NYDIG: Germany, Mt. Gox, and miners selling have caused BTC's decline to be exaggerated
NYDIG’s Greg Cipolaro said recent blockchain moves have stoked “irrational” fears, providing investors with a buying opportunity.
 JinseFinance
JinseFinance

In 2022, I (anna) wrote a proposal for a user-owned base model that is trained with private data rather than data scraped publicly from the internet. I argued that while base models can be trained with public data (e.g. Wikipedia, 4Chan), to take them to the next level you need high-quality private data that only exists in siloed platforms that require permissions or login to access (e.g. Twitter, personal messages, company information).
This prediction is starting to come true. Companies like Reddit and Twitter have realized the value of their platform data, so they have locked down their developer APIs (1, 2) to prevent other companies from freely using their text data to train base models.
This is a huge change from two years ago. Venture capitalist Sam Lessin summed up this change: “[Platforms] just throw this garbage in the back, nobody’s watching, and then all of a sudden you’re like, oh, damn, that garbage is gold, right? We got a lot of it. We have to lock up our garbage bins.” For example, GPT-3 was trained on WebText2, which aggregates the text from all Reddit submissions with at least 3 upvotes (3, 4). With Reddit’s new API, this is no longer possible. As the internet becomes less open, isolated platforms build larger walls to protect their valuable training data. While developers can no longer access this data at scale, individuals can still access and export their own data across platforms due to data privacy regulations (5, 6). The fact that platforms lock down developer APIs, while individual users can still access their own data, presents an opportunity: could 100 million users export their platform data to create the world’s largest treasure trove of data? This trove of data will aggregate all the user data collected by large tech companies and others, which they are often reluctant to share. It will be the largest and most comprehensive training dataset to date, 100 times larger than the datasets used to train today’s leading base models. 1
Rough estimate comparing base model training datasets to example user datasets. Sources and calculations.

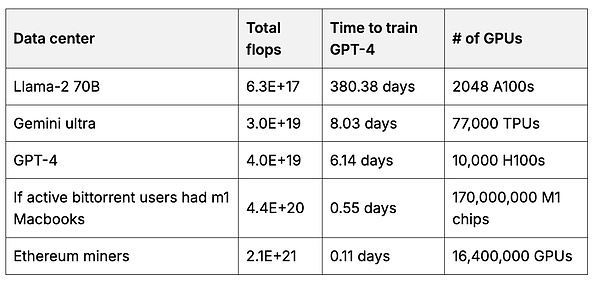
Users can then create a user-owned base model that uses more data than any one company could aggregate. Training the base model requires a lot of GPU compute. But each user can help train a small part of the model with their own hardware, and then merge the parts together to create a larger, more powerful model (7, 8, 9). 2When the incentives are right, users can pool large amounts of computation. For example, Ethereum miners collectively use 50 times as much computation as is used to train the leading base model.
Estimates of the total floating point operations (floating point operations per second = the sum of the “thinking” speeds of all GPUs combined) in data centers used to train the base model compared to Ethereum miner GPUs. 3Source with computation.
Users who contribute to the model will collectively own and govern it. They can get paid when they use the model, and even be paid in proportion to how much their data improves the model. The collective can set the rules for use, including who can access the model and what kind of controls should be in place. Maybe users in each country will create their own models, representing their ideology and culture. Or maybe one country isn’t the right dividing line, and we’ll see a world where every networked nation has its own base model based on its members’ data. I encourage you to take the time to think about what parts of the base model you’d like to own, and what training data you can contribute from the platforms you use. You probably have more data than you realize — your research papers, your unpublished artwork, your Google Docs, your dating profiles, your medical records, your Slack messages. One way to bring this data together is through a personal server, which makes it easy to use your private data with your local LLM. In the future, your personal server could also train a portion of the base model on users you own. Base models tend to be monopolistic because they require large upfront investments in data and compute. It’s tempting to choose the easy option: use open source models that are a few generations behind, the remnants of the big AI companies, as best we can. But we shouldn’t be content to be a few generations behind and eat the leftovers! As users, we should create our own best models — and we have the data and computing power to make that happen.
As AI becomes increasingly capable of doing valuable economic work, a massive economic shift is happening. Big tech companies have already trained AI models based on your public work, writing, artwork, photos, and other data, as well as other people’s data, and are starting to make billions of dollars a year (1). They are now going after your data that’s not available on the public internet, buying your private data from companies like Reddit so they can grow their AI revenue to trillions of dollars a year (2, 3).
That’s where Data DAOs come in. A Data DAO is a decentralized entity that allows users to pool and curate their data, and rewards contributors with dataset-specific tokens that represent ownership of a particular dataset. It’s a bit like a union for data. These datasets can replicate or even surpass datasets sold by large tech companies for hundreds of millions of dollars (4). The DAO has full control over the dataset and can choose to rent it out or sell anonymous copies. For example, Reddit data could even be used to seed new, user-owned platforms, with friends, your past posts, and other data readily available on new platforms. If you’re interested in the technical details: Data DAOs have two main components: 1) on-chain governance, where tokens are earned through data contributions, and 2) secure servers, encrypted using public-private key pairs, where community-owned datasets reside. To contribute, you first verify the data to prove ownership and estimate its value. The data is then encrypted in your browser using the server’s public key, and the encrypted data is stored in the cloud. The data is only decrypted when the DAO approves a proposal to grant access. For example, it could allow AI companies to rent data to train models. You can read more about the architecture of the Vana Network, which aims to enable collective ownership of datasets and models, here.
Data DAOs not only benefit users, they advance AI by making it possible to build AI like open source software, benefiting everyone who contributes. Open source AI is struggling to find a viable business model: paying for GPUs, data, and researchers is expensive. And once a model is trained, there is no way to recoup those costs if it is open source. The technical architecture of a Data DAO can be applied to a Model DAO, where users and developers can contribute data, compute, and research in exchange for ownership of the model.
The default option in society today is to allow big tech companies to take our data and use it to train AI models that work for us. They profit from these AI models because we are replaced by models trained with our data. This is a very bad deal for society, but a good deal for big tech companies. The only way to prevent this from happening is to take collective action. Data is currency, and collective data is power. I encourage you to get involved: the world's first Data DAO focused on Reddit data went live today on the Vana Network. By breaking down the data moat controlled by the privileged few, Data DAOs open a path to a truly user-owned internet.
NYDIG’s Greg Cipolaro said recent blockchain moves have stoked “irrational” fears, providing investors with a buying opportunity.
JinseFinanceLedger users protest against social media censorship.
 Beincrypto
BeincryptoReddit released a limited quantity of free Rabbids avatar NFTs and users are scooping them up, with multiple varieties already depleted.

Over 3 million Reddit Vault wallets have been created.
BeincryptoThe miner used almost 30 million gwei to pay for that transaction.
 Coindesk
CoindeskChina banned crypto trading and mining last year.
CoindeskBeincryptoThe company said that the project is set to utilize the Polygon (MATIC) blockchain for decentralized trading and third-party sales.
 Cointelegraph
CointelegraphPopular social media platform Reddit will launch a new feature called Collectible Avatars. These blockchain-backed items are non-fungible tokens (NFTs) ...
 Bitcoinist
BitcoinistData shows Bitcoin miner revenues have been coming under stress recently as they are now making 61% less than the ...
Bitcoinist