マイクロソフト、OpenAI GPT-4-5、GPT-5モデルのサポートを強化
マイクロソフトは、早ければ来週にもOpenAIの最新モデルをホストする予定だと報じられている。
 JinseFinance
JinseFinance

出典:機械の心臓
マシンハート編集部
汎用AI、本当に日常的に使えるAI、このような作りではないAIが、今、恥ずかしながらカンファレンスのオープニングを飾りました。
5月15日未明、毎年恒例のGoogle I/O開発者会議が正式に開幕した。110分にわたるメイン基調講演では、人工知能について何度も言及されました。

そう、1分1秒がAIについてだったのです。
ジェネレーティブAIの競争は最近、新たな高みに達しており、当然のことながら、このI/Oカンファレンスは完全にAIが中心となっています。
1年前、このステージで私たちは初めて、ネイティブのマルチモーダル・マクロモデルであるGeminiの計画を共有しました。それはI/Oの次世代を示すものでした」と、グーグルCEOのスンダル・ピチャイは語った。「今日、私たちはすべての人にGeminiの技術の恩恵を受けてもらいたいと考えています。この画期的な機能は、検索、画像、生産性ツール、Androidなど、あらゆるものに搭載される予定です。
24時間前、OpenAIは意図的にGPT-4oのリリースを先取りし、リアルタイムの音声、ビデオ、テキストインタラクションで世界を揺るがした。
ここに、Project Astraのプロトタイプのリアルタイムショットがあります:
私たちは、可能な限り地に足の着いた方法で演じられる、ビジネス戦争の最高峰を目撃しているのです。
I/Oで、GoogleはGeminiを搭載した検索の最新バージョンを披露しました。
25年前、グーグルは検索エンジンで情報化時代の第一波を牽引した。
25年前、Googleはその検索エンジンで情報化時代の最初の波を牽引しました。現在、生成AI技術が進化するにつれて、検索エンジンはユーザーの質問によりよく答えられるようになり、コンテキストコンテンツ、位置認識、リアルタイム情報機能をより活用できるようになりました。
カスタマイズされたジェミニ・ビッグ・モデルの最新バージョンに基づき、検索エンジンに思いつくことや、やるべきことを何でも尋ねることができます。
すぐに答えが欲しいけれど、すべての情報をまとめる時間がないこともあるでしょう。そんなときこそ、AI Overviewを使えば、検索エンジンがあなたの代わりに仕事をしてくれます。AIオーバービューでは、AIが自動的に多数のウェブサイトを訪問し、複雑な質問に対する答えを提供します。
カスタマイズされたジェミニのマルチステップ推論により、AIオーバービューはますます複雑化する問題の解決を支援する。問題を複数の検索に分解する代わりに、最も複雑な質問を、思い浮かぶすべてのニュアンスや注意点とともに一度に尋ねることができるようになりました。
複雑な質問に対する正しい答えや情報を見つけるだけでなく、検索エンジンはあなたと協力して、段階を踏んで計画を立てることができます。
I/OでGoogleは、ビッグモデルのマルチモーダルおよび長文テキスト機能を強調しました。技術の進歩により、Google Workspaceのような生産性ツールはよりスマートになりました。
たとえば、Geminiに学校からの最近のメールをすべて要約してもらうことができるようになりました。バックグラウンドで関連するEメールを特定し、PDFなどの添付ファイルまで分析します。そして、キーポイントとアクションアイテムの要約を得ることができます。

出張中でプロジェクト会議に間に合わず、録画が1時間にも及ぶ場合。Google Meetでのミーティングなら、Geminiにハイライトを教えてもらうことができる。ボランティアを募集しているグループがあり、その日は空いている。geminiが応募のメールを書くのを手伝ってくれる。
さらに一歩踏み込んで、グーグルは、推論、計画、記憶能力を備えたインテリジェントなシステムとして、ビッグモデルのエージェントにさらなる可能性を見出しています。エージェントを利用するアプリケーションは、複数のステップを先読みして「考える」ことができ、ソフトウェアやシステム間で連携して、より簡単にタスクを完了できるようにします。このような考え方は、検索エンジンのような製品ではすでに明白であり、人々はAIの能力を直接見ることができます。
少なくとも家族用のバケツアプリに関しては、グーグルはOpenAIの先を行っている。
Google は生態学的に固有の優位性を持っていますが、大きなモデル基盤が重要であり、Google はこのために自社のチームと DeepMind を統合しました。今日、ハサビスはI/Oカンファレンスで初めてステージに立ち、謎の新モデルを直接紹介した。

昨年12月、グーグルは初のネイティブ・マルチモーダルモデルであるGemini 1.0を、Ultra、Pro、Nanoの3つのサイズで発表した。 そのわずか数カ月後、パフォーマンスを向上させた新バージョン1.5 Proをリリースした。
現在、グーグルは、スピードと効率を追求するグーグルの軽量モデルである新しいGemini 1.5 Flashや、グーグルの将来のビジョンであるProject Astraなど、Geminiファミリーに一連のアップデートを導入することを発表している。
この2つのモデルは、両方とも、Gemini 1.5 Flashという軽量モデルです。)
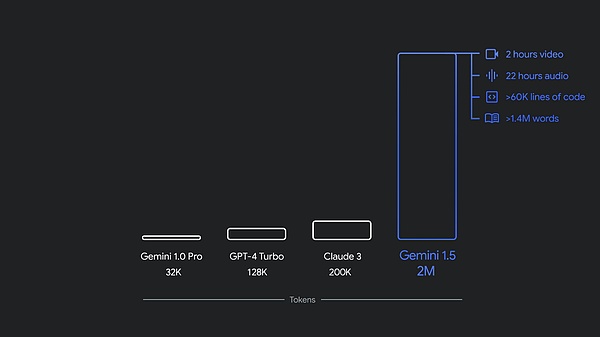
1.5 Proと1.5 Flashの両方は現在、Google AI StudioとVertex AIで100万トークンのコンテキストウィンドウでパブリックプレビューを利用できます。現在、1.5 Proは、APIを使用する開発者とGoogle Cloudの顧客向けに、200万トークンのコンテキストウィンドウでキャンセル待ちリストからも利用できます。
さらに、Gemini Nanoはテキストのみの入力から画像入力ができるように拡張されます。今年の後半、Pixelを皮切りに、GoogleはマルチモーダルなGemini Nanoを発表する。これは、携帯電話ユーザーがテキスト入力を処理できるだけでなく、視覚、音、話し言葉など、より多くの文脈情報を理解できるようになることを意味する。
新しい1.5 Flashは、スピードと効率のために最適化されています。
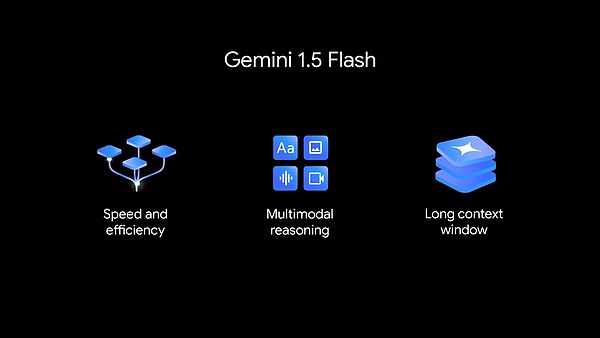
1.5 Flashは、ジェミニ・モデルファミリーの最新メンバーであり、APIの中で最も高速なジェミニ・モデルです。大規模、大量、高頻度のタスク向けに最適化されており、より費用対効果の高いサービスと、画期的に長いコンテキストウィンドウ(100万トークン)を備えています。

Gemini 1.5Flashは強力なマルチモーダル推論と画期的な長いコンテキストウィンドウを備えています。
1.5 Flashは、要約、チャットアプリケーション、画像やビデオのキャプション付け、長い文書や表からのデータ抽出などに優れています。これは、1.5 Proが、最も基本的な知識やスキルをより大きなモデルから、より小さく効率的なモデルへと移行させる、蒸留と呼ばれるプロセスを通して学習させるからです。
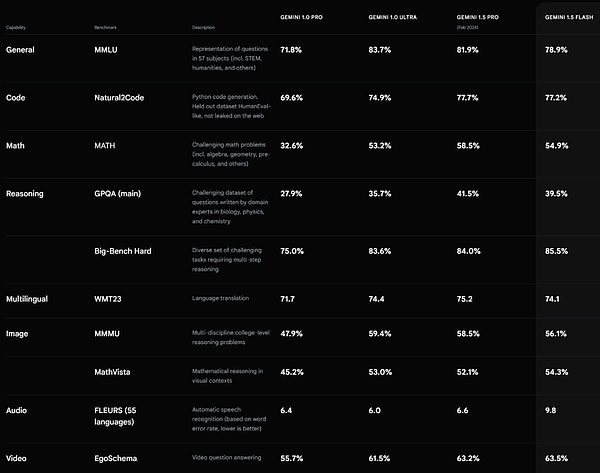
Gemini 1.5フラッシュのパフォーマンス。ソース https://deepmind.google/technologies/gemini/#introduction
Googleは、現在150万人以上の開発者がGeminiモデルを使用しており、20億人以上の製品ユーザーがGeminiを使用していると言及しています。

ここ数カ月の間にGemini 1.5 Proのコンテキストウィンドウを200万トークンに拡張したことに加え、Googleはデータとアルゴリズムの改善を通じて、コード生成、論理的推論と計画、多ラウンド会話、音声と画像の理解も強化した。

1.5 Proは、役割、書式、スタイルを含む製品レベルの動作を指定するコマンドなど、ますます複雑でニュアンスの異なるコマンドに従うことができるようになりました。さらに、Googleは、システムコマンドを設定することで、ユーザーにモデルの動作を指示する能力を与えています。
現在、GoogleはGemini APIとGoogle AI Studioに音声理解を追加しており、1.5 ProはGoogle AI Studioにアップロードされたビデオ画像や音声を推論できるようになっています。さらに、Googleは1.5 ProをGemini AdvancedおよびWorkspaceアプリを含むGoogle製品に統合した。
Gemini 1.5 Proの価格は100万トークンあたり350ドルである。
実際、Geminiで最もエキサイティングなシフトの1つはGoogle検索である。
過去1年間、グーグル検索は検索世代の経験の一部として、何十億ものクエリに答えてきた。今では、新しいタイプの質問や、より長く複雑なクエリ、さらには写真を使った検索など、まったく新しい方法で検索を行い、ウェブが提供する最高の情報を得ることができます。

GoogleはAsk Photos機能を開始しようとしています。たとえば、約9年前にスタートしたGoogleフォト。現在、ユーザーは毎日60億枚以上の写真や動画をアップロードしている。人々は写真を使って自分の生活を検索するのが大好きで、Geminiはそれをこれまで以上に簡単にします。
例えば、駐車場で車の料金を支払っているときに、ナンバープレートを思い出せなかったとしよう。以前は、写真の中のキーワードを検索し、何年もの写真をスクロールしてナンバープレートを見つけることができました。今は、写真を要求するだけでいい。

もうひとつの例は、娘のルシアの幼少期を思い出すときです。ルシアが泳げるようになったのはいつですか?ルシアの水泳の様子を教えてください。
ここで、Geminiは単純な検索を超え、プールや海などのさまざまなシーンを含む、さまざまなコンテキストを認識し、Photosはユーザーが見ることができるようにすべてを集約する。グーグルはこの夏、Ask Photos機能を開始し、さらに多くの機能を追加する予定だ。


本日、Googleはまた、オープンソースのビッグモデルGemmaの一連のアップデートをリリースしました。
リリースによると、Gemma 2は画期的なパフォーマンスと効率を実現するために設計された新しいアーキテクチャを特徴としており、新しいオープンソースモデルには27Bのパラメータがあります。

さらに、Gemmaのモデルファミリーが更新され、新しいGemma 2モデルが追加されました。p>さらに、PaliGemmaはPaLI-3にインスパイアされたGoogle初の視覚言語モデルです。
インテリジェンスは、Google DeepMindの研究の焦点となってきました。
昨日、私たちはOpenAIのGPT-4oを見て、その強力なリアルタイムの音声およびビデオインタラクション機能に圧倒されました。
今日、DeepMindのProject Astraは、視覚および音声対話のための汎用AIインテリジェンスで、Google DeepMindの将来のAIアシスタントのビジョンを垣間見るものとして発表されました。
本当に役に立つためには、インテリジェンスは人間と同じように複雑でダイナミックな現実世界を理解し、それに対応する必要があり、また文脈を理解し行動を起こすために、見聞きしたことを吸収し記憶する必要があるとGoogleは述べています。さらに、インテリジェントボディは、ユーザーが遅延や遅れなしに自然に話しかけることができるように、積極的で、教育可能で、パーソナライズされる必要があります。
過去数年にわたり、Googleはインタラクションの速度と質をより自然にするために、モデルが知覚、推論、対話する方法を改善することに取り組んできました。
本日の基調講演で、Google DeepMindはProject Astraの対話機能を実演しました。
GoogleはGeminiをベースにしたプロトタイプのインテリジェンスを開発したと説明されており、ビデオフレームを順次エンコードすることでより高速に処理し、ビデオと音声入力をイベントのタイムラインに組み合わせ、この情報をキャッシュすることで効率的に情報を処理することができます。この情報をキャッシュすることで、より速く情報を処理することができます。
音声モデリングにより、グーグルはインテリジェンスの発音も強化し、インテリジェンスに幅広いイントネーションを提供できるようにした。これらのインテリジェンスは、使用している文脈をよりよく理解し、対話で素早く応答することができます。
ここで簡単なコメントを。Machine Mindは、Project Astraプロジェクトによって公開されたデモは、GPT-4oリアルタイムデモと比べると、対話体験の点ではるかに能力が低いと感じています。返答の長さであれ、声の感情的な豊かさであれ、割り込みやすさであれ、GPT-4oのインタラクション体験の方がより自然であるように思える。読者はどう感じるだろうか?
AIが生成する動画に関して、Googleは動画生成モデル「Veo」のリリースを発表しました。
自然言語と視覚的セマンティクスを深く理解したVeoモデルは、動画コンテンツの理解、高解像度画像のレンダリング、物理シミュレーションなどにおいて新たな境地を切り開きます。
たとえば、テキストプロンプトを入力します:
水中で脈動するたくさんの斑点のあるクラゲ。
(多くの斑点クラゲが水中で脈動している。その体は透明で、深海で光っている。)
(たくさんの斑点クラゲが水中で見られる。
一人のカウボーイが馬に乗って美しい夕日が沈む平原を横切る。
(美しい夕日、柔らかい光、暖かい色の下で、一人のカウボーイが馬に乗って広い平原を横切っている。)。
Video of a close-up person, enter prompt:
薄暗いカフェに一人で座り、玄関の前で半分読み終えた小説を開いている女性。
(薄暗いカフェに一人で座る女性、彼女の前に広げられた未完の小説。フィルムノワールの美学、ミステリアスな雰囲気。モノクロ)。
特筆すべきは、Veoモデルはこれまでにないレベルの創造的なコントロールを提供し、「コマ撮り」や「空撮」といった映画用語を理解して、一貫性のあるリアルな映像に仕上げていることです。
たとえば、海岸線の映画のような空撮の場合、プロンプトを入力します:
Drone shot along the Hawaii jungle coastline, sunny day
Drone shot along the Hawaii jungle coastline, sunny day
Veo では、動画を生成するプロンプトとして、テキストとともに画像を使用することもできます。テキストのプロンプトとともに参照画像を提供することで、Veo が生成する動画は、画像のスタイルとユーザーのテキストの指示に従います。
興味深いことに、Google が投稿したデモは、Veo が生成した「アルパカ」動画でした。これは、Llama と呼ばれる Meta のオープンソース モデル シリーズを非常に彷彿とさせるものです。

ロングフォームの面では1つのプロンプトでこれを行うこともできるし、一連のプロンプトを提供することで一緒にストーリーを語ることもできる。これは、映画やテレビ制作にビデオ生成モデルを使用する際の鍵となります。
Veoは、Generative Query Network (GQN)、DVD-GAN、Imagen-Video、Phenaki、WALT、VideoPoet、Lumiereなどを含む、Googleのビジュアルコンテンツ生成作業をベースにしています。
Google は本日から、VideoFX で一部のクリエイターが Veo のプレビュー版を利用できるようにし、クリエイターは Google の待機リストに参加できるようにします。 Google はまた、YouTube Shorts などの製品に Veo の機能の一部を導入する予定です。の機能の一部を YouTube Shorts などの製品に導入する予定です。
テキストから画像への生成の面では、Google は、Imagen 3 のリリースにより、一連のモデルを再びアップグレードしました。
Imagen 3 は、ディテール、照明、干渉などを生成するモデルを最適化し、アップグレードしました。
特定のカメラアングルや構図など、より長いプロンプトからImagen 3が詳細を把握できるように、Googleはトレーニングデータの各画像のキャプションに、よりリッチな詳細を追加しました。
たとえば、入力プロンプトに「Slightly defocused in foreground」、「Warm light」などを追加します。
さらに、Googleは画像生成における「ぼやけたテキスト」の問題に対処するための改善を行いました。

使いやすさを向上させるため、Imagen 3は複数のバージョンで提供され、それぞれが異なるタイプのタスクに最適化されています。
本日より、GoogleはImageFXの一部のクリエイター向けにImagen 3をプレビュー利用できるようにしており、ユーザーはウェイティングリストに登録することができます。
ジェネレーティブAIは、人間がテクノロジーと対話する方法を変えつつあります。人間がテクノロジーと相互作用する方法を変えると同時に、ビジネスの効率化のための大きな機会を開いています。しかし、これらの進歩には、最も強力なモデルを訓練し、微調整するために、より多くの計算能力、メモリ、および通信能力が必要です。
そのため、Googleは、これまでで最もパワフルでエネルギー効率の高い第6世代のTPUであるTrilliumを発表しました。
TPU TrilliumはAI専用の高度にカスタマイズ可能なハードウェアであり、Gemini 1.5 Flash、Imagen 3、Gemma 2などの新モデルを含む、今回のGoogle I/Oカンファレンスで発表されたイノベーションの多くは、TPU上で学習され、TPUを使用して提供されます。

Trillium TPUは、TPU v5eと比較して、チップあたりのピーク演算性能が4.7倍向上し、高帯域幅メモリ(HBM)の帯域幅とチップ間相互接続(ICI)の帯域幅も2倍になると説明されています。ICI)の帯域幅を倍増させました。さらに、Trilliumは第3世代のSparseCoreを搭載しており、高度なランキングや推薦のワークロードで一般的な非常に大きな埋め込みを処理できるように設計されています。
グーグルによると、Trilliumは新世代のAIモデルをより高速にトレーニングすることができ、同時に待ち時間を短縮し、コストを削減することができるという。加えて、TrilliumはGoogleのこれまでのTPUの中で最も持続可能であり、前世代と比較してエネルギー効率が67%以上向上しているとされています。
Trilliumは、単一の高帯域幅、低レイテンシーのコンピュートクラスタ(ポッド)で、最大256 TPU(Tensor Processing Units)まで拡張できます。このクラスタレベルのスケーラビリティに加え、マルチスライステクノロジーとTitanium Intelligence Processing Units(IPU)により、Trillium TPUは数百のクラスタまで拡張でき、数千のチップを接続することで
グーグルは2013年に最初のTPU v1を発表し、2017年にはCloud TPUを発表した。これらのTPUは、リアルタイムの音声検索、写真の物体認識、言語翻訳、さらには自動運転車会社Nuroのような製品の技術など、さまざまなサービスを支えてきた。
Trilliumはまた、最先端のAIワークロードを処理するために設計された画期的なスーパーコンピューティングアーキテクチャである、グーグルのAIハイパーコンピュータの一部でもある。グーグルはハギング・フェイスと協力して、オープンソースのモデル訓練と提供のためにハードウェアを最適化している。

以上が、本日のGoogle I/Oカンファレンスのハイライトです。ご覧の通り、グーグルはビッグモデル技術と製品においてOpenAIと完全に競合しています。そして、この2日間のOpenAIとGoogleの発表により、ビッグモデル競争が新たな段階に入ったことがわかります。マルチモーダル、より自然なインタラクションが、ビッグモデル技術をより広く利用可能にし、受け入れられるようにする鍵となりました。
私たちは、ビッグモデル技術と製品革新が私たちにさらなる驚きをもたらすであろう2024年を楽しみにしています。
マイクロソフトは、早ければ来週にもOpenAIの最新モデルをホストする予定だと報じられている。
JinseFinanceグーグルがチャットボット・アリーナ・チャートのトップに立つのは今回が初めてだ。
JinseFinanceOpenAIは、GPT-4o miniの発売は、コスト削減とモデル機能の強化において大きな進展があったことを示すものであり、AIをより普及させ、信頼性の高いものにすることを約束するものであると述べている。
 WenJun
WenJunOpenAIは7月18日に「GPT-4o mini」を発表し、GPT-3.5 Turboよりも安価で効率的だとしている。OpenAIはアップルの頻繁なリリースを模倣しているのだろうか、そしてこれは彼らのジェネレーティブAIモデルの品質に影響を与えるのだろうか?
 Kikyo
KikyoOpenAIがGPT-4後継機で安全性重視の取り組みを強化。倫理的な精査と批判の中、懸念に対処し、責任あるAI開発を保証するため、安全・セキュリティ委員会が設立される。
 Huang Bo
Huang BoOpenAIのチーフサイエンティストIlya Sutskeverと "superalignment team "のJan Leikeを含む最近の辞任は、GPT-4oの立ち上げの中で安全性を優先させることについての意見の相違に続いている。OpenAIの利益へのシフトと、OpenAIの技術を統合したアップルのiOS 18アップデートのようなコラボレーションにおける潜在的なセキュリティリスクに対する懸念が残っている。
 Weatherly
WeatherlyChatGPTが登場してからまだ17ヶ月しか経っていないが、OpenAIはSF映画のようなスーパーAIを開発した。
JinseFinanceOpenAIは月曜日、ChatGPTをよりスマートで使いやすくする最新のAIビッグ言語モデルを発表した。
JinseFinance最新リリースでは、ナレッジベースを2023年4月まで拡張し、300ページのドキュメントをサポートすることで、AIのインタラクションを変革する。
 JixuJinseFinance
JixuJinseFinance