إن ردود DeepSeek المتكررة "الخادم مشغول، يرجى المحاولة مرة أخرى لاحقًا" تدفع المستخدمين في جميع أنحاء العالم إلى الجنون.
أصبحت شركة DeepSeek، التي لم تكن معروفة جيدًا للجمهور من قبل، مشهورة بإطلاق نموذج اللغة V3 في 26 ديسمبر 2024، والذي يمكن مقارنته بـ GPT 4o. في 20 يناير، أصدرت شركة DeepSeek نموذج اللغة R1، وهو قابل للمقارنة بـ OpenAI o1. وفي وقت لاحق، وبفضل الجودة العالية للإجابات التي تم إنشاؤها بواسطة وضع "التفكير العميق" وإبداعه الذي يكشف عن إشارات إيجابية تفيد بأن التكلفة الأولية لتدريب النموذج قد تنخفض بشكل حاد، أصبحت الشركة وتطبيقها مشهورين تمامًا. منذ ذلك الحين، كان DeepSeek R1 يعاني من الازدحام. فقد أصبحت وظيفة البحث عبر الإنترنت مشلولة بشكل متقطع، وكان وضع التفكير العميق يطلب بشكل متكرر "الخادم مشغول". وقد تسببت هذه الظاهرة في مشاكل كبيرة للعديد من المستخدمين.
قبل أكثر من اثني عشر يومًا، بدأ برنامج DeepSeek يعاني من انقطاع الخدمة. وفي ظهر يوم 27 يناير، عرض الموقع الرسمي لبرنامج DeepSeek رسالة "صفحة الويب/واجهة برمجة التطبيقات الخاصة ببرنامج DeepSeek غير متاحة" عدة مرات. وفي نفس اليوم، أصبح برنامج DeepSeek التطبيق الأكثر تنزيلًا على iPhone خلال عطلة نهاية الأسبوع، متجاوزًا تطبيق ChatGPT في قائمة التنزيلات في الولايات المتحدة.
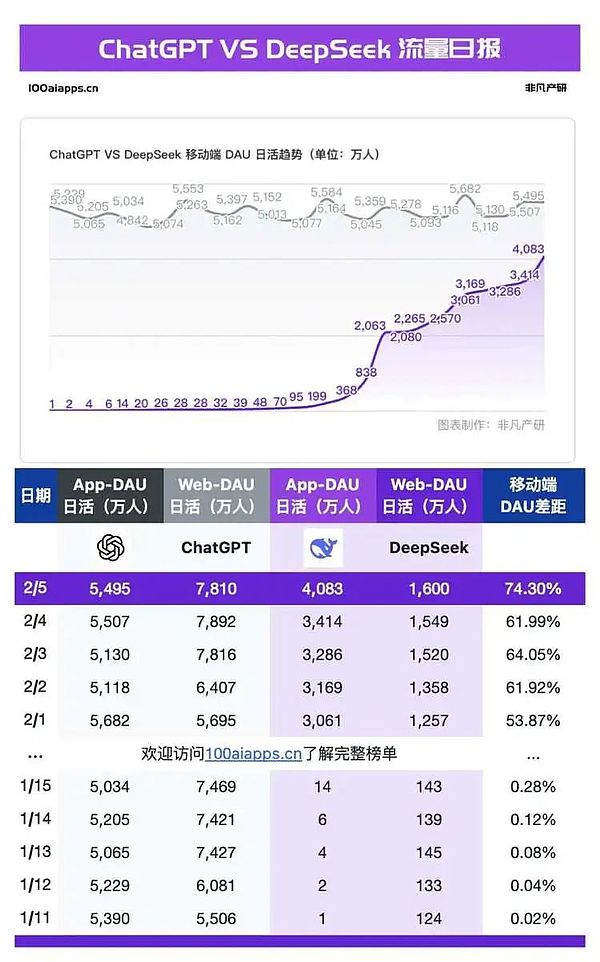
في 5 فبراير، بعد 26 يومًا من إطلاق DeepSeek على الهاتف المحمول، تجاوز عدد مستخدميه النشطين يوميًا 40 مليونًا. بلغ عدد مستخدمي ChatGPT النشطين يوميًا على الهاتف المحمول 54.95 مليونًا، وبلغت حصة DeepSeek 74.3% من مستخدمي ChatGPT. في نفس الوقت تقريبًا الذي كانت فيه شركة DeepSeek في منحنى نموها الحاد، توالت الشكاوى حول خوادمها المزدحمة واحدة تلو الأخرى. بدأ المستخدمون في جميع أنحاء العالم يعانون من إزعاج تعطل الخادم بعد طرح بضعة أسئلة. كما بدأت طرق الوصول البديلة المختلفة في الظهور، مثل موقع DeepSeek البديل. وانطلقت شركات تقديم الخدمات السحابية الكبرى ومصنعو الرقائق وشركات البنية الأساسية عبر الإنترنت، وانتشرت دروس النشر الشخصية في كل مكان. لكن جنون الناس لم يهدأ: فقد ادعت جميع الشركات المصنعة الكبرى في العالم تقريبًا دعمها لنشر DeepSeek، لكن المستخدمين من جميع أنحاء العالم ما زالوا يشكون من عدم استقرار الخدمة.
ما الذي حدث بالضبط وراء هذا؟
1.الأشخاص الذين اعتادوا على ChatGPT لا يمكنهم تحمل عدم قدرة DeepSeek على الفتح
يأتي استياء الأشخاص من "خادم DeepSeek مشغول" من حقيقة أن تطبيقات الذكاء الاصطناعي الرائدة التي كانت تعتمد على ChatGPT نادراً ما كانت تعاني من أي تأخير. منذ إطلاق خدمات OpenAI، واجه ChatGPT العديد من الانقطاعات على مستوى P0 (مستوى الحادث الأكثر خطورة)، ولكن بشكل عام، فهو موثوق نسبيًا، وقد وجد توازنًا بين الابتكار والاستقرار، وأصبح تدريجيًا مكونًا رئيسيًا مشابهًا للخدمات السحابية التقليدية.
<الشكل النمط = "text-align:"> > تعطل ChatGpt على نطاق واسع ليس متكررًا جدًا
عملية التفكير في chatgpt مستقرة نسبيًا ، بما في ذلك خطوتين: الترميز وفك التشفير. مرحلة الترميز تعمل على تحويل النصوص المسبقة إلى أن يتم إنشاء نص واحد إلى أن يكون هناك تبنية على الجمل المقبل. يتم إنشاء المتطلبات.
على سبيل المثال، إذا سألت ChatGPT، "كيف تشعر اليوم؟"، فسوف يقوم ChatGPT بترميز هذه الجملة، وإنشاء تمثيلات انتباه لكل طبقة، والتنبؤ برمز الإخراج الأول "I" بناءً على تمثيلات الانتباه لجميع الرموز السابقة. ثم يقوم بفك تشفير "I" وربطها بـ "كيف تشعر اليوم؟"، ثم الحصول على "كيف تشعر اليوم؟ أنا"، والحصول على تمثيل انتباه جديد، ثم التنبؤ بالرمز التالي: "的"، ثم اتباع الخطوتين الأولى والثانية في حلقة، وأخيراً الحصول على "كيف تشعر اليوم؟ أنا في مزاج جيد".
Kubernetes، وهي أداة لتنظيم الحاويات، هي "القائد خلف الكواليس" لـ ChatGPT. وهي مسؤولة عن جدولة وتخصيص موارد الخادم. عندما يتجاوز تدفق المستخدمين سعة مستوى التحكم في Kubernetes بشكل كامل، سيتم شلل نظام ChatGPT بشكل كامل.
العدد الإجمالي للمرات التي تم فيها شل ChatGPT ليس كثيرًا، ولكن هذا يرجع إلى اعتماده على موارد قوية للدعم وقوة حوسبة قوية للحفاظ على التشغيل المستقر، وهو ما يتجاهله الناس.
بشكل عام، بما أن مقياس البيانات في معالجة الاستدلال يكون أصغر في كثير من الأحيان، فإن متطلبات قوة الحوسبة ليست عالية مثل متطلبات التدريب. وقد قدر المطلعون على الصناعة أنه أثناء عملية الاستدلال على النموذج الكبير الطبيعي، تشغل معلمات النموذج غالبية ذاكرة الرسومات، حيث تمثل أكثر من 80%. الحقيقة هي أنه بين النماذج المتعددة المضمنة في ChatGPT، يكون حجم النموذج الافتراضي أصغر من 671B في DeepSeek-R1. بالإضافة إلى ذلك، يتمتع ChatGPT بقوة حوسبة GPU أكبر بكثير من DeepSeek، لذا فهو يُظهر بشكل طبيعي أداءً أكثر استقرارًا من DS-R1.
يعتبر كل من DeepSeek-V3 وR1 من طرازات 671B. عملية بدء تشغيل النموذج هي عملية الاستدلال. يجب أن يتناسب احتياطي طاقة الحوسبة أثناء الاستدلال مع عدد المستخدمين. على سبيل المثال، إذا كان هناك 100 مليون مستخدم، فمن الضروري تجهيز بطاقات الرسومات لـ 100 مليون مستخدم. هذا ليس ضخمًا فحسب، بل إنه أيضًا مستقل عن احتياطي طاقة الحوسبة أثناء التدريب ولا علاقة له بذلك. بناءً على المعلومات الواردة من جميع الجهات، فمن الواضح أن بطاقة الرسومات الخاصة بجهاز DS واحتياطيات الطاقة الحاسوبية غير كافية، لذا فإنه يتجمد بشكل متكرر.
هذا النوع من التباين ليس مألوفًا للمستخدمين الذين اعتادوا على تجربة ChatGPT السلسة، خاصةً عندما يتزايد اهتمامهم بـ R1. 2.عالق، عالق، وعالق
وعلاوة على ذلك، تظهر المقارنة الدقيقة أن المواقف التي واجهتها OpenAI وDeepSeek مختلفة تمامًا.
الأول مدعوم من قبل مايكروسوفت. وباعتبارها المنصة الحصرية لـ OpenAI، فإن خدمة Microsoft Azure السحابية مجهزة بـ ChatGPT ومولد الصور Dalle-E 2 وأداة الترميز التلقائي GitHub Copilot. ومنذ ذلك الحين، أصبح هذا المزيج النموذج الكلاسيكي للسحابة + الذكاء الاصطناعي وسرعان ما أصبح المعيار الصناعي. وعلى الرغم من أن الأخير عبارة عن شركة ناشئة، إلا أنه يعتمد على مراكز البيانات التي تم بناؤها ذاتيًا في معظم الحالات، على غرار Google، ولا يعتمد على موفري الحوسبة السحابية من جهات خارجية. بعد التحقق من المعلومات العامة، وجدت شركة Silicon Star أن DeepSeek لم تتعاون مع بائعي الخدمات السحابية ومصنعي الرقائق على أي مستوى (على الرغم من أن بائعي الخدمات السحابية أعلنوا خلال مهرجان الربيع أنهم سيشغلون نماذج DeepSeek عليهم، إلا أنهم لم ينفذوا أي تعاون حقيقي).
وعلاوة على ذلك، شهد DeepSeek نموًا غير مسبوق في عدد المستخدمين، مما يعني أنه كان لديه وقت أقل للاستعداد للمواقف العصيبة مقارنة بـ ChatGPT. يأتي الأداء الجيد لـ DeepSeek من تحسينه الشامل على مستوى الأجهزة والنظام. أنفقت شركة Huanfang Quant، الشركة الأم لشركة DeepSeek، 200 مليون دولار لبناء مجموعة الحوسبة الفائقة Firefly-1 في وقت مبكر من عام 2019. وبحلول عام 2022، كانت قد خزنت بهدوء عشرات الآلاف من بطاقات الرسوميات A100. ومن أجل تحقيق تدريب متوازي أكثر كفاءة، طورت DeepSeek إطار عمل تدريب HAI LLM الخاص بها. تعتقد الصناعة أن مجموعة Firefly قد تستخدم الآلاف إلى عشرات الآلاف من وحدات معالجة الرسوميات عالية الأداء (مثل NVIDIA A100/H100 أو الرقائق المحلية) لتوفير قدرات حوسبة متوازية قوية. في الوقت الحالي، يدعم Firefly Cluster تدريب نماذج مثل DeepSeek-R1 وDeepSeek-MoE. تعمل هذه النماذج على مستوى قريب من GPT-4 في المهام المعقدة مثل الرياضيات والترميز. تمثل مجموعة Firefly Cluster استكشاف DeepSeek للهندسة المعمارية والأساليب الجديدة، كما أنها تجعل العالم الخارجي يعتقد أنه من خلال هذا النوع من التكنولوجيا المبتكرة، نجحت DS في خفض تكلفة التدريب ويمكنها تدريب R1 بأداء مماثل لأداء نماذج الذكاء الاصطناعي العليا مع جزء بسيط فقط من قوة الحوسبة الموجودة في النماذج الغربية الأكثر تقدمًا. وقد حسبت شركة SemiAnalysis أن DeepSeek تمتلك في الواقع احتياطيًا ضخمًا من قوة الحوسبة: حيث تمتلك DeepSeek ما مجموعه 60,000 بطاقة معالجة رسومية من NVIDIA، بما في ذلك 10,000 بطاقة A100، و10,000 بطاقة H100، و10,000 بطاقة "إصدار خاص" من H800، و30,000 بطاقة "إصدار خاص" من H20.
يبدو أن هذا يعني أن R1 لديه إمدادات كافية من البطاقات. ولكن في الواقع، كنموذج استدلالي، يتم مقارنة R1 بـ O3 من OpenAI. يتطلب هذا النوع من نماذج الاستدلال نشر المزيد من قوة الحوسبة لمرحلة الاستجابة. ومع ذلك، ليس من الواضح ما إذا كانت قوة الحوسبة التي يوفرها DS على جانب تكلفة التدريب أو الزيادة المفاجئة في قوة الحوسبة على جانب تكلفة الاستدلال أعلى.
من الجدير بالذكر أن DeepSeek-V3 و DeepSeek-R1 كلاهما نماذج لغوية كبيرة، لكنهما يعملان بشكل مختلف. DeepSeek-V3 هو نموذج تعليمات، مشابه لـ ChatGPT، والذي يتلقى الكلمات السريعة ويولد النص المقابل للرد. لكن DeepSeek-R1 هو نموذج استدلال. فعندما يسأل المستخدم R1 سؤالاً، فإنه سيقوم أولاً بإجراء قدر كبير من عملية الاستدلال ثم يقوم بإنشاء الإجابة النهائية. أول ما يظهر في الرمز الذي يولده R1 هو عدد كبير من عمليات سلسلة التفكير. قبل توليد الإجابة، سيقوم النموذج أولاً بشرح المشكلة وتحليلها. سيتم توليد كل عمليات التفكير هذه بسرعة في شكل رموز.
في وجهة نظر Wen Tingcan ، نائب رئيس Yaotu Capital ، يشير احتياطي الحوسبة الضخمة المذكورة أعلاه في مرحلة التدريب التي يمكن أن تتنافس عليها. إلى قاعدة معينة ، ولكن نظرًا لأن Deepseek أصبح منتجًا هائلًا ، فقد انفجر مقياس المستخدم واستخدامه في فترة زمنية قصيرة ، مما أدى إلى نمو متفجر في الطلب على قوة الحوسبة في مرحلة الاستدلال ، لذلك هناك تشويش 140 سوقًا في جميع أنحاء العالم ، لا يمكن أن تستمر DS من خلال البطاقات الحالية على أي حال ، حتى مع وجود بطاقات جديدة ، لأن "الأمر يستغرق وقتًا لبناء سحابة مع بطاقات جديدة". "إن تكلفة تشغيل NVIDIA A100 وH100 ورقائق أخرى لمدة ساعة واحدة لها سعر سوقي عادل. من منظور تكلفة الاستدلال لإخراج الرموز، فإن DeepSeek أرخص بنسبة تزيد عن 90٪ من نموذج OpenAI المماثل o1، وهو لا يختلف كثيرًا عن حسابات الجميع. لذلك، فإن بنية النموذج MOE نفسها ليست المشكلة الرئيسية، ولكن عدد وحدات معالجة الرسومات التي تمتلكها DS يحدد الحد الأقصى لعدد الرموز التي يمكنهم إنتاجها في الدقيقة. حتى إذا كان من الممكن استخدام المزيد من وحدات معالجة الرسومات لخدمات الاستدلال للمستخدمين بدلاً من البحث المسبق للتدريب، فإن الحد الأقصى موجود." لدى Chen Yunfei، مطور تطبيق الذكاء الاصطناعي الأصلي Kitten Fill Light، وجهة نظر مماثلة. ذكر بعض المطلعين على الصناعة أيضًا لـ Silicon Star أن السبب الجذري لتأخر DeepSeek هو أن السحابة الخاصة ليست مبنية بشكل جيد.
تعد هجمات القراصنة عاملًا آخر وراء تأخر R1. في 30 يناير، علمت وسائل الإعلام من شركة الأمن السيبراني Qi'anxin أن شدة الهجمات على الخدمات عبر الإنترنت لشركة DeepSeek تصاعدت فجأة، حيث زادت أوامر الهجوم مئات المرات مقارنة بـ 28 يناير. لاحظت شركة Qi'anxin Xlab أن شبكتين من الروبوتات على الأقل كانتا متورطتين في الهجوم. ومع ذلك، هناك حل واضح على ما يبدو للتأخير في خدمات R1، وهو أن يكون هناك طرف ثالث يقدم الخدمات. وهذا أيضًا هو المشهد الأكثر حيوية الذي شهدناه خلال مهرجان الربيع - حيث قامت العديد من الشركات المصنعة بنشر خدمات لتلبية طلب الناس على DeepSeek.
في الحادي والثلاثين من يناير، أعلنت شركة NVIDIA أن NVIDIA NIM يمكنها الآن استخدام DeepSeek-R1. في السابق، تبخرت القيمة السوقية لشركة NVIDIA بما يقرب من 600 مليار دولار بين عشية وضحاها بسبب تأثير DeepSeek. في اليوم نفسه، يمكن لمستخدمي Amazon Cloud AWS نشر أحدث طراز أساسي R1 من DeepSeek في منصة الذكاء الاصطناعي الخاصة بها، Amazon Bedrock وAmazon SageMaker AI. وفي وقت لاحق، تم ربط تطبيقات الذكاء الاصطناعي الجديدة، بما في ذلك Perplexity وCursor، بـ DeepSeek على دفعات. كانت شركة Microsoft هي الأولى في نشر DeepSeek-R1 على خدمات السحابة Azure وGithub، متقدمة على Amazon وNvidia.
بدءًا من الأول من فبراير، وهو اليوم الرابع من السنة الصينية الجديدة، انضمت أيضًا Huawei Cloud وAlibaba Cloud وVolcano Engine من Bytedance وTencent Cloud. وهم يقدمون عمومًا خدمات نشر النموذج الكامل والحجم الكامل من DeepSeek. وتأتي بعد ذلك شركات تصنيع شرائح الذكاء الاصطناعي مثل BiRen Technology، وHanbo Semiconductor، وAscend، وMuxi، التي تدعي أنها قامت بتكييف النسخة الأصلية من DeepSeek أو نسخة مقطرة أصغر حجمًا. أما بالنسبة لشركات البرمجيات، فقد قامت UFIDA وKingdee وغيرهما بدمج نموذج DeepSeek في بعض منتجاتها لتعزيز قوة المنتج. وأخيرًا، قامت شركات تصنيع المحطات الطرفية مثل Lenovo وHuawei وHonor بدمج نموذج DeepSeek في بعض منتجاتها لاستخدامها كمساعدين شخصيين في الطرف النهائي وكابينة قيادة السيارات الذكية. حتى الآن، نجحت شركة DeepSeek في جذب دائرة شاملة وكبيرة من الأصدقاء بالاعتماد على قيمتها الخاصة، بما في ذلك مصنعو السحابة، والمشغلون، وشركات الأوراق المالية، ومنصات الإنترنت الوطنية للحوسبة الفائقة في الداخل والخارج. نظرًا لأن DeepSeek-R1 هو نموذج مفتوح المصدر تمامًا، فقد أصبح جميع مزودي الخدمة الذين يمكنهم الوصول إليه مستفيدين من نموذج DS. من ناحية أخرى، أدى هذا إلى زيادة شعبية DS بشكل كبير، ولكن في الوقت نفسه تسبب أيضًا في حدوث حالات تجميد متكررة. كان مزود الخدمة وDS نفسه يعانيان من مشاكل متزايدة بسبب تدفق المستخدمين، ولم يتمكن أي منهما من العثور على المفتاح لحل مشكلة الاستخدام المستقر.
بالنظر إلى أن الإصدارات الأصلية من طرازي DeepSeek V3 وR1 تحتوي على 671 مليار معلمة، فهي مناسبة للتشغيل على السحابة. يتمتع بائعو السحابة أنفسهم بقوة حوسبة وقدرات استدلالية كافية. لقد أطلقوا خدمات نشر مرتبطة بـ DeepSeek لخفض عتبة الاستخدام المؤسسي. بعد نشر نموذج DeepSeek، يوفرون واجهة برمجة تطبيقات نموذج DS للعالم الخارجي. وبالمقارنة مع واجهة برمجة التطبيقات التي توفرها DS نفسها، يُعتقد أنها يمكن أن توفر تجربة مستخدم أفضل من DS الرسمي.
ولكن في الواقع، لم يتم حل مشاكل تجربة نموذج DeepSeek-R1 نفسه في الخدمات المختلفة. يعتقد العالم الخارجي أن مقدمي الخدمة لا يعانون من نقص في البطاقات، ولكن في الواقع، فإن R1 الذي نشروه، وتواتر ردود فعل المطورين على التجربة غير المستقرة هو نفسه تمامًا مثل R1. وهذا يرجع إلى أن عدد البطاقات التي يمكن تخصيصها لـ R1 للاستدلال ليس كثيرًا. "لا تزال شعبية R1 مرتفعة، ويتعين على مزودي الخدمة أن يأخذوا في الاعتبار النماذج الأخرى التي يمكن توصيلها. البطاقات التي يمكن توفيرها لـ R1 محدودة للغاية. كما أن R1 تحظى بشعبية كبيرة. بمجرد أن يطلق أي شخص R1 ويقدمه بسعر منخفض نسبيًا، فسوف يطغى عليه الطلب". أوضح مصمم منتجات النماذج والمطور المستقل Gui Zang السبب في ذلك لـ Silicon Star. يعد تحسين نشر النموذج مجالًا واسعًا يغطي العديد من الروابط، من إكمال التدريب إلى النشر الفعلي للأجهزة، ويتضمن عملًا متعدد المستويات، ولكن بالنسبة لحادث تأخر DeepSeek، قد يكون السبب أبسط، مثل نموذج كبير جدًا وإعداد غير كافٍ للتحسين قبل الاتصال بالإنترنت. قبل أن يتم طرح نموذج كبير شائع عبر الإنترنت، فإنه سيواجه العديد من التحديات التي تتعلق بالتكنولوجيا والهندسة والأعمال، مثل الاتساق بين بيانات التدريب وبيانات بيئة الإنتاج، ووقت استجابة البيانات والأداء في الوقت الفعلي الذي يؤثر على استدلال النموذج، وكفاءة الاستدلال عبر الإنترنت واستخدام الموارد مرتفعان للغاية، وقدرات تعميم النموذج غير كافية، والجوانب الهندسية مثل استقرار الخدمة وتكامل واجهة برمجة التطبيقات والنظام، وما إلى ذلك.
تعلق العديد من النماذج الكبيرة الشائعة أهمية كبيرة على تحسين الاستدلال قبل الاتصال بالإنترنت. ويرجع ذلك إلى مشاكل وقت الحوسبة والذاكرة. يشير الأول إلى أن تأخير الاستدلال طويل جدًا، مما يؤدي إلى تجربة مستخدم سيئة، وحتى لا يمكنه تلبية متطلبات التأخير، أي ظاهرة التشويش. يشير الأخير إلى العدد الكبير من معلمات النموذج، واستهلاك ذاكرة الفيديو، وحتى بطاقة GPU واحدة لا يمكن أن تلائم، مما سيؤدي أيضًا إلى التشويش.
شرح وين تينغكان السبب لـ Silicon Star. وقال إن مقدمي الخدمات واجهوا تحديات في تقديم خدمات R1. وكان جوهر الأمر هو أن بنية نموذج DS كانت خاصة وكان النموذج كبيرًا جدًا + MOE (هيكل مختلط من الخبراء، طريقة للحوسبة الفعّالة). "يستغرق تحسين (مقدمي الخدمات) وقتًا، لكن حرارة السوق لها نافذة زمنية، لذا فإنهم جميعًا ينتقلون عبر الإنترنت أولاً ثم يقومون بالتحسين، بدلاً من التحسين الكامل ثم الانتقال عبر الإنترنت."
لكي يعمل R1 بشكل مستقر، يكمن جوهر الأمر الآن في قدرات الاحتياطي والتحسين على جانب الاستدلال. ما يتعين على DeepSeek فعله هو إيجاد طريقة لتقليل تكلفة الاستدلال، وتقليل إخراج البطاقة، وتقليل عدد رموز الإخراج الفردية.
في الوقت نفسه، يُظهر التأخير أيضًا أن احتياطي الطاقة الحاسوبية لـ DS نفسه قد لا يكون ضخمًا كما ذكرت شركة SemiAnalysis. تحتاج شركة Huanfang Fund إلى بطاقات، ويحتاج فريق تدريب DeepSeek أيضًا إلى بطاقات. لا يوجد العديد من البطاقات التي يمكن تخصيصها للمستخدمين. وفقًا لحالة التطوير الحالية، قد لا يكون لدى DeepSeek الدافع لدفع تكاليف استئجار الخدمات في الأمد القريب ثم تقديم تجربة أفضل للمستخدمين مجانًا. من المرجح أن ينتظروا حتى يتم فرز الموجة الأولى من نماذج الأعمال C-end قبل النظر في قضية استئجار الخدمة. وهذا يعني أيضًا أن التأخير سيستمر لفترة طويلة. "ربما يحتاجون إلى خطوتين: 1) إنشاء آلية دفع للحد من استخدام نماذج المستخدم المجانية؛ 2) العثور على مزودي خدمات سحابية للتعاون واستخدام موارد وحدة معالجة الرسوميات الخاصة بأشخاص آخرين." وقد اكتسب الحل المؤقت الذي قدمه المطور تشين يونفي إجماعًا كبيرًا في الصناعة.
ولكن في الوقت الحالي، لا يبدو أن شركة DeepSeek تشعر بالقلق إزاء مشكلة "خادمها المزدحم". وباعتبارها شركة تسعى إلى تحقيق الذكاء الاصطناعي العام، يبدو أن شركة DeepSeek مترددة في التركيز بشكل كبير على تدفق حركة المستخدمين. قد يتعين على المستخدمين التعود على مواجهة واجهة "الخادم مشغول" لفترة من الوقت في المستقبل.
Preview
احصل على فهم أوسع لصناعة العملات المشفرة من خلال التقارير الإعلامية، وشارك في مناقشات متعمقة مع المؤلفين والقراء الآخرين ذوي التفكير المماثل. مرحبًا بك للانضمام إلينا في مجتمع Coinlive المتنامي:https://t.me/CoinliveSG


 > تعطل ChatGpt على نطاق واسع ليس متكررًا جدًا
> تعطل ChatGpt على نطاق واسع ليس متكررًا جدًا  JinseFinance
JinseFinance



