Author: Machine Heart
It's so shocking!
When various technology companies are still catching up with the multimodal capabilities of large models and putting summary text, P-picture and other functions into mobile phones, OpenAI, which is far ahead, directly launched a big move. The product released even made its own CEO Ultraman amazed: It's just like in the movie.

In the early morning of May 14, OpenAI moved out the new generation flagship generation model GPT-4o, desktop App, and demonstrated a series of new capabilities at the first "Spring New Product Release Conference". This time, technology subverted the product form, and OpenAI used action to teach technology companies around the world a lesson.
Today's host is Mira Murati, CTO of OpenAI. She said that today she will mainly talk about three things:

First, OpenAI will make products free first in the future, so that more people can use them.
Second, so OpenAI released a desktop version of the program and an updated UI, which is easier and more natural to use.
Third, after GPT-4, a new version of the big model is here, called GPT-4o. The special thing about GPT-4o is that it brings GPT-4-level intelligence to everyone, including free users, in an extremely natural interactive way.
After this update of ChatGPT, the big model can receive any combination of text, audio and images as input, and generate any combination of text, audio and images as output in real time - this is the future interaction method.
Recently, ChatGPT can be used without registration, and today a desktop program has been added. OpenAI's goal is to allow people to use it anytime and anywhere without feeling, so that ChatGPT can be integrated into your workflow. This AI is now productivity.

GPT-4o is a new big model for the future human-computer interaction paradigm. It has the ability to understand three modalities of text, voice and image, and it reacts very quickly and emotionally, and it is also very human.
On the scene, OpenAI engineers took out an iPhone to demonstrate several main capabilities of the new model. The most important thing is real-time voice conversation. Mark Chen said, "This is my first time to attend a live conference, and I'm a little nervous." ChatGPT said, "Why don't you take a deep breath?"
Okay, I'll take a deep breath.

ChatGPT immediately replied, "You can't do that, you're breathing too hard."
If you've used voice assistants like Siri before, you can see the obvious difference here. First, you can interrupt the AI at any time, and you can continue the next round of conversation without waiting for it to finish. Second, you don't have to wait, the model responds extremely quickly, faster than humans. Third, the model can fully understand human emotions and can also express various emotions.
Then there is the visual ability. Another engineer wrote an equation on paper, asking ChatGPT not to give a direct answer, but to explain how to do it step by step. It seems that it has great potential in teaching people to solve problems.

ChatGPT says, whenever you are overwhelmed by math, I will be there for you.
Next, try GPT-4o's code capabilities. Here are some codes. Open the desktop version of ChatGPT on your computer and interact with it by voice. Let it explain what the code is used for and what a certain function is doing. ChatGPT can answer them fluently.
The result of the output code is a temperature curve graph. Let ChatGPT respond to all questions about this graph in a sentence.

Which month is the hottest month? Is the Y axis in Celsius or Fahrenheit? It can answer them all.
OpenAI also responded to some questions raised by netizens on X/Twitter in real time. For example, real-time voice translation, mobile phones can be used as translators to translate back and forth between Spanish and English.
Another person asked, can ChatGPT recognize your expressions?
It seems that GPT-4o can already do real-time video understanding.
Next, let's take a closer look at the nuclear bomb that OpenAI released today.
Omnimodel GPT-4o
First, we will introduce GPT-4o, where o stands for Omnimodel.
For the first time, OpenAI integrated all modalities in one model, greatly improving the practicality of large models.
OpenAI CTO Muri Murati said that GPT-4o provides "GPT-4-level" intelligence, but improves on GPT-4's capabilities in text, vision, and audio, and will be launched in the company's products "iteratively" in the coming weeks.
“The rationale for GPT-4o spans voice, text, and vision,” said Muri Murati. “We know these models are getting more complex, but we want the interactive experience to be more natural and simpler, so you don’t have to focus on the user interface at all, but just focus on working with GPT.”
GPT-4o matches the performance of GPT-4 Turbo on English text and code, but performs significantly better on non-English text, with a faster API and 50% lower cost. GPT-4o is particularly good at visual and audio understanding compared to existing models.
It can respond to audio input in as fast as 232 milliseconds, with an average response time of 320 milliseconds, similar to humans. Before the release of GPT-4o, users who experienced ChatGPT’s voice conversation capabilities were able to perceive ChatGPT’s average latency of 2.8 seconds (GPT-3.5) and 5.4 seconds (GPT-4).
This voice response model is a pipeline of three separate models: a simple model transcribes the audio to text, GPT-3.5 or GPT-4 takes in the text and outputs text, and a third simple model converts that text back into audio. But OpenAI found that this approach meant that GPT-4 lost a lot of information, such as the model could not directly observe the pitch, multiple speakers or background noise, and could not output laughter, singing or express emotions.
On GPT-4o, OpenAI trained a new model end-to-end across text, vision and audio, meaning that all inputs and outputs are processed by the same neural network.
"From a technical perspective, OpenAI has found a way to map audio directly to audio as a first-level modality and to transfer video to the transformer in real time. These require some new research in tokenization and architecture, but overall it is a data and system optimization problem (as is the case with most things)." Nvidia scientist Jim Fan commented.
GPT-4o can perform real-time reasoning across text, audio, and video, which is an important step towards more natural human-computer interaction (even human-machine-machine interaction).
OpenAI President Greg Brockman also "made it" online, not only letting two GPT-4o talk in real time, but also letting them improvise a song. Although the melody is a bit "touching", the lyrics cover the decoration style of the room, the characteristics of the characters' clothing, and the episodes that happened during the period.
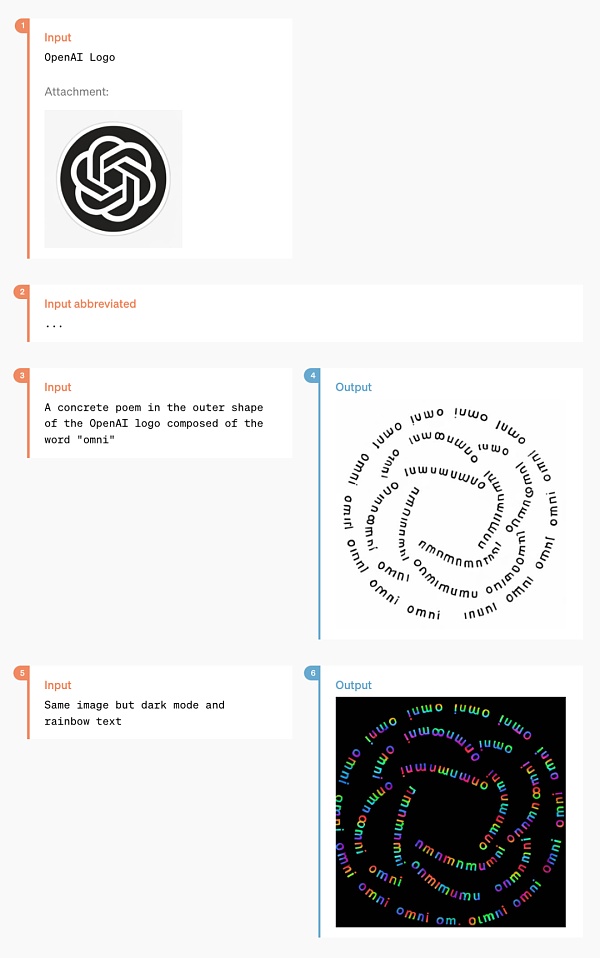
In addition, GPT-4o's ability to understand and generate images is much better than any existing model, and many previously impossible tasks have become "easy as pie".
For example, you can ask it to help print the OpenAI logo on the coaster:

After this period of technical research, OpenAI should have perfectly solved the problem of ChatGPT generating fonts.
At the same time, GPT-4o also has the ability to generate 3D visual content and can perform 3D reconstruction from 6 generated images:


This is a poem, GPT-4o can typeset it into a handwritten style:


More complex typesetting styles can also be handled:



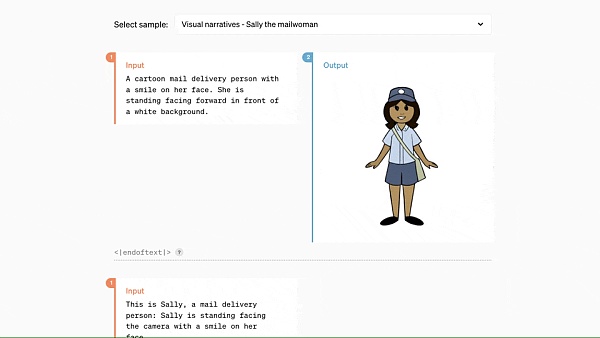
Working with GPT-4o, you only need to enter a few paragraphs of text to get a set of continuous comic storyboards:
The following gameplay should surprise many designers:
This is a stylized poster evolved from two life photos:


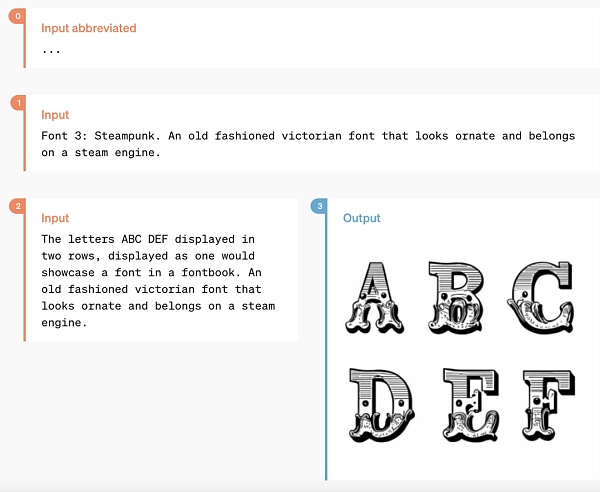
There are also some niche features, such as "text to art":
GPT-4o performance evaluation results
Members of the OpenAI technical team said at X that the mysterious model "im-also-a-good-gpt2-chatbot" that had caused widespread discussion on the LMSYS Chatbot Arena was a version of GPT-4o.
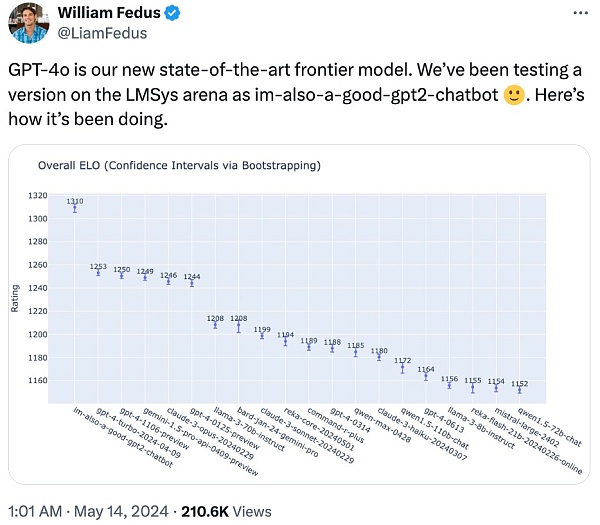
On more difficult prompt sets - especially encoding: GPT-4o has a particularly significant performance improvement over OpenAI's previous best model.
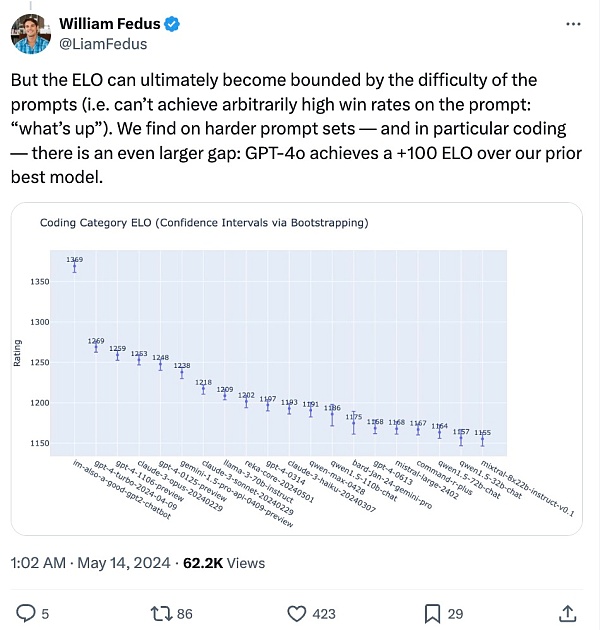
Specifically, across multiple benchmarks, GPT-4o achieves GPT-4 Turbo-level performance in text, reasoning, and encoding intelligence, while achieving new highs in multilingual, audio, and visual capabilities.
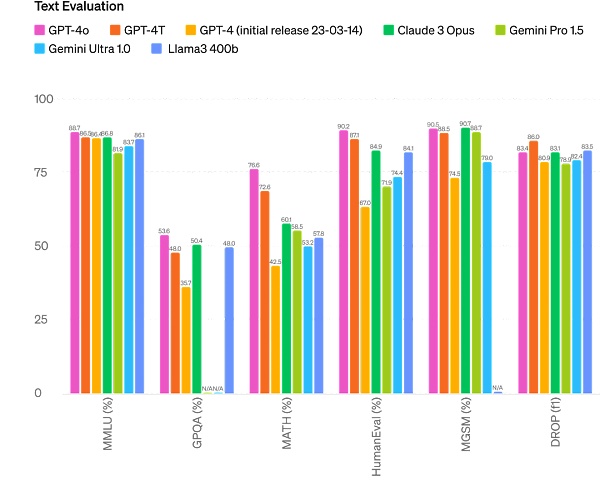
Inference improvement: GPT-4o set a new high score of 87.2% on 5-shot MMLU (common sense questions). (Note: Llama3 400b is still in training)
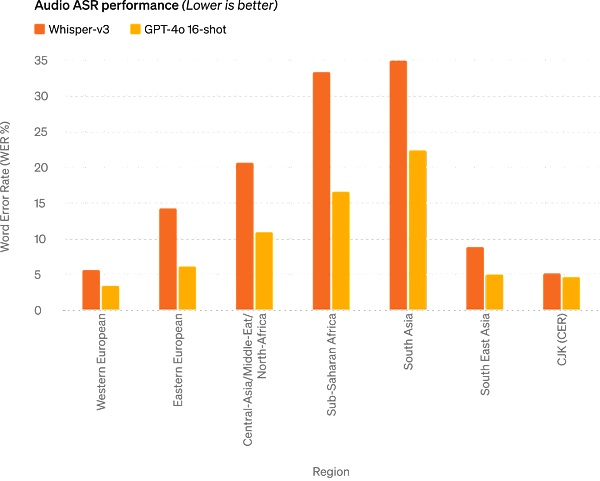
Audio ASR performance: GPT-4o significantly improves speech recognition performance in all languages compared to Whisper-v3, especially for resource-poor languages.
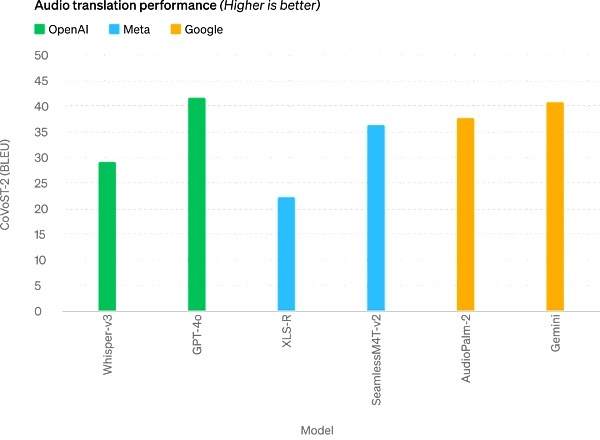
GPT-4o achieves a new SOTA level in speech translation and outperforms Whisper-v3 on the MLS benchmark.
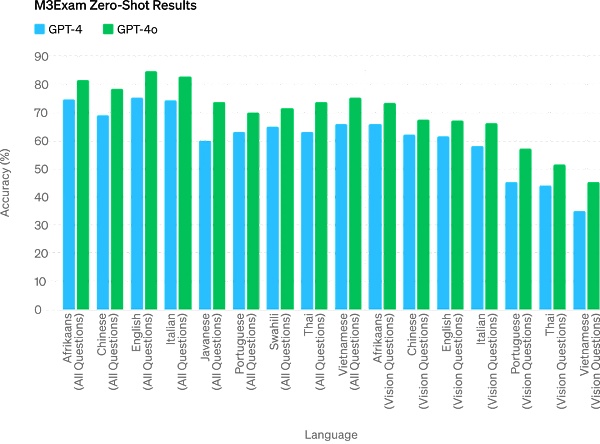
The M3Exam benchmark is both a multilingual and visual assessment benchmark, consisting of standardized test multiple-choice questions from multiple countries/regions, and includes graphics and charts. GPT-4o is stronger than GPT-4 in all language benchmarks.
In the future, the improvement of model capabilities will enable more natural, real-time voice conversations and the ability to talk to ChatGPT via live video. For example, a user can show ChatGPT a live sports game and ask it to explain the rules.
ChatGPT users will get more advanced features for free
More than 100 million people use ChatGPT every week, and OpenAI said that GPT-4o's text and image features are rolling out to ChatGPT for free today, and will provide Plus users with up to 5 times the message limit.

Now open ChatGPT, we find that GPT-4o is already available.
When using GPT-4o, ChatGPT free users can now access the following features: Experience GPT-4 level intelligence; users can get responses from models and networks.
In addition, free users have the following options -
Analyze data and create charts:
Talk to the photos you took:
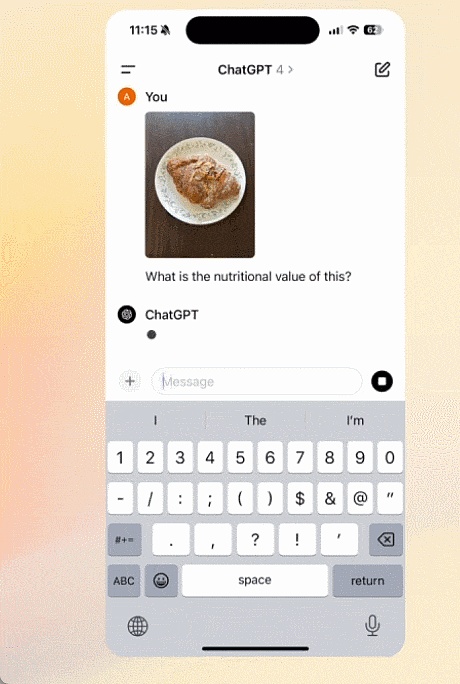
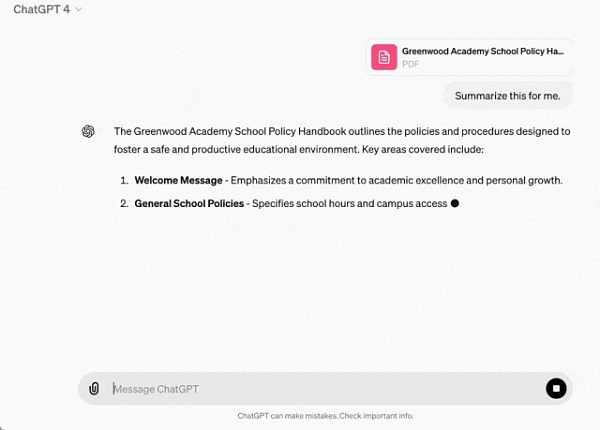
Upload files to get help with summarizing, writing or analysis:
Discover and use GPTs and the GPT App Store:
And use the memory feature to create a more helpful experience.
However, depending on usage and needs, the number of messages that free users can send using GPT-4o will be limited. When the limit is reached, ChatGPT will automatically switch to GPT-3.5 so that users can continue the conversation.
In addition, OpenAI will launch a new version of the voice mode GPT-4o alpha in ChatGPT Plus in the coming weeks, and will launch more new audio and video features for GPT-4o to a small number of trusted partners through APIs.
Of course, through multiple model tests and iterations, GPT-4o has some limitations in all modalities. In these imperfections, OpenAI said it is working hard to improve GPT-4o.
It is conceivable that the opening of the GPT-4o audio mode will definitely bring various new risks. On the issue of security, GPT-4o has built-in security in the cross-modal design through techniques such as filtering training data and refining model behavior after training. OpenAI has also created a new security system to provide protection for voice output.
New desktop app simplifies user workflow
For free and paid users, OpenAI has also launched a new ChatGPT desktop app for macOS. With a simple keyboard shortcut (Option + Space), users can immediately ask ChatGPT questions. In addition, users can also take screenshots and discuss directly in the application.
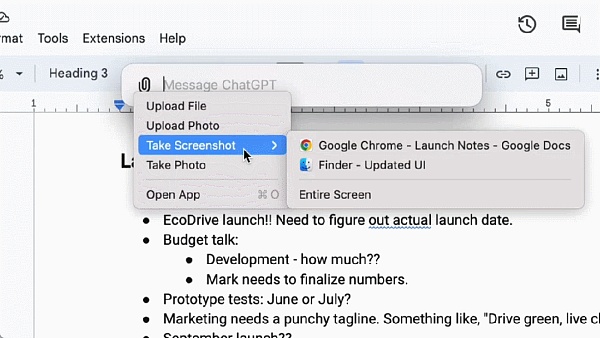
Now, users can also have voice conversations with ChatGPT directly from their computers. GPT-4o's audio and video features will be launched in the future. Start a voice conversation by clicking the headset icon in the lower right corner of the desktop application.
Starting today, OpenAI will launch the macOS application to Plus users and will make it more widely available in the coming weeks. In addition, OpenAI will launch a Windows version later this year.
Altman: You open source, we free
After the release, OpenAI CEO Sam Altman published a long-awaited blog post about the mental journey of driving GPT-4o work:
There are two things I want to emphasize in our release today.
First, a key part of our mission is to make powerful AI tools available to people for free (or at a discounted price). I am very proud to announce that we are making the world's best models available for free in ChatGPT, with no ads or anything like that.
When we founded OpenAI, our original vision was that we would create AI and use it to create all kinds of benefits for the world. Now things have changed, and it looks like we will create AI, and then other people will use it to create all kinds of amazing things, and we will all benefit from it.
Of course, we are a business and will invent a lot of things that will charge for, which will help us provide free, excellent AI services to billions of people (hopefully).
Second, the new voice and video modes are the best computing interaction interfaces I have ever used. It feels like AI in the movies, and I’m still a little surprised it’s real. It turns out that reaching human-level response times and expressiveness is a huge leap forward.
The original ChatGPT hinted at the possibilities of language interfaces, and this new thing (the GPT-4o version) feels fundamentally different - it’s fast, smart, fun, natural, and helpful.
Interacting with computers has never been natural for me, and that’s true. But when we add (optional) personalization, access to personal information, and the ability to let AI take actions on behalf of people, I can really see an exciting future where we can do more with computers than ever before.
Finally, a big thank you to the team for their huge efforts to make this happen!

It’s worth mentioning that last week Altman said in an interview that while universal basic income is difficult to achieve, we can achieve "universal basic compute". In the future, everyone will have free access to GPT’s computing power, which can be used, resold, or donated.
“The idea is that as AI becomes more advanced and embedded in every aspect of our lives, having a large language model unit like GPT-7 may be more valuable than money, and you own part of the productivity,” Altman explained.
The release of GPT-4o may be the beginning of OpenAI’s efforts in this direction.
Yes, this is just the beginning.
Finally, the video “Guessing May 13th’s announcement.” shown in the OpenAI blog today almost completely crashes into a warm-up video for Google’s I/O conference tomorrow, which is undoubtedly a big blow to Google. I wonder if Google feels tremendous pressure after watching OpenAI’s release today?


 Dante
Dante



