the communication needs between graphics cards. Therefore, in the Ampere architecture, which corresponds to the third generation of NVLINK, NVIDIA introduced the first generation of dedicated NV-Link Switch chips to further increase the speed and flexibility of NV-Link.

However, in the update from the Pascal architecture to the Ampere architecture, since customer demand at the time was still focused on small models and large-scale computing clusters did not appear, NV-LINK maintained a regular update rhythm, mainly through chip internal channel iterations and NV-Link Switch chip iterations to achieve rate updates. During this period, NVIDIA also launched the NV-Link bridge for gaming graphics cards to meet the needs of some high-end C-end users.

In the update from A100 to H100, NVIDIA took the first step in the evolution of NV-Link. When the demand for large models began to emerge, the huge data scale and model volume made it difficult for NV-Link interconnection, which used to be limited to 8 graphics cards, to cope with it. Users had to slice the model and load it into different servers for training and alignment. The slower communication rate between servers directly affected the effect of model training. We call the number of graphics cards that can be interconnected with the highest-speed communication protocol HB-DOMIN. In the process of increasingly large model parameters, HB-DOMIN has become a key factor in determining model training capabilities in the same generation of chips.
In this context, NVIDIA's NV-LINK has taken the first step in the evolution of the Hopper architecture, carrying more NV-LINK switch chips through an external dedicated switch, thereby expanding the HB-DOMIN of existing graphics cards. In the Hopper100 era, through the GH200 SuperPOD product, NV-LINK went out of the server for the first time and realized the interconnection of 256 graphics cards across the server.

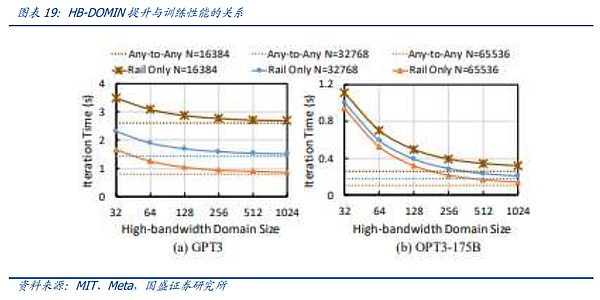
However, due to the low maturity of the corresponding NV-Link 3.0 switching chip under the Hopper architecture, NVIDIA needs a two-layer architecture to connect the graphics cards. Therefore, a large number of high-end optical modules are required in a GH200 256-card cluster, which is extremely costly and inconvenient for customers to purchase. At the same time, when GH200 was released, the parameters of the model had not yet expanded to the trillion level. According to the research results of Meta, under the trillion parameters, the marginal effect of HB-Domin expansion after exceeding 100 will accelerate and decrease.
In the Blackwell architecture era, NVIDIA officially perfected the expansion of NVLINK. With the release of the latest generation of 4NM NV-Link switching chips, NVIDIA launched the official flagship product GB200 NVL72. NVIDIA achieved the goal of achieving a cost-effective HB-DOMIN number at a relatively low cost through the connection of a single-layer NVlink+ copper cable inside a single cabinet, and truly took the first step in expanding the intra-node interconnection protocol to the upper layer.
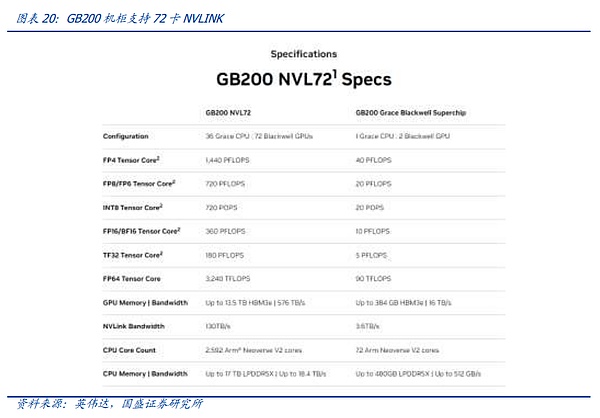
In addition to the latest generation of NV-LINK, we have once again re-recognized the importance of intra-node interconnection protocols. It can even be said that the expansion of intra-node communication has become the key to whether Moore's Law can continue in the computing era. The iteration of intra-node communication protocols and low-cost implementation are the best solutions to deal with the "communication wall" and "memory wall".
At present, NV-LINK's biggest competitor comes from AMD, NVIDIA's biggest competitor in the field of general graphics cards. Like NVIDIA, even AMD, which is the most supportive of network protocol openness, still uses its dedicated protocol "Infinity Fabric" in its intra-node interconnection field. But at the same time, unlike NVIDIA, AMD shared this protocol with the three Ethernet leaders Broadcom, Arista, and Cisco.

At present, the gap between Infinity Fabric and NVLINK is still large. In terms of dedicated switching chips, multi-card interconnection, and protocol completion, AMD still has a long way to go to catch up. This also reflects that the current competition for top general computing power has gradually expanded from the single link of chip design to the link of intra-node communication.
In summary, inter-node communication is becoming an increasingly important component of computing power. At the same time, with the expansion of HB-DOMIN, "computing power nodes" are also gradually expanding. We believe that behind this is the "upward penetration" of inter-node protocols in the entire AI cluster. At the same time, relying on the systematic compression of inter-node protocols and their carrying hardware is also a solution for the realization of Moore's Law for future AI computing power.
3.2 Inter-node communication protocol: timeless, the battle between closed and open
Now let's move our perspective outside the computing power node and take a look at the mainstream protocols that currently constitute the connection of the global computing power cluster. In today's computing power center, NPU is gradually moving towards a million-level scale. Even if the computing power nodes or what we call HB-DOMIN are expanding rapidly, the connection between nodes is still the cornerstone of the global AI computing power.
From the current perspective, the inter-node connection protocol is mainly divided into the InfiniBand protocol and the ROCE protocol family in the Ethernet family. The core of the interconnection between supercomputing nodes lies in the RDMA function. In the past, in traditional CPU-based data centers, the TCP/IP protocol was generally used for transmission, that is, after the data was sent from the memory of the sender, it was encoded by the CPU of the sender device, sent to the CPU of the receiving device, and then decoded and put into the memory. In this process, since the data passes through multiple devices and is encoded and decoded multiple times, a high latency will be generated, and latency is the most critical factor for synchronization between computing cards. Therefore, under the demand for interconnection between graphics cards, bypassing the CPU and realizing remote direct memory access (RDMA) between memories has become a rigid demand for AI cluster connections.
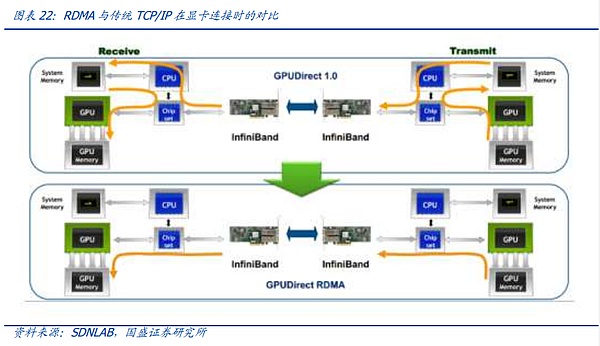
In this context, the ROCE protocol family that supports RDMA natively under the IB protocol Ethernet led by NVIDIA has become the only two options at present, and the distinctive characteristics of these two protocols make the competition between the entire node protocols extremely exciting.
The emergence of the IB protocol can be traced back to 1999, when the PCI bus with poor communication capabilities gradually became a bottleneck for communication between various devices. Against this background, Intel, Microsoft, IBM, and several other giants, FIO Developers Forum and NGIO Forum, merged to create the InfiniBand Trade Association (IBTA), and launched the first version of the IB protocol framework in 2000. Mellanox, a switching chip company founded in 1999, also joined the IB camp.
From the beginning of its creation, IB has pioneered the concept of RDMA, which can bypass the limitations of the PCI bus and access at a higher speed, but the good times did not last long. In 2022, giants such as Intel and Microsoft announced their withdrawal from the IB alliance and turned to the research and development of the PCIE protocol mentioned above, and IB has therefore declined. But in 2005, with the rising demand for communication between storage devices, IB ushered in a new period of growth. Later, with the construction of supercomputers around the world, more and more supercomputers began to use IB for connection. In this process, relying on its unswerving commitment to IB and related acquisitions, Mellanox expanded from a chip company to the entire field of network cards, switches/gateways, remote communication systems, cables and modules, becoming a world-class network provider. In 2019, Nvidia defeated Intel and Microsoft with a bid of US$6.9 billion and successfully acquired Mellanox.

On the other hand, Ethernet released the RoCE protocol in 2010 to implement RDMA based on the Ethernet protocol, and proposed the more mature RoCE v2 in 2014.
Since entering the era of large models, global data centers have rapidly turned to intelligent computing, so major new investment equipment requires support for RDMA connection methods. However, the current competitive landscape has changed from the previous competition between RoCE V2 and IB. Due to NVIDIA's absolute leading position in the global graphics card field, NVIDIA graphics cards are more adaptable to IB, the most obvious of which is reflected in the Sharp protocol deployed by Mellanox switches.
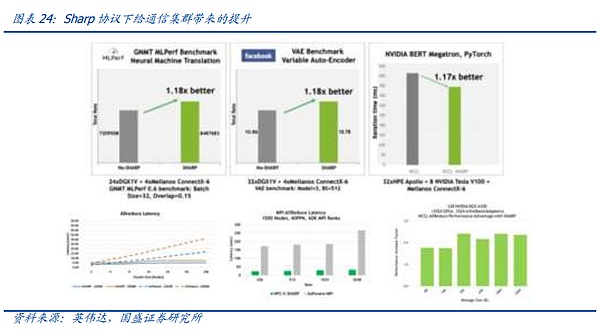
Since in AI computing, a large amount of complex Reduce communication is required between graphics cards, as mentioned above, this is also the core problem that needs to be solved in AI communication system engineering. In Mellanox switch products, with the help of NVIDIA, the company innovatively integrated the computing engine unit in the switching chip, which can support related Reduce computing, thereby helping GPUs reduce load, but related functions require the cooperation of GPU manufacturers.
It can be seen that the core of the communication protocol dispute in the AI era has become a dispute over the right to speak for graphics card manufacturers. At present, the IB protocol has a good competitive advantage with the support of NVIDIA, while traditional Ethernet manufacturers are slightly weak in some functions due to the lack of a powerful chip support. However, the emergence of the Super Ethernet Alliance led by AMD is expected to gradually reverse this situation.

On July 19, 2023, AMD, Broadcom, Cisco, ARISTA, Meta, Microsoft and other leading manufacturers from computing chips, network side and user side jointly established the Super Ethernet Alliance. We believe that the purpose of the establishment of the Super Ethernet Alliance is to be able to build a completely open, more flexible and performance-surpassing IB network protocol on the basis of Ethernet, so as to compete with IB.

AMD, as a core member of the Super Ethernet Alliance, stated at the Mi300 series launch conference that the back-end connection of its graphics cards will unconditionally use Ethernet, and the Infinity Fabric protocol used for intra-node interconnection will also be open to Ethernet manufacturers. We believe that as the cooperation progress between AMD and members such as Broadcom in the UEC Alliance gradually accelerates, the UEC Alliance is also expected to truly form a compatibility and cooperation system similar to N card + IB, thus bringing challenges to NVIDIA. However, the process is destined to be long. From catching up with the computing power of single cards on the AMD side, to the progress of switching chips on the Broadcom side, and then to the openness and cooperation between different manufacturers, there is still a long way to go.
In summary, the dispute over inter-node communication protocols has gradually evolved from a dispute over principles to a dispute over discourse power. Which protocol to use is more of an extension of GPU discourse power. NVIDIA hopes to expand its discourse power in all links through IB, while customers hope to embrace a more open IB. Industry competition will continue to drive the continuous evolution of communication protocols.
4. Where will network hardware innovation go under the impetus of AI?
In the previous section, we discussed how AI demand drives the evolution and expansion of RDMA functions. Similarly, in the field of network hardware, AI's new demands are also bringing other changes in addition to rate updates, from transmission media, switches, network architecture to the overall form of data centers.
4.1 Where will the battle of transmission media go?
In recent years, with the rapid expansion of human data and the exponential increase in transmission rates, we have taken the lead in welcoming the wave of optical fiber replacing copper in the telecommunications side such as wireless networks and fixed networks. From the earliest dial-up Internet access, to fiber-to-the-home and even the current FTTR, optical fiber and optical cables have gradually replaced copper wires.
Inside the data center, the process of optical fiber replacing copper is also underway. Communication systems composed of optical modules, AOCs and other optical communications are gradually replacing copper transmission systems composed of DACs, AECs and other components. Behind this is the inevitable physical law that copper media attenuation becomes more and more severe under high-speed transmission. If there were no diverse demands brought by AI, as the server network port rate increases from generation to generation, optical transmission would gradually penetrate into the cabinet and eventually form an all-optical data center.
However, the emergence of AI has brought some twists and turns to the process of "optical fiber advances and copper fiber retreats", or caused some confusion in the market. The core reason behind this is that AI has brought non-generational linear growth in the complexity and cost of communication systems. In the face of exponential demand growth, high-speed optical modules have become increasingly expensive. Therefore, the more cost-effective copper cables are gradually becoming more attractive at the current rate. At the same time, with the improvement of supporting components such as heat dissipation, graphics card manufacturers are able to compress as many computing units as possible into a single cabinet that can be reached by copper cables.

From the back, it is not difficult to find that in the AI era, due to the increase in expenses, in the current 2-3 years, the core of the optical fiber and copper competition has changed from rate upgrade to cost first. At the same time, due to the accelerated increase in the complexity of the communication system, simplicity and low failure rate have also become key considerations for customers to choose media.
Long-distance cross-server transmission: optical modules are the only solution, and cost reduction and simplification are the directions of innovation.
Due to the transmission distance limitation of copper cables, the so-called "optical retreat and copper advance" can only occur in short-distance transmission. When facing a transmission distance of more than 5 meters, that is, when transmitting across servers or computing nodes, optical transmission is still the only choice. However, at present, in addition to caring about conventional rate upgrades, customers are increasingly concerned about costs and failure rates (device complexity), which has also driven the future upgrade direction of the optical communication industry.
LPO/LRO: LPO replaces traditional DSPs with linear direct drive technology, integrates its functions into the switching chip, and leaves only the driver and TIA chips. The performance of the TIA and driver chips used in the LPO optical module has also been improved, thereby achieving better linearity. LRO is a transitional solution that uses traditional optical modules at one end and LPO optical modules at the other end, making it more acceptable to customers.
Silicon photonics: Silicon photonics uses mature technology to automatically integrate discrete devices in the optical engines of some optical modules on silicon-based chips, thereby achieving significant cost reduction. At the same time, automated production and process updates can also help silicon photonic chips to iterate. We believe that LPO and silicon photonics are the two fastest-progressing cost-reduction innovation solutions in the industry.
Thin-film lithium niobate: Lithium niobate material is the best choice for the electro-optic coefficient among reliable materials (considering Curie point and electro-optic coefficient). The thin-film process shortens the electrode distance, reduces the voltage and improves the bandwidth-to-voltage ratio. Compared with other materials, it has many of the most needed advantages for optoelectronics, such as large bandwidth/low loss/low driving voltage. At present, thin-film lithium niobate is mainly used for high-speed silicon photonic modulators. We believe that the use of thin-film lithium niobate modulators can achieve better performance at 1.6T and 3.2T.
CPO: CPO refers to packaging the optical module directly on the switch motherboard, so that the heat dissipation of the switch motherboard can be shared, and the distance that the electrical signal is transmitted on the switch motherboard can be shortened. However, at present, since the optical modules in the AI center are fragile, it is difficult to maintain them after co-packaging, so the degree of customer recognition of CPO remains to be seen.
Connection within the cabinet: With the dual advantages of cost and stability, copper wire is an advantageous choice in the medium and short term. As the long-term rate increases, optical fiber will enter and copper will retreat.
DAC: Direct Attach Cable, which is a high-speed copper cable, can adapt to ultra-high-speed connections within a shorter distance. The current mainstream 800G DAC in the market is less than 3 meters long, which is a cost-effective connection solution within the cabinet.
AOC: Active Optical Cables, which is a system composed of optical modules and optical fibers that are pre-assembled at both ends. Its transmission distance is shorter than that of traditional multi-mode or single-mode optical modules, but the cost is also lower. It is a short-distance connection option within the cabinet after exceeding the transmission limit of copper cables.
Regarding the evolution of silicon, the current mainstream ideas mainly include chiplet and wafer-scaling. The core ideas of these two methods are to expand the number of computing units that a single chip can carry through more advanced semiconductor manufacturing and design processes, and to develop as many communications as possible within a single silicon chip to maximize computing efficiency. We have introduced this part in detail in the previous in-depth "The Road to ASIC of AI Computing Power - Starting from Ethereum Mining Machines", so we will not repeat it in this article.
In general, the replacement and competition of transmission media follow the demand, and the current demand is very clear. Under new training frameworks such as MOE, model parameters are heading towards a trillion scale. How to cost-effectively achieve a stronger single-node computing power, or expand the number of "HB-DOMIN" domains, so that the model does not need to be segmented too finely, resulting in reduced training efficiency, whether it is light, copper or the bottom silicon, they are constantly working on this route.
4.2 Innovation of switches: Optical switches are just starting out
Switches as the core of the network
As the core node of the network, switches are the core components that carry communication protocols. In today's AI clusters, switches also take on increasingly complex tasks. For example, the Mellanox switch mentioned above has the function of partial alignment operations through the SHARP protocol to help accelerate AI operations.
On the other hand, although today's electrical switches are becoming more powerful and the speed of updates and iterations remains stable, pure optical switching seems to be becoming a new trend. We believe that there are two main reasons behind the trend of optical switches. First, the giantization of AI participants. Second, the accelerated expansion of AI clusters.
Compared to electrical switching systems, optical switching systems remove electrical chips and use optical lenses to refract and distribute the optical signals transmitted into the switch, so that they are not converted and transmitted to the corresponding optical modules. Compared with electrical switches, optical switches save the process of photoelectric conversion, so power consumption, latency, etc. will be lower. At the same time, since they are not restricted by the capacity limit of electrical switch chips, the number of network layers and the number of units that a single switch can cover are also increased. On the contrary, the use of optical switches requires a specially designed network architecture to adapt to them. At the same time, once the cluster of optical switches is established, it cannot be expanded in a scattered manner, and can only expand the entire network cluster at one time, and the flexibility is also poor. In addition, at the current stage, there is no universal version of optical switches, and self-developed or customized design is required, which has a high threshold.
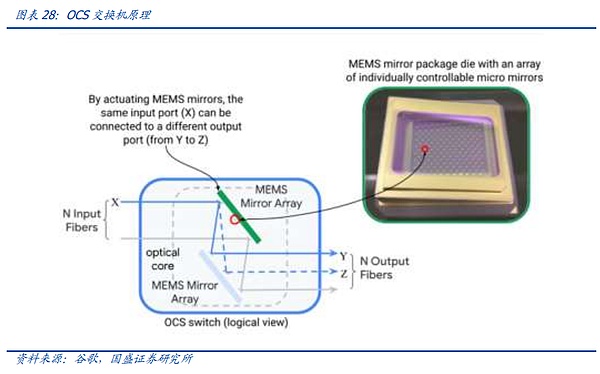
However, as the AI competition officially enters the second half of the giants' battle, the scale of AI clusters owned by giants is rapidly expanding. Giants have mature investment plans, self-developed network architecture capabilities, and sufficient funds. Therefore, as the node scale continues to expand, giant customers such as Google are accelerating the development and deployment of OCS systems.
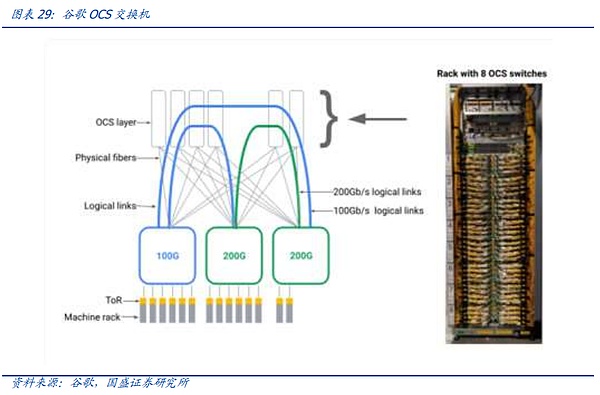
Returning to the traditional electrical switching part, the innovation of today's electrical switches, in addition to the protocol part mentioned above, is more focused on the chip part, including process iteration, functional innovation, etc. At the same time, switch manufacturers such as Broadcom, relying on the use of their own IP in different downstream customer chips, have made their own binding with customers stronger. Combined with the team on the communication protocol, in the AI era, the switch industry has officially become an all-round competition between chip alliances.
4.3 Innovation in network architecture: Where to go after leaf spine?
Network architecture is an important component of the communication system outside of protocols and hardware. The architecture determines the path of data transmission in the server. At the same time, an excellent network architecture can make data traffic accessible across the entire domain while reducing latency and ensuring stability. At the same time, the network architecture also needs to meet the requirements of easy maintenance and expansion. Therefore, architecture is an important part of the communication system from paper design to physical engineering.
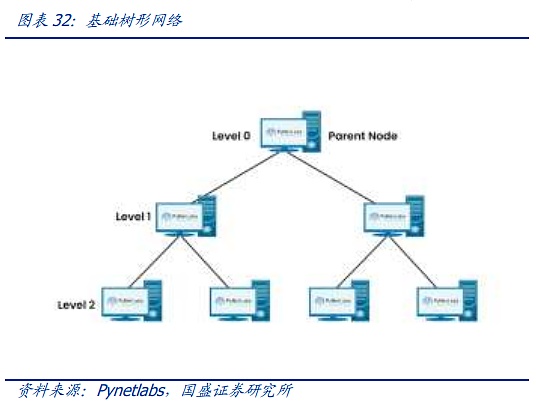
The network architecture of modern society, from the matrix diagram structure of the telephone era to the ClOS network model, lays the foundation for the modern network. The core of the CLOS architecture is to use multiple small-scale, low-cost units to build complex, large-scale networks. Based on the CLOS model, various network topologies have gradually developed, such as star, chain, ring, tree, etc. Subsequently, the tree network has gradually become the mainstream architecture. The tree architecture has evolved through three generations. The first generation is the most traditional tree architecture. The characteristic of this tree architecture is that the bandwidth is strictly converged at 2:1 after each layer. That is, after two 100M downstream devices are connected to the switch, a fixed 100M data stream is output. This architecture can still cope with the smaller data streams before the advent of cloud computing. However, with the advent of the Internet and the cloud computing era, the bandwidth that converges step by step cannot meet the traffic transmission requirements. Therefore, an improved architecture called "fat tree" is gradually used in data centers. The fat tree architecture uses a three-layer switch. Its core concept is to use a large number of low-performance switches to build a large-scale non-blocking network. For any communication mode, there is always a path to make their communication bandwidth reach the network card bandwidth, but more advanced switches are used at the upper layer to keep the top-level switching at a low convergence ratio as much as possible.
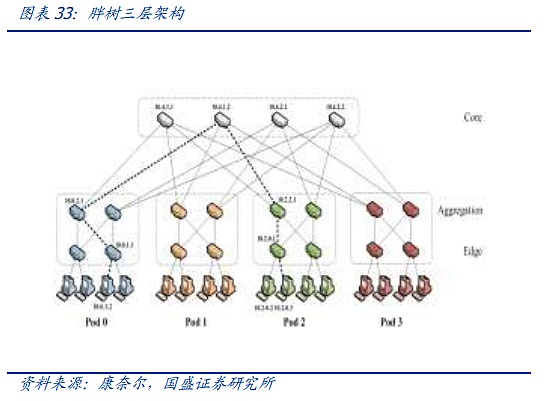
The "Fat Tree" architecture lays the foundation for the connection of modern data centers, but it also has problems such as bandwidth waste, difficulty in expansion, and difficulty in supporting large-scale cloud computing. Faced with the increasingly large scale of the network, the defects of the traditional fat tree are becoming more and more obvious.
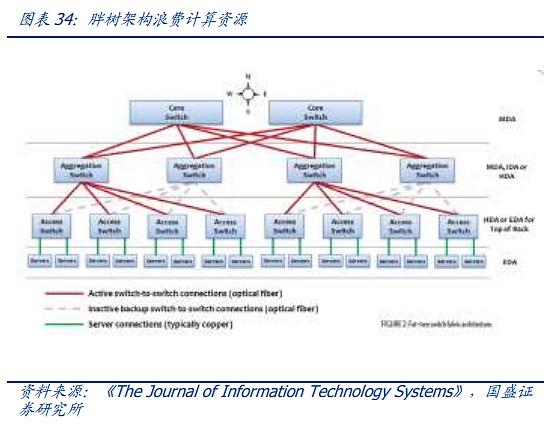
Based on the fat tree, the Spine-Leaf architecture used in today's advanced data centers and AI clusters has evolved. Compared with the fat tree, the Spine-Leaf architecture emphasizes flatness. Compared with the complicated three-layer fat tree, each low-level switch (leaf) is connected to each high-level switch (spine) to form a full-mesh topology. The leaf layer is composed of access switches, which are used to connect servers and other devices. The spine layer is the backbone of the network, responsible for connecting all the leaves. In this configuration, the data forwarding between any two physical servers passes through a fixed number of nodes, one leaf and one spine switch, which ensures the carrying capacity and latency of east-west traffic. The expansion of the spine switch also avoids the use of a large number of extremely expensive core switches. At the same time, the entire network can be expanded by increasing the number of spine switches at any time.
At present, leaf-spine has become the standard architecture of mainstream AI clusters and head data centers due to its many advantages. However, with the rapid expansion of the number of nodes in a single AI cluster and the extreme pursuit of latency during AI training, some problems of the fat tree architecture have begun to emerge. We, First, when the scale expands rapidly, can the update of the switch capacity limit meet the speed of evolution of the graphics card cluster? Second, is the leaf-spine still cost-effective when facing the interconnection of millions of computing nodes?
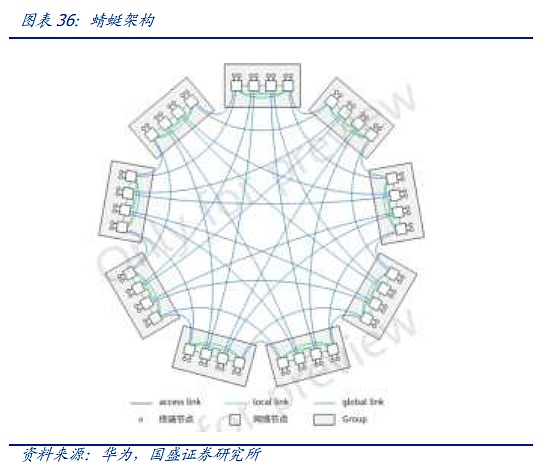
The above two problems of the leaf-spine architecture also lead to innovation at the network architecture level. We believe that innovation is mainly concentrated in two directions. First, pursue new architectures under ultra-large node numbers. Second, reduce the traffic communication between nodes based on a full understanding of the model by expanding HB-DOMIN and superimposing software optimization.
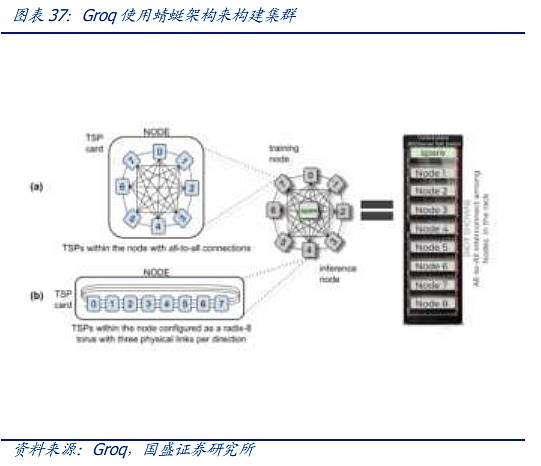
One of the representatives of the first solution is the Dragonfly architecture. The Dragonfly architecture was first proposed in 2008 and was first used in HPC. However, since each expansion requires rewiring and the wiring is relatively complex, even though it uses fewer switches than the CLOS architecture, it ultimately failed to become mainstream. However, in the context of massive nodes and expensive capital expenditures for AI hardware, the Dragonfly architecture is gradually beginning to attract attention from the forefront of the industry again. At present, with the emergence of the OCS optical switching system mentioned above, complex wiring is expected to be simplified through OCS, and the second giant has a clearer planning and capital expenditure rhythm for AI clusters, so the relatively cumbersome expansion process of dragonfly is no longer a constraint. Third, dragonfly has more advantages in latency than leaf spine at the physical level. Currently, AI chips that are more sensitive to latency, such as Groq, have begun to use this architecture to build clusters.
One of the representatives of the second solution is the Rail-only architecture proposed by Meta and MIT. The Rail-Only architecture groups GPUs into a high-bandwidth interconnect domain (HB domain), and then cross-connects specific GPUs in these HB domains to specific Rail switches. Although the routing scheduling complexity of cross-domain communication is increased, the overall architecture can greatly reduce the use of switches through reasonable HB domain and Rail switch design, and can reduce network communication costs by up to 75%. This architecture also implicitly coincides with the innovation of inter-chip communication mentioned above. Through the expanded HB-DOMIN domain, more implementation space is given to training segmentation and software optimization, thereby reducing the demand for switches between HB-DOMINs and providing space for network cost reduction of super-large clusters.
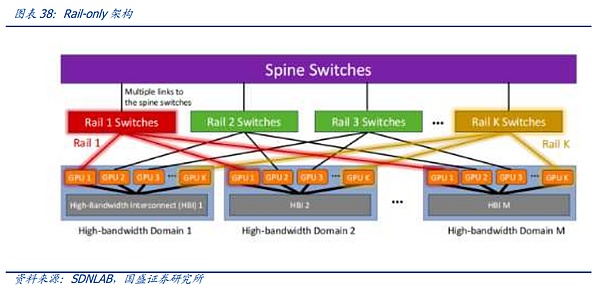
4.4 Innovation of Data Center Clusters: The Ultimate Form of Future Computing Networks?
As the scale of AI clusters continues to expand, the capacity of a single data center will eventually reach its upper limit. The upper limit here does not refer to the capital expenditure or the upper limit of the nodes that the communication network can carry, but the power resources where the data center is located or the cost-effective power resources carrying capacity will reach the upper limit.
In early 2024, Microsoft and OPENAI began to discuss the construction of a supercomputer "Stargate" in 2028. According to The Information, the final overall plan of Stargate may involve an investment of more than $1,000 and require the use of up to 5 gigawatts of electricity. This will also become one of the most urgent problems that the project needs to solve in addition to chips and funds.
Therefore, at the forefront of the current industry, how to use long-distance interconnection between intelligent computing centers to evenly distribute computing power in areas with cost-effective electricity, and avoid rising computing power costs or computing power capacity limits caused by excessively high prices in a single area. Compared with the internal interconnection system of the cluster, the interconnection between data centers uses very different protocols, hardware, etc.
Current data centers are usually connected to the external network through upper-layer switches or core switches, and data center Internet DCI is often built by operators. It uses long-distance coherent optical modules. Although the transmission rate is longer, its rate and stability are significantly different from those of the optical modules used in data centers. At the same time, its price remains high, so cost reduction and rebuilding the architecture are issues that need to be considered before formal construction.
However, if we take a more macro perspective, a single computing center is essentially similar to an HB-DOMIN domain mentioned above and has more powerful functions. Therefore, we believe that the future development path of this type of connection is, on the one hand, to accelerate investment in the coherent optical module industry so that it can bear the carrying and capacity requirements of AI center interconnection, on the other hand, to strengthen the interconnection density within the data center and make the data center more similar to a single HB domain. Finally, it is to innovate distributed software and training software so that it can perform data and model segmentation and parallelism across IDCs.
5. Investment advice:Innovation never stops, and both core links and new variables should be grasped
Like chips, driven by the demand for AI, communication systems are also constantly accelerating innovation. However, unlike the chip industry which often relies on one or two "geniuses" to innovate architecture and ideas, communication software and hardware is a system engineering that requires many engineers to innovate and work together in different links, from the most basic switching chips and optical chips, to the switches and optical modules integrated in the upper-level system, to the design of communication architecture and communication protocols, and then to the operation and maintenance after the system is formed. Each link corresponds to different technology giants and countless engineers.
We believe that compared to the chip industry, which is more inclined towards venture capital, investment in the communications industry is more traceable. The changes in the industry are often initiated and implemented by giants. At the same time, due to the stability requirements of communication system engineering, the selection of suppliers for large AI clusters is often very strict. First of all, in the hardware link, no matter how the network architecture and protocols change, switches and optical modules will always be the most basic building blocks of the system. As long as the Scaling-Law is always effective, the process of human pursuit of parameters will still exist, and the demand for building blocks will continue. It is true that LPO, dragonfly architecture, and rail-only architecture will indeed reduce the proportion or value of related devices, but cost reduction has always been the number one priority of AI. The demand expansion brought about by cost reduction will bring a broader space to the industry. This is the core concept and link that AI communication investment needs to grasp first.
At the same time, for the innovation link, we must also actively track the dynamics of new technologies and find out the changes in components in the core links brought about by the replacement of new technologies. Looking to the future, first of all, the demand for copper cables brought about by the cost-effective HB-DOMIN domain construction will be the first to increase in volume, followed by CPO, long-distance data centers, such as polarization-maintaining fiber, erbium-doped fiber and other special optical fiber demand, and finally all-optical switches, Hyper Ethernet Alliance, etc. bring about the accelerated evolution of domestic switches.
6. Risk Warning
1. AI demand is lower than expected.
At present, AI is still in the model development stage, and specific C-end product development is still in progress. If the subsequent C-end demand is not as expected, there is a risk of a decline in global AI demand.
2. Scaling law is invalid.
The main basis for the current global computing power expansion is that the law of continuously stacking parameter scales through computing power to make the model better still works. If the parameter stacking reaches the upper limit, it will affect the computing power demand.
3. Intensified industry competition.
The global computing power industry and the network industry are developing rapidly under AI. If too many new entrants are attracted to participate in the competition, the profits of existing leading companies will be diluted.


 XingChi
XingChi


