
Web3はAIの計算能力を救えるか?
Web 3.0,人工知能,算数,GTCカンファレンスを終えてWeb3はAI算数を救えるか? ゴールデン・ファイナンス,ファッションはサイクルであり、Web3もサイクルである。
 JinseFinance
JinseFinance

著者|:Frank-Zhang.eth、Twitter : @dvzhangtz
著者は、人工知能そのものが新しいタイプの生産性を表しており、人類の発展の方向性を示していると考えている。center">
著者は、人工知能そのものが新しいタイプの生産性を表し、人類の発展の方向性であると信じている。Web3とAを組み合わせることで、Web3は新しい時代の新しいタイプの生産関係となり、未来の人類社会を組織化し、AIの巨人による絶対的独占の形成を回避する救いの道となる。
元AI研究者だけでなく、第一線でWeb3一級投資の長期的な戦いとして、トラックマッピングを書くために、兄は義務であると考えています。

「A」をより完全に理解するためには、次のことを知る必要があります:
1.機械学習とは何か、なぜ我々は大規模な言語モデルを必要とするのか、などの「A」の基礎概念のいくつか。大規模な言語モデルが必要です。
2.データ取得、モデルの事前学習、モデルの微調整、モデルの使用など、AI開発のステップ。
3.外部知識ベース、連合学習、ZKML、FHEML、プロンプト学習、能力ニューロンなど、新たな方向性。
4.Aチェーン全体でWeb3に対応するプロジェクトとは。
5.AIチェーン全体について、どのリンクがより価値があるか、または大きなプロジェクトになりやすいか。
これらの概念を説明するとき、著者は数式や定義を使わず、類推を使って説明するようにする。
本記事では、できるだけ多くの新しい用語を取り上げており、読者の頭の中に印象を残し、将来その用語に出会ったときに、自分の知識構造のどこにあるのかを確認できるようにしたいと考えている。
Part 1
今日私たちがよく知っているweb3+aiプロジェクトは、人工知能の機械学習におけるニューラルネットワークのアイデアに属する技術です。
次の段落では、人工知能、機械学習、ニューラルネットワーク、トレーニング、損失関数、勾配降下、強化学習、エキスパートシステムといった基本的な概念を定義します。
第2部
人工知能
定義:人工知能とは、人間の心の能力をシミュレートし、拡張し、拡張することができる技術の研究と開発である。人工知能は、人間の知能をシミュレートし、拡張し、拡大することができる理論、方法、技術、応用システムを開発する新しい技術科学である。
私の定義:人間と同じ結果を出す機械であるため、何が真実で何が嘘かを見分けるのが難しい(チューリングテスト)
第3部
エキスパート・システム
エキスパート・システムとは何か?エキスパート・システム
明確なステップがあるものは、知識を利用する:エキスパート・システム

その4
やり方を説明するのが難しい場合:
できないならやればいい。align: left;">1.注釈付きデータを持っている:機械学習、例えばテキストのセンチメントを分析する
例:トレーニングデータが必要
キーメーカーに尋ねられた:"
隣のとても強い王さんに聞かれた。;">2.ほとんどラベルのないデータ:強化学習、例:チェス

ニューラルネットワークはどのように機械に物事を教えるのか
機械学習は現在、幅広い知識と範囲をカバーしています。機械学習の最も古典的なセットであるニューラルネットワークについて説明します。
ニューラルネットワークはどのようにして機械に物事を教えるのでしょうか?: left;">方法1:犬がマットの上でおしっこをしたら肉片をご褒美として与え、しなかったら叱る
方法2:犬がマットの上でおしっこをしたら肉片をご褒美として与え、しなかったら叱る;そして犬がマットから離れるほど強く叱る(損失関数を計算する)
方法3:犬が一歩踏み出すごとに、判定を行う:
マットに近づいたら肉片を、近づかなかったらお尻を叩く
(訓練セッションごとに、損失関数を計算する。訓練セッションごとに、損失関数が計算される)
方法4:犬が一歩踏み出すごとに、判定が行われる
マットのほうに来たら肉片をご褒美に、そうでなかったらお仕置きをする
。"text-align: left;">散歩、スパンキング;
そして、犬がマットの方へ歩くように誘うために、指し示すマットの方向に肉片を与える
(損失関数を計算する。各トレーニングセッションの損失関数を計算し、損失関数を最も小さくする方向に勾配降下を行う)

その6
なぜニューラルネットワークはこの10年で急増したのか?
過去10年間で、人間の力、データ、アルゴリズムが爆発的に増加したからです。
計算能力:ニューラルネットワークは実際に前世紀に提案されたが、当時はそれを実行するハードウェアに時間がかかりすぎた。しかし、今世紀に入ってチップ技術が発展し、コンピューター・チップの計算能力は1年半のペースで倍増している。並列計算に特化したGPUのようなチップもあり、ニューラルネットワークの計算時間は「許容範囲内」となっている。
データ:ソーシャルメディア、インターネット、そしてインターネット上に堆積している膨大な量のトレーニングデータも、大手企業の自動化ニーズに関連している。
モデル:計算能力とデータにより、研究者はより効率的で正確な様々なモデルを開発しました。
計算、データ、モデルは、人工知能の3つの要素としても知られています。
第7部
大規模言語モデル(LLM)とその重要性
なぜ重要なのか
なぜ気にしなければならないのか
なぜ気にしなければならないのか
なぜ気にしなければならないのか
なぜ気にしなければならないのか?">なぜ気にするのか:私たちが今日ここにいるのは、人々がAl+ web3に興味を持っているからです。
なぜビッグ・ランゲージ・モデルなのか:上で述べたように、機械学習には学習データが必要ですが、大規模なデータのアノテーションにはコストがかかりすぎます。strong>
バート - 最初の大きな言語モデル
もし学習データがなかったら?人間の文章はそれ自体がアノテーションの一部です。完成主義的な手法でデータを作ればいいのです。
段落の真ん中を掘り、いくつかの単語をすくい取り、変形アーキテクチャのモデル(これは重要ではない)に、その場所を埋めるべき単語を予測させることができる(そして犬にパッドを見つけさせる)。
モデルが間違った予測をした場合、何らかの損失関数を測定し、勾配降下させます(犬がマットに向かって歩いている場合は肉片で報酬を与え、そうでない場合はお尻を叩き、犬がマットに向かって歩くように誘うために、指し示すマットの方向にポーズをとるように肉片を与えます)
そうすることで、インターネット上のすべてのテキスト文章をトレーニングデータとすることができます。 私の事前学習に対する理解:事前学習によって、機械はコーパスから人間に共通することを学び、「言語感覚」を身につけることができる。 第9回 ビッグ・ランゲージ・モデルへのフォローアップ バートの提案の後、誰もがこれが機能することに気づいた! モデルを大きくし、学習データを大きくするだけで、結果はどんどん良くなる。単なる無謀な突進ではないのだ。 トレーニングデータが急増:バートはトレーニングにすべてのウィキペディアと書籍のデータを使用し、その後ウェブ全体の英語データに拡大し、さらにウェブ全体のすべての言語に拡大しました モデルのパラメータ数は急上昇した Part 1 Pre-training Data Acquisition (このステップは通常、大企業/研究機関のみが行います)事前学習には通常、膨大な量のデータが必要です。ネットワーク全体のあらゆる種類のウェブページをクロールし、テラバイト単位のデータを蓄積し、それを前処理する必要があります モデルの事前学習(このステップは通常、大企業/研究機関のみが行います) モデルの事前学習(このステップは通常、大企業/研究機関のみが行います) モデルの事前学習には通常、膨大な量のデータが必要です。このステップを行うのは大企業/研究機関だけです)データ収集を完了した後、大量のコンピューティングパワーを動員する必要があります。 Part 2 Second pre-training of the model (オプション)事前学習により、機械はコーパスから人間に共通することを学習し、「言語感覚」を身につけることができますが、特定のドメインに関する知識をモデルにもっと与えたい場合は、次のようにします。しかし、特定のドメインに関する知識をモデルにもっと与えたいのであれば、そのドメインからコーパスを取り出し、2回目のプレトレーニングのためにモデルに送り込むことができる。 例えば、Meituanはケータリングとテイクアウトのプラットフォームとして、ケータリングとテイクアウトについてより詳しい大きなモデルが必要です。このようにして得られたモデルは、関連するシーンでより良い結果を得ることができます。 二次事前訓練についての私の理解:二次事前訓練によって、モデルはあるシーンの専門家になることができる その3 モデルの微調整トレーニング (オプション)モデルの事前トレーニング感情分類、トピック抽出、読解など、あるタスクのエキスパートになりたい場合、タスクのデータを使って、微調整を行うことができます。 しかし、ここではデータに注釈を付ける必要があります。例えば、感情分類のデータが必要な場合、次のようなデータが必要です: キーカットのマスターは私に「一致しますか?「ニュートラル 隣のとても強い王さんに聞かれた:「あなたはマッチしますか」 ネガティブ 私の場合。二次的な事前トレーニングについての私の理解:微調整により、モデルは与えられたタスクのエキスパートになる モデルのトレーニングには、グラフィックカード間で転送される大量のデータが必要であることに注意する必要があります。私たちが現在Al+ web3で行っているプロジェクトの大きなカテゴリの1つは分散演算です。しかし、この種の演算で完全な分散型プリトレーニングを行うのは非常に困難です。また、分散型ファインチューントレーニングを行うには、非常に巧妙な設計が必要です。なぜなら、グラフィックスカード間で情報を転送する時間は、計算する時間よりも高くなるからです。 Part 4 モデルのトレーニングには、グラフィックカード間で多くのデータ転送が必要であることに注意してください。現在Al+web3で行っている主なプロジェクトの1つに、分散演算があります。しかし、この種の算術で完全な分散事前トレーニングを行うのは非常に困難です。分散微調整トレーニングを行うには、非常に巧妙な設計も必要です。なぜなら、グラフィックスカード間で情報を転送する時間は、計算する時間よりも高くなるからです。 第5部 モデルの使用 モデルの使用は、モデル推論としても知られています。推論。これは、学習が完了した後にモデルが一度使用されるプロセスを指します。 モデル推論は、トレーニングに比べてグラフィックカードが大量のデータを転送する必要がないため、分散推論は比較的簡単に行うことができます。left;">方法:大量のpdfデータをベクトルデータベースに詰め込み、背景情報として入力に使う 例:百度クラウド、Myshell 。Promptlearning 理由:モデルのカスタマイズニーズを満たすには、外部の知識ベースでは不十分だと感じているが、パラメータ化トレーニングでモデル全体に負担をかけたくない 方法:モデルをトレーニングせず、トレーニングデータだけを使用する。どのようなプロンプトを書くべきかを学習するために学習データだけを使う 例:今日広く使われている その2 モデルを学習するための最も一般的な方法です。 連合学習(FL) 出現の理由:学習モデルの使用において、独自のデータを提供する必要があるため、プライバシーが明らかになり、一部の金融機関や医療機関にとって受け入れがたい 出現の理由:学習モデルの使用において、独自のデータを提供する必要があるため、プライバシーが明らかになり、一部の金融機関や医療機関にとって受け入れがたい受け入れられない 方法論:各組織がローカルでデータを使ってモデルを訓練し、その後、モデルを1か所に集めてモデルフュージョンを行う 例:Flock FHEML 出現の理由:Federated Learningは各参加者がローカルでモデルを訓練することを必要とするが、各参加者にとってこれは敷居が高すぎる 方法論:FHEMLの使用は、完全なホモモルFHEMLを意味する。FHEの使用は完全な同型暗号化を意味するため、暗号化されたデータでモデルを直接訓練することができる 欠点:非常に時間がかかり、コストがかかる 事例:ZAMA、Privasea その3 ZKML その理由:他人が提供するモデリング・サービスを利用するとき、私たちは欠点:遅くて高価 事例:モジュラス スキルニューロン 理由:今日のモデルはブラックボックスのようなもので、多くの訓練データを与えるが、実際に何を学習するのかはわからない。 方法:モデルは脳のようなものだ。脳と同じで、感情を管理する神経細胞の領域もあれば、道徳を管理する領域もある。これらのノードを見つけることで、最適化を目指すことができる 事例:今後の方向性 その1 著者は次の3つに分けられます。 インフラ:分散型Aのインフラ ミドルウェア:インフラがアプリケーション層により良いサービスを提供できるようにする アプリケーション層:インフラがアプリケーション層により良いサービスを提供できるようにする アプリケーション層。">Application Layer: Cエンド/Bエンドに直接面しているいくつかのアプリケーション Part 2 Infra Layer: AIのインフラは常に、データパワー、アルゴリズム(モデル)、データ処理パワーという3つの主要なカテゴリーに分類されます。アルゴリズム(モデル) 分散型アルゴリズム(モデル): @TheBittensorHub Research:x.com/dvzhangtz/stat... 分散型算術: 汎用算術: @akashnet_, @ionet 分散データ: データ注釈:@PublciAl_,QuestLab ストレージ:IPFS, FIL オラクル: Chainlink インデックス:グラフ 第3部 ミドルウェア:どのようにすれば プライバシー:@zama fhe, @Privasea_ai 認証:EZKL, @ModulusLabs , @gizatechxyz アプリケーション層:アプリケーションをすべて分類するのは実は非常に難しく、代表的なものをいくつか挙げることしかできません データ分析 @_kaitoai,@DuneAnalytics ,Adot Agent Market: @myshell_aiVI.
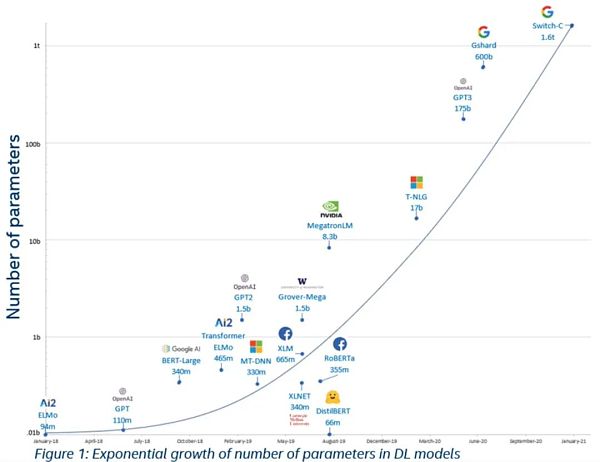
3,つのステップがある。strong>AI開発のステップ
V.Web3プロジェクトの分類に対応する連鎖
まず第一に、他の分野と同様に、インフラは大きなプロジェクトが発生しやすく、特に分散型モデル、分散型演算は限界コストが低いと感じています。
それから、@owenliang60に触発されて、アプリケーションレイヤーも、キラーアプリケーションがあれば、トッププロジェクトになると感じています。
ビッグモデルの歴史を振り返ると、閉鎖の波の先端まで押し上げたキラーアプリはChatGPTでした。おそらくA+Web3のスペースでは、将来的にStepn/Friendtechのような驚異的なアプリケーションが登場するでしょう。
Web 3.0,人工知能,算数,GTCカンファレンスを終えてWeb3はAI算数を救えるか? ゴールデン・ファイナンス,ファッションはサイクルであり、Web3もサイクルである。
JinseFinanceローンチから100日、Celestiaの創業者がアプリと開発者にもたらした変化を振り返る
JinseFinanceBTC,ETF,誕生から10年 米ビットコイン・スポットETFの承認を受けて書かれたGold Finance,ビットコインは正式に世界の金融システムに接続される。
JinseFinanceJinseFinanceJinseFinanceJinseFinance近期是高校学生提交课程论文、进行毕业论文答辩和审核的高峰期。记者调查发现,部分高校学生在悄悄利用ChatGPT等AI(人工智能)写作软件代写论文,或者用AI辅助论文写作,如罗列提纲、润色语言、降低重复率等。 AI写作软件是否会助长学术造假?该不该管?
 8btc
8btcこのアプリはZ世代を念頭に置いて設計されており、プラットフォーム外の転送の禁止など、多くの安全機能が含まれています.
 Beincrypto
Beincrypto午前中、ETH上海でのV Godのライブブロードキャストを視聴しました。いくつかの新しい洞察を皆さんと共有したいと思います。
 链向资讯
链向资讯DAO、私は今でもあなたをとても愛しています。私は残りの人生をあなたと一緒に成長することに費やすつもりです。しかし今のところ、私は自分の故郷である DAO にもっと焦点を当てるつもりです。
 Ftftx
Ftftx