Văn bản: Lan Xi
Mười hai ngày qua kể từ khi DeepSeek trở nên phổ biến thực sự là khoảng thời gian ồn ào nhất. Thành thật mà nói, hầu hết các sản phẩm thảo luận đều có cảm giác làm thêm giờ để đáp ứng KPI và mọi người đều tranh cãi về việc chúng là người hay ma. Chỉ một số ít trong số chúng có giá trị duy trì. Tuy nhiên, có hai podcast đã mang lại lợi ích rất nhiều cho tôi sau khi nghe chúng. Tôi thực sự khuyên bạn nên nghe chúng.
Một là Trương Tiểu Quân đã mời Phan Gia Nghị, tiến sĩ từ Phòng thí nghiệm AI thuộc Đại học California, Berkeley, đến giải thích từng câu một về bài báo DeepSeek. Đầu ra mật độ cao trong gần 3 giờ có thể giết chết tế bào não, nhưng endorphin tiết ra sau khi giết chết cũng có tính nổ.
Một tập khác là bộ sưu tập podcast gồm 3 tập của Ben Thompson về DeepSeek, kéo dài hơn một giờ. Anh chàng này là người sáng lập News Letter và là một trong những nhà phân tích am hiểu công nghệ nhất thế giới. Anh ấy sống ở Đài Bắc quanh năm và có cái nhìn sâu sắc hơn nhiều về Trung Quốc/Châu Á so với những người đồng cấp người Mỹ của mình.
Chúng ta hãy bắt đầu với tập của Zhang Xiaojun. Sau khi đọc bài báo của DeepSeek, khách mời Pan Jiayi đã nhanh chóng phát triển một dự án quy mô nhỏ để tái tạo mô hình R1-Zero, có gần 10.000 Sao trên GitHub.
Kiểu truyền đạt kiến thức được truyền từ thế hệ này sang thế hệ khác thực chất là sự phản ánh của chủ nghĩa duy tâm trong lĩnh vực công nghệ. Cũng giống như Flood Sung, một nhà nghiên cứu tại Dark Side of the Moon, đã nói, mô hình lý luận k1.5 của Kimi ban đầu được lấy cảm hứng từ hai video do OpenAI phát hành. Thậm chí trước đó, khi Google phát hành "Attention Is All You Need", OpenAI đã ngay lập tức nhận ra tương lai của Transformer. Sự lưu loát của trí tuệ là điều kiện tiên quyết cho mọi tiến bộ.
Đó là lý do tại sao mọi người lại thất vọng với tuyên bố của nhà sáng lập Anthropic Dario Amodei rằng “Khoa học không có biên giới, nhưng các nhà khoa học có quê hương”. Trong khi phủ nhận sự cạnh tranh, ông cũng đang thách thức lẽ thường tình cơ bản.
Hãy quay lại nội dung của podcast. và quá trình tìm kiếm câu trả lời khá đẹp; 2 năm, và mô hình chính thống vẫn phù hợp với GPT-4, điều này rất hiếm trong một thị trường ủng hộ "sự đổi mới liên tục". Bản thân o1 cũng là một nỗ lực theo đuổi một hướng kỹ thuật mới, sử dụng các mô hình ngôn ngữ để dạy AI cách suy nghĩ;
- o1 đã đạt được sự cải thiện tuyến tính về mức độ thông minh trong bài kiểm tra chuẩn, điều này thật tuyệt vời. Báo cáo kỹ thuật không tiết lộ quá nhiều chi tiết, nhưng tất cả các điểm chính đều được đề cập, chẳng hạn như giá trị của học tăng cường. Đào tạo trước và điều chỉnh có giám sát tương đương với việc cung cấp cho mô hình các câu trả lời đúng để bắt chước. Theo thời gian, mô hình học cách sao chép mô hình, nhưng học tăng cường cho phép mô hình tự hoàn thành nhiệm vụ. Bạn chỉ cho mô hình biết kết quả là đúng hay sai. Nếu đúng, hãy thực hiện nhiều hơn, và nếu sai, hãy thực hiện ít hơn;
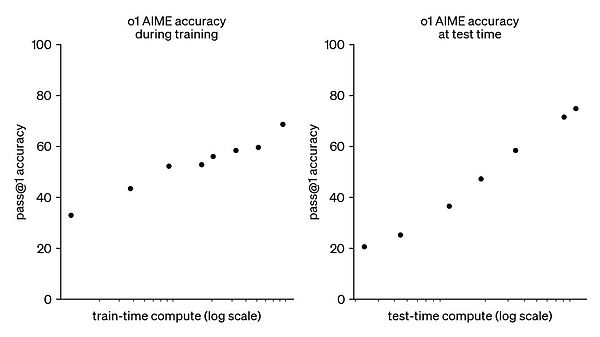
- OpenAI phát hiện ra rằng học tăng cường có thể khiến mô hình tạo ra hiệu ứng gần với suy nghĩ của con người, tức là CoT (chuỗi suy nghĩ). Khi xảy ra lỗi trong các bước giải quyết vấn đề, nó sẽ quay lại bước trước đó và cố gắng nghĩ ra những cách mới. Những điều này không được các nhà nghiên cứu con người dạy, nhưng bản thân mô hình buộc phải hoàn thành nhiệm vụ, ôi không, đó là một khả năng mới nổi. Sau đó, khi DeepSeek-R1 cũng tái hiện một "khoảnh khắc giác ngộ" tương tự, thì pháo đài cốt lõi của o1 thực sự đã bị phá vỡ;
- Mô hình lý luận về cơ bản là sản phẩm của tính toán kinh tế. Nếu sức mạnh tính toán bị tích tụ một cách cưỡng bức, nó vẫn có thể tạo ra hiệu ứng tương tự như o1 khi đạt đến GPT-6, nhưng đó không phải là phép màu với nỗ lực lớn, mà là phép màu với phép màu. Điều đó là có thể nhưng không phải là bắt buộc. Khả năng của mô hình có thể được hiểu là sức mạnh tính toán đào tạo x sức mạnh tính toán lý luận. Cái trước đã quá đắt, và cái sau vẫn rất rẻ, nhưng hiệu ứng nhân lên gần như giống nhau, vì vậy hiện tại ngành công nghiệp đã bắt đầu đi theo con đường lý luận với hiệu suất chi phí tốt hơn;
- Việc phát hành o3-mini vào cuối tháng trước có thể không liên quan nhiều đến DeepSeek-R1, nhưng giá của o3-mini đã giảm xuống còn 1/3 so với o1-mini, điều này hẳn đã bị ảnh hưởng rất nhiều. OpenAI tin rằng mô hình kinh doanh của ChatGPT có hào, nhưng việc bán API thì không, và nó quá dễ thay thế. Gần đây cũng có nhiều tranh cãi ở Trung Quốc về việc liệu ChatBot có phải là một doanh nghiệp tốt hay không. Ngay cả DeepSeek rõ ràng vẫn chưa tìm ra cách để tiếp cận làn sóng lưu lượng truy cập này. Có thể có một xung đột tự nhiên giữa việc thực hiện thị trường ở cấp độ người tiêu dùng và thực hiện nghiên cứu tiên tiến;
- Theo quan điểm của các chuyên gia kỹ thuật, DeepSeek-R1-Zero đẹp hơn R1 vì nó ít có sự can thiệp của con người hơn. Mô hình đã tìm ra quy trình tìm ra giải pháp tối ưu trong hàng ngàn bước suy luận và không phụ thuộc nhiều vào kiến thức trước đó. Tuy nhiên, vì chưa được căn chỉnh nên R1-Zero không thể cung cấp cho người dùng. Ví dụ, nó xuất ra nhiều ngôn ngữ khác nhau. Vì vậy, trên thực tế, R1 của DeepSeek, đã được công nhận trên thị trường đại chúng, vẫn sử dụng các phương pháp cũ như chưng cất, tinh chỉnh và thậm chí là cấy ghép trước các chuỗi suy nghĩ;
- Điều này liên quan đến một vấn đề là khả năng và hiệu suất không đồng bộ. Mô hình có khả năng tốt nhất có thể không phải là mô hình có hiệu suất tốt nhất và ngược lại. Hiệu suất vượt trội của R1 phần lớn là do hướng nỗ lực thủ công. R1 không có ngữ liệu đào tạo độc quyền. Ngữ liệu của mọi người đều chứa thơ cổ điển, v.v. Không thể có chuyện R1 biết nhiều hơn. Lý do thực sự có thể là chú thích dữ liệu. Người ta nói rằng DeepSeek đã tìm thấy sinh viên từ Khoa tiếng Trung của Đại học Bắc Kinh để làm chú thích, điều này sẽ cải thiện đáng kể chức năng thưởng của biểu đạt văn học. Nhìn chung, ngành này không thích sử dụng sinh viên nghệ thuật tự do. Việc bản thân Liang Wenfeng đôi khi thực hiện chú thích không chỉ cho thấy sự nhiệt tình của ông mà còn cho thấy dự án chú thích đã đạt đến giai đoạn cần những người làm bài kiểm tra chuyên nghiệp để hướng dẫn AI. OpenAI cũng trả 100-200 đô la Mỹ một giờ để mời các nghiên cứu sinh tiến sĩ làm chú thích cho o1;
- Dữ liệu, sức mạnh tính toán và thuật toán là ba bánh đà của ngành công nghiệp mô hình lớn. Những đột phá chính của làn sóng này đến từ các thuật toán. DeepSeek-R1 đã phát hiện ra một sự hiểu lầm, đó là, việc nhấn mạnh vào các hàm giá trị trong các thuật toán truyền thống có thể là một cái bẫy. Các hàm giá trị có xu hướng đưa ra phán đoán ở mọi bước của quá trình suy luận, do đó hướng dẫn mô hình đi đúng hướng trong mọi chi tiết. Ví dụ, khi mô hình đang giải bài toán 1+1 bằng bao nhiêu, khi nó có ảo tưởng rằng 1+1=3, nó bắt đầu trừng phạt nó, giống như liệu pháp sốc điện, không cho phép nó mắc lỗi;
- Thuật toán này về mặt lý thuyết là hợp lý, nhưng nó cũng rất cầu toàn. Không phải mọi câu hỏi đều đơn giản như 1+1, đặc biệt là khi hàng nghìn chuỗi mã thông báo được suy ra trong một chuỗi suy nghĩ dài. Nếu mọi bước đều cần được giám sát, tỷ lệ đầu vào-đầu ra sẽ trở nên rất thấp. Do đó, DeepSeek đã đưa ra một quyết định đi ngược lại với lời dạy của tổ tiên. Nó không còn sử dụng hàm giá trị để thỏa mãn chứng rối loạn ám ảnh cưỡng chế trong quá trình nghiên cứu. Nó chỉ chấm điểm các câu trả lời và để mô hình tìm ra cách để có được câu trả lời với các bước chính xác. Ngay cả khi nó có giải pháp 1+1=3, nó sẽ không sửa quá mức. Thay vào đó, nó sẽ nhận ra rằng có điều gì đó không ổn trong quá trình suy luận và thấy rằng nó không thể có được câu trả lời đúng bằng cách tính toán theo cách này, sau đó tự sửa;
- Thuật toán là cải tiến lớn nhất của DeepSeek đối với toàn bộ ngành, bao gồm cách phân biệt mô hình đang bắt chước hay suy luận. Tôi nhớ rằng sau khi o1 ra mắt, nhiều người tuyên bố rằng mô hình chung cũng có thể đưa ra chuỗi suy nghĩ thông qua các từ gợi ý, nhưng những mô hình đó không có khả năng suy luận. Trên thực tế, chúng chỉ đang bắt chước. Nó vẫn đưa ra câu trả lời theo cách thông thường, nhưng để đáp ứng yêu cầu của người dùng, nó đã quay lại và đưa ra ý tưởng dựa trên câu trả lời. Đây là sự bắt chước, một hành động vô nghĩa là bắn mũi tên trước rồi mới vẽ mục tiêu. DeepSeek cũng đã nỗ lực rất nhiều trong việc bẻ khóa phần thưởng chống lại các mô hình, chủ yếu là để giải quyết vấn đề các mô hình trở nên xảo quyệt. Nó dần đoán được cách suy nghĩ để nhận được phần thưởng, nhưng không thực sự hiểu tại sao phải suy nghĩ theo cách này;
- Trong những năm gần đây, ngành công nghiệp đã mong chờ sự xuất hiện của các mô hình trong quá khứ, mọi người nghĩ rằng nếu số lượng kiến thức là đủ, mô hình sẽ phát triển một cách tự nhiên. Cải thiện hiệu suất của nó, nó bắt đầu tích cực chuỗi suy nghĩ của nó. Học tập củng cố sau khi chưng cất K1.5 đã được phát hành cùng lúc với DeepSeek -R1, nhưng vì nó không phải là nguồn mở và không đủ tích lũy quốc tế, mặc dù nó đã đóng góp các đổi mới thuật toán tương tự, nên ảnh hưởng của nó. Sau khi đặt câu hỏi-nhưng có vẻ như có một số lợi nhuận phản tác dụng , Openai's Moat vẫn còn rất sâu 3. Trên thực tế, không có sự đổi mới nào ở cấp độ kiến trúc và tác động của DeepSeek lên thị trường nguồn mở hoàn toàn không được lường trước. Nguồn nhân lực của Meta rất mạnh, nhưng cơ cấu tổ chức không chuyển đổi những nguồn lực này thành thành tựu công nghệ.
Nói về podcast của Ben Thompson, ông đã xác minh chéo phán đoán của Pan Jiayi ở nhiều chỗ. Ví dụ, R1-Zero đã xóa điểm nhấn kỹ thuật của HF (phản hồi của con người) trong RLHF, nhưng có nhiều cuộc thảo luận hơn về cạnh tranh địa chính trị và quá khứ của các công ty lớn. Câu chuyện rất trôi chảy:
- Một trong những động lực khiến Thung lũng Silicon nhấn mạnh quá mức về tính an toàn của AI là họ có thể sử dụng nó để hợp lý hóa hành vi khép kín. Ngay từ giao thức GPT-2, mục đích là tránh sử dụng các mô hình ngôn ngữ lớn để tạo ra nội dung "lừa dối và thiên vị", nhưng "lừa dối và thiên vị" còn lâu mới là nguy cơ tuyệt chủng của loài người. Về cơ bản, đây là sự tiếp nối của cuộc chiến văn hóa và dựa trên giả định rằng "khi kho thóc đầy, nghi thức sẽ được biết đến", nghĩa là các công ty công nghệ Mỹ có lợi thế tuyệt đối về công nghệ, vì vậy chúng ta có đủ điều kiện để không thảo luận về việc liệu AI có phân biệt chủng tộc hay không;
- Giống như những gì Openai đã nói một cách chính đáng khi nó quyết định che giấu chuỗi tư tưởng O1 - chuỗi suy nghĩ ban đầu có thể không được căn chỉnh, và người dùng có thể cảm thấy bị xúc phạm sau khi nhìn thấy nó, vì vậy chúng tôi đã quyết định cắt nó và không hiển thị cho người dùng - nhưng DeepSeek -R1 đã đưa ra sự tự tin của người dùng. Nhìn thấy nó; Điều này khác với tất cả các công ty công nghệ vào thời điểm đó. DeepSeek đã mã nguồn mở mô hình R1 và giải thích rõ ràng cách thực hiện. Đây là một hành động thiện chí to lớn. Nếu công ty Trung Quốc này tiếp tục kích động địa chính trị, họ nên giữ bí mật về những thành tựu của mình. Google cũng đã vạch ra vạch đích cho các nhà sản xuất máy chủ chuyên nghiệp như Sun, đưa cuộc cạnh tranh lên mức hàng hóa.
- Nhà nghiên cứu Roon của OpenAI tin rằng việc hạ cấp tối ưu hóa của DeepSeek để vượt qua chip H800 - các kỹ sư không thể sử dụng CUDA của Nvidia và chỉ có thể chọn PTX cấp thấp hơn - là một minh chứng sai lầm, vì điều đó có nghĩa là thời gian họ lãng phí cho nó không thể bù đắp được, trong khi các kỹ sư người Mỹ có thể nộp đơn xin H100 mà không phải lo lắng. Phần cứng yếu đi không thể mang lại sự đổi mới thực sự.
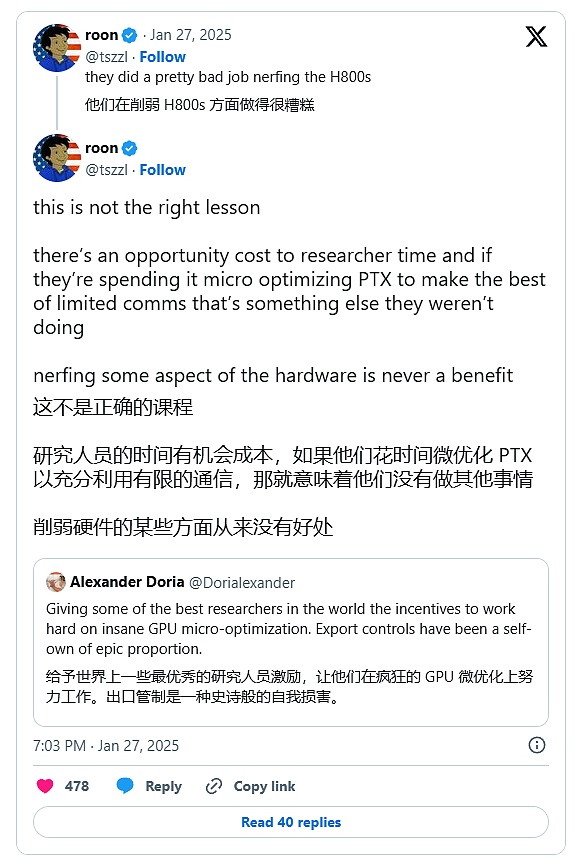
- Nếu Google năm 2004 nghe theo lời khuyên của Roon và không "lãng phí" các nhà nghiên cứu giá trị để xây dựng các trung tâm dữ liệu tiết kiệm hơn, thì có lẽ các công ty Internet của Mỹ ngày nay sẽ thuê máy chủ đám mây của Alibaba. Trong hai thập kỷ đổ xô vào của cải vừa qua, Thung lũng Silicon đã mất đi động lực để tối ưu hóa cơ sở hạ tầng. Các nhà máy lớn và nhỏ đã quen với các mô hình sản xuất thâm dụng vốn và vui vẻ nộp biểu mẫu ngân sách để đổi lấy đầu tư. Họ thậm chí còn sử dụng chip của Nvidia làm tài sản thế chấp. Còn về cách tạo ra nhiều giá trị nhất có thể với nguồn lực hạn chế, thì không ai quan tâm; các công ty AI chắc chắn sẽ ủng hộ nghịch lý Jevons, tức là điện toán rẻ hơn tạo ra nhiều cách sử dụng hơn, nhưng hành vi thực tế trong vài năm qua lại không nhất quán, vì mọi công ty đều thể hiện sự ưu tiên cho nghiên cứu hơn là chi phí, cho đến khi DeepSeek thực sự đưa nghịch lý Jevons vào mắt mọi người; Công ty Nvidia trở nên có giá trị hơn và giá cổ phiếu của Nvidia trở nên rủi ro hơn. Những điều này có thể cùng tồn tại. Nếu DeepSeek có thể đạt được thành tựu như vậy trên một con chip bị hạn chế nghiêm ngặt, thì hãy tưởng tượng xem tiến bộ công nghệ sẽ lớn đến mức nào khi họ có được tài nguyên điện toán toàn năng. Đây là một tiết lộ đầy cảm hứng cho toàn bộ ngành, nhưng giá cổ phiếu của Nvidia dựa trên giả định rằng họ là nhà cung cấp duy nhất, điều này có thể bị làm sai lệch;
- Các công ty công nghệ Trung Quốc và Hoa Kỳ có sự khác biệt rõ ràng trong việc đánh giá giá trị của các sản phẩm AI. Trung Quốc tin rằng sự khác biệt nằm ở việc đạt được cấu trúc chi phí vượt trội, phù hợp với những thành tựu của họ trong các ngành công nghiệp khác. Hoa Kỳ tin rằng sự khác biệt đến từ chính sản phẩm và biên lợi nhuận cao hơn được tạo ra dựa trên sự khác biệt này, nhưng Hoa Kỳ cần phải suy nghĩ lại về tâm lý giành chiến thắng trong cuộc cạnh tranh bằng cách phủ nhận sự đổi mới, chẳng hạn như hạn chế các công ty Trung Quốc có được chip cần thiết cho nghiên cứu AI;
- Cho dù danh tiếng của Claude ở San Francisco có tốt đến đâu thì cũng khó có thể thay đổi được điểm yếu tự nhiên của nó trong mô hình bán API, đó là quá dễ bị thay thế. ChatGPT cho phép OpenAI có khả năng chống chịu rủi ro cao hơn với tư cách là một công ty công nghệ tiêu dùng. Tuy nhiên, về lâu dài, DeepSeek sẽ có lợi cho cả những người bán AI và những người sử dụng AI. Chúng ta nên biết ơn món quà hào phóng này.
Vâng, vậy là xong. Tôi hy vọng bài tập này có thể giúp bạn hiểu rõ hơn về ý nghĩa thực sự của DeepSeek đối với ngành công nghiệp AI sau khi nó trở nên phổ biến.


 Alex
Alex

