Lightning Network hoạt động như thế nào (1)?
Trong bài viết hôm nay chúng tôi sẽ tiếp tục giới thiệu về Lightning Network và giải thích rõ ràng nguyên lý hoạt động cũng như các công nghệ liên quan của Lightning Network.
 JinseFinance
JinseFinance

Vào đầu năm 2024, OpenAI đã tung ra một quả bom AI khác cho thế giới—người mẫu tạo video Sora.
Giống như ChatGPT một năm trước, Sora được coi là một khoảnh khắc quan trọng khác trong AGI (Trí tuệ tổng hợp nhân tạo).
"Sora có nghĩa là việc triển khai AGI sẽ được rút ngắn từ 10 năm xuống còn 1 năm", Chu Hongyi, chủ tịch 360, đưa ra dự đoán.
Nhưng mô hình này gây ấn tượng không chỉ vì video do AI tạo ra có độ phân giải dài hơn và cao hơn mà còn vì OpenAI đã vượt qua tất cả các video trước đó. Khả năng của AIGC tạo ra nội dung video liên quan đến thế giới thực.
Trò chơi cyberpunk vô nghĩa thật thú vị, nhưng cách mọi thứ trong thế giới thực có thể được AI tái tạo lại có ý nghĩa hơn.
Vì mục đích này, OpenAI đã đề xuất một khái niệm hoàn toàn mới - World Simulator.
Trong báo cáo kỹ thuật do OpenAI chính thức phát hành, Sora được định vị là"mô hình tạo video như một công cụ mô phỏng thế giới", "Kết quả nghiên cứu của chúng tôi cho thấy rằng việc mở rộng mô hình tạo video là một cách khả thi để xây dựng một trình mô phỏng chung về thế giới thực."

(Nguồn: Trang web chính thức của OpenAI)
OpenAI tin rằngSora đã đặt nền tảng cho các mô hình có thể hiểu và mô phỏng thế giới thực, đây sẽ là một cột mốc quan trọng trong việc hiện thực hóa của AGI. Với điều này, nó đã hoàn toàn tách biệt khỏi các công ty như Runway và Pika trong lĩnh vực video AI.

Từ văn bản (ChatGPT) đến hình ảnh (DALL·E) đến video (Sora), đối với OpenAI, nó giống như thu thập từng mảnh ghép một, cố gắng phá vỡ hoàn toàn ranh giới giữa ảo và thực thông qua hình thức truyền thông hình ảnh , trở thành sự tồn tại giống như bộ phim "Ready Player One".
Nếu Apple Vision Pro là màn hình phần cứng của người chơi số một, thì hệ thống AI có thể tự động xây dựng một thế giới ảo mô phỏng chính là linh hồn.
"Mô hình ngôn ngữ gần giống với bộ não con người và mô hình video gần giống với thế giới vật chất", Yao Fu, nghiên cứu sinh tiến sĩ tại Đại học Edinburgh, cho biết.
"Tham vọng của OpenAI nằm ngoài sức tưởng tượng của mọi người, nhưng có vẻ như chỉ có nó mới làm được điều đó." Nhiều doanh nhân AI than thở về con đường Light Cone Intelligence.
Sora trở thành "người mô phỏng thế giới" như thế nào?
Mô hình Sora mới ra mắt của OpenAI đã mở ra cánh cửa cho đường đua video AI vào năm 2024, hoàn toàn khác biệt so với điều đó vào năm 2023 Một ranh giới được vẽ ra giữa thế giới cũ.
Trong 48 video trình diễn được phát hành chỉ trong một hơi thở, Light Cone Intelligence nhận thấy rằng hầu hết các vấn đề bị chỉ trích đối với các video AI trước đây đều đã được giải quyết: rõ ràng hơn Tạo hình ảnh, hiệu ứng tạo thực tế hơn, hiểu chính xác hơn, hiểu logic mượt mà hơn, kết quả tạo ổn định và nhất quán hơn, v.v.
Nhưng tất cả những điều này chỉ là phần nổi của tảng băng trôi mà OpenAI đã chỉ ra,vì OpenAI đã không nhắm mục tiêu vào video ngay từ đầu mà là tất cả các hình ảnh hiện có . .
Hình ảnh là một khái niệm lớn hơn và video là một tập hợp con của nó, chẳng hạn như màn hình cuộn lớn trên đường phố và những cảnh ảo trong nhà thế giới trò chơi, v.v. Điều OpenAI muốn làm là sử dụng video làm điểm đầu vào để bao quát tất cả hình ảnh, mô phỏng và hiểu thế giới thực, đó là khái niệm "trình mô phỏng thế giới" mà nó nhấn mạnh.
Như Chen Kun, nhà sản xuất bộ phim AI "Wonderland of Mountains and Seas" và Xingxian Culture, nói với Lightcone Intelligence, "OpenAI đang cho chúng tôi thấy khả năng của nó khả năng trong video. Nhưng mục đích thực sự là thu thập dữ liệu phản hồi của mọi người để khám phá và dự đoán loại video mà mọi người muốn tạo. Cũng giống như đào tạo mô hình lớn, một khi công cụ này được mở, nó sẽ tương đương với mọi người trên khắp thế giới đang làm việc đối với nó, thông qua việc đánh dấu và nhập liệu liên tục, mô hình thế giới của nó ngày càng trở nên thông minh hơn."
Vì vậy, chúng tôi thấy rằngVideo AI đã trở thành một cách để hiểu Trong giai đoạn đầu tiên, nó chủ yếu nêu bật các đặc tính của nó như một "mô hình tạo video"; trong giai đoạn thứ hai, nó có thể cung cấp giá trị như một "trình mô phỏng thế giới".
Cốt lõi của việc nắm bắt thuộc tính "thế hệ video" của Sora là tìm ra điểm khác biệt, đó là Sora, Runway và Pika Sự khác biệt được phản ánh ở đâu? Câu hỏi này rất quan trọng vì nó giải thích phần nào lý do tại sao Sora có thể bị nghiền nát.
Trước hết, OpenAI đi theo ý tưởng đào tạo một mô hình ngôn ngữ lớn, sử dụng dữ liệu trực quan quy mô lớn để đào tạo một mô hình tổng quát với các kiến thức chung khả năng.
Điều này hoàn toàn khác với logic "chỉ có nhân sự chuyên trách" trong lĩnh vực video Wensheng. Năm ngoái, Runway cũng có một kế hoạch tương tự, được gọi là "mô hình thế giới toàn cầu". Ý tưởng gần như tương tự nhưng không có sự tiếp nối. Lần này Sora dẫn đầu trong việc thực hiện ước mơ của Runway.
Theo tính toán của Trợ lý giáo sư Xie Saining tại Đại học New York, số lượng tham số Sora là khoảng 3 tỷ. Mặc dù không đáng kể so với mô hình GPT nhưng điều này bậc độ lớn đã vượt xa Runway và Pika, đối với một số công ty, nó có thể được gọi là một cuộc tấn công giảm kích thước.
Qi Borquan, tổng giám đốc Trung tâm đổi mới AI công nghệ Wanxing, nhận xét rằng thành công của Sora một lần nữa chứng minh khả năng xảy ra "phép lạ lớn", "Sora vẫn đi theo quy mô của OpenAI Law, dựa vào sự làm việc chăm chỉ để đạt được những điều kỳ diệu, một lượng lớn dữ liệu, mô hình lớn và sức mạnh tính toán lớn. Lớp dưới cùng của Sora sử dụng các mô hình thế giới đã được xác minh trong các lĩnh vực trò chơi, lái xe không người lái và robot để xây dựng video Vincent mô hình để đạt được khả năng mô phỏng thế giới."
Thứ hai, Sora lần đầu tiên chứng minh sự tích hợp hoàn hảo giữa mô hình khuếch tán và khả năng của mô hình lớn.
Video AI giống như một bộ phim bom tấn, phụ thuộc vào hai yếu tố quan trọng: kịch bản và hiệu ứng đặc biệt. Trong số đó, kịch bản tương ứng với “logic” trong quá trình tạo video AI và các hiệu ứng đặc biệt tương ứng với “hiệu ứng”. Để đạt được "logic" và "hiệu ứng", hai đường dẫn kỹ thuật được phân biệt đằng sau mô hình khuếch tán và mô hình lớn.
Vào cuối năm ngoái, Light Cone Intelligence dự đoán rằng để đáp ứng cả hiệu ứng và logic, hai con đường khuếch tán và mô hình lớn cuối cùng sẽ hội tụ. Không ngờ OpenAI lại giải quyết vấn đề này nhanh đến vậy.
(Nguồn: Trang web chính thức của OpenAI)
OpenAI rút ra trong báo cáo kỹ thuật Điểm nổi bật : “Phương pháp tiếp cận của chúng tôi biến nhiều loại dữ liệu trực quan khác nhau thành một biểu diễn thống nhất có thể được sử dụng để đào tạo các mô hình tổng quát trên quy mô lớn.”
Cụ thể, OpenAI mã hóa từng loại khung video thành các bản vá trực quan. Mỗi bản vá tương tự như một mã thông báo trong GPT và trở thành đơn vị đo lường nhỏ nhất trong video và hình ảnh. Và nó có thể bị hỏng và sắp xếp lại mọi lúc, mọi nơi. Sau khi tìm ra cách thống nhất dữ liệu và thống nhất trọng lượng và thước đo, chúng tôi đã tìm thấy cầu nối giữa mô hình khuếch tán và mô hình lớn.
Trong toàn bộ quá trình tạo, mô hình khuếch tán vẫn chịu trách nhiệm tạo ra hiệu ứng tạo. Sau khi thêm cơ chế chú ý của Transformer mô hình lớn, sẽ có nhiều quyền kiểm soát hơn Khả năng dự đoán và suy luận, điều này giải thích tại sao Sora có thể tạo video từ các hình ảnh tĩnh thu được hiện có và cũng có thể mở rộng các video hiện có hoặc điền vào các khung hình bị thiếu.
Kể từ khi phát triển, các mô hình video đã cho thấy xu hướng kết hợp. Trong khi các mô hình đang hướng tới sự kết hợp thì công nghệ cũng đang hướng tới sự kết hợp.
Áp dụng tích lũy công nghệ tích lũy trước đây vào các mô hình trực quan cũng đã trở thành lợi thế của OpenAI. Trong quá trình đào tạo video của Sora Vincent, OpenAI đã giới thiệu khả năng hiểu ngôn ngữ của DALL-E3 và GPT. Theo OpenAI, việc đào tạo dựa trên DALL-E3 và GPT có thể cho phép Sora tạo chính xác các video chất lượng cao theo lời nhắc của người dùng.
Sau một loạt cú đấm kết hợp, kết quả là khả năng mô phỏng, tạo thành nền tảng của "trình mô phỏng thế giới".
"Chúng tôi nhận thấy rằng các mô hình video thể hiện một số khả năng mới nổi thú vị khi được đào tạo trên quy mô lớn. Những khả năng này khiến Sora Có khả năng mô phỏng nhất định các khía cạnh của con người, động vật và môi trường trong thế giới vật chất. Những đặc tính này phát sinh mà không có bất kỳ thành kiến quy nạp rõ ràng nào đối với ba chiều, vật thể, v.v.—chúng hoàn toàn là hiện tượng quy mô", OpenAI cho biết.
Lý do cơ bản khiến "mô phỏng" có thể bùng nổ đến vậy là vì mọi người đã quen với việc sử dụng các mô hình lớn để tạo ra những thứ không tồn tại, nhưng họ có thể chính xác hiểu vật lý. Logic về cách thế giới vận hành, chẳng hạn như cách các lực tương tác, cách tạo ra ma sát, cách một quả bóng rổ chạm vào một parabol, v.v. Đây là những điều mà chưa có mô hình nào trước đây có thể thực hiện được và đây là ý nghĩa cơ bản của Sora vượt xa mức độ tạo video.
Tuy nhiên, từ demo đến thành phẩm thực tế có thể sẽ gây bất ngờ hoặc sốc. Yang Likun, nhà khoa học trưởng của Meta, đã trực tiếp đặt câu hỏi với Sora, ông nói: "Chỉ có thể tạo ra các video thực tế dựa trên lời nhắc không có nghĩa là hệ thống thực sự hiểu được thế giới vật chất. Quá trình tạo ra khác với dự đoán nhân quả dựa trên các mô hình thế giới." . Các mô hình sáng tạo Bạn chỉ cần tìm một mẫu hợp lý từ không gian khả năng mà không cần hiểu và mô phỏng mối quan hệ nhân quả trong thế giới thực."
Qi Borquan cũng cho biết rằng mặc dù OpenAI đã được xác minh rằng mô hình video Vincent lớn dựa trên mô hình thế giới là khả thi, nhưng cũng có những khó khăn về độ chính xác của các tương tác vật lý. Mặc dù Sora có thể mô phỏng một số tương tác vật lý cơ bản nhưng nó có thể gặp khó khăn khi xử lý nhiều hơn hiện tượng vật lý phức tạp; Có những thách thức trong việc xử lý các phụ thuộc lâu dài, tức là làm thế nào để duy trì tính nhất quán và logic về mặt thời gian, độ chính xác của các chi tiết không gian. Nếu việc xử lý các chi tiết không gian không đủ chính xác, nó có thể ảnh hưởng đến độ chính xác và độ tin cậy của nội dung video.
Video gây gián đoạn nhưng không chỉ đơn thuần là video
Sora có thể đã trở thành người mô phỏng thế giới từ lâu, nhưng về mặt tạo video, nó đã có tác động đến thế giới hiện tại.
Hạng mục đầu tiên là giải quyết các vấn đề không thể giải quyết được bằng các công nghệ trước đây và đẩy một số ngành lên một giai đoạn mới.
Điển hình nhất là ngành sản xuất phim và truyền hình. Khả năng mang tính cách mạng nhất của Sora lần này là video được tạo ra có thời lượng dài nhất đạt tới 1 phút. Để tham khảo, Pika phổ biến có thể tạo ra thời lượng 3 giây và Gen-2 của Runway có thể tạo ra thời lượng 18 giây. Điều này có nghĩa là với Sora, video AI sẽ trở thành năng suất thực sự, giúp giảm chi phí và cải thiện hiệu quả.
Chen Kun nói với Guancone Intelligence rằng trước khi Sora ra đời, chi phí sử dụng các công cụ video AI để sản xuất phim khoa học viễn tưởng đã giảm xuống một nửa. Sau khi Sora ra mắt, nó thậm chí còn trở nên đáng giá hơn mong đợi.
Sau khi Sora được thả ra, điều khiến anh ấn tượng nhất là bản demo một chú cá heo đi xe đạp. Trong video đó, phần thân trên là cá heo, phần thân dưới là hai chân người, trên chân có mang giày, bằng một phong cách hội họa rất kỳ lạ, chú cá heo hoàn thành hành động đạp xe như một con người.
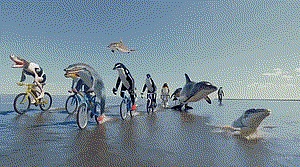
"Điều này đơn giản là khiến chúng tôi kinh ngạc! Hình ảnh này tạo ra một cảm giác phi lý vừa giàu trí tưởng tượng vừa phù hợp với các định luật vật lý. Nó vừa hợp lý vừa bất ngờ. Đây chính là điều khiến khán giả phải kinh ngạc. Các tác phẩm điện ảnh và truyền hình ", Trần Khôn nói.
Chen Kun tin rằngSora sẽ hạ thấp ngưỡng dành cho tất cả người sáng tạo nội dung xuống một bước lớn, giống như điện thoại thông minh và Douyin hồi đó. .
"Trong tương lai, người sáng tạo nội dung có thể không cần chụp ảnh mà chỉ cần nói một đoạn văn hoặc một từ để thể hiện ý tưởng độc đáo trong đầu họ. Hãy ra ngoài và được nhiều người nhìn thấy hơn. Đến lúc đó, tôi nghĩ có thể sẽ có một nền tảng mới lớn hơn Douyin. Tiến lên một bước, có lẽ Sora có thể hiểu được suy nghĩ tiềm thức của mọi người và tự động tạo, tạo Nội dung không cần người dùng để tích cực tìm kiếm sự biểu đạt,” Chen Kun nói.
Ngành tương tự cũng bao gồm các trò chơi. Phần cuối của báo cáo kỹ thuật OpenAI là một video trò chơi "Minecraft" với câu sau được viết bên cạnh: "Sora có thể Đồng thời điều khiển người chơi trong Minecraft thông qua các chiến lược cơ bản đồng thời hiển thị thế giới và động lực của nó với độ trung thực cao. Chỉ cần nhắc đến 'Minecraft' trong phụ đề nhắc nhở của Sora sẽ kích hoạt cận cảnh các tính năng này."

Doanh nhân trò chơi AI Chen Xi đã nói với chúng tôi , "Bất kỳ người chơi game nào cũng sẽ toát mồ hôi lạnh khi nhìn thấy câu này! OpenAI thể hiện tham vọng của mình mà không cần dè dặt." Sự giải thích và phân tích của Chen Xi tin rằng câu ngắn gọn này truyền tải hai điều:Sora có thể điều khiển nhân vật trong game, đồng thời thể hiện môi trường trò chơi.
"Như OpenAI đã nói, Sora là một trình giả lập, một công cụ trò chơi và là giao diện chuyển đổi giữa trí tưởng tượng và thế giới thực. , chỉ cần bạn nói về nó, hình ảnh có thể được hiển thị. Sora hiện đã học cách xây dựng một thế giới trong một phút và cũng có thể tạo ra các nhân vật ổn định. Kết hợp với GPT-5 của riêng mình, một loại hoàn toàn do AI tạo ra, hàng nghìn kilômét vuông , một bản đồ chứa đầy những sinh vật hoạt động với nhiều màu sắc khác nhau, nghe có vẻ không còn viển vông nữa. Tất nhiên, liệu màn hình có thể được tạo trong thời gian thực hay không và liệu nó có hỗ trợ nhiều người chơi trực tuyến hay không là những vấn đề rất thực tế. Nhưng dù thế nào đi nữa , chế độ trò chơi mới đã sắp ra mắt, ít nhất là với Sora không có vấn đề gì khi tạo ra “Kết thúc rồi, tôi được bao quanh bởi những người đẹp”, Chen Xidao nói.
Loại thứ hai dựa trên khả năng mô phỏng thế giới để tạo ra những thứ mới ở nhiều lĩnh vực hơn.
Yao Fu, nghiên cứu sinh tiến sĩ tại Đại học Edinburgh, cho biết: "Các mô hình sáng tạo học các thuật toán tạo ra dữ liệu, thay vì ghi nhớ chính dữ liệu đó . Cũng giống như ngôn ngữ. Cũng giống như cách các mô hình mã hóa các thuật toán (trong não của bạn) tạo ra ngôn ngữ, các mô hình video mã hóa các công cụ vật lý tạo ra luồng video.Mô hình ngôn ngữ có thể được coi là gần giống với bộ não con người, trong khi video các mô hình gần giống với thế giới vật chất.”< /p>
Việc tìm hiểu các quy luật phổ quát trong thế giới vật chất làm cho trí tuệ thể hiện gần hơn với trí thông minh của con người.
Ví dụ, trong lĩnh vực robot, quá trình truyền tải trước đó trước tiên là đưa ra hướng dẫn bắt tay cho bộ não robot rồi truyền nó đến tay. Tuy nhiên , vì robot không thực sự hiểu được ý nghĩa của "Bắt tay" nên chỉ dẫn chỉ có thể chuyển thành "đường kính bàn tay có thể giảm xuống bao nhiêu cm?" Nếu mô phỏng thế giới trở thành hiện thực, robot có thể trực tiếp bỏ qua quá trình chuyển đổi lệnh và hiểu nhu cầu ra lệnh của con người chỉ trong một bước.
Jia Kui, người sáng lập Trí tuệ đa chiều và là giáo sư tại Đại học Công nghệ Nam Trung Quốc, bày tỏ với Light Cone Intelligence rằng mô phỏng vật lý rõ ràng có thể được áp dụng đối với robot trong lĩnh vực tương lai, "Mô phỏng vật lý của Sora là tiềm ẩn. Nó cho thấy những hiệu ứng chỉ có thể được tạo ra bằng sự hiểu biết bên trong và mô phỏng thế giới vật lý. Để trực tiếp hữu ích cho robot, tôi nghĩ tốt hơn là nên làm cho nó rõ ràng. "
"Khả năng của Sora vẫn đạt được thông qua dữ liệu video khổng lồ và công nghệ ghi lại phụ đề. Thậm chí còn không có mô hình rõ ràng 3D chứ đừng nói đến mô phỏng vật lý. . Mặc dù hiệu ứng mà nó tạo ra đã đạt/gần bằng hiệu ứng đạt được thông qua mô phỏng vật lý. Nhưng công cụ vật lý có thể làm được nhiều việc hơn là chỉ tạo ra video và còn có nhiều yếu tố khác cần thiết cho việc huấn luyện robot”, Jacqui nói.
Mặc dù Sora vẫn còn nhiều hạn chế nhưng một mối liên kết đã được thiết lập giữa thế giới ảo và thực, điều này khiến cho dù đó có phải là thế giới ảo kiểu Ready Player One hay không, Cho dù robot có giống con người hơn hay không thì chúng vẫn có nhiều khả năng lớn hơn.
Trong bài viết hôm nay chúng tôi sẽ tiếp tục giới thiệu về Lightning Network và giải thích rõ ràng nguyên lý hoạt động cũng như các công nghệ liên quan của Lightning Network.
JinseFinanceArweave, nguyên lý hoạt động và ý nghĩa của Arweave, bài viết này giới thiệu ngắn gọn về nguyên lý hoạt động và giá trị của Arweave.
JinseFinanceMô hình AI mới của Google, HeAR, sử dụng phân tích âm sinh học để phát hiện các dấu hiệu sớm của tình trạng sức khỏe bằng cách phân tích các âm thanh như tiếng ho và hơi thở. Hợp tác với Salcit Technologies, Google đặt mục tiêu tăng cường khả năng phát hiện bệnh sớm và khả năng tiếp cận, mặc dù vẫn còn nhiều thách thức trong việc đảm bảo độ chính xác của AI và giành được sự tin tưởng của y tế.
 Joy
JoyZircuit, mạng Ethereum Lớp 2, nổi bật với trình sắp xếp được hỗ trợ bởi AI để nâng cao tính bảo mật và hiệu quả giao dịch, thu hút hơn 3,3 tỷ USD tài sản đặt cọc trước khi ra mắt mạng chính được hỗ trợ bởi Binance Labs.
JoyHai ngày trước, truyền thông nước ngoài đã thực hiện một cuộc phỏng vấn độc quyền với nhóm nòng cốt của Sora, sau khi xem video gốc, gần như không nói gì, khung cảnh giống như một bài phát biểu của Trưởng phòng Mã của Ủy ban Cải cách và Phát triển Quốc gia.
JinseFinanceKhám phá tương lai của sự tích hợp AI và Web3: sức mạnh tính toán phi tập trung, dữ liệu lớn, đổi mới Dapp và tác động sâu sắc của nó đối với đổi mới công nghiệp.
JinseFinanceCó bốn cách để tích hợp AI và Web3: sức mạnh tính toán phi tập trung, cộng tác thuật toán và mô hình, dữ liệu lớn phi tập trung và Dapp được hỗ trợ bởi AI.
JinseFinanceTại sao có thể gọi Sora là cột mốc mới trong ngành AI? Làm thế nào nó có thể vượt qua AIGC, giới hạn trên của việc tạo nội dung AI? Khách quan mà nói thì phiên bản Sora hiện tại có hạn chế hay thiếu sót gì không?
JinseFinanceSora là một mô hình trí tuệ nhân tạo do OpenAI phát triển, có thể tạo ra các cảnh video chân thực và giàu trí tưởng tượng dựa trên hướng dẫn văn bản do người dùng nhập.
JinseFinanceCon đường AI đang bùng nổ trở lại, dự án nào hoạt động tốt và thế lực mới nào đang nổi lên?
JinseFinance