壁に囲まれたコイン市場はやってくるか?判断するための4つの重要指標
トレントシーズンは、トレントがビットコインを追い抜き、高いリターンをもたらす短期的な現象で、2025年の主な指標はBTC.D、ETH/BTC、USDT.D、OTHERS/BTCと予測されている。
 JinseFinance
JinseFinance

著者:Tu Min, CSDN
今年の5月は、まるで2023年3月の夢を見ているようで、賑やかなAIの宴が次々と行われています。
しかし、意図的かどうかはわかりませんが、昨年3月、Googleはビッグ言語モデル(BLM)のPaLM APIを公開することを選択し、ほぼ同時にOpenAIは最強のモデルであるGPT-4を公開し、世間を驚かせ、そのわずか数日後、MicrosoftはOfficeバケットがGPT-4によって革命を起こしたと発表しました。GPT-4は世界初のものであり、グーグルのような企業が使用するものとしては世界初である。
やや気恥ずかしいのは、今年も同じ状況が演出されるようで、一方では OpenAIが昨日の早朝、今月のAI春祭りの夜のオープニングとして、完全にアップグレードされたフラッグシップGPT4o をもたらすために、他方では、マイクロソフトは来週ブリード2024年に開催されるので、Googleのピンチによって再びこの時間は、風を回すために逆転することができます!2つの "局のグループ "は、我々は今朝早くI/O 2024開発者会議のオープニングから表示されます。
今年のI/Oカンファレンスは、グーグルの旗艦戦略「AIファースト」の8年目でもある。
予想通り、「AI」は約2時間の基調講演でI/Oカンファレンス全体を貫くキーワードでした。

外部からの競合を前に、グーグルCEOのスンダル・ピチャイ(Sundar Pichai)は先日、ゲスト番組で「AIはまだ開発の初期段階にある。
私は、グーグルが検索を最初に行った会社ではないように、開発の初期段階であっても、最終的にはグーグルがこの戦争に勝つと信じている。
I/Oカンファレンスでスンダー・ピチャイは同じ点を強調し、「我々はまだAIプラットフォームシフトの初期段階にいる。私たちは、クリエイター、開発者、スタートアップ、そしてすべての人に大きなチャンスがあると考えています。"
Sundar Pichai氏は、Geminiが昨年リリースされたとき、テキスト、画像、動画、コードなどを横断して推論できる、大きなマルチモーダルモデルとして位置づけられたと述べた。2月、グーグルは長文テキストにおけるブレークスルーとなるGemini 1.5 Proをリリースし、コンテキストウィンドウを他のどの大規模ベースモデルよりも多い100万トークンに拡張した。現在、150万人以上の開発者がGoogleツールでGeminiモデルを使用しています。
Gemini アプリがAndroidとiOS向けに公開されました。Gemini Advancedを使えば、ユーザーはGoogleの最もパワフルなモデルにアクセスできます。
Googleは、Gemini 1.5 Proの改良版を世界中のすべての開発者に提供しています。加えて、Gemini 1.5 Proは、今日100万のトークンコンテキストを持ち、35の言語で利用可能なGemini Advancedで消費者が直接利用できるようになりました。
Googleは、Gemini 1.5 Proのコンテキストウィンドウを200万トークンに拡大し、プライベートプレビューで開発者が利用できるようにしました。
私たちはまだAgentの初期段階にいますが、GoogleはすでにまずAgentの探求を始めており、スマートフォンのカメラを通して世界を分析するProject Astraを試したり、コードを識別して解釈したり、人間がメガネを見つけるのを助けたり、音を認識したり...。
Gemini 1.5 Proよりも軽量なGemini 1.5 Flashがリリースされ、低遅延やコストといった重要なタスクのために最適化された。
1080pの「高品質」ビデオを生成するVeoモデルとテキスト生成イメージモデルであるImagen 3がリリースされました。
新しいアーキテクチャと27Bのサイズを持つGemma 2.0が登場しました。
デバイスのベースモデルを内蔵した初のモバイルOSであるAndroidは、Geminiモデルを深く統合し、Google AIを中核とするOSとなりました。
第6世代のTPUであるTrilliumがリリースされました。前世代のTPU v5eと比べて4.7倍向上しています。
非常に大きなモデルを行うと言われています。"
Googleの "狂気を殺す"、様々なモデルがリリースされています。今回のカンファレンスでは、Googleが過去の大型モデルをアップグレードしただけでなく、さまざまな新モデルを発表した。
Gemini が昨年リリースされたとき、グーグルはそれを、テキスト、画像、動画、コードなどを横断して推論できる、大規模なマルチモーダルモデルと位置づけていました。2月、GoogleはGemini 1.5 Proをリリースしました。これは、コンテキストウィンドウの長さを100万トークンにまで拡張し、他のどの大規模な基本モデルよりも長いテキストにおける画期的なものです。
Gemini 1.5 Proは、翻訳、エンコーディング、推論といったGemini 1.5 Proの主要なユースケースの品質向上から始まり、より複雑なタスクをより幅広く処理できるようになった。1.5 Proは、ロール、フォーマット、スタイルを含む製品レベルの動作を指定するコマンドなど、複雑で微妙なコマンドに従うことができるようになった。また、システムコマンドを設定することで、ユーザーがモデルの動作を制御できるようになりました。
同時に、GoogleはGemini APIとGoogle AI Studioに音声理解を追加し、1.5 ProはGoogle AI Studioにアップロードされた動画から画像と音声を推論できるようになりました。
さらに注目すべきは、100万トークンのコンテキストが十分な長さであったかのように、Googleは本日、コンテキストウィンドウを200万トークンに拡張し、プライベートプレビューで開発者が利用できるようにすることで、その機能をさらに拡張しました。
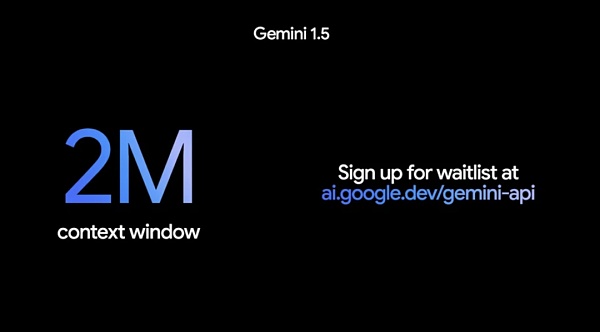
200 万トークンのコンテキストウィンドウを持つ 1.5 Pro にアクセスするには、Google AI Studio に参加するか、Google Cloud のユーザーの場合は Vertex AI のウェイティングリストに参加する必要があります。に参加する必要があります。
Gemini 1.5 Flashは、スケーリング用に構築された軽量モデルであり、API内で最速のGeminiモデルです。低レイテンシでコストクリティカルなタスクのために最適化され、より費用対効果の高いサービスを提供し、画期的に長いコンテキストウィンドウを特徴としています。

1.5 Proモデルよりも重量は軽いものの、膨大な情報量のマルチモーダルな推論が可能です。デフォルトで、Flashには100万トークンのコンテキストウィンドウが付属しており、1時間のビデオ、11時間のオーディオ、30,000行以上のコードベース、または700,000以上の単語を扱うことができます。
Gemini 1.5 Flashは、要約、チャット、画像やビデオへのキャプション付け、長い文書や表からのデータ抽出などに優れています。
Gemini 1.5 Flashは、画像や動画にキャプションを付けたり、長い文書や表からデータを抽出したりすることなどに優れています。これは、1.5 Proが蒸留と呼ばれるプロセスを通して学習させるためで、より大きなモデルから、より小さく効率的なモデルへと、最も重要な知識やスキルを移します。
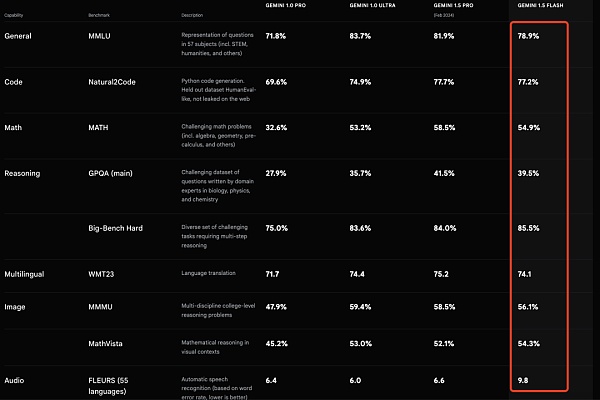
Gemini 1.5 Flashの価格は、100万トークンあたり35セントで、GPT-4oの100万トークンあたり5ドルより少し安いです。
Gemini 1.5 Flashの価格は100万トークンあたり35セントで、GPT-4oの100万トークンあたり5ドルよりも安い。
Gemini 1.5 Proと1.5 Flashの両方は、パブリックプレビューとGoogle AI StudioおよびVertex AIで利用可能です。
PaliGemmaは、PaLI-3にインスパイアされた、強力でオープンなVLM(視覚言語モデル)です。 PaliGemmaは、SigLIP視覚モデルやGemma言語モデルなどのオープンコンポーネントに基づいています。PaliGemmaは、SigLIP視覚モデルやGemma言語モデルなどのオープンなコンポーネントをベースにしており、幅広い視覚言語タスクにおいてクラス最高の微調整性能を達成するように設計されています。これには、画像や短い動画のキャプション付け、視覚的なクイズ、画像内のテキストの理解、オブジェクトの検出、オブジェクトのセグメンテーションなどが含まれます。
グーグルによると、オープンな探求と研究を促進するため、PaliGemmaはさまざまなプラットフォームやリソースを通じて利用可能で、GitHub、Hugging Face Models、Kaggle、Vertex AI Model Garden、ai.nvidia.com(TensoRT-LLMを使用)で見つけることができます。Acceleratedを使って)PaliGemmaを見つけ、JAXやHugging Face Transformers と簡単に統合することができます。
全リリースのGemma 2は、画期的なパフォーマンスと効率を実現するために設計された、まったく新しいアーキテクチャで、新しいサイズで提供されます。270億のパラメーターを持つGemma 2は、Llama 3 70Bに匹敵するパフォーマンスを提供しますが、サイズはLlama 3 70Bの半分です。

Gemma 2の効率的な設計は、同等のモデルの半分以下の計算しか必要としないとGoogleは述べています。27Bのモデルは、NVIDIAのGPU上で動作するように最適化されており、Vertex AIの単一のTPUホスト上でも効率的に動作させることができるため、より幅広いユーザーへの展開が容易になり、費用対効果も向上します。

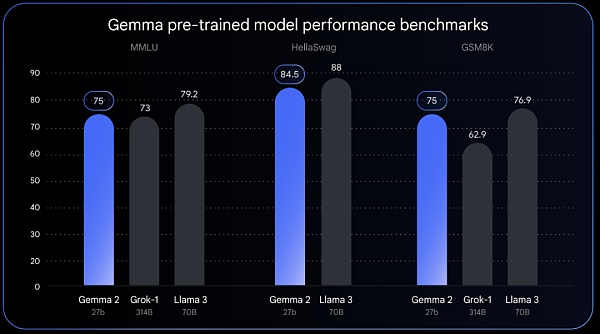
Gemma 2は6月に発売予定です。月発売予定です。
OpenAIのSoraに対抗するものとして考えられているGoogleは、本日、1分以上かかることもある、幅広い映画的・視覚的スタイルの高品質な1080p解像度の動画を生成する動画生成モデル、Veoを発表しました。
Veo は、Generative Query Networks (GQN)、DVD-GAN、Imagen-Video、Phenaki、WALT、VideoPoet、Lumiere などの生成的動画モデルに関する Google の長年の研究を基盤としており、アーキテクチャ、スケーリング法則、その他の技術を組み合わせて、品質と出力解像度を向上させています。.
本日より、ユーザーはウェイティングリストに参加して、Veoへのアクセスをリクエストすることができます。
Googleの以前のモデルよりも、気が散るような視覚的アーチファクトがはるかに少なくなっており、新しくリリースされたImagen 3は、自然言語をよりよく理解することができます。自然言語やキューの背後にある意図をよりよく理解し、長いキューに小さな詳細を組み込むことができます。

Imagen 3は本日より、クリエイターがImageFXで個人的にプレビューできるようになり、ウェイティングリストに参加できるようになりました。 Imagen 3はVertex AIとともに近日公開予定です。
エージェントとは、推論、計画、記憶する能力を持ち、複数のステップを先読みして「考える」ことができ、ソフトウェアやシステムにまたがって動作するインテリジェントなシステムのことです。
エージェントとはインテリジェントなシステムのことです。
本日のカンファレンスで、Google DeepMindの共同設立者であるデミス・ハービス(Demis&Harbis&Harbis)CEOは、Googleが日常生活に役立つ一般的なAIエージェントの開発に取り組んでおり、プロジェクトAstra(Advanced Visual and Speech Response Agent)はその主要な試みの1つであることを明らかにしました。Project Astra (Advanced Visual and Speech Response Agent)はその主要な試みのひとつである。
このプロジェクトは、Googleが開発したプロトタイプエージェントであるGeminiをベースにしており、ビデオフレームを順次エンコードし、ビデオと音声入力をイベントのタイムラインに組み合わせ、効率的に呼び出すためにその情報をキャッシュすることで、より高速に情報を処理します。
音声モデルを活用することで、グーグルはエージェントに幅広いトーンを提供するために発音も強化しました。これらのエージェントは、使用しているコンテキストをよりよく理解し、対話で素早く応答することができます。
発表会で実演された例では、「Project Astra」によって、現実のシナリオで音を出すものが自動的に認識され、音を出している特定の部品の場所を直接特定することもできるほか、コンピュータの画面に表示されるコードの役割を説明したり、人間が眼鏡を見つけるのを助けたりすることなどができる。
「このような技術があれば、人々が携帯電話やメガネ型デバイスを通じて、プロのAIアシスタントを持つことができる未来を想像するのは簡単です。これらの機能の一部は、今年の後半にGoogle製品に搭載される予定です」とGoogleは述べています。
現在、改良されたGemini 1.5 Proが、世界中のすべての開発者向けのGemini Advancedサブスクリプションに導入されています。すべての開発者に、35の言語で利用可能なGemini 1.5 Proの改良版が提供されます。
デフォルトでは、前述のように、Gemini 1.5 Proは100万トークンのコンテキストを持ち、この長いコンテキストウィンドウは、Gemini Advancedが、合計1,500ページまでと予想される複数の大きなドキュメントを理解したり、100通の電子メールを要約したり、1時間のビデオコンテンツを処理したり、30,000行を超えるコードベースを理解したりできることを意味する。コードベース。
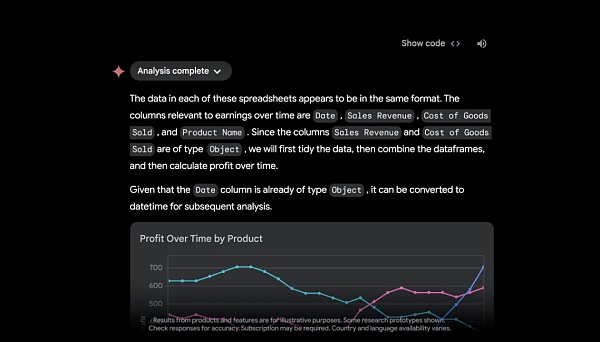
Googleドライブ上のファイルをアップロードしたり、デバイスから直接アップロードしたりする機能により、Googleは、まもなくGemini Advancedがデータアナリストとして機能し、スプレッドシートなどのアップロードされたデータファイルから洞察を発見し、カスタムビジュアライゼーションやチャートを動的に構築することを明らかにした。
Gemini Advancedの購読者は、よりパーソナライズされたエクスペリエンスを得るために、まもなくGemsを作成できるようになる。
を作成できるようになります。フィットネス・バディ、スーシェフ、コーディング・バディ、クリエイティブ・ライティング・ガイドなど、お好きなジェムを作成できます。例えば、"あなたは私のランニングコーチで、毎日のランニングスケジュールを教えてくれ、前向きで明るく、やる気を維持してくれる"。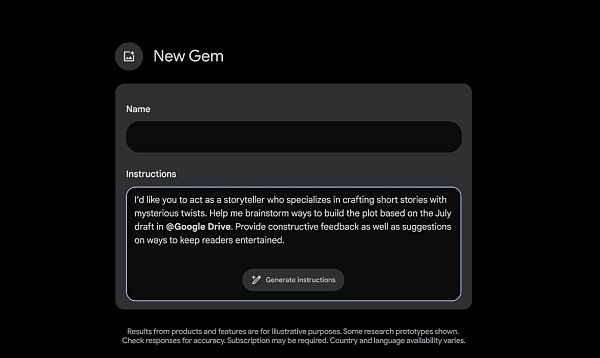
商業的なシナリオを現場で適用しなければ、ビッグモデル技術の反復は「紙の上」にすぎないように思えます。OpenAIの歩む道は、AI応用路線でスピードを競っているGoogleやMicrosoftとは異なる。検索エンジンとして出発したグーグルにとって、このAIの波に乗り遅れることはないに違いない。
グーグルの副社長兼検索責任者のリズ・リード氏は、「ジェネレーティブAIを使えば、検索は想像以上のことができる。調査から計画、ブレインストーミングまで、あなたが思いつくこと、成し遂げなければならないことは何でも思いつくことができ、グーグルはすべての用事を引き受けてくれるのです。"
発表会でグーグルは、「1回の検索で、必要な情報をすべて得られる」AIオーバービューという機能を発表した。検索すれば、すべての情報が得られる」。
簡単に言えば、すぐに答えが欲しいが、必要な情報をまとめている時間がない場合、例えば、新しいヨガやピラティスのスタジオを探していて、地元の人に人気があり、通いやすく、新規会員には割引があるスタジオがいい場合、ニーズを述べて検索を実行するだけでいい。AIが複雑な問題に対する答えを提供します。
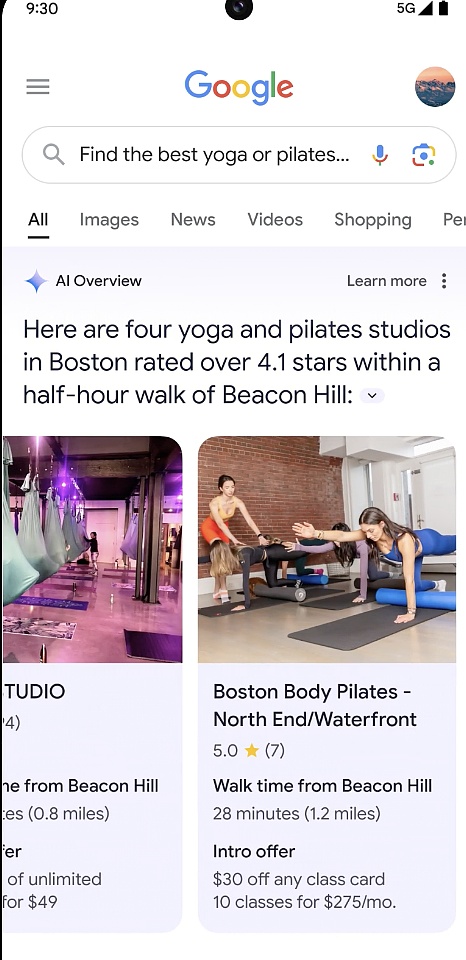
動画理解の進歩により、Googleはビジュアル検索機能を強化しました。ビジュアル検索機能が強化されました。Google Lensの動画検索を使えば、抱えている問題や身の回りにあるもの(動いているものも含む)を撮影して、答えを検索することができます。
ただし、この2つの機能は今のところ米国でのみ利用可能で、今後さらに多くの国で利用できるようになる予定です。
検索レベル以外にも、ビッグモデルの登場によって、製品のインテリジェンスはさらに強化されるでしょう。
写真検索アプリのレベルでは、Googleは写真を尋ねる機能をもたらします。
Geminiを使えば、写真の中のさまざまな文脈情報を特定することができます。娘の様子は?
Gemini(ジェミニ)
を使えば、写真に写っているさまざまな情報を特定することができます。
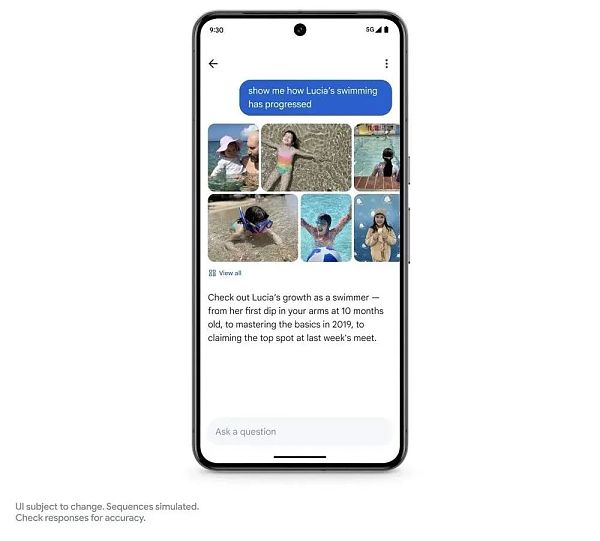
この1つの機能はまだ公開されていませんが、Googleは今年の夏に登場すると言っています。
Googleはまた、大きなモデルをGoogle Workspaceに統合しました。例えば、Gmail内のメールを検索したり、学校との最新の電子メールに接続して学校のワークフローを把握したりすることで、子供の学校で起きていることすべてを把握することができます。ジェミニに学校からの最近のメールをすべて要約してもらうことができます。バックグラウンドで関連するメールを識別し、PDFなどの添付ファイルまで分析します。
NotebookLMはGoogleが昨年7月に発表したAIノートアプリで、アップロードされたドキュメントを要約してアイデアを作成します。
マルチモーダルビッグモデル技術に基づき、Googleはこのアプリに音声出力を追加しました。Gemini 1.5 Proを使用して、ユーザーのソース資料を取り込み、パーソナライズされたインタラクティブな音声対話を生成します。
AIでオペレーティングシステムをアップグレードすることは、マイクロソフトとグーグルが力を入れていることです。何十億人ものユーザーを抱える世界ナンバーワンのモバイルオペレーティングシステムとして、GoogleはGeminiモデルをAndroidに統合し、多くの便利なAI機能を導入したと述べています。

例えば「Circle to Search」は、ユーザーがアプリを切り替えることなく、円を描く、落書きする、タップするなどの組み合わせで検索できるようにするものだ。例えば、「Circle to Search」は、ユーザーがアプリを切り替えることなく、円を描く、落書きする、タップするなどのシンプルなインタラクションを使って、より多くの情報にアクセスできるようにします。今日、「Circle to Search」は、物理や数学のさまざまな問題を解くためのステップバイステップの指示を与えながら、出てきたヒントを丸で囲むことで、答えだけでなく、より深い理解を得ることができるため、学生の宿題を手助けすることができます。
また、Googleは近日中にAndroidのGeminiをアップデートし、ユーザーがアプリの上部にあるGeminiのオーバーレイを簡単に引き出せるようにする予定です。
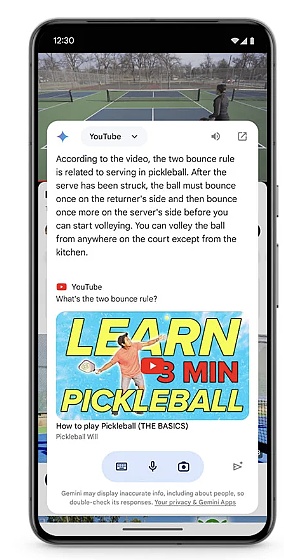
「Androidは、デバイスベースモデルを内蔵した最初のモバイルオペレーティングシステム」であり、Gemini Nanoを使えば、AndroidユーザーはAI機能を素早く体験することができる。 Googleは、マルチモーダリティを搭載したGemini Nanoの最新モデルを、今年後半のPixelから展開することを明らかにした。マルチモーダル搭載のナノ。これは、新しいPixel携帯がテキスト入力を扱えるだけでなく、視覚、音、話し言葉など、より多くの文脈情報を理解できるようになることを意味する。
さらにグーグルは、アンドロイドのGemini Nanoを使用して、「銀行」を名乗る人物から緊急送金やギフトカードでの支払いを求められたり、カードの暗証番号やパスワードなどの個人情報を求められたりした場合(これは良いアイデアかもしれない)など、典型的な詐欺に関連する通話中の会話を検出すると、リアルタイムのアラートを提供する。例えば、"銀行 "を名乗る人物が緊急送金やギフトカードでの支払い、カードの暗証番号やパスワードなどの個人情報(これらは一般的な銀行からの要求ではない)を要求してきた場合、警告が表示されますが、この機能はまだベータ版です。h2>
Sundar Pichai氏は、最先端のモデルのトレーニングには多くのコンピューティングパワーが必要だと述べた。MLコンピューティングに対する業界の需要は、過去6年間で100万倍に増加しました。そして毎年10倍ずつ増加している。
MLコンピューティングに対する需要の高まりに対応するため、グーグルは第6世代のTPU「Trillium」を発表した。Trilliumは、前世代のTPU「v5e」と比べて、1チップあたりの計算性能が4.7倍向上している。このレベルの性能を達成するために、Googleは行列乗算ユニット(MXU)のサイズを拡大し、クロック速度を向上させました。
さらに、Trilliumは第3世代のSparseCoreを搭載しています。これは、高度なランキングや推薦のワークロードで一般的な、非常に大きな埋め込みを処理するための特別なアクセラレーターです。
Trillium TPUはTPU v5eよりも67%以上エネルギー効率が高くなっています。
Googleは2024年末までに、Trilliumをクラウドの顧客に提供する予定であると伝えられています。
上記のモデルや製品のアップデートに加えて、Googleはセキュリティ対策も行いました。AIの悪用などの事態を想定した最新の動きを見せています。
一方では、GoogleはGeminiベースの新しいモデルファミリーを導入し、 LearnLM.のリリースで学習用に微調整しました。これは、研究に裏打ちされた学習科学と学術的原則をGoogleの製品に統合し、認知負荷を管理し、学習者の目標、ニーズ、動機に適応するのを助けるものです。

一方、知識をよりアクセスしやすく消化しやすくするために、Googleは新しい実験ツール「Illuminate」を構築しました。Illuminateは、AIが生成した2人の声の対話を数分で生成し、研究論文の重要な洞察の概要と短いディスカッションを提供することができます。
最後に、グーグルは、システムの弱点を積極的にテストし、それを破ろうとする「AI支援レッドチーム」技術を採用し、透かしツール「SynthID」をテキストと動画の2つの新しいモードに拡張することで、AIが生成したコンテンツを認識しやすくしました。
これらはGoogleのI/O 2024基調講演の主なハイライトで、豊富な製品がありますが、そのほとんどは待つ必要があります。
このカンファレンスが終わり、多くの専門家が言いたいことを言いました。NVIDIAのシニアリサーチマネージャー、ジム・ファン(Jim Fan)氏は次のように述べています:
Google I/O。 いくつかの考え:モデルはマルチモーダル入力のようだが、マルチモーダル出力ではない。すべてのモーダル入力/出力のネイティブなマージは、必然的な将来のトレンドです:
"use a more robotic voice"、"speak 2x faster"、"talk 2x faster"、"speak 2x faster"、"speak 2x faster"、"speak 2x faster"、"speak 2x faster"、"speak 2x faster"、"speak 2x faster"、"speak 2x faster"、"speak 2x faster"、"speak 2x faster"、"speak 2x faster"、"speak 2x faster"。倍速く話す」、「この画像を繰り返し編集する」、「一貫性のある漫画を生成する」。
感情や背景音など、モーダルの境界を越えて情報が失われることはありません。
新しいコンテキスト機能を提供します。少数の例で、異なる感覚を斬新な方法で組み合わせるようにモデルを教えることができます。
GPT-4oは完璧ではありませんが、フォームファクターは正しくできています。AndrejのLLM-as-OSのアナロジーを使うなら、できるだけ多くのファイル拡張子をネイティブにサポートするモデルが必要です。
Googleは正しいことをしています。プランニング、リアルタイムのブラウジング、マルチモーダル入力、すべてログインページからの操作です。グーグルの最強の堀は流通だ。Geminiは最高のモデルである必要はない。
AIの著名な研究者であるエンダ・ウーは、「I/Oでのクールな発表について、グーグルの友人たち全員におめでとうと言いたい!私は個人的に、Geminiが200万トークンの入力コンテキストウィンドウを持ち、オンデバイスAIをよりよくサポートすることを楽しみにしています。
トレントシーズンは、トレントがビットコインを追い抜き、高いリターンをもたらす短期的な現象で、2025年の主な指標はBTC.D、ETH/BTC、USDT.D、OTHERS/BTCと予測されている。
JinseFinance5月15日早朝、Google I/O開発者会議が正式に開催された。本稿は、2時間にわたる会議の内容をまとめたものである。
JinseFinanceJinseFinanceMade by Googleのイベントで、グーグルは最新の製品であるPixel 8と8 Proスマートフォンを紹介し、AIを強化したデジタルアシスタントであるAssistant with Bardを発表した。
 Catherine
CatherineMicrosoft と Google は、AI の研究開発に多額の投資を行っています。
 Beincrypto
BeincryptoBinance の製品責任者は、取引所での経験、2022 年の課題、そして今後の予定について多くのことを共有しています。
 cryptopotato
cryptopotato米国証券取引委員会(SEC)とリップルの間の法廷闘争は、昨日新たな活動を見ました。
 Bitcoinist
BitcoinistGoogle は、イーサリアム アドレスを検索すると、ウォレットの ETH 残高を表示するようになりました。
 Others
Others仮想通貨コミュニティのセンチメントはこれまでで最も低く、BTC が死にゆく資産であるという新たな憶測につながっています。
 Cointelegraph
Cointelegraph「NFT」と「代替不可能なトークン」の検索クエリは、「ドージコイン」、「ブロックチェーン」、さらには「イーサリアム」の検索よりもさらに人気があります。
Cointelegraph