JPモルガン:ビットコインは「すでに金を上回る
JPモルガン・チェースが木曜日に発表したレポートによると、ビットコインは投資家のポートフォリオにおいて金よりも人気がある。
 JinseFinance
JinseFinance

ソース:Zepin Macro
OpenAI は2月16日、動画生成モデル「Sora」をリリースしました。Soraは、主要な測定基準において、いくつかの以前のビデオ生成モデルを大幅に上回っており、ビデオ生成に使用することで、物理世界の空間シミュレーションが、ほぼ現実的なレベルにまで達していることが明らかになりました。
なぜSoraはAIにおける新たなマイルストーンなのでしょうか?AIコンテンツ制作の上限であるAIGCをどのように破ったのでしょうか?客観的に見て、現在のバージョンのSoraの限界や欠点はありますか?
Soraのような動画生成クラスモデルの今後のアップデートや反復の方向性は?どのような業界を混乱させるのでしょうか?私たち一人ひとりにどのような影響を与えるのでしょうか?その背後には、どのような新しい産業の機会が潜んでいるのか?
SoraがAIのマイルストーンであるのは、AIGCのAIによるコンテンツ作成の上限を再び押し上げたからです。以前、人々はChatgptのようなテキストベースのコンテンツ作成支援、イラストや画面生成の支援、短い動画にアバターを使うことを始めていました。Soraはビッグモデルのビデオ生成クラスであり、テキストや画像の入力を介して、ビデオを編集するために、接続、拡張、および他の方法を生成することができ、マルチモーダルビッグモデルのカテゴリに属し、モデルのこのクラスは、さらなる拡張、拡張上のビッグモデルの言語クラスなどのGPTにある。".このモデルの主な革新点は、ビデオフレームを、言語モデルにおける単語トークンに類似した、パッチのシーケンスとして扱うことであり、幅広いビデオの効率的な管理を可能にする。このアプローチは、テキストによる条件生成と組み合わされることで、Soraがテキストの手がかりに基づいて、文脈に関連した、視覚的に一貫性のあるビデオを生成することを可能にします。
原則的に、Soraは3つの主要なステップでビデオトレーニングを実施する。1つ目はビデオ圧縮ネットワークで、ビデオや画像をコンパクトで効率的な形に縮小します。2つ目は時空間パッチ抽出で、ビュー情報をより小さなユニットに分解する。最後に、ビデオ生成があり、入力テキストまたは画像がデコードおよびエンコードされ、トランスフォーマ モデル (すなわち、ChatGPT ベース コンバーター) が、テキストおよび画像キュー内のコンテンツが完全なビデオに形成されるように、これらのユニットをどのように変換または結合するかを決定します。
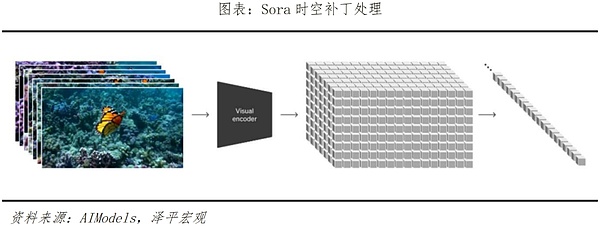
Sora は、動画生成モデルにとって最も重要な2つの指標である再生時間と解像度において、以前の動画生成モデルを劇的に上回っています。Soraは、動画生成モデルにとって最も重要な2つの指標である「継続時間」と「解像度」において、これまでの動画生成モデルを劇的に凌駕しています。Soraがリリースされる前、Pika1.0、Emu Video、Gen-2といった主なモデルは、それぞれ3~7秒、4秒、4~16秒の動画を生成することができましたが、Soraは1080pの解像度で60秒の動画を生成することができます。Soraはテキストプロンプトに基づいてビデオを生成するだけでなく、ビデオの編集や拡張機能も備えています。Soraはテキストに対する理解も深い。テキスト解析の訓練を受けたSoraは、テキストコマンドの背後にある感情的な意味を正確に捉えて理解し、テキストプロンプトをシーンにマッチした詳細なビデオコンテンツにスムーズかつ自然に変換することができます。
Soraはビデオ生成において、仮想世界の物理法則をよりよくシミュレートすることができ、物理世界をよりよく理解することができる。その技術的な特徴は主に2つあります。
1つは、複数のショットでコヒーレントな3D空間モーションビデオを生成する能力です。
2つ目は、異なる視点で同じオブジェクトの一貫性を維持する能力です。このようにして、モデルは映像内のキャラクター、オブジェクト、およびシーンの動きの一貫性と連続性を維持し、単純な相互作用のために、世界の要素に影響を与えるように微調整できます。Pikaのような従来のモデルとは対照的に、Soraは映像のカラースタイルやその他の要素を正確に理解した上で映像を生成し、表情豊かなキャラクターや生き生きとした感情を持つ映像コンテンツを作成します。また、被写体と背景の関係を重視しているため、映像の被写体と背景の相互作用は非常に流動的で安定しており、サブシーンの切り替えも論理的です。
生成されたビデオの公式な例では、「スタイリッシュな女性が、温かみのあるネオンとアニメーション化された都市標識で満たされた東京の通りを歩いている。黒のレザージャケットに赤いロングドレス、黒のブーツを履き、黒のレザーバッグを持っている。サングラスに赤い口紅。彼女は自信とカジュアルさを持って歩いている。通りは濡れて反射し、色とりどりの光で鏡のような効果を生み出している。多くの歩行者が歩いている」、空は、肌に至るまで完全なディテールを達成し、光と影の反射の動き方、カメラの動き方に臨場感がある。

2.そらのレベルは?制限はありますか?
Soraは言語モデルのChatGPT 3.5に相当します。
SoraとChatGPTは、拡散モデルが構築されたTransformerアーキテクチャから派生したもので、奥行き、オブジェクトの永続性、自然なダイナミクスを示すのに優れています。これまでの実世界シミュレーションは、3D物理モデリング用のGPU駆動ゲームエンジンを使って実行されるのが一般的で、高水準の環境シミュレーションと多様なインタラクティブアクションを実現するためには、人間が構築し、高精度の複雑なプロセスが必要でした。しかし、Soraモデルにはデータ駆動型の物理エンジンやグラフィック・プログラミングがなく、より要求の厳しい3D構築では精度が劣ります。その結果、複数のキャラクターの自然な相互作用や、環境のリアルなシミュレーションを達成することは依然として困難です。
たとえば、Sora のビデオ生成におけるバグの例を 2 つ挙げます。
Sora が「こぼれたグラスに液体が飛び散る」というテキストを入力すると、グラスが溶けてテーブルになり、液体がグラスを飛び越える様子が表示されますが、グラスが飛び散るような効果はありません。は飛び散りません。
もうひとつの例は、浜辺から突然椅子が掘り起こされたとき、AIはその椅子を非常に軽い物質だと思い、ただ浮き上がってくることができるほどです。

この種の「エラー」には主に2つの理由があります。1つは、モデルが自動補完生成において、テキスト計画の一部ではないオブジェクトまたはエンティティを自発的に生成してしまうことです。シナリオによっては、OpenAIの「Walking through the streets of Japan in winter」の場合のように、動画にリアリズムを加えることができますが、より多くの環境では、何もないところから生成されたテーブルが水に変わってしまった最初の例のように、動画の物理法則のもっともらしさを減らしてしまうことがあります。
2つ目は、ソラのシミュレーションで起こっているアクションが多い場合、時間的にも空間的にも順序が混乱しやすいということです。例えば、「トレッドミルの上を走る人」と入力すると、トレッドミルの上を間違った方向に歩く人が生成される可能性が高い。このように、Soraは、より複雑な現実世界の物理的相互作用、ダイナミクス、因果関係を正確にモデル化し、単純な物理的特性やオブジェクトの特性をシミュレートするのは難しいままです。
これらの継続的な問題にもかかわらず、Soraはビデオモデリングの将来的な可能性を示しており、十分なデータと計算能力があれば、ビデオコンバータは現実世界の物理、因果関係、および関係をより深く理解し始めるかもしれません。これにより、動画のシミュレーション世界に基づいたAIシステムを訓練する新しい方法が可能になるかもしれません。
Soraは動画生成カテゴリーにおけるAIの最先端を象徴していますが、その将来的な有効性は、おそらく3つの大きな方向性で向上させることができます:
1つは、データの次元から始めることです。トレーニングのためのデータ需要の急増に伴い、将来はトレーニング可能なデータサンプルの不足に直面します。現在、主なビッグモデルは言語テキストに依存していますが、Soraは画像入力も可能ですが、学習の汎用性はテキストほどではありません。参加者数が指数関数的に増加する中で、単一のデータタイプと限られた高品質データはすぐに枯渇してしまうかもしれない。
コーネル大学の研究によると、ビッグモデルのトレーニング用の高品質データは2026年までに枯渇する可能性が高く、低品質のテキストデータは2030年以降に枯渇するようです。データソースの次元を拡張することが、Soraのソリューションです。テキストと画像に加えて、音声、ビデオ、熱、電位、深度もすべて、Soraの学習の拡張領域となり得る。真にマルチモーダルなグランドモデルとなるのに役立つ。例えば、MetaのオープンソースであるImageBindは、DINOv2の画像やビデオ認識機能だけでなく、赤外線や慣性計測ユニットなど、複数の感覚を備えており、深度、熱エネルギー、電位エネルギーなどの異なるモダリティを認識し、学習することができます。
2つ目はアルゴリズム層の最適化で、これはモデル学習における「オーバーフィット」と「アンダーフィット」現象を解決する鍵です。前の例で述べたように、Soraはテキストプランにないオブジェクトやエンティティを自発的に生成するので、映像効果のリアリズムを向上させるのに役立ちます。しかし、場合によっては、2つの非常に関連性の高い要素が、適用できないシナリオで一緒に現れることがあります。つまり、アルゴリズムが特定の結果を達成するために「オーバーフィッティング」しているのです。この現象は、人間が試験の準備のために、あるクラスの問題に正しく答えるために集中的な訓練を繰り返すことに似ており、その結果、試験の同じクラスの問題で多くのミスが発生することになります。
また、同じ例では、コップが倒されたのに割れないで溶けてしまったが、これはモデルが「アンダーフィット」だったからである。これらの2つのタイプの問題は、モデルが正確に分類されていないサンプルで訓練され、その結果、最適なモデルではない決定木になり、実際のアプリケーションの汎化性能の劣化につながるために発生します。オーバーフィッティングやアンダーフィッティングを完全に排除することはできませんが、正則化、データクリーニング、学習サンプルのサイズ縮小、Dropout廃棄、プルーニングアルゴリズムなどの方法によって、将来的に軽減・削減することができます。
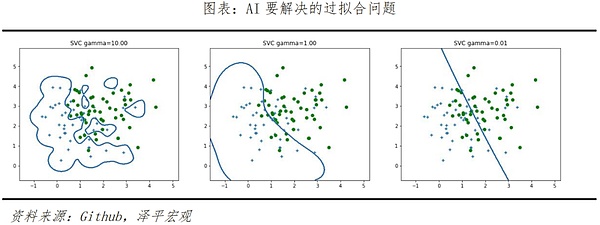
第三は、演算業界です。soraはまた、2024年に演算能力の需要につながるAIの波を爆発させるために続けているマルチモーダルモデルの開発において、AI企業は、より大きく、より高い求めている高いでしょう。チップのR&D設計レイアウト、さらにはEDAとウェハ分野に、業界チェーンの上流カットの強さ。
現在のAIモデルのトレーニングは主にNVIDIA GPUに依存しているが、主流の演算チップはすでに供給不足に陥っており、2024年までの予測需要は150万~200万に達する。
OpenAIの創業者サム・アルトマンは2018年から自社チップの需給に注目し、AIチップ企業Rain Neuromorphicsに投資し、2019年にRainのチップを購入、そして2023年11月にサムは「Tigris」というコードネームのチップ企業に数十億ドルを求めた。サムは2023年11月、「Tigris」というコードネームのチップ企業のために数十億ドルの融資を求めている。
テスラは、スマートカーでAIトラックの歯を切り、また、自動運転アルゴリズムの基本ディスク上のチップ設計に上流に移動し、徐々に中流の制御を求めている。
ARM、NVIDIA、TSMCによって構築されたグローバルAI半導体産業チェーンは、短期的には最大の利益を得るものの、中長期的にはより大きな競争をもたらす可能性があることは予見できる。演算インフラ、特に演算チップの自律的な建設は、中国がAI路線で世界の進歩に歩調を合わせるための重要な方向であり続けている。
年初のアップルのVision Proヘッドセットのリリースから、大手PCメーカーによるAIPCの相次ぐリリース、そしてOpenAIによるSoraのリリースに至るまで、世界のAIにおけるイノベーションは加速しており、その反復はますます速くなっている。
今後、AIが自動的に作成・生成するコンテンツは多くの産業分野に影響を与え、話題の「タイムリーな報道」がAIの主な仕事となり、主にAIGCの効率性と、誰もがAIを使いこなす能力を競うことになり、Soraのような話題を使いこなせるのは誰か、という競争になる。競争は、AIを活用するみんなの能力であり、誰がそらのような強力なAIプロダクションツールを活用できるかということだ。将来的には、「小説を投げて、大ヒット作を作る」ことは不可能ではありません。Soraは最大1分間の動画を生成することができ、動画は最後まで鏡になることができ、マルチアングルのレンズ切り替えができ、対象は常に同じです。ソラの動画は、風景や表情、色彩などのカメラ言語を使って、寂しさ、賑やかさ、ダサさなどの感情色を表現することもできる。要するに、将来的にもっとソラがあれば、あるいは上記のようないくつかの角度から生成的なビデオのこれらの大規模なモデルがラグを改善するために、AIのビデオ効果の将来は、おそらくほとんどと人工的な撮影は似ていません。
マルチモーダルモデルのアプリケーションは2024年に夜明けを迎え、映画やテレビ、ライブ放送、メディア、広告、アニメーション、アート、デザイン、および他のいくつかの産業に影響を与えます。現在のショートビデオの時代において、Soraはショートビデオの撮影、演出、編集を担ってきた。将来的には、Soraは、現在のショートビデオ、ライブ、映画やテレビ、アニメーション、広告や他の産業のために、ビデオのさまざまな用途の様々な生成深い影響を与えるだろう。
例えば、ショートビデオ制作の分野では、 Soraはショートドラマ制作の包括的なコストを大幅に削減し、「重い制作と軽い制作」という共通の問題を解決するために、ショートドラマ制作の焦点は、高品質の脚本とコンテンツ制作の未来に戻ることが期待され、テストは優秀なクリエイターです!というのが主な理由だ。Soraは関連業界の企業にとって、実にコスト削減と効率化が期待できる。広告制作会社はSoraモデルを使ってブランドに準拠した広告動画を生成し、撮影やポストプロダクションのコストを大幅に削減する。ゲームやアニメ制作会社はSoraを使ってゲームシーンやキャラクターアニメーションを直接生成し、3Dモデリングやアニメーション制作のコストを削減する。企業にとってのコスト削減は、製品・サービスの品質向上や技術革新に活用でき、さらなる生産性向上を促進する。2023年が世界的なAIビッグモデル爆発とグラフィック生成元年だとすれば、業界は2024年にAI動画生成とマルチモーダルビッグモデル元年に突入することになる。ChatgptからSoraまで、AIがあらゆる個人とあらゆる産業に影響を与え、変化する現実が徐々に起こっている。
JPモルガン・チェースが木曜日に発表したレポートによると、ビットコインは投資家のポートフォリオにおいて金よりも人気がある。
JinseFinanceマイニング, 半減, JPモルガン, JPモルガン:ビットコイン半減は上場マイナーに恩恵をもたらす GOLDEN FINANCE, JPモルガンは、半減は上場マイナーのシェアを増加させると述べている。
JinseFinanceJPモルガンがリスクを理由にテザー社の市場支配を批判、テザー社CEOは規制当局との協力と業界の重要性を強調し弁明。
 Brian
Brianアナリストによると、Tetherは規制遵守と透明性の欠如のために最も危険にさらされており、Tetherの競争相手であるCircleは、今後のステーブルコイン規制に積極的に備えているようだ。
JinseFinanceJPモルガン・チェースの口座閉鎖問題は、銀行業務における透明性と公正な顧客サービスの必要性を浮き彫りにした。
 Cheng Yuan
Cheng YuanJPモルガン・チェースはその公認参加者であり、仲介会社である。ETFはまずビットコインを現金に換えることで実施され、その逆も可能である。
JinseFinance詳細な事後分析と次のステップ
 Others
OthersJPモルガンのウマル・ファルークが「ほとんどの仮想通貨はいまだにジャンクだ」という言葉を口にするやいなや、金融庁は...
 Ledgerinsights
Ledgerinsightsブロックチェーンベースのビデオゲーム会社である Fracture Labs は、昨年 11 月に成功した 430 万ドルの資金調達ラウンドに続き、新しい開発を発表しました ...
 Bitcoinist
Bitcoinist金融機関は stETH 取引プールから逃げ出しており、暗号化市場は風雨に見舞われようとしていますか?
 链向资讯
链向资讯