جي بي مورغان: بيتكوين "تجاوزت" الذهب
يظهر أحد المؤشرات أن عملة البيتكوين أصبحت أكثر شعبية من الذهب في محافظ المستثمرين، حيث يواصل سعرها الوصول إلى مستويات قياسية جديدة، وفقا لتقرير صادر عن بنك جيه بي مورجان تشيس يوم الخميس.
 JinseFinance
JinseFinance

المصدر: Zeping Macro
في 16 فبراير، أصدرت OpenAI نموذج إنشاء الفيديو Sora، والذي أدى إلى توسيع قدرات الذكاء الاصطناعي بشكل كبير في إنشاء محتوى الفيديو. يتقدم Sora بشكل كبير على بعض نماذج توليد الفيديو السابقة في المؤشرات الرئيسية، وإذا استخدمته لإنشاء مقاطع فيديو، فستجد أن قدرات المحاكاة المكانية للعالم المادي قد وصلت إلى مستوى قريب من الواقع.
لماذا يمكن تسمية Sora بعلامة فارقة جديدة في صناعة الذكاء الاصطناعي؟ كيف يمكن اختراق AIGC، الحد الأعلى لإنشاء محتوى الذكاء الاصطناعي؟ من الناحية الموضوعية، هل هناك أي قيود أو عيوب في الإصدار الحالي من سورا؟
ما هو اتجاه التحديثات والتكرارات المستقبلية لنماذج إنشاء الفيديو مثل Sora؟ ما هي الصناعات التي سيؤدي ظهورها إلى تعطيلها؟ وما هو تأثيرها على كل واحد منا؟ ما هي فرص الصناعة الجديدة وراء ذلك؟
السبب الذي يجعل Sora أحد إنجازات الذكاء الاصطناعي هو أنه يخترق مرة أخرى الحد الأعلى لإنشاء المحتوى المعتمد على الذكاء الاصطناعي لـ AIGC. في السابق، بدأ الجميع في استخدام إنشاء المحتوى النصي مثل Chatgpt للمساعدة في الرسم التوضيحي وإنشاء الشاشة، واستخدام البشر الافتراضيين لإنشاء مقاطع فيديو قصيرة. سورا هو نموذج كبير لتوليد الفيديو. يمكن إنشاء مقاطع الفيديو وتوصيلها وتوسيعها وتحريرها عن طريق إدخال نص أو صور. وهو ينتمي إلى فئة النماذج الكبيرة متعددة الوسائط. هذا النوع من النماذج هو امتداد إضافي لنماذج اللغات الكبيرة مثل مثل GPT. يتعامل Sora مع "تصحيحات" الفيديو بطريقة مشابهة لكيفية عمل GPT-4 على الرموز النصية. الابتكار الرئيسي لهذا النموذج هو التعامل مع إطارات الفيديو كتسلسلات من التصحيحات، على غرار الرموز المميزة للكلمات في نماذج اللغة، مما يسمح لها بإدارة مجموعة متنوعة من مقاطع الفيديو بشكل فعال. يتيح هذا النهج، جنبًا إلى جنب مع الإنشاء المشروط بالنص، لـ Sora إنشاء مقاطع فيديو ذات صلة بالسياق ومتماسكة بصريًا استنادًا إلى الإشارات النصية.
من حيث المبدأ، يقوم Sora بشكل أساسي بتنفيذ التدريب عبر الفيديو من خلال ثلاث خطوات. الأولى هي شبكة ضغط الفيديو، والتي تعمل على تقليل أبعاد مقاطع الفيديو أو الصور إلى شكل مضغوط وفعال. والثاني هو استخراج التصحيح الزماني المكاني، والذي يقوم بتحليل معلومات العرض إلى وحدات أصغر. تحتوي كل وحدة على جزء من المعلومات المكانية والزمانية في العرض، حتى يتمكن Sora من تنفيذ المهام المستهدفة في الخطوات اللاحقة . التعامل مع. الخطوة الأخيرة هي إنشاء الفيديو. يتم إدخال النصوص أو الصور لفك التشفير والتشفير. ويحدد نموذج Transformer (أي محول ChatGPT الأساسي) كيفية تحويل هذه الوحدات أو دمجها لتكوين محتوى كامل في النص والمطالبات بالصور والفيديو.
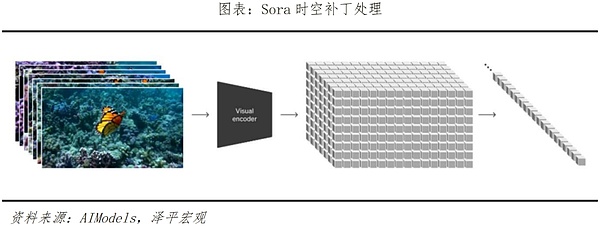
أهم مؤشرين لسورا في نموذج إنشاء الفيديو—— يتفوق بشكل كبير على النماذج السابقة من حيث المدة والدقة، ويتمتع بقدرات قوية على فهم النص وعمقه وتوليد التفاصيل، ويمكن القول إنه منتج بارز آخر في صناعة الذكاء الاصطناعي. قبل إصدار Sora، كان وقت إنشاء النماذج الرئيسية مثل Pika1.0 وEmu Video وGen-2 يتراوح بين 3 إلى 7 ثوانٍ و4 ثوانٍ و4 إلى 16 ثانية على التوالي؛ بينما كان بإمكان Sora إنشاء أوقات ما يصل إلى 60 ثانية، والتي يمكن تحقيق دقة 1080 بكسل، ولا يستطيع Sora إنشاء مقاطع فيديو بناءً على المطالبات النصية فحسب، بل يتمتع أيضًا بقدرات تحرير وتوسيع الفيديو. يتمتع سورا أيضًا بفهم قوي ومتعمق للنص. بفضل التدريب المكثف على تحليل النص، يستطيع Sora التقاط المعنى العاطفي وراء التعليمات النصية وفهمه بدقة، وتحويل المطالبات النصية بسلاسة وطبيعية إلى محتوى فيديو مفصل ومطابق للمشهد.
يستطيع Sora محاكاة القوانين الفيزيائية للعالم الافتراضي بشكل أفضل في إنشاء الفيديو، وفهم العالم المادي بشكل أفضل، وإنتاج إحساس واقعي بالعدسة. تتضمن ميزاته التقنية بشكل أساسي اثنتين:
أولاً، يمكنه إنشاء مقاطع فيديو متماسكة ثلاثية الأبعاد للحركة الفضائية من عدسات متعددة.
والثاني هو الحفاظ على تناسق نفس الكائن تحت زوايا رؤية مختلفة. وبهذه الطريقة يمكن للنموذج أن يحافظ على تماسك واستمرارية حركة الشخصيات والأشياء والمشاهد في الفيديو، ويمكنه التأثير على العناصر الموجودة في العالم من خلال الضبط الدقيق وإجراء تفاعلات بسيطة. بالمقارنة مع النماذج السابقة مثل Pika، يمكن للفيديو الذي تم إنشاؤه بواسطة Sora أيضًا أن يفهم بدقة عناصر مثل نمط ألوان الفيديو وإنشاء محتوى فيديو بتعبيرات وجه غنية ومشاعر حية. كما أنه يهتم بالعلاقة بين الموضوع والخلفية، مما يجعل التفاعل بين موضوع الفيديو والخلفية سلسًا ومستقرًا للغاية، ويكون تبديل القصة المصورة منطقيًا.
في مثال للفيديو الذي تم إنشاؤه والذي قدمه المسؤول: "امرأة عصرية تسير في شوارع طوكيو المليئة بأضواء النيون الدافئة ولافتات المدينة المتحركة. وهي ترتدي سترة جلدية سوداء ، تنورة طويلة حمراء وحذاء أسود، تحمل حقيبة جلدية سوداء. كانت ترتدي نظارة شمسية وأحمر شفاه أحمر. كانت تمشي بثقة وعفوية. كان الشارع رطبًا وعاكسًا، مما خلق تأثير مرآة مع الأضواء الملونة. سار العديد من المشاة "ذهابًا وإيابًا" ",يحقق Sora وصفًا تفصيليًا تمامًا، حتى وصولاً إلى وصف تفاصيل الجلد، ويكون واقعيًا في معالجة التفاصيل مثل حركة انعكاس الضوء والظل، وحركة العدسة، وما إلى ذلك.

2. ما هو مستوى سورا؟ ما هي القيود؟
يعادل Sora نموذج اللغة ChatGPT3.5، وهو إنجاز كبير في الصناعة وهو على مستوى رائد جدًا، لكنه لا يزال يتمتع بخصائصه الخاصة. محددات.
لدى Sora وChatGPT نفس أصل بنية Transformer، حيث يبني الأول نموذج انتشار يعتمد على البنية، وهو ممتاز في عرض العمق ودوام الكائن والديناميكيات الطبيعية. تم عادةً تشغيل عمليات المحاكاة السابقة للعالم الحقيقي باستخدام محركات الألعاب المعتمدة على وحدة معالجة الرسومات للنمذجة الفيزيائية ثلاثية الأبعاد، والتي تتطلب إنشاءًا يدويًا وعمليات معقدة بدقة عالية لتحقيق محاكاة بيئية عالية المستوى وإجراءات تفاعلية متنوعة. ومع ذلك، فإن نموذج سورا لا يحتوي على محرك فيزيائي يعتمد على البيانات وبرمجة رسومية، كما أن دقته منخفضة في البناء ثلاثي الأبعاد عالي الطلب. ومن ثم، يظل تحقيق محاكاة واقعية لشخصيات متعددة تتفاعل بشكل طبيعي مع البيئة أمرًا صعبًا.
على سبيل المثال، فيما يلي مثالان للأخطاء في مقاطع الفيديو التي أنشأها Sora:
عندما يُدخل Sora النص "سائل مسكوب من زجاج مقلوب." "، الزجاج يظهر في الصورة وهو يذوب في الطاولة، مع قفز السائل عبر الزجاج، ولكن دون أي تأثير لتحطم الزجاج.
على سبيل المثال، تم حفر كرسي فجأة من الشاطئ، ويعتقد الذكاء الاصطناعي أن الكرسي مادة خفيفة للغاية يمكنها أن تطفو مباشرة.

هناك سببان رئيسيان لمثل هذه "الأخطاء":
أولاً، نظرًا لأن النموذج يكمل المحتوى الذي تم إنشاؤه تلقائيًا، فإنه يقوم تلقائيًا بإنشاء كائنات أو كيانات غير مضمنة في خطة النص. وهذا الموقف شائع بشكل خاص، خاصة في مشهد مزدحم أو تشوش. في بعض السيناريوهات، سيؤدي ذلك إلى زيادة واقعية الفيديو، كما هو الحال في حالة "المشي في شوارع اليابان في الشتاء" المقدمة من OpenAI، ولكن في المزيد من البيئات سيقلل من عقلانية القوانين الفيزيائية في الفيديو، مثل حيث أن الطاولة المتولدة من الهواء الرقيق في المثال الأول مصنوعة من الماء.
والثاني هو أنه عند حدوث العديد من الإجراءات في محاكاة سورا، فمن السهل الخلط بين الترتيب، بما في ذلك الترتيب الزمني والترتيب المكاني. على سبيل المثال، عند كتابة "شخص يركض على جهاز المشي"، هناك فرصة لتوليد شخص يمشي على جهاز المشي في الاتجاه الخاطئ. لذلك، يحاكي سورا بدقة التفاعلات الفيزيائية والديناميكيات والعلاقات السببية الأكثر تعقيدًا في العالم الحقيقي، ولا يزال من الصعب محاكاة الفيزياء البسيطة وخصائص الأشياء.
على الرغم من هذه المشكلات المستمرة، يوضح سورا الإمكانات المستقبلية لنماذج الفيديو. ونظرًا لوجود ما يكفي من البيانات والقدرة الحاسوبية، قد تبدأ محولات الفيديو في اكتساب فهم أعمق لفيزياء العالم الحقيقي. ,العلاقة السببية. قد يؤدي هذا إلى تمكين طرق جديدة لتدريب أنظمة الذكاء الاصطناعي بناءً على محاكاة الفيديو للعالم.
تمثل Sora طليعة تقنيات الذكاء الاصطناعي في مجال إنشاء الفيديو، لكن تحسينات أدائها المستقبلية قد تأتي من ثلاثة اتجاهات رئيسية:
الأول هو البدء من بُعد البيانات. مع زيادة الطلب على البيانات لأغراض التدريب، سنواجه مشكلة نقص عينات البيانات القابلة للتدريب في المستقبل. حاليًا، تعتمد النماذج الكبيرة الرئيسية على نص اللغة، وعلى الرغم من أن Sora يمكنه أيضًا إدخال الصور، إلا أن نطاق التدريب ليس جيدًا مثل النص. أنواع البيانات فردية وعالية الجودة محدودة، والتي قد يتم استنفادها بسرعة في سياق الزيادات الأسية في حجم المعلمة.
تُظهر أبحاث جامعة كورنيل أنه من المرجح أن يتم استنفاد البيانات عالية الجودة للتدريب على النماذج الكبيرة قبل عام 2026، وسيتم استنفاد البيانات النصية منخفضة الجودة بعد عام 2030. إن توسيع أبعاد مصادر البيانات هو الحل الذي يقدمه Sora. بالإضافة إلى النصوص والصور، يمكن أن يصبح الصوت والفيديو والطاقة الحرارية والطاقة الكامنة والعمق مجالات توسع لتعلم Sora. ساعده على أن يصبح نموذجًا كبيرًا متعدد الوسائط حقًا. على سبيل المثال، يتمتع برنامج ImageBind مفتوح المصدر من Meta بحواس متعددة، فهو لا يتمتع بقدرات التعرف على الصور والفيديو الخاصة بـ DINOv2 فحسب، بل يحتوي أيضًا على الأشعة تحت الحمراء ووحدات قياس القصور الذاتي، والتي يمكنها استشعار وتعلم أوضاع مختلفة مثل العمق والطاقة الحرارية والإمكانات. طاقة. بعد أن يقوم Sora بتوسيع نهاية الإدخال، يمكنه أيضًا دمج الأبعاد المذكورة أعلاه بشكل أفضل مع إنشاء الفيديو لتدريب ومحاكاة عالم مادي أكثر واقعية.
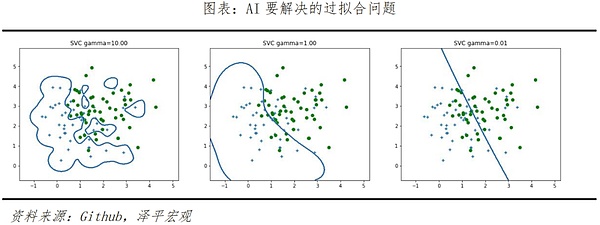
والثاني هو التحسين من مستوى الخوارزمية، ويعد حل ظواهر "الإفراط في الملاءمة" و"عدم الملاءمة" الموجودة في التعلم النموذجي هو المفتاح. كما ذكرنا في المثال السابق، سيقوم Sora تلقائيًا بإنشاء كائنات أو كيانات غير مضمنة في خطة النص، مما يساعد على تحسين صحة تأثير الفيديو. ومع ذلك، في بعض الحالات، قد يظهر عنصران مترابطان للغاية في نفس الوقت في سيناريوهات غير قابلة للتطبيق، أي أن الخوارزمية "تتجاوز" من أجل تحقيق نتيجة محددة. تشبه هذه الظاهرة كيفية تدريب الإنسان بشكل متكرر ومكثف للإجابة على نوع من الأسئلة بشكل صحيح أثناء التحضير للامتحان، ولكنها بدلاً من ذلك تؤدي إلى عدد كبير من الأخطاء في الأسئلة المشابهة في الامتحان.
في نفس المثال، سقط الكوب لكنه انصهر دون أن ينكسر. وذلك لأن النموذج "غير مناسب". والسبب في هذين النوعين من المشاكل في النموذج هو أن العينات التي لم يتم تصنيفها بدقة يتم اختيارها للتدريب، وأن شجرة القرار المتكونة ليست نموذجًا مثاليًا، مما يؤدي إلى انخفاض أداء التعميم للتطبيقات الحقيقية. لا يمكن القضاء على التجاوز والتجهيز بشكل كامل، ولكن يمكن تخفيفهما وتقليلهما من خلال بعض الطرق في المستقبل، مثل: التنظيم، وتنظيف البيانات، وتقليل حجم عينات التدريب، والتخلي عن التسرب، وخوارزميات التقليم، وما إلى ذلك.
والثالث هو صناعة الطاقة الحاسوبية. يواصل سورا تفجير موجة الذكاء الاصطناعي، والتي ستؤدي أيضًا إلى استمرار الطلب على القوة الحاسوبية في عام 2024 في الارتفاع في ظل تطوير نماذج متعددة الوسائط. وتسعى شركات الذكاء الاصطناعي إلى دخول أكبر في سلسلة الصناعة، لرقائق البحث والتطوير و تخطيط التصميم، وحتى EDA والرقائق.التقدم في هذا المجال.
في الوقت الحالي، يعتمد تدريب نماذج الذكاء الاصطناعي بشكل أساسي على وحدات معالجة الرسومات NVIDIA، ولكن رقائق الطاقة الحاسوبية السائدة تعاني بالفعل من نقص في المعروض، ومن المتوقع أن يصل الطلب إلى 1.5-2 مليون بحلول عام 2024.
يولي مؤسس OpenAI Sam Altman اهتمامًا لمسألة العرض والطلب على رقائقه منذ عام 2018. وقد استثمر في شركة شرائح الذكاء الاصطناعي Rain Neuromorphics واشترى رقائق Rain في عام 2019. وفي نوفمبر 2023، سام بدأ العمل في شركة تحمل الاسم الرمزي "شركة شرائح Tigris" وتسعى للحصول على تمويل بمليارات الدولارات. وباعتبارها شركة رائدة في الصناعة، فقد وضعت بالفعل خططًا مبكرة لبناء سلسلة صناعة الطاقة الحاسوبية بقيادة نفسها، بهدف إعادة تشكيل المشهد العالمي لأشباه الموصلات من خلال ثورة صناعة الذكاء الاصطناعي.
تسلا، التي دخلت مسار الذكاء الاصطناعي بالسيارات الذكية، تتجه أيضًا نحو تصميم الرقائق الأولية استنادًا إلى أساسيات خوارزميات القيادة الذاتية، وتسعى تدريجيًا للسيطرة على منتصف الطريق..
من المتوقع أنه على الرغم من أن سلسلة صناعة أشباه الموصلات ذات الذكاء الاصطناعي العالمية التي أنشأتها ARM وNvidia وTSMC هي المستفيد الأكبر على المدى القصير، إلا أنها قد تؤدي إلى منافسة أكبر على المدى المتوسط والطويل. لا يزال البناء المستقل للبنية التحتية للحوسبة، وخاصة رقائق الحوسبة، اتجاهًا مهمًا للصين لمواكبة العالم على مسار الذكاء الاصطناعي.
من إصدار جهاز العرض المثبت على الرأس Vision Pro من Apple في بداية العام، إلى الإصدارات المتعاقبة لـ AIPC من قبل كبرى الشركات المصنعة لأجهزة الكمبيوتر، إلى إصدار Sora بواسطة OpenAI هذه المرة، أصبح العالم أكثر اهتماما بالذكاء الاصطناعي. فالابتكار يتسارع، والتكرار يصبح أسرع فأسرع.
في المستقبل، سيؤثر المحتوى الذي يتم إنشاؤه تلقائيًا باستخدام الذكاء الاصطناعي على العديد من مجالات الصناعة. وستكون "التغطية في الوقت المناسب" للموضوعات الساخنة هي مهمة الذكاء الاصطناعي بشكل أساسي، وستكون المنافسة الرئيسية هي AIGC كفاءة المنافسة هي قدرة الجميع على التحكم في الذكاء الاصطناعي، والمنافسة تدور حول من يمكنه التحكم في أداة إنتاج قوية للذكاء الاصطناعي مثل Sora. في المستقبل، لن يكون من المستحيل "إخراج رواية وإنتاج فيلم رائج". يستطيع Sora إنشاء فيديو تصل مدته إلى دقيقة واحدة. ويمكن تصوير الفيديو حتى النهاية، والتبديل بين زوايا متعددة، ويبقى الكائن دون تغيير. يمكن لمقاطع فيديو Sora أيضًا استخدام لغة العدسات مثل المناظر الطبيعية والتعبيرات والألوان للتعبير عن الألوان العاطفية مثل الوحدة والرخاء والجاذبية. باختصار، إذا ظهر المزيد من Sora في المستقبل، أو إذا خضعت نماذج توليد الفيديو الكبيرة هذه لمزيد من التحسينات والتأخيرات من الزوايا المذكورة أعلاه، فقد تكون تأثيرات فيديو الذكاء الاصطناعي المستقبلية جيدة تقريبًا مثل التصوير اليدوي.
سيبدأ تطبيق النماذج متعددة الوسائط في فجر عام 2024، مما سيؤثر على العديد من الصناعات مثل السينما والتلفزيون والبث المباشر والإعلام والإعلان والرسوم المتحركة والتصميم الفني. في عصر الفيديو القصير الحالي، يتولى سورا "شخص واحد" جميع المهام مثل التصوير والإخراج وتحرير مقاطع الفيديو القصيرة. في المستقبل، سيكون لمقاطع الفيديو المتنوعة التي أنشأها Sora لأغراض مختلفة تأثير عميق على الفيديو القصير الحالي والبث المباشر والسينما والتلفزيون والرسوم المتحركة والإعلان وغيرها من الصناعات.
على سبيل المثال، في مجال إنشاء مقاطع الفيديو القصيرة، من المتوقع أن يؤدي Sora إلى تقليل التكلفة الإجمالية لإنتاج المسرحيات القصيرة بشكل كبير وحل المشكلة الشائعة المتمثلة في "التركيز على الإنتاج ولكن ليس على الإنشاء". ومن المتوقع أن يعود التركيز إلى إنشاء محتوى نصي عالي الجودة في المستقبل، الأمر الذي سيختبر القدرة الإبداعية للمبدعين المتميزين. من المتوقع أن تعمل Sora على تقليل التكاليف وزيادة الكفاءة للشركات في الصناعات ذات الصلة. تستخدم شركات إنتاج الإعلانات نماذج Sora لإنشاء مقاطع فيديو إعلانية تتوافق مع العلامة التجارية، مما يقلل بشكل كبير من تكاليف التصوير وما بعد الإنتاج والألعاب والرسوم المتحركة. تستخدم الشركات Sora لإنشاء الرسوم المتحركة لمشهد الألعاب والشخصيات مباشرة، مما يقلل تكاليف إنتاج النماذج ثلاثية الأبعاد والرسوم المتحركة. ويمكن استخدام التكاليف التي توفرها الشركات لتحسين جودة المنتجات والخدمات أو الابتكار التكنولوجي لزيادة تحسين الإنتاجية. إذا كان عام 2023 هو انفجار النماذج الكبيرة العالمية للذكاء الاصطناعي والعام الأول لإنشاء الصور والنصوص، فإن عام 2024 سيكون العام الذي تدخل فيه الصناعة السنة الأولى لإنشاء فيديو الذكاء الاصطناعي والنماذج الكبيرة متعددة الوسائط. من Chatgpt إلى Sora، يحدث التأثير والتغيرات الحقيقية للذكاء الاصطناعي على كل فرد وكل صناعة تدريجيًا.
يظهر أحد المؤشرات أن عملة البيتكوين أصبحت أكثر شعبية من الذهب في محافظ المستثمرين، حيث يواصل سعرها الوصول إلى مستويات قياسية جديدة، وفقا لتقرير صادر عن بنك جيه بي مورجان تشيس يوم الخميس.
JinseFinanceالتعدين، والنصف، وجي بي مورجان تشيس، وجي بي مورجان تشيس: إن تخفيض بيتكوين إلى النصف سيفيد عمال المناجم المدرجين في جولدن فاينانس، وقال جي بي مورجان تشيس إن حصة عمال المناجم المتداولين علنًا ستزداد بعد النصف.
JinseFinanceينتقد جي بي مورغان سيطرة تيثر على السوق، مشيرًا إلى المخاطر؛ يدافع الرئيس التنفيذي لشركة Tether، مشددًا على التعاون التنظيمي وأهمية الصناعة.
 Brian
Brianيعتقد المحللون أن Tether تواجه أكبر المخاطر بسبب الافتقار إلى الامتثال التنظيمي والشفافية. يبدو أن الدائرة المنافسة لـ Tether تستعد بنشاط للوائح العملة المستقرة القادمة.
JinseFinanceيسلط الجدل الأخير حول إغلاق الحساب الذي أثاره بنك جيه بي مورجان تشيس الضوء على الحاجة إلى الشفافية وخدمة العملاء العادلة في مجال الخدمات المصرفية.
 Cheng Yuan
Cheng Yuanمع وجود JPMorgan كمشارك معتمد، الشركة الوسيطة، يمكن تحقيق ETF أولاً عن طريق تحويل Bitcoin إلى نقد والعكس صحيح.
JinseFinanceمفصلة بعد الوفاة والخطوات التالية
 Others
Othersبمجرد أن نطق عمر فاروق من JP Morgan بعبارة "معظم العملات المشفرة لا تزال غير مهمة" ، أصبحت السلطة النقدية في ...
 Ledgerinsights
Ledgerinsightsأعلنت Fracture Labs ، وهي شركة ألعاب فيديو قائمة على blockchain ، عن تطورات جديدة بعد جولة تمويل ناجحة بقيمة 4.3 مليون دولار في نوفمبر الماضي ...
 Bitcoinist
Bitcoinist机构出逃stETH交易池,加密市场山雨欲来风满楼?
 链向资讯
链向资讯