Livepeer :如何在Livepeer网络上引入AI视频计算
现在是时候将 AI 视频计算功能引入Livepeer了
 JinseFinance
JinseFinance

作者:Cynic、Shigeru
导读:利用算法、算力与数据的力量,AI技术的进步正在重新定义数据处理和智能决策的边界。与此同时,DePIN代表了从中心化基础设施向去中心化、基于区块链的网络的范式转变。
随着世界迈向数字化转型的步伐不断加快,AI和DePIN(去中心化物理基础设施)已成为推动各行各业变革的基础性技术。AI与DePIN的融合,不仅能够促进技术的快速迭代和应用广泛化,还将开启更为安全、透明和高效的服务模式,为全球经济带来深远的变革。
DePIN:去中心化脱虚向实,数字经济中流砥柱
DePIN,是去中心化物理基础设施(Decentralized Physical Infrastructure)的缩写。从狭义上说,DePIN主要指由分布式账本技术支撑的传统物理基础设施的分布式网络,例如电力网络、通信网络、定位网络等。从广义上说,所有由物理设备支撑的分布式网络都可以称之为DePIN,例如存储网络、计算网络。
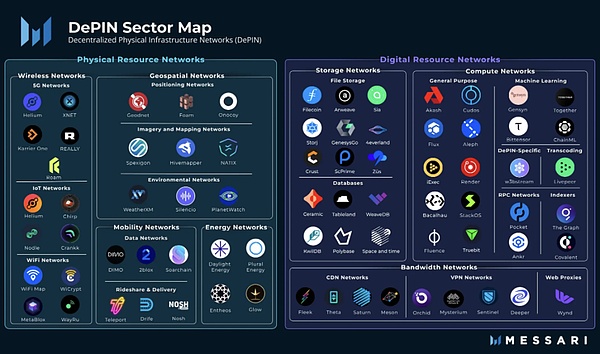
from: Messari
如果说Crypto在金融层面带来了去中心化的变革,那么DePIN就是实体经济中的去中心化方案。可以说,PoW矿机,就是一种DePIN。从第一天起,DePIN就是Web3的核心支柱。
AI三要素——算法、算力、数据,DePIN独占其二
人工智能的发展通常被认为依赖于三个关键的要素:算法、算力和数据。算法指驱动AI系统的数学模型和程序逻辑,算力指执行这些算法所需的计算资源,数据是训练和优化AI模型的基础。

三要素中哪个最重要?chatGPT出现之前人们通常认为是算法,不然学术会议、期刊论文也不会被一篇又一篇的算法微调所填充。可当chatGPT与支撑其智能的大语言模型LLM亮相之后,人们开始意识到后两者的重要性。海量的算力是模型得以诞生的前提,数据质量和多样性对于建立健壮和高效的AI系统至关重要,相比之下,对于算法的要求不再如往常精益求精。
在大模型时代,AI从精雕细琢变为大力飞砖,对算力与数据的需求与日俱增,而DePIN恰好能够提供。代币激励撬动长尾市场,海量的消费级算力与存储将成为大模型提供最好的养料。
AI的去中心化不是可选项,而是必选项
当然有人会问,算力和数据,在AWS的机房中都有,而且在稳定性、使用体验方面都胜过DePIN,为什么要选择DePIN而不是中心化的服务?
这种说法自然有其道理,毕竟纵观当下,几乎所有大模型都是由大型的互联网企业直接或间接开发的,chatGPT的背后是微软,Gemini的背后是谷歌,中国的互联网大厂几乎人手一个大模型。为何?因为只有大型的互联网企业拥有足够的优质数据与雄厚财力支撑的算力。但这是不对的,人们已经不想再被互联网巨头操纵一切。
一方面,中心化的AI具备数据隐私和安全风险,可能受到审查与控制;另一方面,互联网巨头制造的AI会使人们进一步加强依赖性,并且导致市场集中化,提高创新壁垒。

from: https://www.gensyn.ai/
人类不应该需要一个AI纪元的马丁路德了,人们应该有权利直接和神对话。
商业角度看DePIN:降本增效是关键
哪怕抛开去中心化与中心化的价值观之争,从商业角度来看,将DePIN用于AI仍然有其可取之处。
首先,我们需要清晰地认识到,尽管互联网巨头手中掌握了大量的高端显卡资源,散入民间的消费级显卡组合起来也能构成非常可观的算力网络,也就是算力的长尾效应。这类消费级显卡,闲置率其实是非常高的。只要DePIN给到的激励能超过电费,用户就有动力为网络贡献算力。同时,所有物理设施被用户自身所管理,DePIN网络无需负担中心化供应商无法避免的运营成本,只需关注协议设计本身。
对于数据而言,DePIN网络通过边缘计算等方式,能够释放潜在数据的可用性,降低传输成本。同时,多数分布式存储网络而言具备自动去重功能,减少了AI训练数据清洗的工作。
最后,DePIN所带来的Crypto经济学增强了系统的容错空间,有望实现提供者、消费者、平台三赢的局面。
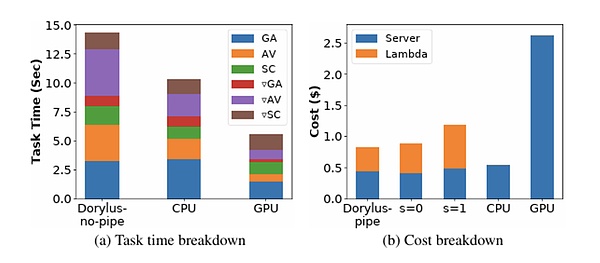
from: UCLA
以防你不相信,UCLA最新的研究表明相同成本下使用去中心化计算相比传统GPU集群实现了2.75倍的性能,具体来说,快了1.22倍且便宜4.83倍。
筚路维艰:AIxDePIN会遇到哪些挑战?
We choose to go to the moon in this decade and do the other things, not because they are easy, but because theyare hard.
——John Fitzgerald Kennedy
运用DePIN的分布式存储与分布式计算无信任地构建人工智能模型仍然具备许多挑战。
工作验证
从本质上,计算深度学习模型与PoW挖矿都是通用计算,最底层都是门电路之间的信号变化。宏观而言,PoW挖矿是“无用的计算”,通过无数的随机数生成与哈希函数计算试图得出前缀有n个0的哈希值;而深度学习计算是“有用的计算”,通过前向推导与反向推导计算出深度学习中每层的参数值,从而构建一个高效的AI模型。
事实是,PoW挖矿这类“无用的计算”使用了哈希函数,由原像计算像很容易,由像计算原像很难,所以任何人都能轻易、快速地验证计算的有效性;而对于深度学习模型的计算,由于层级化的结构,每层的输出都作为后一层的输入,因此验证计算的有效性需要执行之前的所有工作,无法简单有效地进行验证。
from: AWS
工作验证是非常关键的,否则,计算的提供者完全可以不进行计算,而提交一个随机生成的结果。
有一类想法是让不同的服务器执行相同计算任务,通过重复执行并检验是否相同来验证工作的有效性。然而,绝大多数模型计算是非确定性的,即使在完全相同的计算环境下也无法复现相同结果,只能在统计意义上实现相似。另外,重复计算会导致成本的快速上升,这与DePIN降本增效的关键目标不相符。
另一类想法是Optimistic机制,先乐观地相信结果是经过有效计算的,同时允许任何人对计算结果进行检验,如果发现有错误,可以提交一个Fraud Proof,协议对欺诈者进行罚没,并对举报者给予奖励。
并行化
之前提到,DePIN撬动的主要是长尾的消费级算力市场,也就注定了单个设备所能提供的算力比较有限。对于大型AI模型而言,在单个设备上进行训练的时间会非常长,必须通过并行化的手段来缩短训练所需时间。
深度学习训练的并行化主要的难点在于前后任务之间的依赖性,这种依赖关系会导致并行化难以实现。
当前,深度学习训练的并行化主要分为数据并行与模型并行。
数据并行是指将数据分布在多台机器上,每台机器都保存一个模型的全部参数,使用本地的数据进行训练,最后对各个机器的参数进行聚合。数据并行在数据量很大时效果好,但需要同步通信来聚合参数。
模型并行是当模型大小太大无法放入单个机器时,可以将模型分割在多台机器上,每台机器保存模型的一部分参数。前向和反向传播时需要不同机器之间通信。模型并行在模型很大时有优势,但前后向传播时的通信开销大。
对于不同层之间的梯度信息,又可以分为同步更新与异步更新。同步更新简单直接,但是会增加等待时间;异步更新算法等待时间短,但是会引入稳定性问题。
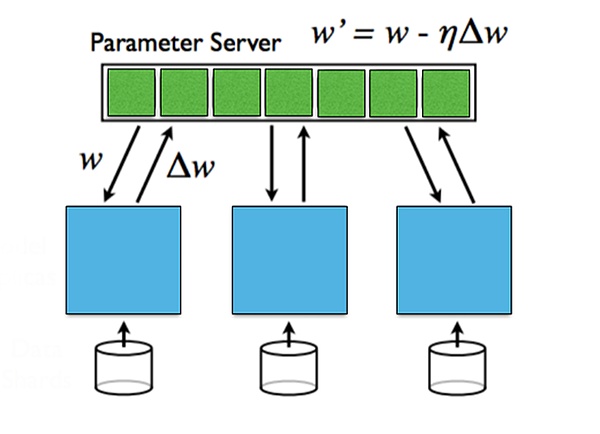
from: Stanford University, Parallel and Distributed Deep Learning
隐私
全球正在掀起保护个人隐私的思潮,各国政府都在加强对个人数据隐私安全的保护。尽管AI大量使用公开数据集,真正将不同AI模型区分开的还是各企业专有的用户数据。
如何在训练过程中得到专有数据的好处同时不暴露隐私?如何保证构建的AI模型参数不被泄露?
这是隐私的两个方面,数据隐私与模型隐私。数据隐私保护的是用户,而模型隐私保护的是构建模型的组织。在当前的情况下,数据隐私比模型隐私重要得多。
多种方案正在尝试解决隐私的问题。联邦学习通过在数据的源头进行训练,将数据留在本地,而模型参数进行传输,来保障数据隐私;而零知识证明可能会成为后起之秀。
案例分析:市场上有哪些优质项目?
Gensyn
Gensyn是一个分布式计算网络,用于训练 AI 模型。该网络使用基于Polkadot的一层区块链来验证深度学习任务是否已正确执行,并通过命令触发支付。成立于2020年,2023年6月披露一笔4300万美元的A轮融资,a16z领投。
Gensyn使用基于梯度的优化过程的元数据来构建所执行工作的证书,并由多粒度、基于图形的精确协议和交叉评估器一致执行,以允许重新运行验证工作并比较一致性,并最终由链本身确认,来保证计算的有效性。为了进一步加强工作验证的可靠性,Gensyn引入质押来创建激励。
系统中有四类参与者:提交者、求解者、验证者和举报者。
• 提交者是系统的终端用户,提供将要计算的任务,并为已完成的工作单元付费。
• 求解器是系统的主要工作者,执行模型训练并生成证明以供验证者检查。
• 验证器是将非确定性训练过程与确定性线性计算联系起来的关键,复制部分求解器证明并将距离与预期阈值进行比较。
• 举报人是最后一道防线,检查验证者的工作并提出挑战,挑战通过后获得奖励。
求解者需要进行质押,举报者检验求解者的工作,如发现作恶,进行挑战,挑战通过后求解者质押的代币被罚没,举报者获得奖赏。
根据Gensyn的预测,该方案有望将训练成本降至中心化供应商的1/5。
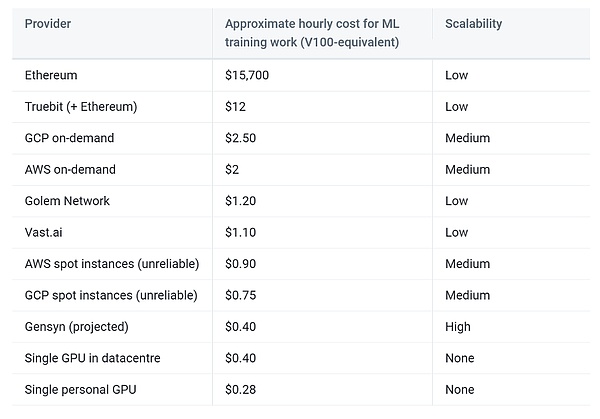
from: Gensyn
FedML
FedML 是一个去中心化协作的机器学习平台,用于在任何地方以任何规模进行去中心化和协作式 AI。更具体地说,FedML 提供了一个 MLOps 生态系统,可以训练、部署、监控和持续改进机器学习模型,同时以保护隐私的方式在组合数据、模型和计算资源上进行协作。成立于2022年,FedML于2023年3月披露600万美元的种子轮融资。
FedML由FedML-API和FedML-core两个关键组件构成,分别代表高级API和底层API。
FedML-core包括分布式通信和模型训练两个独立的模块。通信模块负责不同工作者/客户端之间的底层通信,基于MPI;模型训练模块基于PyTorch。
FedML-API建立在FedML-core之上。借助FedML-core,可以通过采用面向客户端的编程接口轻松实现新的分布式算法。
FedML团队最新的工作中证明,使用FedML Nexus AI在消费级GPU RTX 4090上进行AI模型推理,比A100便宜20倍,快1.88倍。
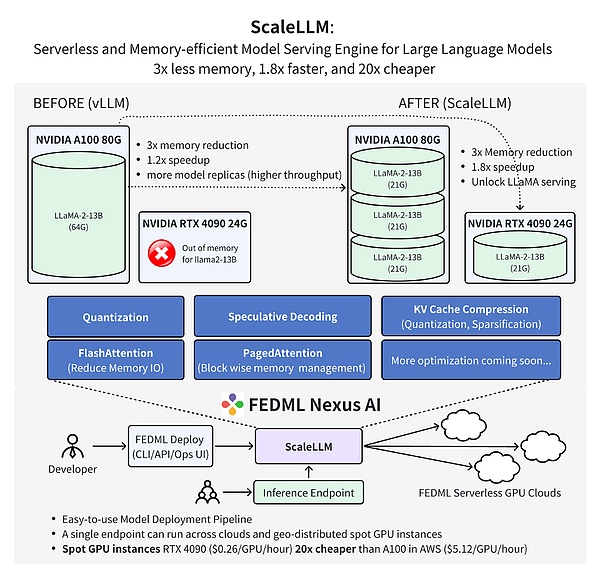
from: FedML
未来展望:DePIN带来AI的民主化
有朝一日,AI进一步发展为AGI,彼时算力将成为事实上的通用货币,DePIN使得这一过程提前发生。
AI和DePIN的融合开启了一个崭新的技术增长点,为人工智能的发展提供了巨大的机遇。DePIN为AI提供了海量的分布式算力和数据,有助于训练更大规模的模型,实现更强的智能。同时,DePIN也使AI向着更加开放、安全、可靠的方向发展,减少对单一中心化基础设施的依赖。
展望未来,AI和DePIN将不断协同发展。分布式网络将为训练超大模型提供强大基础,这些模型又将在DePIN的应用中发挥重要作用。在保护隐私和安全的同时,AI也将助力DePIN网络协议和算法的优化。我们期待着AI和DePIN带来更高效、更公平、更可信的数字世界。
现在是时候将 AI 视频计算功能引入Livepeer了
JinseFinanceRonin 因其与 Web3 游戏《Axie Infinity》的合作而闻名,它为数百万每日活跃用户提供服务,并管理着巨大的交易量(迄今为止 NFT 交易量已超过 40 亿美元),从而证明了自己的可靠性。
 BrianJinseFinance
BrianJinseFinance美国出台法案限制中国在区块链和加密货币领域的作用,旨在保护国家安全和数据隐私。
 Hui Xin
Hui XinOP Labs 在乐观的 Goerli 测试网络中引入防错系统,为去中心化超级链生态系统铺平道路。
 Bitcoinworld
Bitcoinworld昨天,万事达卡宣布计划推出万事达卡多令牌网络 (MTN) 的测试版。
 Ledgerinsights
LedgerinsightsSOL 价格已跌至 2021 年 3 月以来的最低点。
 Beincrypto
Beincrypto事实证明,以太坊既是新区块链协议的突破,也是制约因素。
 Cointelegraph
Cointelegraph比特币网络记录了 2022 年 10.65 吉瓦 (GW) 的最低电力需求。在高峰期,BTC 网络需要 16.09 GW 的电力。
Cointelegraph随着实际采用的增长,比特币第二层扩展解决方案闪电网络的支付额增长超过400%。
Cointelegraph