HTX、2カ月で4度目のハッキングに遭い3000万ドルを失う
HTX(旧Huobi Global)は2ヶ月で4回目のハッキングに遭い、3000万ドルを失った。
 Jasper
Jasper

出典:騰訊科技
春節以来、DeepSeekの人気は上昇を続けており、多くの誤解や論争を伴い、ある人は「OpenAIを打ち負かす国の光」だと言い、またある人は「スマートな宿題の外国の大きなモデルのコピーに過ぎない」と言う。
これらの誤解と論争は、主に5つの側面に焦点を当てています:
1、過度の神話と無脳の軽蔑は、最終的にDeepSeekは根本的な技術革新ではない?|にできるようにあなたがそれをすることができます本当に出くわすことあなたは、実際には私たち約束、誰でも素早くはちょうど無視これらの一見正確にどのように{}人のことを忘れることができます。
2、DeepSeekのコスト、本当にわずか550万ドル?
3、DeepSeekは本当に効率的に行うことができます場合は、世界の主要な巨人の巨大なAIの設備投資は、すべてのお金の無駄ではありませんか?
4、DeepSeekはPTXプログラミングを使用し、本当にNvidia CUDAへの依存を回避できるのか?
5、DeepSeekは世界的に爆発的な人気を博しているが、コンプライアンスや地政学などの問題から、海外では次々と禁止されるのではないか?
I. 過剰な神話と無脳な減価償却 DeepSeekは結局、根本的な革新ではない?
インターネットの実務家は、それが業界の発展の推進の価値を肯定する価値があることをcaozが、それは転覆について話をするのは早すぎる。
例えば、何人かの人々がテストし、バウンスコードの閉じた空間で典型的なボールをシミュレートし、DeepSeekは、プログラムのパフォーマンスから書き出され、ChatGPT o3-miniは、ビューのフォロー度のポイントの物理学に比べて、ギャップがまだあります。
過剰に神話化してはいけませんが、無闇に軽蔑してもいけません。
DeepSeekの技術的な成果については、2つの極端な見方があります。1つは、その技術的なブレークスルーを「破壊的な革命」と呼ぶもので、もう1つは、外国のモデルの模倣に過ぎないと見るもので、OpenAIのモデルを抽出することで進歩を得たという憶測さえあります。
マイクロソフトは、DeepSeekはChatGPTの結果を抽出したものだと述べているため、一部の人々はこの状況を利用して、DeepSeekを無価値なものとして中傷しています。
真実は、どちらの意見も一方的すぎるということです。
より正確には、DeepSeekのブレークスルーは、業界のペインポイントに向けたエンジニアリングパラダイムのアップグレードであり、AI推論の「less is more」という新たな道を開くものです。
DeepSeekは3つの大きなイノベーションを成し遂げました。
第1に、学習アーキテクチャをスリム化することで、例えばGRPOアルゴリズムは、従来の強化学習に必要なCriticモデル(つまり「ダブルエンジン」設計)を省くことで、複雑なアルゴリズムを実装可能なエンジニアリングソリューションに単純化することができます。
DeepSeekアルゴリズムは業界のペインポイントに向けて設計されていますが、新しいエンジニアリングパラダイムのアップグレードでもあります。
次に、GRPOアルゴリズムはシンプルな評価基準を採用しています。たとえば、コード生成シナリオにおける手動スコアリングをコンパイル結果やユニットテストの合格率に直接置き換えるなど、決定論的なルールベースのシステムであり、AIトレーニングにおける主観的バイアスの問題を効果的に解決します;
最後に、GRPOアルゴリズムは、純粋なアルゴリズム進化モデルであるZeroモードと、数千の手動ラベル付けデータしか必要としないR1モードとの間の微妙なバランスを見つけました。純粋にアルゴリズム的で自律的に進化するZeroモデルと、数千の手動注釈データしか必要としないR1モデルの組み合わせは、自律的なモデル進化の能力を保持し、人間による解釈可能性を保証します。
しかし、これらの改良はディープラーニングの理論的境界を突破するものではなく、OpenAI o1/o3のようなヘッドモデルの技術的パラダイムを完全に覆すものでもなく、むしろシステムレベルの最適化を通じて業界のペインポイントに対処するものです。
DeepSeekは完全にオープンソースであり、これらのイノベーションを詳細に文書化しているため、世界中がこれらの進歩を活用して、独自のAIモデルトレーニングを改善することができます。これらの革新的なポイントは、オープンソースのドキュメントで見ることができます。
また、Stability AIの元研究責任者であるTanishq Mathew Abraham氏も、最近のブログ投稿でDeepSeekのイノベーションのうち3つを取り上げています:
1.マルチヘッデッドアテンションメカニズム:ビッグランゲージモデルは通常、いわゆるマルチヘッデッドアテンション(MHA)メカニズムを使用するTransformerアーキテクチャに基づいています。DeepSeekチームは、より良いパフォーマンスを達成しながら、メモリをより効率的に使用するMHAメカニズムの変種を開発しました。
2.検証可能な報酬を持つGRPO:ディープシークは、非常に単純な強化学習(RL)プロセスでGPT-4のような結果を実際に達成できることを実証しました。さらに、彼らはGRPOと呼ばれるPPO強化学習アルゴリズムの変種を開発し、より効率的で優れたパフォーマンスを発揮するようになりました。
3.DualPipe:マルチGPU環境でAIモデルをトレーニングする場合、考慮すべき効率関連の要素が多くあります。DeepSeekチームは、DualPipeと呼ばれる新しいアプローチを考案し、大幅に効率的で高速になりました。
伝統的に「蒸留」とはトークン確率(ロジット)のトレーニングを指しますが、ChatGPTはこの種のデータをオープンにしていないため、ChatGPTを「蒸留」することは基本的に不可能です。
そのため、技術的な観点から見れば、ディープシークの功績は疑問視されるべきではありません。
ですから、技術的な観点からは、DeepSeekの功績は疑問視されるべきではありません。OpenAI o1の意識の連鎖による推論プロセスは公開されていないため、ChatGPTだけを「抽出」することは難しかったでしょう。
そしてcaoz氏は、DeepSeekのトレーニングは、蒸留されたコーパス情報の一部を部分的に利用したり、少量の蒸留検証を行ったかもしれないが、それがモデル全体の品質や価値に与える影響は非常に小さいはずだと主張しています。
また、主要なモデルの蒸留検証に基づいて、独自のモデルの最適化は、多くの大規模なモデルチームの日常的な操作ですが、結局のところ、ネットワークAPIの必要性は、非常に限られた情報を取得することができ、インターネットデータ上の膨大な情報量との相対的な影響の決定的な要因になる可能性は低い、apiコールを介して主要な大規模なモデルは、バケツの一滴のコーパスを得ることができ、それはより多くの検証分析のために使用されている合理的な推測である。直接大規模な訓練として使用するよりも、戦略の検証分析に使用される合理的な推測である。
すべての大型モデルはインターネットからコーパスの訓練を得る必要があり、有力な大型モデルは常にインターネットにコーパスを提供している。この観点からすると、すべての有力な大型モデルは捕捉され、蒸留される宿命を捨て去ることはできないが、これを成否の鍵として扱う必要はない。
結局のところ、私たちは皆、「私の中のあなた」と「あなたの中の私」とともに、反復的に前進していくのです。
550万ドルというコストは、それが何であるかが明確でないため、正しくもあり間違いでもある結論です。
Tanishq Mathew Abraham氏は、ディープシークのコストを客観的に見積もっています:
まず、この数字がどこから来ているのかを理解する必要があります。この数字は、DeepSeek-R1論文の1カ月前に発表されたDeepSeek-V3論文に初めて掲載されました。
DeepSeek-V3はDeepSeek-R1のベースモデルであり、DeepSeek-R1は実際にはDeepSeek-V3に強化学習トレーニングを追加したものです。強化学習トレーニングを加えたものです。
つまり、ある意味、このコストの数字は、強化学習トレーニングの追加コストを考慮していないため、本質的に不正確なのです。しかし、その追加コストはおそらく数十万ドル程度でしょう。

では、DeepSeek-V3の論文で主張されている550万ドルのコストは正確なのでしょうか?
GPUコスト、データセットサイズ、モデルサイズに基づく複数の分析でも、同様の見積もりが出ています。注目すべきは、DeepSeek V3/R1は6710億のパラメータを持つモデルですが、mixture-of-expertsアーキテクチャを採用しているため、関数呼び出しや前方伝播で使用されるパラメータは約370億のみであり、トレーニングコスト計算のベースとなっているのはこの値であるということです。
注意すべき点は、DeepSeekは現在の市場価格に基づいて推定コストを報告していることです。彼らの2,048 H800 GPUクラスタ(注:よくある誤解ですが、H100ではありません)が実際にいくらかかったのかはわかりません。多くの場合、GPU クラスターを一括で購入するほうが、断片的に購入するよりも安いので、実際のコストはもっと低いかもしれません。
しかし、重要なのは、これは最終的なトレーニング実行のコストに過ぎないということです。最終的なトレーニングに到達するまでに、多くの小規模な実験やアブレーション研究があり、これらにはこの報告書では把握されていないかなりのコストがかかる。
その他にも、研究者の給与など、数多くのコストがあります。SemiAnalysisによると、ディープシークの研究者の給与は100万ドルとも噂されている。これは、OpenAIやAnthropicのようなAGIフロンティアラボの給与水準のトップエンドに匹敵する。
こうした追加コストを理由に、ディープシークの低コストと運営効率を否定する声もある。この議論は著しく不公平だ。なぜなら、他のAI企業も同様に人件費に多くの給与を費やしており、これは通常モデルのコストに織り込まれていないからだ。"
Semianalysis(半導体とAIに特化した独立系調査分析会社)も、DeepSeekのAI TCO(AIにおける総所有コスト)の分析を行い、4つの異なるGPUモデル(A100、H20、H800、H100)を使用した場合のDeepSeek AIの総所有コストを表にまとめました。には、機器の購入、サーバーの構築、運用のコストが含まれています。4年サイクルの場合、これら60,000個のGPUの総コストは25億7300万ドルで、そのほとんどはサーバーの購入(16億2900万ドル)と運用(9億4400万ドル)のコストです。
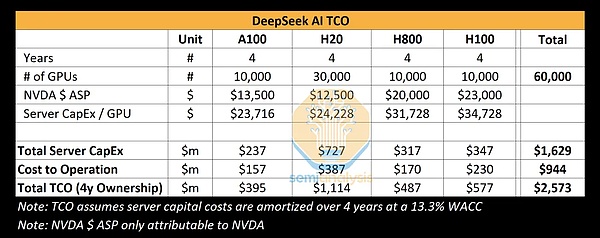
もちろん、ディープシークが正確に何枚のカードを所有し、個々のモデルの何パーセントを占めているかは、外部の誰も知りません。を占めているのか、すべて推定に過ぎません。
要約すると、機器、サーバー、運用、その他のコストをすべて考慮すると、コストは確かに550万ドルをはるかに超えますが、550万ドルの正味コンピューティングパワーコストで、すでに非常に効率的です。
3つ目は、コンピューティングパワーに投資するための莫大な資本支出です。
これは広く流布しているが、かなり一方的な見方だ。確かに、DeepSeekはトレーニング効率で優位性を示しており、また、コンピューティングリソースの使用におけるAI企業のいくつかの頭は、効率性の問題を抱えている可能性があることを露呈した。エヌビディアの短期的な急落も、この誤った解釈が広く流布されたことに関係しているのかもしれない。
しかし、より多くのコンピューティングリソースを持つことが悪いことだというわけではありません。スケーリング法則の観点からは、コンピュートパワーが大きければ大きいほど、常にパフォーマンスが向上します。この傾向は、2017年にTransformerアーキテクチャが導入されて以来続いており、DeepSeekのモデルもTransformerアーキテクチャをベースにしている。
AI開発の焦点は、モデルサイズからデータセットサイズへ、そして現在は推論計算と合成データへと進化していますが、計算量が多いほどパフォーマンスが向上するという中核的なルールは変わっていません。
ディープシークがより効率的な道を見つけたとはいえ、規模の法則は依然として真実であり、より多くの計算リソースがより良い結果をもたらすことに変わりはありません。
4つ目は、DeepSeekはNVIDIA CUDAへの依存をバイパスして、PTXを使用しているかということです。
DeepSeekの論文では、DeepSeekはPTX (Parallel Thread Execution) プログラミングを使用しており、このようなカスタムPTX最適化により、DeepSeekのシステムとモデルは、基礎となるハードウェアのパフォーマンスをよりよく解放できると言及しています。
元の論文には次のように書かれています:
「私たちはカスタマイズされたPTX(並列スレッド実行)命令を採用し、通信チャンクサイズを自動調整します。これは、L2キャッシュの使用と他のSMへの干渉を大幅に削減します。""我々は、カスタマイズされたPTX(並列スレッド実行)命令を採用し、通信チャンクサイズを自動調整します。これにより、L2キャッシュの使用と他のSMへの干渉が大幅に減少します。"
上海交通大学の戴国浩(Dai Guohao)准教授は、どちらの主張も正確ではないとみている。まず、PTX(並列スレッド実行)命令は実際にはCUDAドライバ層内にあるコンポーネントであり、依然としてCUDAエコシステムに依存しています。そのため、PTXがCUDAの独占を回避するために使用されるという考えは間違っています。
Dai Guohao教授は、PTXとCUDAの関係を明確に説明するためにパワーポイントを使用しました。
PPT by Guohao Dai, Associate Professor, Shanghai Jiaotong University
CUDA は、ユーザー向けのプログラミング・インターフェースの範囲を提供する、比較的上位のインターフェースです。そして、PTXは一般的にCUDAドライバーに隠されているため、ほとんどすべてのディープラーニングやビッグモデルのアルゴリズムエンジニアはこのレイヤーに触れることはありません。
では、なぜこのレイヤーが重要なのでしょうか?その理由は、この位置からわかるように、PTXは基礎となるハードウェアと直接相互作用し、より良いプログラミングと基礎となるハードウェアへの呼び出しを可能にするからです。
平たく言えば、DeepSeekの最適化は、チップに制約のある現実における最後の手段ではなく、チップがH800であろうとH100であろうと関係なく、インターコネクトの効率を向上させる積極的な最適化なのです。
DeepSeekが炎上した後、Nvidia、Microsoft、Intel、AMD、AWSのクラウド大手5社はDeepSeekを棚上げにしたり統合したりしました。
しかし、一方で、DeepSeekの棚に外国のクラウドジャイアントは、「外国人が敗北した」、いくつかの過度に感情的なレトリックがあります。
実際には、これらの企業によるDeepSeekの展開は、ビジネス上の考慮事項のためです。クラウドベンダーとしては、できるだけ多くの人気・実力のある機種の導入をサポートすることで、顧客により良いサービスを提供できると同時に、DeepSeek関連のトラフィックの波を擦り寄せて、おそらく新規ユーザーの一部を取り込んでコンバージョンさせることもできる。
DeepSeekが大ヒットしたときに一元的に展開されたのは事実だが、DeepSeekに夢中になっていたとか、「圧倒されていた」というのは言い過ぎだろう。
しかも、中国のテックコミュニティは、DeepSeekが攻撃された後、アベンジャーズ同盟を結成してDeepSeekを支援した。
一方で、地政学的な理由やその他の現実的な理由から、近いうちに外国が次々とDeepSeekを禁止するだろうという声もある。
これに対し、caoz氏はより明確な解釈を示しました。実は、私たちが話しているDeepSeekには2つの製品が含まれており、1つは世界を席巻したアプリ「DeepSeek」、もう1つはgithub上のオープンソースコードライブラリです。前者は後者のデモと考えることができ、その能力の完全なデモンストレーションである。一方、後者は繁栄するオープンソースのエコシステムに成長するかもしれない。
使用が制限されているのはDeepSeekのアプリであり、大企業がアクセスして提供しているのはDeepSeekのオープンソースソフトウェアの展開である。この2つは完全に異なるものです。
ディープシークは「中国の大手モデル」として世界的なAI分野に参入し、最も雰囲気の良いオープンソースプロトコルであるMITライセンスを使って、商用利用すら許可した。現在の議論は技術革新の範囲をはるかに超えているが、技術の進歩に白黒の善し悪しは決してない。過度な喧伝や全面的な否定に陥るのではなく、時間と市場にその真価を問う方がいい。結局のところ、AIマラソンでは、本当の競争は始まったばかりなのだ。
参考:
caozによるディープシークに関するよくある誤解
https://mp.weixin.qq.com/s/Uc4mo5U9CxVuZ0AaaNNi5g
-size: 14px;">https://www.tanishq.ai/blog/posts/deepseek-delusions.html
HTX(旧Huobi Global)は2ヶ月で4回目のハッキングに遭い、3000万ドルを失った。
Jasper韓国銀行、10万人の市民が参加する画期的なCBDCパイロットを開拓し、デジタルウォン時代への重要な一歩を踏み出す。
 Hui Xin
Hui Xinバイナンス前CEOのCZ Zhao氏は、米国検察当局が法的トラブルの中で逃亡リスクの懸念を理由に保釈条件に異議を唱え、暗号通貨市場が規制当局の監視から反発する一方で、渡航制限に直面している。
JasperJPモルガンのアナリストは、グレイスケール・ビットコイン・トラスト(GBTC)のETFへの転換に伴い、27億ドル以上の資金流出の可能性があると予想。
Jasperビットコインの取引で、クジラが前例のない310万ドルの手数料を誤って支払い、暗号コミュニティに憶測と不安を呼び起こし、眉をひそめた。
Jasperシンガポール金融管理局は、個人投資家を保護するために暗号規制を強化し、投機的な活動を抑制する措置を導入した。
Jasperビル・ゲイツは、AIの進歩に伴い週3日労働の短縮を構想しており、テクノロジーが労働構造に変革をもたらすという業界の議論に共鳴している。
Hui Xin元FTXのCEOであるサム・バンクマン=フライドは、サバ(「マック」)の取引によって刑務所生活をナビゲートし、適応能力を明らかにし、法的な難題の中で型破りな刑務所での商売についての洞察を提供する。
Hui Xinブルックリンのメトロポリタン拘置所で、SBFは思いがけない経済活動を展開している。判決を待つ間、彼は刑務所経済の世界に足を踏み入れる。SBFのユニークな適応は、「マック」として知られる保存食の魚の袋を拘置所内でのサービスと交換することである。
 Joy
Joyバイナンス前CEOのChangpeng "CZ" Zhao氏は、米司法省との43億ドルの和解に関連した辞任後、ソーシャルメディアプラットフォームX(旧Twitter)のアカウント制限に直面した。同プラットフォームはルール違反をほのめかし、CZはボット検出アルゴリズムの欠陥が制限の原因だとし、リチャード・テン氏がバイナンスの指導的役割を担っているにもかかわらず、同氏の今後の活動に不透明感を与えている。
 Jixu
Jixu