ライトニング・ネットワークの仕組み(1)
本日の記事では、引き続きライトニング・ネットワークを紹介し、その仕組みとテクノロジーについてお話しします。
 JinseFinance
JinseFinance

2024年の年明けに、OpenAIは新たなAI爆弾を世界に投下した。
1年前のChatGPTのように、SoraはAGI(一般人工知能)のもうひとつの画期的な瞬間と考えられています。
「Soraは、AGIの実現が10年から1年に短縮されることを意味する」と360の周鴻儀会長は予測している。
しかし、このモデルが非常にセンセーショナルなのは、AIが生成したビデオがより長く、より鮮明であるということだけでなく、OpenAIが実際の物理的な世界に関連したビデオコンテンツを生成するために、過去のすべてのAIGCの能力を凌駕したということです。
ナンセンスなサイバーパンクはクールだが、現実世界のあらゆるものがAIによって再現されることの方が有意義だ。
そのために、OpenAIはワールドシミュレータというまったく新しいコンセプトを打ち出しました。
OpenAIの公式テクニカルレポートでは、Soraは「ワールドシミュレータとして機能するビデオ生成モデル」として位置づけられており、「我々の発見は、ワールドシミュレータが、ワールドシミュレータとして機能することを示唆している」とされています。ビデオ生成モデルを拡張することは、物理世界の普遍的なシミュレータを構築するための実行可能な道である。"

OpenAIは、Soraが現実世界のモデルを理解し、シミュレートできるようにするための基礎を築き、これが主要なAGI実装のマイルストーンになると考えています。マイルストーンになるだろう。これにより、AIビデオトラックにおけるRunwayやPikaのようなセグメントを完全に引き離します。

テキスト(ChatGPT)から画像(DALL-E)から映像(Sora)まで、OpenAIにとってはジグソーパズルのピースを集めるようなもので、映像という媒体を通してバーチャルとリアルの境界を壊そうとし、映画「トップガン」の存在そのものになろうとしています。
アップルのVision Proが『トップガン』のハードウェア的な現れであるとすれば、シミュレートされた仮想世界を自動的に構築するAIシステムは魂である。
「言語モデルは人間の脳に近似しており、ビデオモデルは物理世界に近似しています」とエジンバラ大学の博士課程に在籍するヤオ・フーは言う。
「OpenAIの野望は誰もが想像していたよりも大きいですが、それができるのはOpenAIしかないようです」と、何人かのAI起業家はLight Cone Intelligenceに叫んだ。
なぜ「そら」は「ワールド・シミュレーター」になったのか?
OpenAIの新しくリリースされたSoraモデルは、2023年以前の古い世界と一線を画し、2024年のAIビデオトラックへの扉を大きく開けています。
ライトコーン・インテリジェンスは、一挙に公開した48本のデモ映像の中で、これまでAI映像が批判されてきた問題点のほとんどが解決されていることを発見した。それは、より明確なフレームの生成、より生き生きとした生成、より正確な理解、よりスムーズな論理的理解、より安定した一貫性のある生成結果などである。
しかし、これらすべてはOpenAIの氷山の一角に過ぎません。なぜならOpenAIは、最初からビデオではなく、すべての存在をターゲットにしていたからです。
イメージはより大きな概念であり、ビデオはそのサブセットです。たとえば、通りにスクロールする大きなスクリーンや、ゲーム世界の仮想シーンなどです。ワールド・シミュレーター」というコンセプトは、OpenAIがやろうとしていることだ。
AI映画『山海のワンダーランド』のプロデューサー、クン・チェンがライトコーン・インテリジェンスに語ったように、「OpenAIは映像の面で何ができるかを見せてくれているが、本当の目的は、人々のフィードバックデータを得て、人々がどんな映像を生成したいかを探り、予測することだ」。人々がどのようなビデオを生成したいのかを。大きなモデルのトレーニングのように、いったんツールがオープンになれば、世界中の人々がそのために働き、常にタグ付けし、記録することで、その世界モデルをより賢く、よりスマートにしていくのと同じことなのだ。"
つまり、AIビデオが物理世界を理解するための第一段階となり、「ビデオ生成モデル」としての特性を際立たせ、第二段階になって初めて「世界シミュレーター」として使えるようになることがわかる。「世界シミュレーター」。
ソラの「映像生成」属性を捉える核心は、ソラとランウェイの違い、ランウェイと世界の違いを見つけることである。ソラはランウェイやピカと何が違うのか?この問いは、ソラがなぜそれを打ち砕くのか、その理由の一端を説明するものであり、非常に重要である。
まず最初に、OpenAIは大規模な言語モデルをトレーニングするという考え方に沿って、一般的な能力を持つ生成モデルをトレーニングするために大規模な視覚データを使用しています。
これは、ヴィンセント・ビデオ・スペースの「特化した」ロジックとはまったく異なります。昨年、Runwayは「Universal World Model」と呼ばれる、大まかには似たようなプロジェクトを持っていましたが、実行には至りませんでしたので、今回Soraは一歩先に進み、Runwayの夢を実現しました。
ニューヨーク大学の謝世寧助教授の予測によると、そらの参加額は約30億で、GPTモデルに比べれば取るに足らないが、この桁はランウェイやピカなど一部の企業をはるかに超えており、次元の違う打撃と言える。
万興科技のAIイノベーションセンター総経理である斉鳳権氏は、Soraの成功は「大きな努力による奇跡」の可能性を再び証明するものだとコメントした。Soraは依然として、大量のデータ、大規模なモデル、大量の演算能力に依存するOpenAIのスケーリング法則に従っている。 Soraの基礎となるレイヤーは、ゲーム、ドローン、ロボット工学で検証された世界モデルを使用し、世界をシミュレートする能力を達成するVincennesビデオモデルを構築している。"
第二に、Soraで初めて、拡散モデルとビッグモデル能力の完璧な融合が実証されました。
AI映像は大ヒット映画のようなもので、脚本と特殊効果という2つの重要な要素に依存している。スクリプトはAIビデオ生成プロセスの「ロジック」に対応し、FXは「エフェクト」に対応します。論理」と「効果」を実現するために、普及モデルと大規模モデルの2つの技術経路が背後にある。
昨年末、ライトコーン・インテリジェンスは、「エフェクト」と「ロジック」を両立させるためには、「拡散モデル」と「大型モデル」の2つの経路がいずれ収束すると予測した。OpenAIがこんなに早くこの問題を解決するとは思っていなかった。
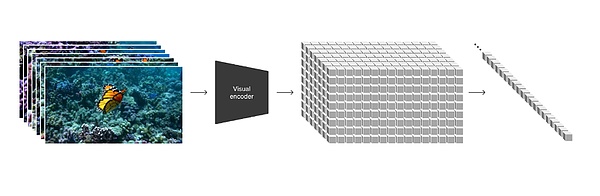
(画像出典:OpenAI公式サイト)
OpenAIは技術報告書の中で、「さまざまな種類の視覚データを統一された表現に変換する我々のアプローチは、生成的な大規模訓練に使用することができます。生成モデルの大規模トレーニングに使用できる。"
具体的には、OpenAIはビデオフレームの各フレームを個々のビジュアルパッチにエンコードし、その各パッチはGPTのトークンに類似しており、ビデオ、画像の最小測定単位となり、いつでもどこでも分割、再編成が可能です。データを統一し、測定基準を統一し、拡散モデルとビッグモデルの橋渡しをする方法を見つける。
生成の全体のプロセスでは、拡散モデルはまだ大きなモデルTransformerの注意メカニズムの増加の部分の効果を生成する担当であり、生成のより多くの予測、推論能力は、なぜSoraは、既存の取得した静止画像からビデオを生成することができます説明するだけでなく、することができます。既存のビデオを拡張したり、欠けているフレームを埋めることができます。
現在までのところ、ビデオモデルの開発は、合成に向かう傾向を示しており、モデルが収束に向かっている一方で、技術も合成に向かっています。
これまで蓄積された技術を映像モデルに応用することも、OpenAIの強みになっている。Sora Wen Shengビデオのトレーニングプロセスにおいて、OpenAIはDALL-E3とGPTの言語理解能力を導入した。OpenAIによると、DALL-E3とGPTをベースにトレーニングすることで、Soraはユーザーのプロンプトに正確に従うことができ、高品質のビデオを生成することができる。
この組み合わせの結果、ワールド・シミュレータの基礎となるシミュレーション機能が出現しました。
「私たちは、ビデオモデルが大規模に訓練されたときに、多くの興味深い出現能力を示すことを発見しました。これらの能力により、Sora は物理世界の人、動物、環境の特定の側面をシミュレートすることができます。これらの特性は、3Dやオブジェクトなどへの明示的な還元的バイアスなしに出現します。
「シミュレーション」がこれほどまでに大爆発している根本的な理由は、大きなモデルでは存在しないものを作ることが当たり前になっているからです。しかし、物理世界の仕組みのロジックを正確に理解することは可能です。例えば、力がどのように相互作用するのか、摩擦はどのように生まれるのか、バスケットボールはどのように作られるのか、などです。しかし、物理的な世界がどのように機能するのか、力がどのように相互作用するのか、摩擦がどのように生まれるのか、バスケットボールがどのように放物線を描くのか、などのロジックを理解できることは、これまでどのモデルにもできなかったことであり、それこそが「そら」をビデオ世代のレベルを超えて根本的に重要なものにしているのだ。
しかし、デモから完成品への移行は、驚きや衝撃を与えることがある。メタ社のチーフ・サイエンティストであるリークン・ヤン氏は、「単に合図に合わせてリアルなビデオを生成できるだけでは、システムが本当に物理的な世界を理解していることを示すことにはならない。世界を理解しているとは言えない。生成モデルは可能性空間から妥当なサンプルを見つけるだけでよく、現実世界の因果関係を理解し、モデル化する必要はないのです」。
Qi Boringquanはまた、OpenAIがワールドモデルベースの生成的ビデオマクロモデリングが実現可能であることを検証している一方で、物理的相互作用の精度には困難があり、Soraはいくつかの基本的な物理的相互作用をシミュレートすることはできるが、より複雑な物理現象、長期的な依存関係を扱うのは難しいかもしれないと述べています。また、空間的なディテールの正確さが不十分であると、映像コンテンツの正確さや信頼性に影響を与える可能性があります。
Disrupting video, but much more than just video
Sora becomes the world simulator.
ワールド・シミュレーターになるのはずっと先のことかもしれないが、ビデオを生成するという点では、今すでに世界にインパクトを与えている。
1つ目のカテゴリーは、それまでの技術では解決できなかった問題を解決し、いくつかの産業を次のレベルに押し上げることです。
最も典型的なのは映画・テレビ制作業界であり、今回のSoraの最も画期的な能力は、1分という最長の動画を生成することです。参考までに、Pikaが生成する動画の長さは3秒で、RunwayのGen-2の長さは18秒である。つまり、Soraを使えば、AI動画が本当の生産性となり、コスト削減と効率化を達成できるようになる。
クン・チェン氏はLight Cone Intelligenceの取材に対し、Soraの誕生前、AIビデオツールを使ってSF映画を制作するコストは半分に下がり、Sora上陸後はさらに望ましいものになったと語った。
Soraがリリースされた後、彼が最も感銘を受けたのは、イルカが自転車に乗るデモだった。そのビデオでは、上半身はイルカ、下半身は人の両足で、足には靴が履いてあり、イルカが人間になりきって自転車に乗る動作を完成させるという、非常に奇抜な画風だった。
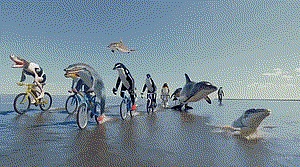
「これは私たちにとってただただ驚きです!私たちにとっては、ただただ驚きです!この映像は、想像力豊かでありながら物理法則に沿った不条理感を生み出し、感覚的でありながら予想外のものであり、これこそ観客が感嘆するような映画やテレビの作品なのです」とチェン・クンは語った。
陳坤氏は、ソラはスマートフォン、ジッターバグのようになり、すべてのコンテンツクリエイターの敷居が大きく下がり、コンテンツクリエイターが桁違いに増幅すると考えている。
「将来的には、コンテンツクリエイターは撮影する必要もないかもしれませんが、段落や単語を言うだけで、頭の中にあるユニークなアイデアを表現することができ、より多くの人に見てもらうことができます。その時、Jitterbugを超える新しいプラットフォームが生まれる可能性があると思います。一歩進んで、もしかしたらSoraはみんなの潜在意識を理解し、ユーザーが積極的に表現を求めなくても、自動的にコンテンツを生成・作成できるようになるかもしれません」とチェン・クンは語った。
ゲームについても同様で、OpenAIの技術レポートの最後には、My Worldのゲームプレイ動画が掲載されている。世界とそのダイナミクスを忠実にレンダリングしながら。Soraのプロンプトクレジットで「Minecraft」と言うだけで、これらの機能を刺激することができます。"

AIゲーム起業家のXi Chen氏は次のように語っています。
「これを読んだゲーム関係者は冷や汗ものだ! OpenAIはその野望を惜しげもなく明らかにした」。陳さんの解釈と分析によると、この短い文章は次の2つのことを伝えているそうです:Soraはゲームキャラクターをコントロールすることができ、同時にゲーム環境をレンダリングすることができる。
「OpenAIが言うように、Soraはシミュレータであり、ゲームエンジンであり、想像と現実世界の間の翻訳インターフェースです。soraは現在、1分間の世界を構築するために学習し、安定したキャラクターを生成し、独自のGPT-5を使用することで、数千平方キロメートルのあらゆる色のアクティブな生き物を持つ純粋なAI生成マップは、もはや気まぐれには聞こえません。もちろん、グラフィックをリアルタイムで生成できるかどうかや、オンライン・マルチプレイに対応しているかどうかは、すべて現実的な問題だ。しかし、いずれにせよ、新しいゲームモードが登場し、少なくとも『美女に囲まれて終了』を生成するためにSoraを使うことは間違いなくなってきている」とChen Xi氏は語った。
2つ目のカテゴリーは、世界をシミュレートし、より多くの分野で新しいものを創造する能力に基づいています。
エディンバラ大学の博士課程に在籍するヤオ・フー氏は、「生成モデルは、データそのものを記憶するのではなく、データを生成するためのアルゴリズムを学習します。言語モデルが(脳内で)言語を生成するアルゴリズムをエンコードするように、ビデオモデルはビデオストリームを生成する物理的エンジンをエンコードします。言語モデルは人間の脳を近似していると考えることができ、ビデオモデルは物理世界を近似しています。"
物理世界の普遍的な法則を学ぶことで、具現化された知性は人間の知性にも近づきます。
例えば、ロボット工学の分野では、以前の伝導プロセスでは、ロボットの脳に握手の命令を与え、それを手に渡していましたが、ロボットは「握手」の意味をよく理解できなかったため、命令を次のように翻訳することしかできませんでした。「手の直径を何センチに縮めるか」である。もしワールド・シミュレーターが実現すれば、ロボットはコマンドの翻訳プロセスを省略し、人間のコマンドの必要性をワンステップで理解できるようになるだろう。
トランス・ディメンショナル・インテリジェンスの創設者で華南理工大学教授の賈逵氏は、ライトコーン・インテリジェンスに対し、明示的な物理シミュレーションが将来的にロボット工学に応用される可能性があると語った。理解し、シミュレーションすることで、効果を生み出すことができる。"ロボットに直接役立つためには、明示的である方が良いと思う。"
「そらの能力は、依然として膨大な量のビデオデータと再キャプチャ技術によって達成されており、物理的なシミュレーションはおろか、3Dで明示的にモデル化されてもいません。生成されるエフェクトは、物理シミュレーションで実現できるものに限りなく近い。しかし、物理エンジンは単にビデオを生成するだけでなく、ロボットを訓練するために存在しなければならない他の多くの要素があります」とジャッキー氏は言います。
Soraにはまだ多くの制限がありますが、仮想世界と現実世界のリンクが作成されたことで、トップガンのような仮想世界と、より人間に近いロボットの両方の可能性が広がりました。
本日の記事では、引き続きライトニング・ネットワークを紹介し、その仕組みとテクノロジーについてお話しします。
JinseFinanceArweave,Arweaveの仕組みと存在意義 Golden Finance,この記事では、Arweaveの仕組みと存在意義について簡単に説明します。
JinseFinanceグーグルの新しいAIモデル「HEAR」は、咳や呼吸などの音を分析することで、生体音響分析を用いて健康状態の初期兆候を検出する。サルシット・テクノロジーズと提携することで、グーグルは病気の早期発見とアクセシビリティの向上を目指しているが、AIの精度を確保し、医療の信頼を得ることには課題が残っている。
 Joy
Joyイーサリアムのレイヤー2ネットワークであるZircuitは、トランザクションのセキュリティと効率性を高めるためにAIを搭載したシーケンサーで際立っており、Binance Labsの支援を受けたメインネットのローンチに先立ち、33億ドル以上のステークアセットを集めている。
Joy2日前、外国メディアはソラのコアチームにインタビューを行い、元のビデオを見て、何も言うことはありません、シーンは馬発展改革委員会主任の演説のようなものです。
JinseFinanceAIとWeb3の融合の未来:分散型演算、ビッグデータ、Dappイノベーション、そして産業イノベーションへの広範囲な影響を探る。
JinseFinanceAIとWeb3の融合には、分散型演算、アルゴリズムとモデルのコラボレーション、分散型ビッグデータ、AI対応Dappsという4つの道がある。
JinseFinanceソラがAIの新たなマイルストーンとなった理由は?どのようにしてAIGC(AIコンテンツ作成上限)を破ったのか?客観的に見て、現在の「そら」に限界や欠点はあるのか?
JinseFinanceSoraはOpenAIが開発したAIモデルで、ユーザーが入力したテキストコマンドに基づいて、リアルで想像力豊かなビデオシーンを生成する。
JinseFinanceどのプロジェクトが好調で、どこに新たな勢力が出現しているのか?
JinseFinance