OpenAIが本格的なo1モデルAPIをオープン リップル社が安定コインRLUSDを公開
ゴールデンファイナンスがお届けする朝の暗号通貨・ブロックチェーン業界ニュースレター「ゴールデンモーニング8」第2542号では、最新・最速のデジタル通貨・ブロックチェーン業界ニュースをお届けします。
 JinseFinance
JinseFinance

ソース:Heart of the Machine
ビッグ言語モデルはまだ上方修正することが可能であり、OpenAIはそれを再び証明した。
OpenAIは北京時間9月13日午前0時、困難な問題を特別に解決するために設計された一連の新しいAIビッグモデルを正式に公開した。これは大きなブレークスルーであり、新しいモデルは複雑な推論を可能にし、これまでの科学的、コード的、数学的モデルよりも難しい問題を解決する汎用モデルです。

OpenAI によると、ChatGPT と Big Models API の本日の新リリースは、このシリーズの最初のモデルで、プレビュー版のみだそうです。-o1に加えて、OpenAIは現在開発中の次のアップデートの評価も示しました。
o1モデルは、一挙に数々の歴代記録を打ち立てました。
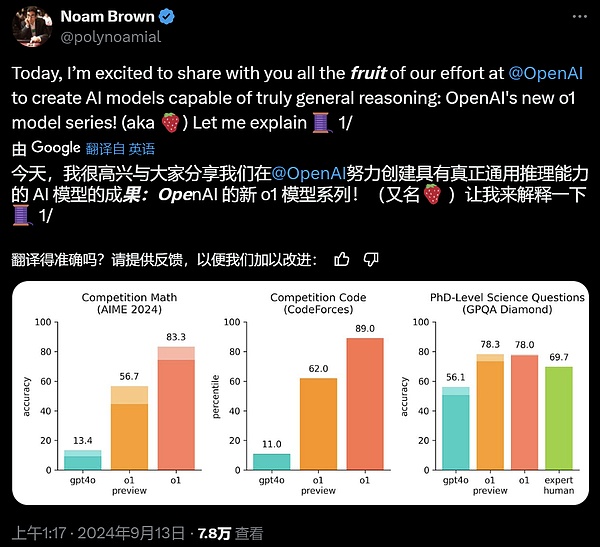
まず第一に、o1はOpenAIがサム・アルトマンから科学者に至るまで「大々的に宣伝」してきた大きなイチゴのようなモデルです。真の汎用推論機能を備えている。GPT-4oを大きく上回り、大きなモデルの上限を「読めない」から「優秀」にし、専門的な訓練なしで数学オリンピックの金賞に直行し、博士レベルの科学クイズでは人間の専門家をも凌ぐなど、一連の難しいベンチマークで非常に強いことが示されています。
Outman 氏は、o1のパフォーマンスにはまだ欠点があるものの、それでも初めて使ったときは圧倒されるだろうと述べています。
次に、o1はビッグモデルのスケールアップ対パフォーマンス曲線に上昇をもたらします。より多くの計算能力を与えれば与えるほど、より多くの知性が出力され、人間のレベルを超えるまでになります。
つまり、方法論的には、o1ビッグモデルは、言語モデルが真の強化学習にかけられることを初めて証明したのです。
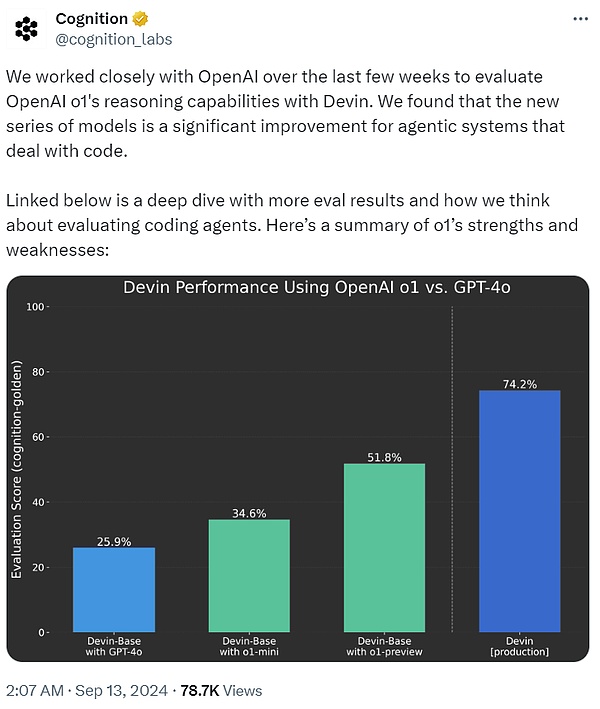
最初のAIソフトウェアエンジニアであるDevinを開発したCognition AIは、ここ数週間OpenAIと密接に協力し、Devinを使ってo1の推論能力を評価してきたという。その結果、GPT-4oに比べてその結果、o1ファミリーのモデルは、コードを処理するインテリジェント・システムにとって、GPT-4oを大きく上回るものであることがわかった。
最後に、実際には、o1がオンラインになったことで、ChatGPTは、すぐに答えを口にするのではなく、質問に答える前に考え抜くことができるようになりました。人間の脳のシステム1とシステム2のように、ChatGPTはシステム1(速い、自動的、直感的、エラーが起こりやすい)だけを使うことから、システム2(ゆっくり、じっくり、意識的、信頼できる)思考を使えるように進化しました。これにより、以前は解決できなかった問題を解決できるようになった。
今日のChatGPTのユーザーエクスペリエンスを見ると、これは小さな前進です。単純なプロンプトでは、ユーザーはあまり違いに気づかないかもしれませんが、トリッキーな数学やコードの質問をすると、違いが顕著になり始めます。もっと重要なことは、前進する道が見え始めたということです。
一言で言えば、OpenAIが今夜投下した爆弾発言は、すでに寝不足で深夜に勉強しているAIコミュニティ全体を揺るがしました。次に、OpenAIのo1ビッグモデルの技術的な詳細を見てみましょう。
技術ブログ「Learning to Reason with LLMs」で、OpenAIは言語モデルのo1ファミリーについて詳細な技術的紹介をしています。
OpenAI o1は、複雑な推論タスクを実行するために強化学習によって訓練された言語モデルの新しいクラスです。特徴的なのは、o1は回答する前に考えるということで、ユーザーに回答する前に、長い思考の内部チェーンを生成することができます。
つまり、このモデルは、人間がそうであるように、応答する前に問題について考えることに時間をかける必要がある。訓練を通じて、思考プロセスを洗練させ、さまざまな戦略を試し、間違いを認識することを学びます。
OpenAIのテストでは、物理学、化学、生物学の難易度の高いベンチマークタスクにおいて、シリーズの後続アップデートのモデルは博士課程の学生と同様のパフォーマンスを示しました。
国際数学オリンピック(IMO)の予選試験では、GPT-4oは13%の問題しか正解しなかったのに対し、o1モデルは83%の問題に正解しました。
このモデルのコーディング能力はコンペティションでも評価され、Codeforcesコンペティションでは89パーセンタイルにランクインしました。
OpenAIによると、初期のモデルであるため、情報のためにウェブをブラウズしたり、ファイルや画像をアップロードしたりといったChatGPTの便利な機能の多くはまだ持っていないとのことです。
しかし、複雑な推論タスクにとっては大きな前進であり、AI能力の新たなレベルを表しています。
ポイントは、OpenAIの大規模な強化学習アルゴリズムが、データ効率の高いトレーニングの間に、思考の連鎖を使って効率的に考える方法をモデルに教えるということです。言い換えれば、強化学習のスケーリング法則のようなものです。
OpenAI は、強化学習 (トレーニング中に計算) と思考時間 (テスト中に計算) を増やせば増やすほど、o1 のパフォーマンスが向上し続けることを発見しました。また、このアプローチのスケーリングの限界は、OpenAIも調査を続けている大規模モデルの事前トレーニングの限界とは大きく異なります。
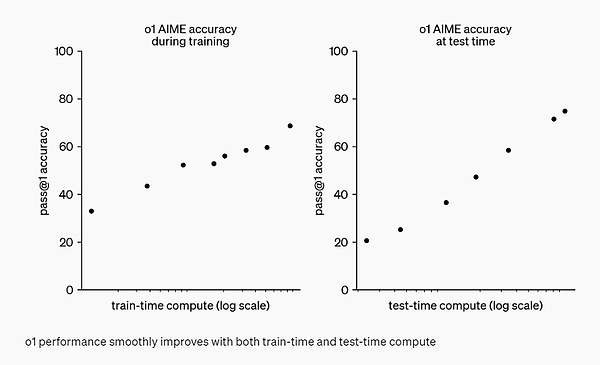
GPT-4oと比較した推論性能の向上を強調するために、OpenAIはo1を一連の異なる人間試験と機械学習ベンチマークでテストしました。および機械学習ベンチマークでo1モデルをテストしました。実験結果は、o1が大多数の推論タスクでGPT-4oを大幅に上回ることを示しています。
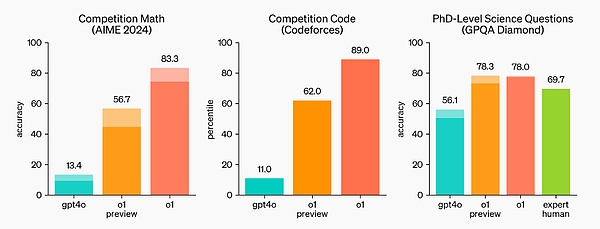
O1のパフォーマンスは、多くの推論集約型ベンチマークにおいて人間の専門家に匹敵する。最近のフロンティアモデルは、MATHとGSM8Kで非常に優れたパフォーマンスを発揮するため、これらのベンチマークはもはやモデルを区別するのに有効ではありません。その結果、OpenAIはAIMEで数学のパフォーマンスを評価しました。AIMEは、米国で最も賢い高校数学の学生をテストするために設計された試験です。公式デモでは、o1-previewが非常に難しい推論問題を解いています:王女が王子の2倍の年齢であるとき、王女は王子と同じ年齢であり、王女は2人の現在の年齢の和の半分である。王子と王女の年齢はいくつでしょう?この問題の解答をすべて示しなさい。
2024年のAIME試験では、GPT-4oは問題の平均12% (1.8/15)しか解けなかったのに対し、o1は各問題にサンプルが1つしかない場合は平均74% (11.1/15)、64のサンプル間で合意に達した場合は平均83% (12.5/15)、学習した採点関数を使用した場合は平均83% (12.5/15)だった。学習された採点関数を使用して1000サンプルを並べ替えた場合は93%(13.9/15)。13.9点であれば、全米トップ500にランクインし、米国数学オリンピックのカットオフを上回ることになります。
OpenAIは、化学、物理、生物学の専門知識をテストする難解な知能ベンチマークであるGPQA Diamondベンチマークでもo1を評価しました。モデルを人間と比較するために、OpenAIは博士号を持つ専門家を雇い、GPQA Diamondベンチマークの質問に答えさせました。
実験の結果、o1は人間の専門家を上回り、このベンチマークでそうなった最初のモデルになりました。
これらの結果は、o1がすべての点で博士よりも有能であるということを意味するわけではありません。
視覚認識を有効にした場合、o1はMMMUベンチマークで78.2%のスコアを記録し、人間の専門家に匹敵する最初のモデルとなりました。
難しい質問に答える前に長い時間をかけて考える人間のように、o1は問題を解決しようとするときに思考の連鎖を使います。強化学習を通じて、o1は思考の連鎖を磨き、使用する戦略を改善することを学びます。o1はエラーを認識して修正することを学び、厄介なステップをより単純なものに分解することができます。このプロセスは、モデルの推論を大幅に向上させる。
o1を初期化し、o1に基づいてプログラミングスキルをさらに訓練した後、OpenAIは非常に強力なプログラミングモデル(o1-ioi)を訓練しました。このモデルは2024年の国際情報学オリンピック(IOI)の問題で213点を獲得し、ランキングの上位49%に入りました。このモデルは、2024年のIOIに参加する人間の参加者と同じ条件下で競争に参加しました。
各問題について、特別に訓練されたo1モデルは多数の回答候補をサンプリングし、テスト時間の選択戦略に基づいてそのうちの50を提出します。選択基準には、IOI公開テストケースのパフォーマンス、モデルが生成したテストケース、および学習されたスコアリング関数が含まれます。
この研究は、この戦略が効果的であることを示している。というのも、回答が直接ランダムに提出された場合、平均スコアはわずか156点であり、この戦略は競争の条件下で少なくとも60点の価値があることを示唆しているからです。
OpenAIは、提出の制約が緩和されると、モデルのパフォーマンスがさらに向上することを発見しました。1問につき10,000件の投稿が許可されていた場合、テストで選ばれた戦略がなくても、モデルは362.14点、つまり金メダルを獲得していたでしょう。
最後に、OpenAIはモデルのコーディングスキルを実証するために、Codeforces主催の競技プログラミングコンテストをシミュレートしました。gPT-4oのEloスコアは808で、人間の競技者の上位11%に入りました。このモデルはGPT-4oとo1をはるかに凌駕しており、Eloスコアは1807で、競合の93%を凌駕しています。
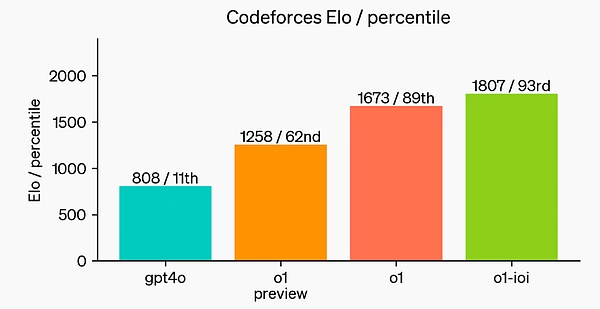
GPT-4oとo1をはるかに凌駕しています。プログラミング競技のさらなる微調整により、o1の能力がさらに向上し、2024年の国際情報オリンピック(IOI)のルールでは上位49%にランクインした。
次の公式例は、o1-previewのプログラミング能力を視覚的に示しています。
試験や学術的なベンチマークに加え、OpenAIは、o1-previewに対する人間の嗜好を評価しました。このプロンプトでは、o1-previewとGPT-4oに対する人間の嗜好が評価されました。
この評価では、人間のトレーナーが匿名でo1-previewとGPT-4oのプロンプトに回答し、好ましい回答に投票しました。O1-previewは、データ分析、プログラミング、数学といったより推論的なカテゴリではGPT-4oよりもはるかに人気がありました。しかし、O1-previewはいくつかの自然言語タスクでは人気がなく、すべてのユースケースに適しているわけではないことを示唆しています。
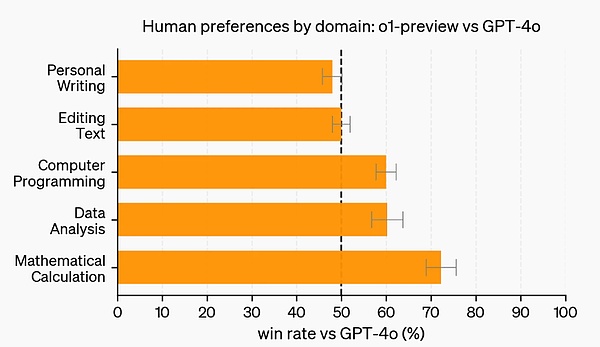
より強固な推論を必要とする分野では、o1-previewが好まれる。
Chain-of-Thought (CoT) reasoning offers new ways of thinking about security and alignment.OpenAIは、推論モデルのChain-of-Thoughtにモデルの行動ポリシーを統合することで、効率的かつ堅牢に人間の価値観や原則を教えることができることを発見しました。原則を効率的かつ堅牢に教えることができることを発見しました。o1-previewは、重要なジェイルブレイク評価や、モデルのセキュリティ拒絶境界を評価するために使用される最も厳密な内部ベンチマークにおいて、大幅な改善を達成しています。
OpenAIは、思考連鎖の使用は、1)モデルの思考を明確な方法で観察することを可能にし、2)セキュリティルールに関するモデルの推論は、配布外のシナリオに対してより堅牢であるため、セキュリティとアライメントの大幅な改善につながると主張しています。
独自の改善をストレステストするために、OpenAIは配備前に独自のセキュリティ準備フレームワークに基づいて、一連のセキュリティテストとレッドチームテストを実施しました。その結果、思考の連鎖による推論が、評価プロセス全体を通して能力を向上させるのに役立つことが判明しました。特に注目すべきは、OpenAIは報酬ハッキングの興味深い例を観察したことです。
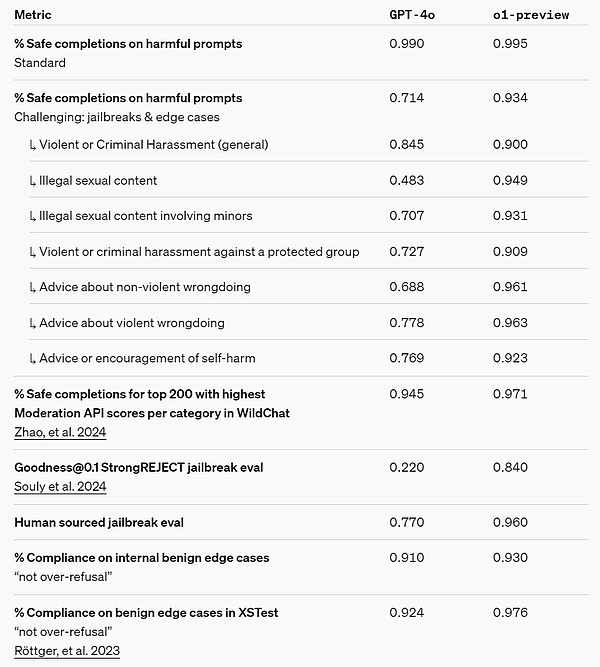
セキュリティ準備フレームワークのリンク:https://openai.com/safety/
OpenAIは、隠れた思考の連鎖がモデルを監視するユニークな機会を提供すると考えています。それが忠実で明確であると仮定すると、隠された思考連鎖はモデルの心を「読み」、その思考プロセスを理解することを可能にします。将来的には、例えば、ユーザーが操作した形跡がないか、思考連鎖を監視したいと思うかもしれません。
しかし、これが機能するためには、モデルはその思考を変更されない形で自由に表現できなければならないため、思考連鎖にポリシーの遵守やユーザーの好みを訓練することはできず、OpenAIは一貫性のない思考連鎖をユーザーに直接見せたくはありません。
そのため、ユーザーエクスペリエンス、競争上の優位性、および思考連鎖の監視を追求する選択肢など、多くの要因を考慮した結果、OpenAIはユーザーにオリジナルの思考連鎖を見せないことにしました。OpenAIはこの決定にはマイナス面があることを認識しており、そのため、思考連鎖から有用なアイデアがあれば、それを再現するようにモデルを回答で教えることで、これを部分的に補うように努めています。一方、o1モデルファミリーの場合、OpenAIはモデルによって生成された思考連鎖の要約を表示します。
o1は、AIの推論の最先端の水準を大幅に引き上げるものだと言ってよいでしょう。openAIは、反復プロセスでこのモデルの改良版をリリースする予定であり、これらの新しい推論機能が、モデルを人間の価値観や原則と統合する能力を向上させることを期待しています。openAIは、o1とその後継が、科学、プログラミング、数学、および関連分野におけるAIの新しいユースケースを解き放つと信じています。
o1は一連のモデルです。今回、OpenAIはミニ版のOpenAI o1-miniも一緒にリリースしており、同社のブログではプレビュー版とミニ版で異なる定義がされています。"開発者により効率的なソリューションを提供するために、我々はOpenAI o1-miniもリリースしています。""OpenAI o1-miniはより高速で安価な推論モデルで、特にプログラミングに優れています。"全体として、o1-miniのコストはo1-previewより80%低い。
o1のような大規模な言語モデルは、大規模なテキストデータセットで事前に訓練されているため、広範な世界知識を持っているにもかかわらず、実世界のアプリケーションではコストがかかり、時間がかかることがあります。
対照的に、o1-miniは、事前トレーニング中にSTEM推論に最適化された、より小さなモデルです。o1と同じ高負荷の強化学習(RL)パイプラインを使用してトレーニングした後、o1-miniは、多くの有用な推論タスクで同等のパフォーマンスを達成する一方で、コスト効率が大幅に向上しています。
例えば、知能と推論を必要とするベンチマークにおいて、o1-miniはo1-previewやo1と比較して良好な性能を発揮する。しかし、非STEMの事実知識を必要とするタスクでは、低いパフォーマンスとなります。
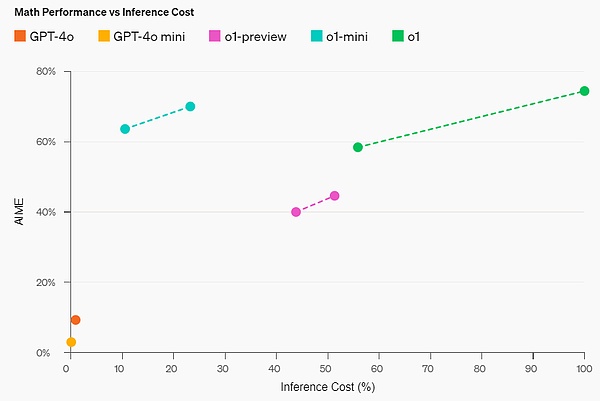
数学的能力:高校のAIME数学コンテストでは、o1-mini(70.0%)はo1(74.4%)と同等だったが、はるかに安く、o1-preview(44.6%)とo1-miniを上回った。preview(44.6%)。o1-miniのスコア(約11/15問題)は、米国で上位500人程度の高校生の中に入っています。
コーディング能力:Codeforcesの競技ウェブサイトでは、o1-miniのEloスコア1650はo1(1673)に匹敵し、o1-preview(1258)よりも高い。さらに、o1-miniはHumanEvalコーディングベンチマークとハイスクール・サイバーセキュリティ・キャプチャー・ザ・フラッグ(CTF)チャレンジでも好成績を収めました。
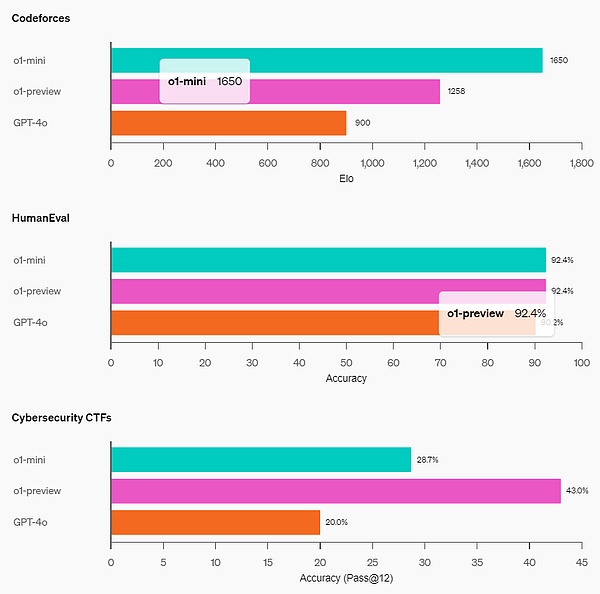
STEM: o1-miniは、GPQA(科学)やMATH-500など、推論を必要とする多くのアカデミックベンチマークでGPT-4oを上回っています。
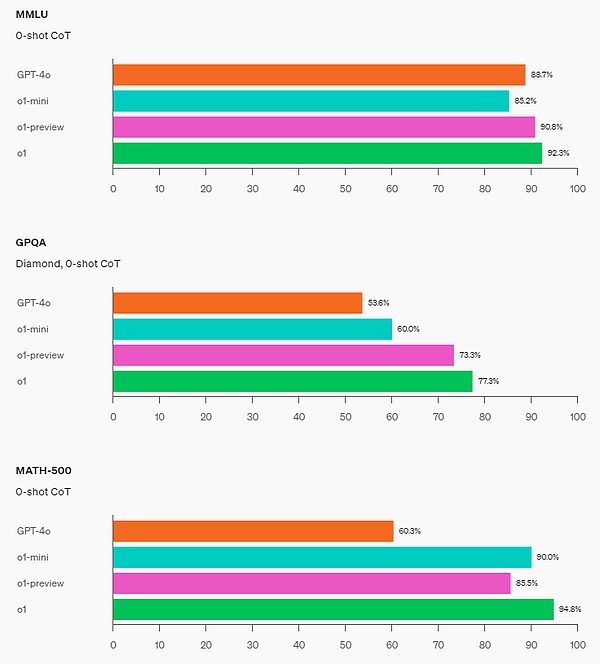
人間の好み評価:OpenAIは、人間の評価者に、ドメイン間の挑戦的なオープンエンドのプロンプトでo1-miniとGPT-4oを比較させます。o1-previewと同様に、o1-miniは推論集約的なドメインではGPT-4oよりも好まれますが、言語中心のドメインではo1-miniはGPT-4oよりも好まれません。
速度レベルでは、OpenAIはGPT-4o、o1-mini、o1-previewの一語推論の質問に対する答えを比較しました。その結果、GPT-4oは不正解でしたが、o1-miniとo1-previewはどちらも正解し、o1-miniは約3-5倍速く答えを導き出しました。

ChatGPTプラスとチーム(個人とチーム)。ユーザーは、同社のチャットボット製品であるChatGPTでo1モデルをすぐに使い始めることができます。o1-previewまたはo1-miniのいずれかを手動で選択して使用することができます。ただし、ユーザーのアクセスは制限されています。
現在、各ユーザーはo1-previewには週に30通、o1-miniには週に50通しかメッセージを送ることができません。
そう、それは小さい!しかしOpenAIは、ユーザーが利用できる回数を増やし、ChatGPTが与えられたプロンプトに使用する適切なモデルを自動的に選択するように取り組んでいるという。
Enterprise と Education のユーザーに関しては、来週までどちらのモデルも使い始めることはできません。
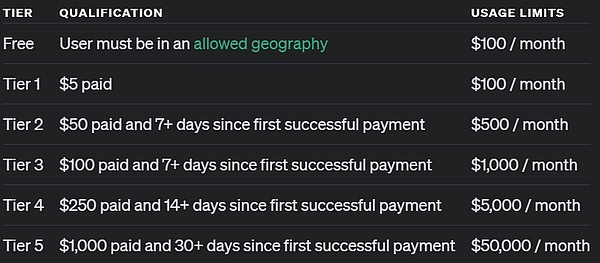
APIへのアクセスに関しては、OpenAIによると、API使用レベル5に達した開発者は、すぐにモデルを使ったアプリのプロトタイプを始めることができますが、20RPMという速度制限もあります。API利用レベル5とは何か? 簡単に言えば、1,000ドル以上を使い、1ヶ月以上有料ユーザーであることを意味する。
OpenAI によると、両モデルの API 呼び出しには、関数呼び出し、ストリーミング、システムサポートメッセージなどは含まれないそうです。繰り返しますが、OpenAIはこれらの制限を強化するために取り組んでいると述べています。
OpenAIによると、将来的にはモデルのアップデートに加えて、これらのモデルをより便利にするために、ウェブブラウジング、ファイルや画像のアップロードなどの機能を追加する予定だそうです。
"新しいo1モデルファミリーに加え、GPTモデルファミリーの開発とリリースを継続する予定です。"
参考:
https://openai.com/index/introducing-openai-o1-preview/
https://openai.com/index/openai-o1-mini-advancing-cost-efficient-reasoning/
https://openai.com/index/learning-to-reason-with-llms/
https://x.com/sama/status/1834283100639297910
ゴールデンファイナンスがお届けする朝の暗号通貨・ブロックチェーン業界ニュースレター「ゴールデンモーニング8」第2542号では、最新・最速のデジタル通貨・ブロックチェーン業界ニュースをお届けします。
JinseFinance「イリヤは本当は何を見たのか」は、2024年のAIコミュニティで最も話題になった話のひとつとなった。
JinseFinanceロードマップ全体は、「今」、「次」、「その後」の3つのセクションに分かれている。 リストアップされたプロジェクトのすべてが2025年末までに完了するわけではないが、これらのカテゴリーはo1Labsの次のフェーズの作業の焦点を明確に区分している。
JinseFinanceOpenAIは、数学やコーディングなどの分野における推論や問題解決を向上させるために設計されたo1モデルを発表した。以前のモデルより精度は高いが、コストが高く、ウェブブラウジングや画像処理のような特定の機能がまだ欠けている。
 Joy
JoyAI開発会社は、最新のモデル群がテストを通じて優れていることから、製品名の「カウンターをリセット」していると述べた。
 Cheng Yuan
Cheng YuanグーグルのGemini 1.5 Proは、ChatGPT-4oのような定評あるモデルを凌駕し、AIベンチマークの新たなリーダーとして登場した。このモデルの性能はAIコミュニティーに興奮を呼び起こしたが、将来的に利用可能になるかはまだ不透明だ。
 Dante
DanteOpenAIは、GPT-4o miniの発売は、コスト削減とモデル機能の強化において大きな進展があったことを示すものであり、AIをより普及させ、信頼性の高いものにすることを約束するものであると述べている。
 WenJun
WenJun5月15日早朝、Google I/O開発者会議が正式に開催された。本稿は、2時間にわたる会議の内容をまとめたものである。
JinseFinanceJinseFinanceO3 Labs をフォローしている場合は、O3 と呼ばれるクロスチェーンの分散型取引所 (DEX) を構築していると聞いたことがあるかもしれません ...
 Bitcoinist
Bitcoinist