Nguồn: Machine Heart
Sau khi đột ngột tuyên bố chấm dứt hợp tác với OpenAI vào tháng 2, công ty khởi nghiệp về robot nổi tiếng Figure AI đã tiết lộ lý do đằng sau quyết định này vào tối thứ năm: họ đã tạo ra mô hình trí thông minh tổng quát Helix của riêng mình.

Helix là mô hình thị giác-ngôn ngữ-hành động (VLA) tổng quát thống nhất nhận thức, hiểu ngôn ngữ và khả năng điều khiển đã học để vượt qua nhiều thách thức lâu đời trong lĩnh vực robot.
Helix đã tạo ra nhiều sản phẩm đầu tiên:
Điều khiển toàn thân: Đây là mô hình VLA điều khiển liên tục tốc độ cao đầu tiên của phần thân trên của rô-bốt hình người trong lịch sử, bao phủ cổ tay, thân, đầu và từng ngón tay;
Hợp tác nhiều rô-bốt: Hai rô-bốt có thể hợp tác với một mô hình để hoàn thành các nhiệm vụ chưa từng có;
Nắm bắt bất kỳ vật thể nào: Nó có thể nhặt bất kỳ vật thể nhỏ nào, bao gồm hàng nghìn vật thể mà chúng chưa từng gặp trước đây, chỉ bằng cách làm theo các hướng dẫn bằng ngôn ngữ tự nhiên;
Mạng nơ-ron đơn: Helix sử dụng một tập hợp các trọng số mạng nơ-ron để học mọi hành vi - cầm và đặt đồ vật, sử dụng ngăn kéo và tủ lạnh, và tương tác giữa các rô-bốt - mà không cần bất kỳ tinh chỉnh nào cho từng nhiệm vụ cụ thể;
Bản địa hóa: Helix là mô hình VLA rô-bốt đầu tiên trong lịch sử chạy trên GPU cục bộ và có khả năng thương mại hóa.
Trong lĩnh vực lái xe thông minh, tất cả các nhà sản xuất ô tô đều đang thúc đẩy việc triển khai công nghệ đầu cuối trên diện rộng trong năm nay. Hiện tại, robot do VLA điều khiển cũng đã bước vào giai đoạn đếm ngược để thương mại hóa. Theo cách này, Helix có thể được coi là một bước đột phá lớn trong trí thông minh hiện thân.
Một tập hợp các trọng số của mạng nơ-ron Helix chạy đồng thời trên hai rô-bốt, chúng cùng nhau làm việc để cất những món đồ tạp hóa mà chúng chưa từng nhìn thấy trước đây.
Những phần mở rộng mới cho robot hình người
Figure cho biết môi trường gia đình là thách thức lớn nhất mà ngành robot phải đối mặt. Không giống như môi trường công nghiệp được kiểm soát, ngôi nhà chứa vô số đồ vật bất thường, chẳng hạn như đồ thủy tinh dễ vỡ, quần áo nhăn nheo và đồ chơi nằm rải rác, mỗi thứ đều có hình dạng, kích thước, màu sắc và kết cấu không thể đoán trước. Để robot có thể hữu ích trong gia đình, chúng cần có khả năng tạo ra những hành vi thông minh mới theo yêu cầu.
Công nghệ robot hiện tại không thể áp dụng cho môi trường gia đình — hiện tại, việc dạy cho robot ngay cả một hành vi mới cũng đòi hỏi sự can thiệp đáng kể của con người. Hoặc là phải mất nhiều giờ lập trình thủ công bởi các chuyên gia trình độ tiến sĩ hoặc hàng nghìn lần trình diễn, cả hai cách này đều rất tốn kém. Hình 1: Đường cong mở rộng của các phương pháp khác nhau để tiếp thu các kỹ năng robot mới. Trong các hoạt động tìm kiếm thông tin truyền thống, việc phát triển kỹ năng phụ thuộc vào việc các chuyên gia viết thủ công các tập lệnh. Trong phương pháp học bắt chước bằng robot truyền thống, việc mở rộng kỹ năng phụ thuộc vào dữ liệu thu thập được. Với Helix, các kỹ năng mới có thể được chỉ định ngay lập tức thông qua ngôn ngữ.
Hiện nay, các lĩnh vực khác của trí tuệ nhân tạo đã thành thạo khả năng khái quát hóa tức thời này. Nếu kiến thức ngữ nghĩa phong phú thu được trong mô hình ngôn ngữ thị giác (VLM) có thể được chuyển đổi trực tiếp thành hành động của robot thì có thể đạt được bước đột phá về công nghệ.
Khả năng mới này về cơ bản sẽ thay đổi quỹ đạo phát triển của ngành robot (Hình 1). Câu hỏi chính sau đó là: làm thế nào chúng ta có thể trích xuất tất cả những kiến thức thông thường này từ VLM và chuyển đổi chúng thành khả năng điều khiển robot tổng quát? Figure xây dựng Helix để thu hẹp khoảng cách này.
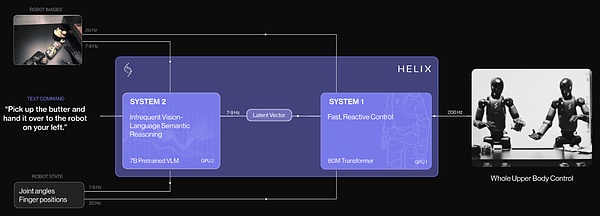
Helix: Mô hình VLA "System 1 + System 2" đầu tiên trong lĩnh vực robot
Helix là mô hình VLA "System 1 + System 2" đầu tiên trong lĩnh vực robot, được sử dụng để điều khiển toàn bộ phần thân trên của robot hình người với tốc độ cao và sự khéo léo.
Hình ảnh cho thấy các phương pháp tiếp cận trước đây phải đối mặt với sự đánh đổi cơ bản: xương sống VLM có tính tổng quát nhưng không nhanh, trong khi các chính sách thị giác-vận động của rô-bốt có tính tổng quát nhưng không đủ. Helix giải quyết vấn đề đánh đổi này thông qua hai hệ thống bổ sung được đào tạo từ đầu đến cuối để giao tiếp:
Hệ thống 1 (S1): chính sách thị giác vận động phản ứng nhanh chuyển đổi các biểu diễn ngữ nghĩa tiềm ẩn do S2 tạo ra thành các hành động liên tục chính xác của rô-bốt ở tần số 200 Hz;
Hệ thống 2 (S2): VLM được đào tạo trước qua internet trên bo mạch chạy ở tần số 7-9 Hz để hiểu bối cảnh và hiểu ngôn ngữ, đạt được khả năng khái quát rộng rãi trên các đối tượng và bối cảnh.
Kiến trúc tách biệt này cho phép mỗi hệ thống hoạt động theo khung thời gian tối ưu của nó. S2 có thể “suy nghĩ chậm” về các mục tiêu cấp cao, trong khi S1 có thể “suy nghĩ nhanh” về các hành động mà robot thực hiện và điều chỉnh theo thời gian thực. Ví dụ, trong hành vi hợp tác (xem hình bên dưới), S1 có thể nhanh chóng thích ứng với những chuyển động thay đổi của robot đối tác trong khi vẫn duy trì các mục tiêu ngữ nghĩa của S2.
 Helix cho phép robot thực hiện các điều chỉnh vận động tinh một cách nhanh chóng, điều này cần thiết để phản hồi các đối tác hợp tác khi thực hiện các mục tiêu ngữ nghĩa mới.
Helix cho phép robot thực hiện các điều chỉnh vận động tinh một cách nhanh chóng, điều này cần thiết để phản hồi các đối tác hợp tác khi thực hiện các mục tiêu ngữ nghĩa mới.
Thiết kế của Helix có một số ưu điểm chính so với các phương pháp hiện có:
Tốc độ và khả năng khái quát hóa: Helix có tốc độ tương đương với các chiến lược sao chép hành vi chuyên biệt cho một nhiệm vụ duy nhất, đồng thời có thể khái quát hóa cho hàng nghìn đối tượng thử nghiệm mới với các dự đoán không có lần thử nào;
Khả năng mở rộng: Helix trực tiếp đưa ra khả năng điều khiển liên tục trong không gian hành động có nhiều chiều, tránh các lược đồ mã hóa hành động phức tạp được sử dụng trong các phương pháp VLA trước đây. Các lược đồ này đã cho thấy một số thành công trong các thiết lập điều khiển chiều thấp (ví dụ: bộ kẹp song song nhị phân), nhưng phải đối mặt với những thách thức về khả năng mở rộng trong điều khiển hình người chiều cao;
Sự đơn giản về mặt kiến trúc: Helix sử dụng một kiến trúc chuẩn - một VLM mã nguồn mở, trọng lượng mở cho Hệ thống 2 và một chính sách thị giác vận động đơn giản dựa trên Transformer cho Hệ thống 1;
Phân tách các mối quan tâm: Việc tách S1 và S2 cho phép chúng ta lặp lại từng hệ thống riêng biệt mà không bị hạn chế bởi việc tìm kiếm một không gian quan sát thống nhất hoặc biểu diễn hành động.
Hình giới thiệu một số chi tiết về mô hình và đào tạo, thu thập bộ dữ liệu hành vi điều khiển từ xa đa dạng, chất lượng cao từ nhiều robot, nhiều người vận hành, tổng cộng khoảng 500 giờ. Để tạo ra các cặp đào tạo bằng ngôn ngữ tự nhiên, các kỹ sư đã sử dụng mô hình ngôn ngữ trực quan được chú thích tự động (VLM) để tạo ra các hướng dẫn sau.
VLM xử lý các đoạn video được phân đoạn từ camera tích hợp trên rô-bốt và đưa ra lời nhắc: "Bạn sẽ đưa ra hướng dẫn nào cho rô-bốt để thực hiện hành động mà nó nhìn thấy trong video?" Tất cả các đối tượng được xử lý trong quá trình đào tạo đều bị loại khỏi quá trình đánh giá để tránh làm ô nhiễm dữ liệu.
Kiến trúc mô hình
Hệ thống Helix bao gồm hai thành phần chính: S2, mạng xương sống VLM; S1, bộ chuyển động thị giác có điều kiện tiềm ẩn.
S2 được xây dựng trên VLM mã nguồn mở, có trọng số mở với 7 tỷ tham số được đào tạo trước trên dữ liệu quy mô internet. Nó xử lý hình ảnh robot đơn sắc và thông tin trạng thái robot (bao gồm tư thế cổ tay và vị trí ngón tay) và chiếu chúng vào không gian nhúng ngôn ngữ thị giác. Kết hợp với các hướng dẫn ngôn ngữ tự nhiên chỉ định hành vi mong muốn, S2 chắt lọc mọi thông tin liên quan đến nhiệm vụ ngữ nghĩa thành một vectơ tiềm ẩn liên tục, được truyền đến S1 để điều chỉnh các hành động cấp thấp của nó.
S1 là bộ biến đổi mã hóa-giải mã chú ý chéo 80 triệu tham số chịu trách nhiệm điều khiển mức thấp. Nó dựa trên mạng xương sống thị giác đa thang độ tích chập hoàn toàn để xử lý hình ảnh, được khởi tạo hoàn toàn từ quá trình đào tạo trước trong mô phỏng. Trong khi S1 nhận được cùng hình ảnh và trạng thái đầu vào như S2, nó xử lý các đầu vào này ở tần số cao hơn để điều khiển vòng kín phản ứng nhanh hơn. Các vectơ tiềm ẩn từ S2 được chiếu vào không gian nhãn của S1 và nối dọc theo chiều chuỗi với các đặc điểm trực quan được trích xuất bởi mạng xương sống trực quan S1, cung cấp khả năng điều kiện hóa nhiệm vụ.
Khi hoạt động, S1 sẽ điều khiển toàn bộ phần thân trên của cơ thể ở tần số 200 Hz, bao gồm tư thế cổ tay mong muốn, điều khiển gập và mở ngón tay, cũng như mục tiêu định hướng thân và đầu. Hình ảnh thêm hành động “phần trăm hoàn thành nhiệm vụ” tổng hợp vào không gian hành động, cho phép Helix dự đoán điều kiện kết thúc của chính nó, giúp việc sắp xếp nhiều hành vi đã học trở nên dễ dàng hơn.
Đào tạo
Helix được đào tạo hoàn toàn từ đầu đến cuối: từ các pixel thô và lệnh văn bản đến các hành động liên tục với mức mất mát hồi quy tiêu chuẩn.
Đường truyền ngược của gradient là từ S1 đến S2 thông qua vectơ truyền thông ngầm được sử dụng để điều chỉnh hành vi của S1, cho phép tối ưu hóa chung hai thành phần.
Helix không cần phải được điều chỉnh cho một nhiệm vụ cụ thể; nó duy trì một giai đoạn đào tạo và một tập hợp các trọng số mạng nơ-ron duy nhất, mà không cần các đầu hành động riêng biệt hoặc các giai đoạn tinh chỉnh cho từng nhiệm vụ.
Trong quá trình đào tạo, họ cũng thêm một khoảng thời gian bù trừ giữa các đầu vào S1 và S2. Độ lệch này được hiệu chỉnh để phù hợp với khoảng cách giữa độ trễ suy luận của các triển khai S1 và S2, đảm bảo rằng các yêu cầu kiểm soát thời gian thực trong quá trình triển khai được phản ánh chính xác trong quá trình đào tạo.
Suy luận phát trực tuyến được tối ưu hóa
Thiết kế đào tạo của Helix cho phép triển khai song song hiệu quả các mô hình trên robot Figure, mỗi mô hình được trang bị GPU nhúng công suất thấp kép. Quy trình suy luận được chia thành mô hình S2 (lập kế hoạch ngầm cấp cao) và mô hình S1 (kiểm soát cấp thấp), mỗi mô hình chạy trên một GPU chuyên dụng.
S2 chạy như một quy trình nền không đồng bộ để xử lý các quan sát mới nhất (trạng thái camera và rô-bốt trên bo mạch) và các lệnh ngôn ngữ tự nhiên. Nó liên tục cập nhật vectơ tiềm ẩn trong bộ nhớ chia sẻ mã hóa các ý định hành vi cấp cao.
S1 thực hiện như một quy trình thời gian thực riêng biệt với mục tiêu duy trì vòng điều khiển 200Hz quan trọng cần thiết để thực hiện trơn tru toàn bộ chuyển động của thân trên. Đầu vào của nó là quan sát mới nhất và vectơ tiềm ẩn S2 mới nhất. Do sự khác biệt về tốc độ vốn có giữa lý luận S2 và S1, S1 tự nhiên hoạt động ở độ phân giải thời gian cao hơn đối với các quan sát của robot, tạo ra vòng phản hồi chặt chẽ hơn để điều khiển phản ứng.
Chiến lược triển khai này cố ý phản ánh độ lệch thời gian được đưa vào trong quá trình đào tạo, do đó giảm thiểu khoảng cách phân phối suy luận-đào tạo. Mô hình thực thi không đồng bộ này cho phép cả hai quy trình chạy ở tần số tối ưu tương ứng, cho phép Helix chạy nhanh như chính sách học mô phỏng tác vụ đơn nhanh nhất.
Điều thú vị là sau khi Figure phát hành Helix, Yanjiang Guo, một nghiên cứu sinh tiến sĩ tại Đại học Thanh Hoa, cho biết các ý tưởng kỹ thuật của nó khá giống với một trong những bài báo CoRL 2024 của họ, mà độc giả quan tâm cũng có thể tham khảo để đọc.

Địa chỉ bài báo: https://arxiv.org/abs/2410.05273
Kết quả
Kiểm soát toàn bộ phần thân trên bằng VLA chi tiết
Helix có thể điều phối không gian hành động 35 độ tự do ở tần số 200Hz, kiểm soát mọi thứ từ chuyển động ngón tay riêng lẻ đến quỹ đạo của bộ phận hiệu ứng cuối, ánh mắt đầu và tư thế thân mình.
Việc điều khiển đầu và thân đặt ra những thách thức đặc biệt – khi đầu và thân chuyển động, nó sẽ thay đổi những gì robot có thể tiếp cận và nhìn thấy, tạo ra các vòng phản hồi gây ra sự mất ổn định trong quá khứ.
Video 3 chứng minh sự phối hợp này trong thực tế: robot theo dõi nhịp nhàng tay bằng đầu trong khi điều chỉnh thân mình để có tầm với tối ưu trong khi vẫn duy trì khả năng kiểm soát chính xác các ngón tay để cầm nắm. Trước đây, việc đạt được mức độ chính xác này trong không gian hành động có nhiều chiều như vậy là rất khó, ngay cả đối với một nhiệm vụ đơn lẻ đã biết. Hình minh họa cho thấy không có hệ thống VLA nào trước đây có thể chứng minh được mức độ phối hợp thời gian thực này trong khi vẫn duy trì khả năng khái quát hóa trên nhiều tác vụ và đối tượng.

VLA của Helix có thể điều khiển toàn bộ phần thân trên của robot hình người. Đây là mô hình đầu tiên trong lĩnh vực học robot đạt được điều này.
Hợp tác nhiều robot Zero-Shot
Figure cho biết họ đã đẩy Helix đến giới hạn của nó trong một kịch bản hoạt động đa tác nhân khó khăn: hai robot Figure đã hợp tác để đạt được mục tiêu lưu trữ hàng tạp hóa Zero-Shot.
Video 1 cho thấy hai tiến bộ cơ bản: Cả hai robot đều có thể vận chuyển thành công hàng hóa mới lạ (các vật phẩm chưa từng gặp trong quá trình đào tạo), chứng minh khả năng khái quát hóa mạnh mẽ đối với nhiều hình dạng, kích thước và vật liệu khác nhau.
Ngoài ra, cả hai robot đều hoạt động bằng cùng trọng lượng mô hình Helix, không yêu cầu đào tạo riêng cho robot hoặc phân công vai trò rõ ràng. Sự hợp tác của chúng đạt được thông qua các lời nhắc bằng ngôn ngữ tự nhiên, chẳng hạn như "chuyển túi bánh quy cho robot bên phải bạn" hoặc "lấy túi bánh quy từ robot bên trái bạn và đặt vào ngăn kéo mở" (xem Video 4). Đây là lần đầu tiên VLA được sử dụng để chứng minh các hoạt động cộng tác linh hoạt và có thể mở rộng giữa nhiều robot. Thành tựu này đặc biệt đáng chú ý khi xét đến việc họ đã xử lý thành công những vật thể hoàn toàn mới.

Helix cho phép nhiều robot cộng tác chính xác
Khả năng "nhặt bất cứ thứ gì" xuất hiện


Chỉ với lệnh "Nhặt [X]", robot Figure được trang bị Helix về cơ bản có thể nhặt bất kỳ vật dụng nhỏ nào trong gia đình. Trong quá trình thử nghiệm có hệ thống, không cần bất kỳ cuộc trình diễn hay lập trình tùy chỉnh nào trước đó, robot đã xử lý thành công hàng nghìn vật thể mới trong một môi trường lộn xộn — từ đồ thủy tinh và đồ chơi đến dụng cụ và quần áo.
Đặc biệt, Helix có thể xây dựng mối liên hệ giữa khả năng hiểu ngôn ngữ trên quy mô internet và khả năng điều khiển robot chính xác. Ví dụ, khi được yêu cầu "nhặt một vật thể ở sa mạc", Helix không chỉ xác định được rằng cây xương rồng đồ chơi phù hợp với khái niệm trừu tượng này mà còn chọn được bàn tay gần nhất và có thể nắm chặt nó một cách an toàn bằng các lệnh vận động chính xác.
Figure cho biết: "Khả năng nắm bắt 'ngôn ngữ thành hành động' phổ quát này mở ra những khả năng mới thú vị cho việc triển khai rô-bốt hình người trong môi trường phi cấu trúc."

Helix có thể dịch các hướng dẫn cấp cao như "nhấc [X]" thành các hành động cấp thấp.
Thảo luận
Helix có hiệu quả trong việc đào tạo
Helix đạt được khả năng khái quát hóa đối tượng mạnh mẽ với rất ít tài nguyên. Hình cho biết: “Chúng tôi sử dụng tổng cộng ~500 giờ dữ liệu có giám sát chất lượng cao để đào tạo Helix, đây chỉ là một phần nhỏ (<5%) trong tập dữ liệu VLA được thu thập trước đó và không dựa vào bộ sưu tập hiện thân của nhiều robot hoặc nhiều giai đoạn đào tạo”. Họ lưu ý rằng quy mô bộ sưu tập này gần hơn với các tập dữ liệu học mô phỏng một tác vụ hiện đại. Mặc dù có yêu cầu dữ liệu tương đối nhỏ, Helix có thể được mở rộng sang không gian hành động đầy thử thách hơn, cụ thể là khả năng điều khiển toàn bộ phần thân trên của người máy, với đầu ra tốc độ cao, đa chiều.
Bộ tạ đơn
Các hệ thống VLA hiện tại thường yêu cầu tinh chỉnh chuyên biệt hoặc đầu hành động chuyên dụng để tối ưu hóa hiệu suất thực hiện các hành vi cấp cao khác nhau. Đáng chú ý, Helix có thể thực hiện các hành động như nhặt và đặt các vật phẩm vào nhiều loại hộp đựng khác nhau, vận hành ngăn kéo và tủ lạnh, phối hợp chuyển giao khéo léo nhiều robot và thao tác hàng nghìn vật thể mới chỉ bằng một bộ trọng số mạng nơ-ron (7B cho Hệ thống 2 và 80M cho Hệ thống 1).

"Nhấc Helix lên" (Helix có nghĩa là xoắn ốc)
Tóm tắt
Helix là mô hình "tầm nhìn-ngôn ngữ-hành động" đầu tiên điều khiển trực tiếp toàn bộ phần thân trên của robot hình người thông qua ngôn ngữ tự nhiên. Không giống như các hệ thống robot trước đây, Helix có thể tạo ra các thao tác phối hợp, khéo léo, có tầm nhìn xa ngay lập tức mà không cần bất kỳ trình diễn cụ thể nào về nhiệm vụ hoặc lập trình thủ công mở rộng.
Helix đã chứng minh được khả năng khái quát hóa vật thể mạnh mẽ, có thể nhận diện hàng nghìn vật dụng gia đình mới lạ với nhiều hình dạng, kích thước, màu sắc và đặc tính vật liệu khác nhau mà nó chưa từng gặp trong quá trình đào tạo, chỉ bằng cách sử dụng các lệnh ngôn ngữ tự nhiên. Công ty cho biết: "Đây là bước chuyển mình mang tính cách mạng của Figure trong việc mở rộng hành vi của robot hình người - một bước mà chúng tôi tin rằng sẽ rất quan trọng vì robot của chúng tôi ngày càng hỗ trợ nhiều hơn trong môi trường gia đình hàng ngày".
Mặc dù những kết quả ban đầu này chắc chắn rất thú vị, nhưng nhìn chung những gì chúng ta thấy ở trên vẫn chỉ là bằng chứng về khái niệm, cho thấy những gì có thể thực hiện được. Cuộc cách mạng thực sự sẽ đến khi Helix có thể được triển khai ở quy mô lớn. Mong ngày đó đến sớm hơn!
Cuối cùng, việc phát hành Figure có thể chỉ là một bước nhỏ trong nhiều đột phá về trí thông minh hiện thân trong năm nay. Sáng sớm nay, 1X Robotics cũng chính thức thông báo sẽ sớm ra mắt sản phẩm mới.


 Hui Xin
Hui Xin

