アマゾンの40億ドル追加投資でAnthropicがOpenAIに追いつく?
アマゾンはアンソロピックを "AIインフラ開発のハブ "と位置づける
 JinseFinance
JinseFinance

はじめに
デジタル化の時代において、人工知能(AI)は技術革新と社会進歩を推進する重要な力となっている。AIは過去一定期間、ベンチャーキャピタル業界や資本市場で最もホットな話題となっている。
ブロックチェーン技術の発展とともに、分散型AI(Decentralized AI)が台頭してきました。 この記事では、分散型AIの定義とアーキテクチャ、AI業界との相乗効果について説明します。
分散型AIの定義とアーキテクチャ
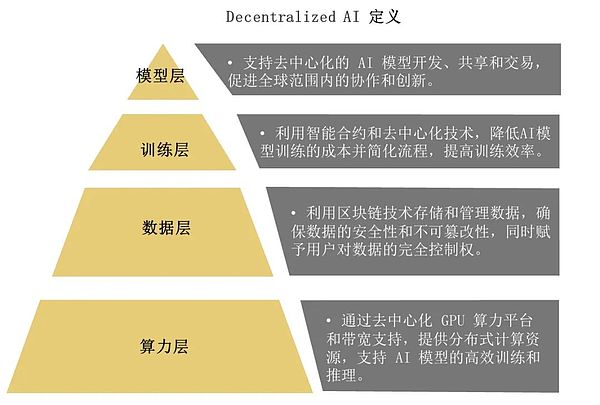
分散型AIは、分散型のコンピューティングリソースとデータストレージを活用して、プライバシーとセキュリティを強化した分散型の方法でAIモデルを訓練し、使用します。
- モデルレイヤー:分散型AIモデルの開発、共有、取引をサポートし、グローバル規模でのコラボレーションとイノベーションを促進します。strong>です。このレベルは、ブロックチェーン技術を使用してAIモデルの共有とコラボレーションのためのグローバルなプラットフォームを構築するBittensorなどのプロジェクトに代表されます。
- トレーニング層:スマートコントラクトと分散型テクノロジーを活用することで、AIモデルトレーニングのコストを下げ、プロセスを合理化し、トレーニング効率を向上させる。このレベルの課題は、効率的なモデルトレーニングのために分散コンピューティングリソースをいかに効果的に活用するかです。
- データレイヤー:ブロックチェーン技術を使ってデータを保存・管理し、データのセキュリティと改ざんを保証すると同時に、ユーザーがデータを完全に制御できるようにする。このレベルのアプリケーションは、ブロックチェーン技術を通じてデータの透明な取引と所有権の確認を可能にする分散型データマーケットプレイスなどである。
- 演算レイヤー:分散コンピューティングリソースは、分散GPU演算プラットフォームと帯域幅サポートを通じて提供され、AIモデルの効率的なトレーニングと推論をサポートする。エッジ コンピューティングや分散 GPU ネットワークなど、このレベルの技術の進歩は、AI モデルのトレーニングと推論に新しいソリューションを提供します。
分散型AI代表プロジェクト

分散型AI業界大要:モデル層
モデル層:ビッグモデルの参加パラメーターの数は指数関数的に増加し、モデルの性能は著しく向上していますが、モデルをさらにスケーリングすることによる利益は減少しています。この傾向は、AIモデルの方向性と、パフォーマンスを維持しながらコストとリソース消費を削減する方法を再考する必要があります。
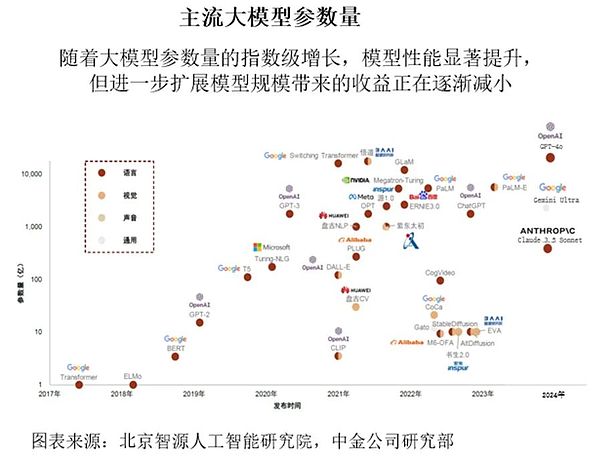
大規模なAIモデルの開発は、以下の法則に従っています。
大規模なAIモデルの開発は「スケールの法則」に従っています。
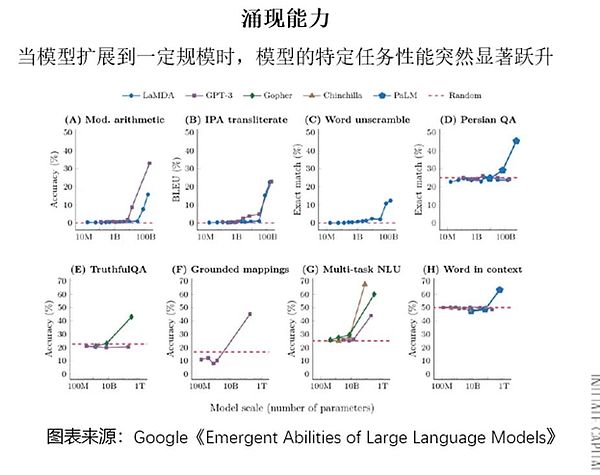
モデルがあるサイズまでスケールアップすると、特定のタスクにおけるパフォーマンスが突然大幅に向上します。タスクのパフォーマンスが突然大幅に向上します。大きなモデルパラメータの数が増えるにつれて、モデル性能の向上は徐々に減少していき、パラメータスケールとモデル性能のバランスをどのようにとるかが今後の開発の鍵となるでしょう。
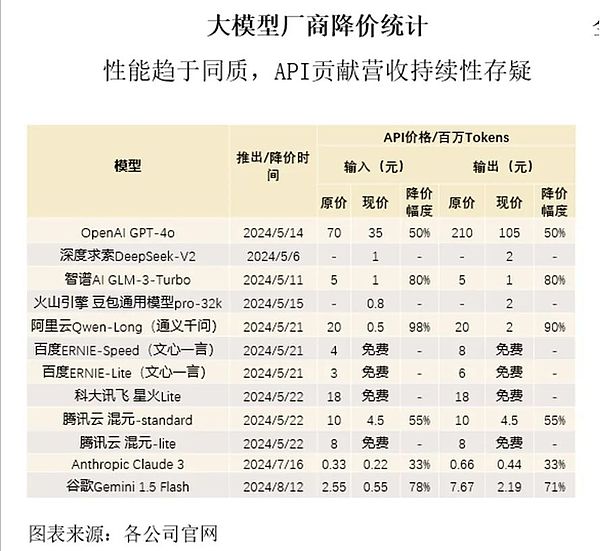
AIのビッグモデル用APIについて見てきました。価格競争が激化し、複数のベンダーが市場シェアを拡大するために価格を引き下げた。しかし、ビッグモデルの性能の均質化に伴い、API収益の持続性が疑問視されている。いかにユーザーの高い粘着性を維持し、収益を上げるかが今後の大きな課題となるだろう。
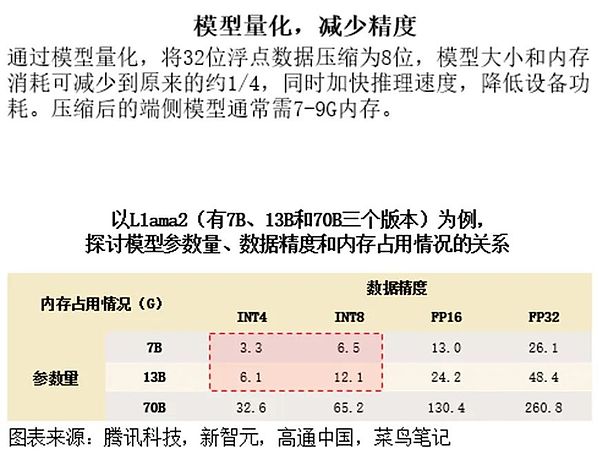

エンドサイドモデリングの適用は、データ精度を下げ、専門家混合モデル(MoE)アーキテクチャを採用することで達成される。モデルの量子化技術は、32ビットの浮動小数点データを8ビットに圧縮し、それによってモデルのサイズとメモリ消費量を大幅に削減することができます。このようにして、モデルはエンド側のデバイスで効率的に実行することができ、AI技術のさらなる普及を促進します。

要約:ブロックチェーンはモデルレイヤーを強化し、AIモデルの透明性、コラボレーション、ユーザーエンゲージメントを向上させます。

中央集権的なAI産業の育成:トレーニング層
トレーニング層:大規模なモデルのトレーニングには、高帯域幅と低遅延の通信が必要であり、大規模なモデルの試みには分散型演算ネットワークの可能性があります。このレベルの課題は、より効率的なモデルトレーニングのために、通信と計算リソースの割り当てを最適化することです。
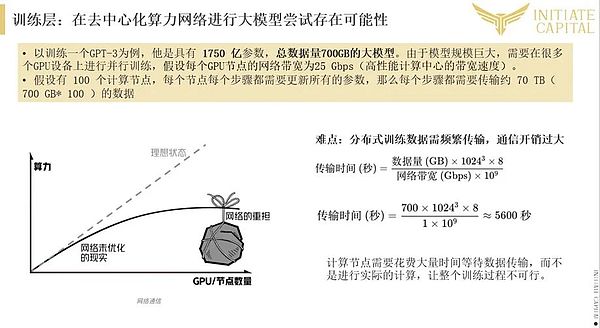
分散型算術ネットワークは、大規模なモデル訓練にある程度の可能性があります。
分散型演算ネットワークは、大規模なモデルトレーニングにある程度の可能性がある。過剰な通信オーバーヘッドという課題はあるものの、スケジューリングアルゴリズムを最適化し、送信データ量を圧縮することで、トレーニング効率を大幅に改善することができます。しかし、現実の環境におけるネットワークの待ち時間やデータ伝送のボトルネックをどのように克服するかは、分散型トレーニングの大きな課題のままです。

大きなモデルの訓練ボトルネックを解決するためにトレーニングのボトルネックを解決するために、データ圧縮、スケジューリングの最適化、ローカル更新と同期などの技術を採用することができます。これらの方法は、通信オーバーヘッドを削減し、トレーニング効率を向上させることができ、分散型演算ネットワークを大規模モデルトレーニングのための実行可能な選択肢にすることができます。
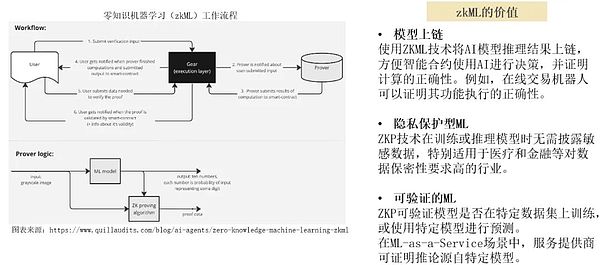
ゼロ知識機械学習(zkML)は、ゼロ知識証明と機械学習技術を組み合わせることで、学習データやモデルの詳細を公開することなく、モデルの検証や推論を可能にします。この技術は、ヘルスケアや金融など、高いレベルのデータ機密性を必要とする業界に特に適しており、AIモデルの正確性と信頼性を検証しながら、データプライバシーを確保することができます。
分散型AI産業グルーミング:データ層
データのプライバシーとセキュリティは、AIの発展において重要な問題になっている。分散型のデータ保存と処理技術は、これらの問題に対処するための新しいアイデアを提供します。
データストレージ、データインデックス、データアプリケーションはすべて、分散型AIシステムが適切に機能するための重要な側面です。FilecoinやArweaveのような分散型ストレージプラットフォームは、データのセキュリティとプライバシー保護、ストレージコストの削減という点で新たなソリューションを提供します。="https://img.jinse.cn/7332365_image3.png">
分散型ストレージの例:

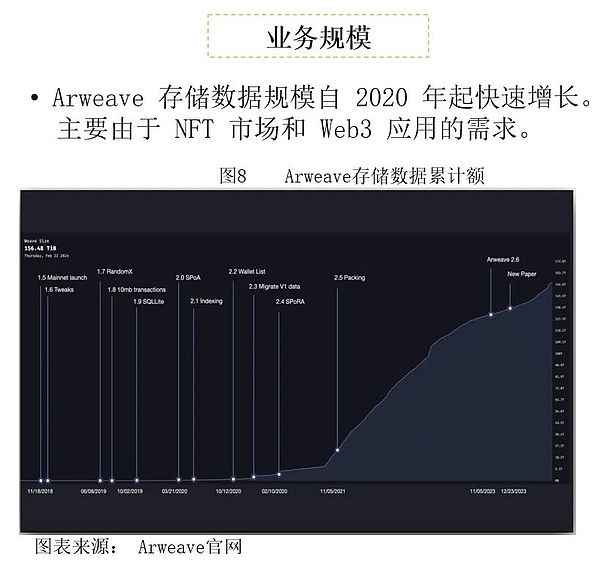
2020年以降、アルウィーブは主にNFT市場とWeb3アプリケーションからの需要によって、データストレージのサイズが急速に拡大しています。Arweaveにより、ユーザーは分散型の永久データストレージを実現し、長期データストレージの課題を解決することができます。
一方、AOプロジェクトはArweaveエコシステムをさらに強化し、ユーザーにより強力なコンピューティング能力と幅広いアプリケーションシナリオを提供します。
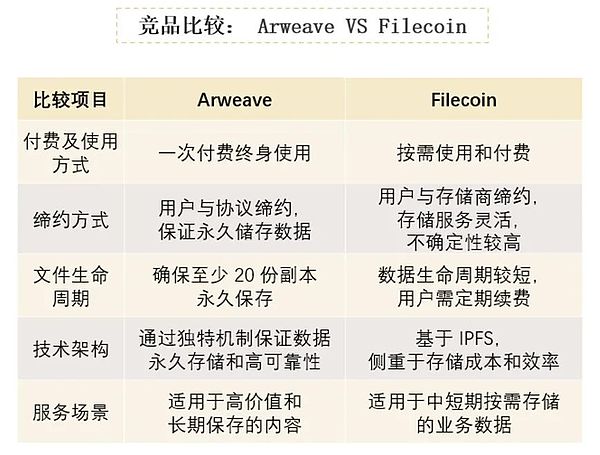
このページでは、2つのディセンダを比較します。このページでは、2つの分散型ストレージ・プロジェクト、Arweaveを比較します。Arweaveは1回限りの支払いで永続的なストレージを可能にし、Filecoinは毎月の支払いモデルを使って柔軟なストレージ・サービスを提供することに重点を置いています。両者とも、技術的なアーキテクチャ、ビジネス規模、市場での位置づけの点でそれぞれ利点があり、ユーザーは特定のニーズに応じて適切なソリューションを選択することができます。
Decentralised AI industry compendium: arithmetic layer
Arithmetic Layer:AIモデルの複雑さが増すにつれて、コンピューティングリソースの必要性も高まります。コンピューティング・リソースの需要も増大します。分散型演算ネットワークの出現は、AIモデルのトレーニングと推論にリソースを割り当てる新しい方法を提供します。= "https://img.jinse.cn/7332370_image3.png">
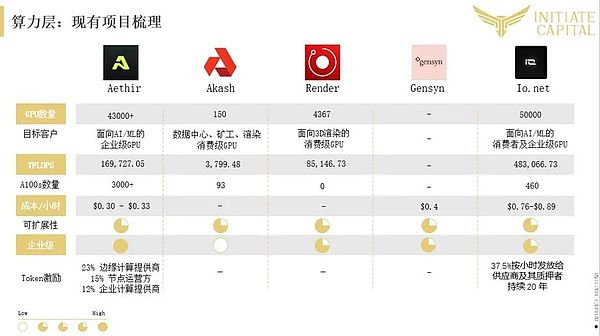
分散型計算ネットワーク(トレーニングや推論専用の計算ネットワークも同様)は、現在、DeAIサーキットで観測されている中で、最も活発で急成長している分野です。これは、DeAI回路でこれまで観察された中で、最も活発で急速に成長している領域である。これは、現実世界のインフラプロバイダーがAIチェーンの果実を獲得していることと一致しています。GPUなどのコンピューティング・パワー・リソースの不足が続く中、コンピューティング・パワーのハードウェア・デバイスを持つベンダーがこの分野に参入しています。
アエティールのケース:
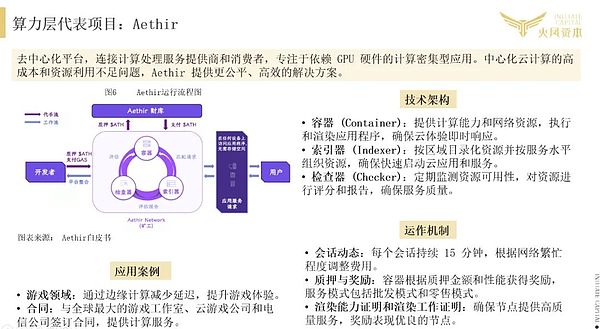
ビジネスモデル:算術リースのための二国間マーケットプレイス
Decentralised Arithmetic Marketplace,基本的には、Web3テクノロジーを活用することで、グリッド・コンピューティングの概念を経済的に実行可能なマーケットプレイスへと拡張する方法です。本質的には、Web3技術を利用したグリッド・コンピューティングのアイデアを、経済的にインセンティブを与える、信頼のない環境に拡張するものです。分散型演算サービス市場は、CPUやGPUなどのリソースのプロバイダーに、分散型ネットワークにアイドル演算を貢献させるインセンティブを与え、演算リソースの需要側(モデルプロバイダーなど)を接続して、より低コストで柔軟な方法で演算サービスリソースを提供することで形成されます。分散型の算術市場は、中央集権型の独占クラウドサービスプロバイダーに対する挑戦でもある。
分散型演算市場は、提供するサービスの種類に基づいてさらに分類することができます:汎用と専用です。汎用演算ネットワークは分散型クラウドのように動作し、さまざまなアプリケーションに演算リソースを提供します。専用演算ネットワークは、主に特定のユースケース向けにカスタマイズされた目的別演算ネットワークである。例えば、Render Networkはレンダリングワークロードに特化した専用コンピューティングネットワークであり、GensynはMLモデルのトレーニングに特化した専用コンピューティングネットワークであり、io.netは汎用コンピューティングネットワークの一例です。
DeAIにとって、分散型インフラストラクチャでモデルをトレーニングする際の重要な課題の1つは、大規模な演算、帯域幅の制約、および世界中のさまざまなベンダーの異種ハードウェアの使用による高いレイテンシーです。その結果、AI専用の計算ネットワークは、汎用の計算ネットワークよりもAIに適したものを提供できます。MLモデルの集中的なトレーニングは、今でも最も効率的で安定したプロジェクトですが、プロジェクトの資本力に非常に高い要求をします。
Conclusion
DecentralisedAIという新たな技術トレンドは、データプライバシー、セキュリティ、費用対効果の面で、その優位性を徐々に実証しつつあります。次回の記事では、分散型AI が直面するリスクと課題、そして進むべき道を探ります。
アマゾンはアンソロピックを "AIインフラ開発のハブ "と位置づける
JinseFinance21シェアーズの幹部は、「アマゾンが書籍の分野を超え、業界全体を再定義したように、イーサネットも、現在では想像もつかないような革命的な使用例で我々を驚かせるかもしれない」と語った。
JinseFinanceAWS、AIモデルのコストを賄う無償クレジットプログラムを拡充。Anthropic社への投資により、スタートアップエコシステムへのコミットメントを反映し、関係が強化される。AzureやGoogle Cloudとの競争の中、規制当局の監視が強まる。
 Xu Lin
Xu Linアップル(AAPL)、アマゾン(AMZN)、メタ(META)の決算に投資家が期待。iPhoneの需要、ホリデーシーズンの業績、広告戦略に注目。決算前の取引は楽観的。
 EdmundJinseFinance
EdmundJinseFinanceアマゾンのAWS上のTitan AIスイートは、強力な画像ジェネレーターと「Q」言語モデルを導入し、リアルさと多様性でビジネス向けAIアプリケーションを強化する。
 YouQuan
YouQuanアマゾンは、ビジネス用に特別に設計された人工知能アシスタント「アマゾンQ」の発売を発表した。
 Olive
Oliveアマゾンの人工知能への進出は、ウォール街を興奮の渦に巻き込んだ。この対訳では、アマゾンのAIへの取り組みと金融界への影響について、さまざまな角度から掘り下げている。
 Cheng Yuan
Cheng YuanImmutableは、ゲーム開発者の視野を広げるためにAmazon Web Servicesと提携しました。この提携は、AWSのスタートアップ・アクセラレーター・プログラムの継続的な拡大の一環である。
 Catherine
Catherineアマゾンで購入可能なAI生成ガイドブックが急増しており、専門家たちはその潜在的な危険性に警鐘を鳴らしている。
Catherine