How MegaETH actually eliminates the gas limit
MegaETH achieves decentralization of computing power and eliminates gas restrictions by splitting full nodes.
 JinseFinance
JinseFinance

Author: knower, crypto KOL; Translation: Jinse Finance xiaozou
The main content of this article will be some of my personal thoughts on the MegaETH white paper, and I may expand further from here if I can. No matter what this article turns out to be, I hope you can learn something new from it.

MegaETH's website is cool because there is a mechanical rabbit on it and the color scheme is very eye-catching. Before this, there was only a Github - having a website makes everything much simpler.
I browsed the MegaETH Github and learned that they are developing some type of execution layer, but I have to be honest, maybe I am wrong about this idea. The fact is, I don’t know enough about MegaETH, and now they are the hot topic on EthCC.
I need to know everything to make sure I see the same technology as the cool guys.
The MegaETH whitepaper says that they are a live EVM-compatible blockchain that aims to bring web2-like performance to the crypto world. Their purpose is to improve the use experience of Ethereum L2 by providing attributes such as over 100,000 transactions per second, sub-millisecond block times, and transaction fees of one cent.
Their whitepaper highlights the growing number of L2s (discussed in one of my previous articles, although the number has climbed to over 50, with more L2s in "active development") and their lack of PMF in the crypto world. Ethereum and Solana are the most popular blockchains, and users will gravitate to one of them, only choosing other L2s if there are tokens to mine.
I don’t think too many L2s are a bad thing, just like I don’t think it’s necessarily a good thing, but I acknowledge that we need to step back and examine why our industry has created so many L2s.
Occam’s razor would say that VCs enjoy the feeling of knowing that they really have a chance to build the next L2 (or L1) king and get satisfaction from investing in these projects, but I also think that perhaps many crypto developers actually want more L2s. Both sides may be right, but the conclusion about which side is more correct is not important, it is better to look at the current infrastructure ecosystem objectively and make the best of what we have.
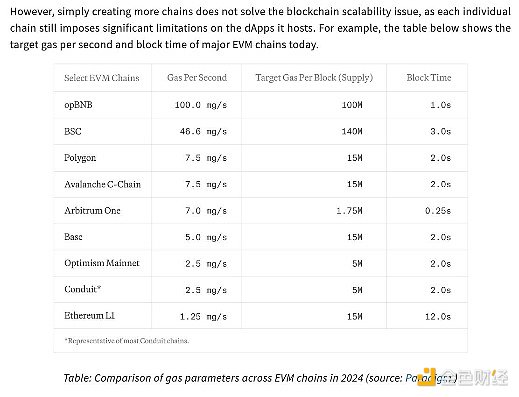
The performance of the L2 we currently have available is high, but not enough. The MegaETH whitepaper says that even with opBNB’s (relatively) high 100 MGas/s, that would only mean 650 Uniswap transactions per second — modern or web2 infrastructure can do 1 million transactions per second.
We know that despite the crypto advantages that come from decentralization and enabling permissionless payments, it’s still pretty slow. If a game development company like Blizzard wanted to bring Overwatch to the chain, they couldn’t do it — we need higher CTRs to provide real-time PvP and other features that web2 games naturally provide.
One of MegaETH’s solutions to the L2 dilemma is to delegate security and censorship resistance to Ethereum and EigenDA respectively, turning MegaETH into the world’s most performant L2 without any trade-offs.
L1 typically requires homogeneous nodes that perform the same tasks with no room for specialization. In this case, specialization refers to work like sorting or proving. L2 bypasses this problem and allows the use of heterogeneous nodes, separating tasks to improve scalability or alleviate some of the burden. This can be seen in the growing popularity of shared sorters (such as Astria or Espresso) and the rise of specialized zk proof services (such as Succinct or Axiom).
“Creating a live blockchain involves more than just using an off-the-shelf Ethereum execution client and adding sorter hardware. For example, our performance experiments show that even with a powerful server equipped with 512GB of RAM, Reth can only achieve about 1000 TPS in a live sync setting on recent Ethereum blocks, equivalent to about 100 MGas/s.”
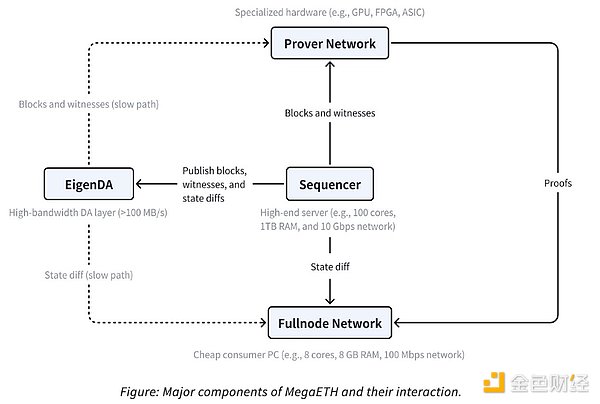
MegaETH extends this partitioning by abstracting transaction execution from full nodes, using only a single “active” sorter to eliminate the consensus overhead in typical transaction execution. “Most full nodes receive state differences from this sorter over the p2p network and apply the differences directly to update their local state. Notably, they do not re-execute transactions; instead, they indirectly validate blocks using proofs provided by provers.” I haven’t read much analysis of how good MegaETH is other than “it’s fast” or “it’s cheap” comments, so I’m going to try to dissect its architecture and compare it to other L2s. MegaETH uses EigenDA to handle data availability, which is pretty standard practice these days. Rollup-as-a-Service (RaaS) platforms like Conduit allow you to choose Celestia, EigenDA, or even Ethereum (if you wish) as the data availability provider for your rollup. The difference between the two is fairly technical and not entirely relevant, and it seems like the decision to choose one over the other is based more on consensus than anything else.
The collator sorts and eventually executes transactions, but is also responsible for publishing blocks, witnesses, and state differences. In the L2 context, a witness is additional data that the prover uses to verify the collator's blocks.
State differences are changes to the blockchain state, and can be basically anything that happens on the chain - the function of a blockchain is to constantly append and verify new information added to its state, and the function of these state differences is to allow full nodes to confirm transactions without re-executing them.
Provers consist of special hardware that compute cryptographic proofs to verify block contents. They also allow nodes to avoid double-executing. There are zero-knowledge proofs and fraud proofs (or are they optimistic proofs?), but the distinction between them is not important right now.
Putting all of this together is the task of the full node network, which acts as a kind of aggregator between provers, collators, and EigenDA to (hopefully) make the MegaETH magic a reality.
MegaETH's design is based on a fundamental misunderstanding of EVM. Although L2 often blames EVM for its poor performance (throughput), it has been found that revm can reach 14,000 TPS. If it's not EVM, what's the reason?
The three main EVM inefficiencies that lead to performance bottlenecks are lack of parallel execution, interpreter overhead, and high state access latency.
Due to the abundance of RAM, MegaETH is able to store the state of the entire blockchain, with Ethereum's exact RAM being 100GB. This setup speeds up state access significantly by eliminating SSD read latency.
I don't know much about SSD read latency, but presumably some opcodes are more intensive than others, and if you throw more RAM at the problem, you can abstract it away. Does this still work at scale? I'm not sure, but for this post, I'll take it as fact. I'm still skeptical that chains can determine throughput, transaction costs, and latency all at once, but I'm trying to be an active learner.
Another thing I should mention is that I don't want to be overly picky. My idea is to never favor one protocol over another, or even to value them equally at the beginning - I'm only doing this to gain better understanding, and to help anyone reading this post gain the same understanding at the same time. You may be familiar with the trend of parallel EVM, but there is a problem. Although progress has been made in porting the Block-STM algorithm to the EVM, it is said that "the actual speedup that can be achieved in production is inherently limited by the available parallelism in the workload." This means that even if parallel EVM is released and eventually deployed to the EVM chain on the mainnet, the technology is limited by the basic reality that most transactions may not need to be executed in parallel. If transaction B depends on the result of transaction A, you can't execute two transactions at the same time. If 50% of the block transactions are interdependent like in this case, then parallel execution is not a significant improvement as claimed. While this statement is a bit of an oversimplification (and maybe even a little incorrect), I think it hits the point.
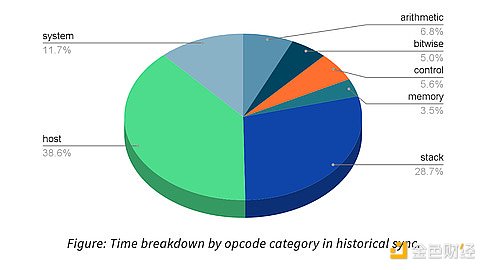
The gap between Revm and native execution is quite significant, especially as Revm is still 1-2 OOMs slower and not worth using as a standalone VM environment. It was also found that there are not enough compute-intensive contracts to warrant the use of Revm at this time. "For example, we analyzed the time spent on each opcode during historical synchronization and found that about 50% of the time in Revm was spent on "host" and "system" opcodes."
In terms of state synchronization, MegaETH found more problems. State synchronization is simply described as a process of synchronizing a full node with sorter activity, a task that can quickly consume the bandwidth of a project like MegaETH. Here’s an example to illustrate this: If the goal is to sync 100,000 ERC20 transfers per second, this would consume about 152.6 Mbps of bandwidth. This 152.6 Mbps is said to exceed MegaETH’s estimates (or performance), essentially introducing an impossible task.
This only takes into account simple token transfers, and ignores the possibility of higher consumption if transactions are more complex. This is a possible scenario given the diversity of on-chain activity in the real world. MegaETH writes that Uniswap transactions modify 8 storage slots (while ERC20 transfers only modify 3 storage slots), bringing our total bandwidth consumption to 476.1 Mbps, a much more unfeasible goal.
Another problem with achieving a 100k TPS high-performance blockchain lies in resolving updates to the chain state root, which is a task that manages sending storage proofs to light clients. Even with specialized nodes, full nodes still need to use the network’s sorter nodes to maintain the state root. Taking the problem of syncing 100,000 ERC20 transfers per second as an example, this would come with the cost of updating 300,000 keys per second.
Ethereum uses the MPT (Merkle Patricia Trie) data structure to calculate the state after each block. In order to update 300,000 keys per second, Ethereum needs to "convert 6 million non-cached database reads," which is much more than any consumer-grade SSD can handle today. MegaETH writes that this estimate doesn't even include write operations (or estimates for on-chain transactions such as Uniswap transactions), making the challenge more of a Sisyphean endless effort than the uphill battle most of us might prefer.
There's another problem, we've reached the limit of block gas. The speed of the blockchain is actually limited by the block gas limit, a self-imposed obstacle designed to increase the security and reliability of the blockchain. "The rule of thumb for setting a block gas limit is that any block within this limit must be processed reliably within the block time." The whitepaper describes the block gas limit as a "throttling mechanism" that ensures nodes can reliably keep up, assuming they meet minimum hardware requirements.
Others say that the block gas limit is chosen conservatively to protect against the worst-case scenario, another example of modern blockchain architecture valuing security over scalability. The idea that scalability is more important than security falls apart when you consider how much money is transferred between blockchains every day, and how losing that money for a slight increase in scalability would result in a nuclear winter.
Blockchains may not be great at attracting high-quality consumer applications, but they are incredibly good at permissionless peer-to-peer payments. No one wants to mess that up.
Then there's the parallel EVM speeds that are workload dependent, and their performance is bottlenecked by the "long dependency chains" that minimize over-"speedup" of blockchain functions. The only way to solve this problem is to introduce multi-dimensional gas pricing (MegaETH refers to Solana’s native fee market), which remains difficult to implement. I’m not sure if there is a dedicated EIP for this, or how such an EIP would work on the EVM, but I guess technically it’s a solution.
Finally, users don’t interact with sorter nodes directly, and most users don’t run full nodes at home. Therefore, the actual user experience of a blockchain depends heavily on its underlying infrastructure, such as RPC nodes and indexers. No matter how fast a live blockchain runs, it won’t matter if the RPC nodes can’t efficiently handle a large number of read requests at peak times, quickly propagate transactions to sorter nodes, or if the indexers can’t update the application’s view quickly enough to keep up with the chain. ”
Perhaps too much, but it is very important. We all rely on Infura, Alchemy, QuickNode, etc., and the infrastructure they run is likely to support all of our transactions. The easiest explanation for this dependence comes from experience. If you have ever tried to claim an L2 airdrop in the first 2-3 hours after an airdrop, you will understand how difficult it is for RPC to manage this congestion.
Having said so much, I just want to express that a project like MegaETH needs to overcome many obstacles to reach the heights it wants to reach. One post said that they have been able to achieve high-performance development by using a heterogeneous blockchain architecture and a super-optimized EVM execution environment. "Today, MegaETH has a high-performance live development network and is steadily moving towards becoming the fastest blockchain, limited only by hardware. ”
MegaETH’s Github lists a number of major improvements, including but not limited to: an EVM bytecode → native code compiler, a dedicated execution engine for large memory sorter nodes, and an efficient concurrency control protocol for the parallel EVM. An EVM bytecode/native code compiler is now available, called evmone, and while I’m not coding savvy enough to know its core workings, I’ve done my best to figure it out.
evmone is a C++ implementation of the EVM that takes the EVMC API and converts it into an execution module for Ethereum clients. It mentions a few other features that I don’t understand, such as its dual interpreter approach (baseline and advanced), and the intx and ethash libraries. In summary, evmone offers the opportunity for faster transaction processing (via faster smart contract execution), greater development flexibility, and increased scalability (assuming different EVM implementations can handle more transactions per block).
As a blockchain user, I’m excited to see if this works. I’m spending too much money on mainnet transaction fees and it’s time for a change, but that change still feels increasingly difficult to achieve and unlikely to happen anytime soon.
While this post is mostly centered around architectural improvements and scalability, it will still take internal rollup shared liquidity and cross-chain tooling to make rollup A feel consistent with rollup B. We’re not there yet, but maybe by 2037 everyone will sit back and reminisce about how we were obsessed with “fixing” the scalability problem.
MegaETH achieves decentralization of computing power and eliminates gas restrictions by splitting full nodes.
JinseFinanceThis isn’t just MicroStrategy’s doing; it’s a real trend that’s powerful enough to have driven a significant rally in the bitcoin market this year.
JinseFinanceThe first place is undoubtedly Satoshi Nakamoto, who holds more than 1.1 million bitcoins.
JinseFinanceThis article will sort out the ins and outs of MegaETH vs Monad, and introduce and analyze them respectively as well as our opinions on them.
JinseFinanceAmid the rapid development of blockchain technology, Monad and MegaETH, as two emerging projects, are driving the evolution of the Ethereum ecosystem in their own unique ways.
JinseFinanceThe upcoming Vitalik-backed L2 hopes to become “Live Ethereum”.
JinseFinanceLayer 2, EVM, MegaETH supported by Vitalik and led by Dragonfly How to make ETH great again (MEGA) Golden Finance, Why do we need a MegaETH
JinseFinancePeople who hold at least 1,000 Bitcoins are called "Bitcoin whales."
JinseFinanceToken swap is by no means just a new way to solve the liquidity problem of NFT.
JinseFinanceCrypto Capital Venture's Dan Gambardello anticipates Cardano's (ADA) surge, linked to Coinbase's SEC resolution. Positive indicators, parallels with Ripple's case, and Cardano's development activity contribute to optimistic sentiments.
 Edmund
Edmund