



トランプ・メディア、Bakktの全株式取得で暗号帝国を構築か?
トランプ・メディアは暗号通貨会社Bakktを全株式取引で買収する方向で協議を進めていると報じられ、Bakktの株価は163%急騰した。高い評価にもかかわらず、トランプ・メディアは財務上の課題に直面しているが、競争の激しい暗号市場への拡大を目指している。
 Weatherly
Weatherly

Author: 0xjacobzhao Source: X, @0xjacobzhao
The independent research report is supported by IOSG Ventures.そして調査と執筆のプロセスは、Sam Lehman (Pantera Capital)の集中学習の研究論文に触発されたものであり、Ben Fielding (Gensyn.ai)、Gao Yuan (Gradient), Samuel Dare & Erfan Miahi (Covenant AI), Shashank Yadav (Fraction AI), Chao Wang.本論文に対する貴重な提案。本論文は客観的で正確であるように努めており、一部の見解には主観的な判断が含まれ、どうしても偏ってしまうので、読者の皆様のご理解をお願いいたします。
人工知能(AI)は、パターンフィッティングに基づく統計学習から、構造化推論を中心とした能力システムへと移行しつつある。事後訓練の重要性が急速に高まっています。DeepSeek-R1の出現は、ビッグモデルの時代における強化学習のパラダイムレベルの転換を示すものであり、事前トレーニングがモデルに共通のコンピテンシー・ベースを構築し、強化学習はもはや単なる価値調整ツールではなく、体系的に以下のことが可能であることが実証されている、ということが業界のコンセンサスとなっている。強化学習は、推論チェーンと複雑な意思決定能力の質を体系的に向上させることが実証されており、インテリジェンスを継続的に向上させるテクノロジーへと徐々に進化しています。
同時に、Web3は、分散型演算ネットワークと暗号化インセンティブを通じて、AIの生産関係を再構成しており、強化学習の構造的ニーズであるロールアウトサンプリング、報酬シグナル、検証可能なトレーニングは、ブロックチェーン演算と連動しています、強化学習が構造的に必要とするロールアウト・サンプリング、報酬シグナル、検証可能なトレーニングは、ブロックチェーンの算術連携、インセンティブ分配、検証可能な実行と自然に適合する。本稿では、AIトレーニングパラダイムと強化学習技術原理を体系的に解体し、強化学習×Web3の構造的優位性を示し、Prime Intellect、Gensyn、Nous Research、Gradient、Grail、Fraction AIなどのプロジェクトを分析する。
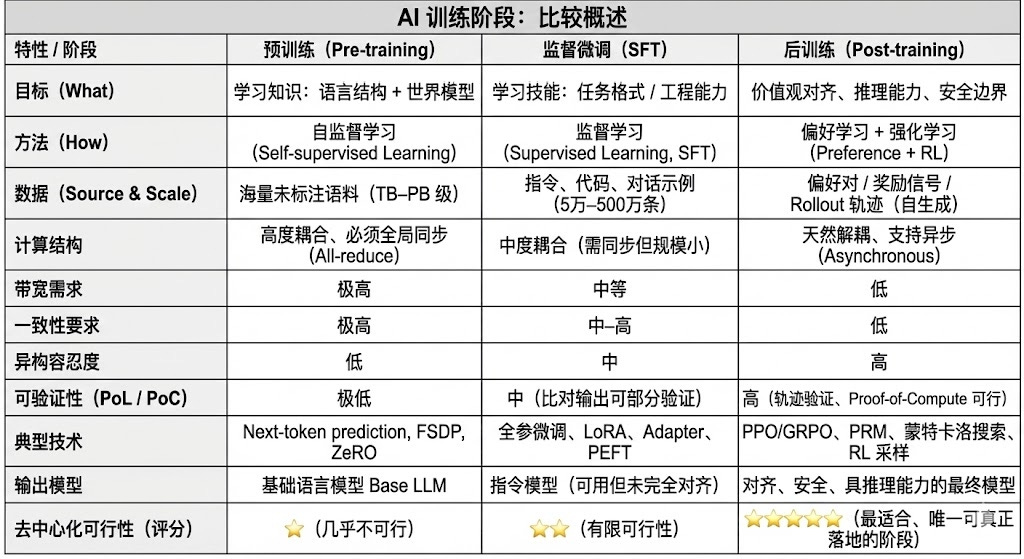
最新の大規模言語モデル(LLM)トレーニングの完全なライフサイクルは、通常、3つのコアフェーズに分割されます:事前トレーニング、教師ありの微調整、およびポストトレーニング。training/RL)である。この3つはそれぞれ「世界モデルの構築 - タスク能力の注入 - 推論と価値の形成」の機能を担い、その計算構造、データ要件、検証の難易度が分散マッチングの程度を決定する。
大規模な自己教師あり学習による事前学習。教師あり学習)により、モデルの言語の統計的構造と、LLM能力の根源であるクロスモーダル世界モデルを構築する。この段階では、何兆ものコーパスをグローバルに同期させた学習が必要で、数千から数万のH100の同型クラスタに依存し、80~95%のコストがかかり、帯域幅やデータの権利に非常に敏感であるため、高度に集中化された環境で行う必要があります。
Supervised Fine-tuningは、タスク能力と命令フォーマットを注入するために使用されます。ファインチューニングは、フルパラメータ学習か、パラメトリック効率的ファインチューニング(PEFT)手法のいずれかによって行うことができ、その中でもLoRA、Q-LoRA、Adapterが業界の主流です。しかし、同期された勾配がまだ必要であり、分散化の可能性は限られている。
ポストトレーニングは、モデルの推論能力、値、セキュリティ境界を決定する複数の反復サブステージから構成され、強化学習システム(RLHF、RLHF、RLHF、RLHF、RLHF、RLHF)の両方によってアプローチされます。(RLHF、RLAIF、GRPO)だけでなく、RLを使用しないDeleterious Preference Optimisation(DPO)やProcess Reward Models(PRM)でもアプローチされる。このフェーズはデータ量とコストが低く(5-10%)、ロールアウトとポリシーの更新に重点を置いています。非同期および分散実行を自然にサポートし、ノードは完全な重みを保持する必要がなく、検証可能な計算とオンチェーンインセンティブの組み合わせにより、オープンで分散化されたトレーニングネットワークが構築され、Web3トレーニングセッションに最も適しています。です。
強化学習(RL)は、学習への体系的なアプローチです。学習(RL)は、環境との相互作用-報酬のフィードバック-戦略の更新を通じて、モデルの意思決定能力を向上させる。完全なRLシステムは通常、ポリシー、ロールアウト、学習の3種類のコンポーネントから構成される。ストラテジーは環境と相互作用して軌道を生成し、ラーナーは報酬信号に基づいてストラテジーを更新する!xx5e!,w_1456,c_limit,f_auto,q_auto:good,fl_progressive:steep/ttps%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages% 2F5556c8b32F5556c8b3-0bc5-479e-b8f7-392f82950bbc_1376x768.png">
ポリシーネットワーク(ポリシー):環境の状態から行動を生成し、システムの意思決定の中核となる。学習中の一貫性を維持するために中央集中型のバックプロパゲーションを必要とし、推論中は異なるノードに分散して並列実行することができる。
ロールアウト:ノードはポリシーに従って環境相互作用を実行し、状態-アクション-報酬の軌道を生成する。このプロセスは並列性が高く、通信量が非常に少なく、ハードウェアの違いに影響されないため、分散化におけるスケーリングに最も適したセグメントである。
学習:すべてのロールアウト軌道を集約し、ポリシーの勾配更新を実行する。 計算能力と帯域幅の要件が最も高い唯一のモジュールであるため、収束の安定性を確保するために、通常は中央または軽度の中央集権に保たれる。収束の安定性。
強化学習は5つのステージに分けることができ、全体的なプロセスは以下の通りである。/p>

RLAIF(AIフィードバックからの強化学習)は、手作業によるアノテーションをAIジャッジまたは体質的ルールで置き換え、嗜好の獲得を自動化することで、コストを大幅に削減し、規模を拡大することを可能にします。大幅なコスト削減と規模拡大を伴う自動化は、Anthropic、OpenAI、DeepSeekなどにとって支配的なアライメント・パラダイムとなっています。
報酬モデリング段階(Reward Modeling):選好ペアは、出力を報酬にマッピングすることを学習する報酬モデルを入力します。 RMはモデルに「何が正しい答えか」を教え、PRMはモデルに「正しく推論する方法」を教えます。推論」である。
RM(報酬モデル)は、最終的な答えの良し悪しを評価するために使われ、出力に点数をつけるだけです:
報酬検証可能性フェーズ(RLVR / Reward Verifiability):報酬シグナルの生成と使用時に「検証可能性制約」を導入し、可能な限り報酬が再現可能なルールから得られるようにします、これにより、報酬のハッキングやバイアスのリスクを減らし、オープンな環境における監査可能性とスケーラビリティを向上させます。
ポリシーの最適化:これは、より合理的で、安全で、より安定した行動パターンを持つポリシーπθ′を得るために、報酬モデルによって与えられたシグナルによって導かれるポリシーパラメータθを更新するプロセスです。
PPO (Proximal Policy Optimization):RLHFの従来のオプティマイザ。
GRPO (Group Relative Policy Optimization):これはDeepSeek-R1の中核となる革新的な機能で、単純に期待値を推定するのではなく、回答候補のグループ内の優位性の分布をモデル化して期待値を推定します。を単純にランク付けするのではなく、期待値を推定します。このアプローチは、報酬の大きさの情報を保持し、推論連鎖最適化により適しており、学習プロセスにおいてより安定しており、PPO後の深い推論シナリオのための重要な強化学習最適化フレームワークとみなされている。
DPO(直接選好最適化):非強化学習の事後学習手法:軌道を生成せず、報酬をモデル化せず、選好対を直接最適化する。低コストで安定しているため、LlamaやGemmaのようなオープンソースモデルのアライメントに広く使われているが、推論を向上させるものではない。
新政策展開段階:最適化されたモデルは、より強力なSystem-2 Reasoningを示し、人間やAIのプリファレンスとより一貫した振る舞いをし、より高いレベルの推論を行います。人間やAIの嗜好と一致した行動、より低い錯覚率、より高い安全性を示す。モデルは嗜好を学習し続け、プロセスを最適化し、継続的な反復で意思決定の質を向上させ、閉ループを形成します。

強化学習は、初期の段階から発展してきました。
強化学習は、初期のゲームインテリジェンスから、産業横断的な自律的意思決定のための中核的なフレームワークへと発展してきました。その応用シナリオは、技術的な成熟度や産業実装の度合いに応じて5つのカテゴリーに分類することができ、それぞれの方向性において重要なブレークスルーを牽引してきました。
Game & Strategy (ゲーム&アンプ; 戦略):RLの方向性として最も早く検証されたもので、AlphaGoで導入された、AlphaGo、AlphaZero、AlphaStar、OpenAI Five、その他の「完全な情報+明確な報酬」環境において、RLは人間の専門家に匹敵する、あるいはそれを上回る意思決定知能を実証し、現代のRLアルゴリズムの基礎を築きました。
Robotics and Embodied AI: RLは、連続制御、ダイナミクス・モデリング、環境との相互作用を通じて、ロボットがマニピュレーション、モーション・コントロール、クロスモーダルなタスク(RT-2、RT-Xなど)を学習することを可能にします。これは急速に産業化に向かっており、地上での実世界ロボット工学のための重要な技術ルートです。
デジタル推論(LLMシステム-2):RL + PRMは、大きなモデルを言語模倣から構造化推論へと押し上げました。DeepSeek-R1、OpenAI o1/o3、Anthropic Claude、AlphaGeometryは、最終的な答えを評価するだけでなく、推論チェーンのレベルでの最適化に本質的に報酬を与えます。
自動化された科学的発見と数学的最適化:RLは、ラベルのない複雑な報酬や大規模な探索空間で、最適な構造や方針を発見します。AlphaTensor、AlphaDev、Fusion RLなどの基本的なブレークスルーを実装し、人間の直感を超えた探索を実証しています。
Economic Decision-making & Trading: RLは、戦略の最適化、高次元のリスク制御、適応的な取引システムの生成に使用されています。
経済的意思決定と取引:RLは戦略の最適化、高次元のリスク制御、適応的取引システムの生成に使用されます。
強化学習(RL)とWeb3の高い適合性は、両者が本質的に「インセンティブ駆動型システム」であるという事実に由来します。 RLは戦略を最適化するために報酬シグナルに依存し、ブロックチェーンは参加者の行動を調整するために経済的インセンティブに依存するため、両者はメカニズムレベルで自然に一致します。RLの中核要件である大規模な異種展開、報酬分配、真正性の検証は、Web3の構造的な強みである。
Decoupling inference and training: 強化学習の学習プロセスは、明示的に2つのフェーズに分けることができます:
Decoupling inference and training.align: left;">Rollout ( Explore Sampling ):計算集約的だが通信が少ないタスクで、モデルが現在のポリシーに基づいて大量のデータを生成する。ノード間の頻繁な通信を必要とせず、グローバルに分散されたコンシューマーGPUでの並列生成に適しています。
更新(パラメータ更新):収集したデータに基づいてモデルの重みを更新し、高帯域幅の集中型ノードが必要です。
「推論-トレーニングの切り離し」は、分散化された異種演算構造に自然に適合します:ロールアウトはオープンネットワークにアウトソーシングでき、トークン機構を介して貢献ごとに支払うことができますが、モデルの更新は安定性を確保するために集中化されたままです。
検証可能性:ZKとProof-of-Learningは、ノードが実際に推論を実行していることを検証する手段を提供することで、オープンネットワークにおける正直さの問題を解決します。コードや数学的推論のような決定論的タスクでは、検証者は答えをチェックするだけで作業負荷を確認することができ、分散型RLシステムの信頼性を劇的に高めることができます。
インセンティブ層、トークンエコノミーに基づくフィードバック生成メカニズム:Web3のトークンメカニズムは、RLHF/RLAIFプリファレンスフィードバック貢献者に直接報酬を与え、透明で課金可能な、許可不要のプリファレンスデータ生成のインセンティブ構造を可能にします。ステーキングとスラッシング。(ステーキング/スラッシングはフィードバックの質をさらに制限し、従来のクラウドソーシングよりも効率的で整合のとれたフィードバック市場を作り出します。
マルチインテリジェント強化学習(MARL)の可能性:ブロックチェーンは本質的に、オープンで透明性が高く、常に進化し続けるマルチインテリジェント環境であり、アカウント、契約、インテリジェンスがインセンティブ主導で常に戦略を調整しているため、大規模なMARL実験場を構築するのに適しています。大規模なMARL実験場を構築する可能性は当然ある。まだ初期ではあるが、その状態開示、検証可能な実行、プログラム可能なインセンティブは、将来のMARL開発に原則的な利点を提供する。
上記の理論的枠組みに基づいて、現在のエコシステムで最も代表的なプロジェクトを簡単に分析します。
Prime Intellectは、グローバルでオープンな算術市場を構築し、トレーニングの敷居を下げ、共同分散型トレーニングを促進し、完全なオープンソースの超知能技術スタックを開発することに取り組んでいます。そのシステムには、Prime Compute(統合クラウド/分散演算環境)、INTELLECTモデルファミリー(10B-100B+)、Open Reinforcement Learning Environments Hub、大規模合成データエンジン(SYNTHETIC-1/2)が含まれます。
Prime Intellectの中核となるインフラストラクチャーコンポーネントであるprime-rlフレームワークは、非同期分散環境向けに設計されており、強化学習に非常に関連しています。その他のフレームワークには、帯域幅のボトルネックを突破するOpenDiLoCo通信プロトコルや、計算の完全性を保証するTopLoc検証メカニズムが含まれています。
Prime Intellect Core Infrastructure Components

Technology Cornerstone: prime-rl非同期強化学習フレームワーク
prime-rl はPrime Intellectの中核となるトレーニングエンジンで、大規模な非同期分散環境向けに設計されています。prime-rlはPrime Intellectの中核となるトレーニングエンジンで、大規模な非同期分散環境向けに設計されています。ロールアウトワーカーとトレーナーはもはや同期されたりブロックされたりすることはなく、ノードはいつでも参加したり離脱したりすることができ、単に最新の戦略を取り込んで生成されたデータをアップロードし続けるだけです:
これはPrime Intellectの中核となるトレーニングエンジンです。centre">
Actors (Rollout Workers):モデルの推論とデータ生成を担当します。IntellectはvLLM推論エンジンをアクター側に革新的に統合しました。vLLMのPagedAttentionテクノロジーとContinuous Batching機能により、アクターは非常に高いスループットで推論トレースを生成できます。
Learner (Trainer): ポリシーの最適化を担当するLearnerは、非同期に共有された経験バッファからデータを取得し、すべてのアクターを待たずに勾配を更新します。すべてのアクターが現在のバッチを完了するのを待たずに、勾配を更新します。
Orchestrator: モデルの重みとデータフローのスケジューリングを担当します。
Key innovations of prime-rl:
Orchestrator: モデルの重みとデータフローのスケジューリングを担当します。: left;">真の非同期:prime-rlは、従来のPPOの同期パラダイムを放棄し、遅いノードを待たず、バッチ整列を必要とせず、任意の性能で任意の数のGPUがいつでもアクセスできるようにし、分散型RLを実現可能にしています。
FSDP2とMoEの深い統合:FSDP2パラメータスライスとMoEスパース活性化により、prime-rlは、アクティブなエキスパート上でのみアクターが実行される分散環境で、何百億ものモデルを効率的に学習することができます。これにより、メモリコストと推論コストが劇的に削減されます。
GRPO+ (Group Relative Policy Optimisation): GRPOはクリティックネットワークを不要にし、計算とメモリのオーバーヘッドを劇的に削減します。prime-rlのGRPO+は、安定化メカニズムにより、高レイテンシー条件下でも信頼性の高い収束を保証します。
INTELLECT model family: a sign of maturity for decentralised RL
INTELLECT model family: a sign of maturity for decentralised RL
INTELLECT-2(32B、2025年4月)は、GRPO+でprime-rlを多段階遅延で検証した最初のパーミッションレスRLモデルです、
INTELLECT-3 (106B MoE、2025年11月)は、12Bパラメータのみをアクティブにするスパースアーキテクチャを採用し、12Bパラメータで512×H200のRLを実現。
Prime Intellectはまた、いくつかのサポートインフラも構築しています。OpenDiLoCo は、重みの違いを定量化した時間的に疎な通信によって、場所をまたいだトレーニングトラフィックを数百分の一に削減し、InTELLECT-1を3つの異なる地域で使用できるようにしています。TopLoc + 検証者は、アクティブ化フィンガープリンティングとサンドボックス検証により、推論と報酬データの信頼性を保証する分散化された信頼された実行レイヤーを形成します。また、SYNTHETIC データ・エンジンは、高品質な推論チェーンを大規模に生成し、671BのモデルをコンシューマーGPUクラスタ上で効率的に実行するためのパイプライン並列性を実現します。これらのコンポーネントは、データ生成、検証、および分散型RLの推論スループットのための重要なエンジニアリング基盤を提供します。INTELLECTシリーズは、この技術スタックが成熟した世界クラスのモデルを生成できることを実証し、分散型トレーニングシステムの概念段階から実用段階への移行を示します。
Gensynの目標は、世界中の未使用の演算を、オープンで信頼性のない、無限にスケーラブルなAIトレーニングインフラに集約することです。インフラストラクチャーである。コアは、デバイス間で標準化された実行レイヤー、信頼性のないタスク検証システムを備えたピアツーピアのオーケストレーション・ネットワーク、スマートコントラクトによるタスクと報酬の自動割り当てで構成されている。強化学習の特徴に注目し、GensynはRL Swarm、SAPO、SkipPipeなどのメカニズムを導入し、生成、評価、更新の3段階を切り離し、グローバルなヘテロジニアスGPUを活用して集団進化のための「群れ」を形成する。最終的な成果は、単なる演算ではなく、検証可能な知性です。
強化学習アプリケーション

Proposers: 動的に生成されるタスク(数学、コード問題など)で、タスクの多様性とカリキュラム学習のような難易度適応をサポートします。
Evaluators: 凍結された「審判モデル」またはローカル報酬シグナルを生成するルールを使用して、ローカルロールアウトを評価します。評価プロセスを監査できるため、エラーの余地が少なくなります。
これら3つを合わせて、中央集権的なスケジューリングなしに大規模な共同学習を可能にするP2P RL組織を形成します。
RL SwarmとSAPOにより、Gensynは強化学習、特に学習後のRLVRが分散型アーキテクチャに自然に適していることを実証しました。--Gensynは、RLVR(特に学習後の段階)が分散型アーキテクチャに自然に適合することを実証している。RLVRは、高周波のパラメータ同期よりも、大規模で多様な探索(Rollout)に依存しているからだ。PoLとVerdeの検証システムと組み合わせることで、Gensynは何兆ものパラメトリック・モデルを訓練するための代替経路を提供します。それは、もはや1つの巨大技術に依存することなく、世界中にある何百万もの異種GPUの自己進化する超知的ネットワークです。
ヌースリサーチは、分散型の自己進化型認知インフラを構築しています。そのコア・コンポーネントであるHermes、Atropos、DisTrO、Psyche、World Simは、継続的な閉ループの知的進化システムに組織化されています。事前訓練-事後訓練-推論」という従来の直線的なプロセスとは異なり、NousはDPO、GRPO、拒絶サンプリングなどの強化学習技術を採用し、データ生成、検証、学習、推論を継続的なフィードバックループに統合し、継続的な自己改善のための閉ループAIエコシステムを構築します。
Nous研究コンポーネントの概要

モデル層:エルメスと推論能力の進化 ヌースリサーチの主要なユーザー向けモデルインターフェースであるヘルメス・ファミリーの進化は、従来のSFT/DPOアライメントから推論RLへの業界の移行経路を明確に示しています: Hermes 1-3:インストラクション・アライメントと早期エージェント能力:Hermes 1-3は低コストのインストラクション・アライメントに依存していました。エルメス1-3は、ロバストな命令アライメントのために低コストのDPOに依存し、エルメス3では、合成データとAtropos検証メカニズムの最初の導入に依存した。 Hermes 4 / DeepHermes: 思考連鎖によってSystem-2スタイルのスローシンキングを重くし、Test-Time Scalingによって数学とコードのパフォーマンスを向上させ、「...」に依存しています。拒絶サンプリング+アトロポス検証」によって、純度の高い推論データを構築します。 DeepHermesはさらに、分散が難しいPPOの代わりにGRPOを採用し、推論RLをPsyche分散GPUネットワーク上で実行できるようにし、オープンソースの推論RLのスケーラビリティの基礎を築いています。 PPOを置き換えるためにGRPOを使用したのはこれが初めてです。 Atropos:検証可能な報酬駆動型強化学習環境 AtroposはNous RLシステムの真のハブです。ハブです。ヒント、ツールの呼び出し、コードの実行、複数ラウンドのインタラクションを標準化されたRL環境にカプセル化し、出力が正しいことを直接検証することで、高価で拡張性のない人間の注釈に代わる決定論的な報酬シグナルを提供します。さらに重要なことに、分散型トレーニングネットワークであるPsycheにおいて、Atroposはノードが実際に戦略を改善していることを検証する「レフリー」として機能し、監査可能なProof-of-Learningをサポートし、分散型RLにおける報酬の信頼性の問題を根本的に解決します。 DisTrO対Psyche:分散強化学習のためのオプティマイザー層 従来のRLF(RLHFDisTrOは運動量の分離と勾配圧縮によってRLの通信コストを数桁削減し、インターネット帯域幅でトレーニングを実行できるようにします。Psycheはこのトレーニングメカニズムをオンチェーンネットワークに展開し、ノードが推論、検証、報酬評価、重み付けの更新をローカルで完了できるようにし、完全なRLクローズドループを形成します。RLシステムは、ノードが推論、検証、報酬評価、重み更新をローカルに実行できるようにする閉ループシステムである。 Nousのシステムでは、Atroposが思考の連鎖を検証し、DisTrOが訓練通信を圧縮し、PsycheがRLループを実行し、World Simが複雑な環境を提供し、Forgeが実際の推論をキャプチャし、Hermesがすべての学習を重みに書き込む。強化学習は単なるトレーニング・フェーズではなく、データ、環境、モデル、インフラストラクチャーをつなぐNousアーキテクチャーのコア・プロトコルであり、ヘルメスをオープンソースの演算ネットワーク上で継続的に改善する生きたシステムにしている。 グラディエント・ネットワークのコア・ビジョンは、オープン・インテリジェンス・スタックを通じてヘルメスを再構成することです。グラディエント・ネットワークのコア・ビジョンは、オープン・インテリジェンス・スタックを通じてAIコンピューティング・パラダイムを再構成することである。グラディエントのテクノロジー・スタックは、独立に進化し異種協働が可能なコア・プロトコルのセットで構成されています。 システムは、通信の最下層から知的協働の最上層に至る順に、Parallax(分散推論)、Echo(分散RLトレーニング)、Lattica(P2Pネットワーク)、SEDM / Massgen / Symphony / CUAHarm(メモリ、協働、セキュリティ)、VeriLLM(信頼された認証)、Mirage(Hi-Fiシミュレーション)の各プロトコルで構成されており、これらが一体となってAIコンピューティング・パラダイムの継続的な進化を構成しています。これらは共に、継続的に進化する分散型インテリジェント・インフラストラクチャを形成します。 エコー - 強化学習トレーニング・アーキテクチャ エコーはグラディエントの強化学習フレームワークです。Echoは、強化学習のトレーニング、推論、データ(報酬)の経路を切り離すように設計されており、ロールアウト生成、ポリシーの最適化、報酬の評価を、異種環境で独立してスケールし、スケジューリングすることができます。これは、推論側ノードとトレーニング側ノードのヘテロジニアスネットワークで動作し、軽量な同期メカニズムによって広域ヘテロジニアス環境におけるトレーニングの安定性を維持し、従来のDeepSpeed RLHF / VERLにおける推論-トレーニングの混合によって引き起こされるSPMDの障害やGPU利用のボトルネックを効果的に緩和します。 Echoは演算利用率を最大化するために「推論-トレーニング・デュアルクラスター・アーキテクチャー」を採用しており、デュアルクラスタは互いにブロックすることなく独立して実行されます: サンプリングスループットの最大化:推論スウォームは、コンシューマーグレードのGPUとエッジデバイスで構成され、パイプライン並列でParallaxによって構築された高スループットのサンプラーを備えています。 Maximising Gradient Arithmetic:Training Swarmは、集中型クラスタまたは世界中の複数の場所で実行可能なコンシューマグレードGPUのネットワークで構成され、勾配更新を担当します、パラメータ同期とLoRAチューニングを担当し、学習プロセスに集中します。 ポリシーとデータの一貫性を維持するために、Echoは、ポリシーの重みと軌道の双方向の一貫性管理のために、シーケンシャルと非同期の2つの軽量同期プロトコルを提供します: Sequential Pull Mode|Precision First : 学習側は、新しい軌道を引く前に推論ノードにモデルバージョンの更新を強制し、軌道の鮮度を確保します。 プッシュプルモード|効率優先:推論側がバージョンラベル付きの軌道を継続的に生成し、学習側が自分のペースでそれを消費する。
グラディエント・ネットワーク:強化学習アーキテクチャ・エコー

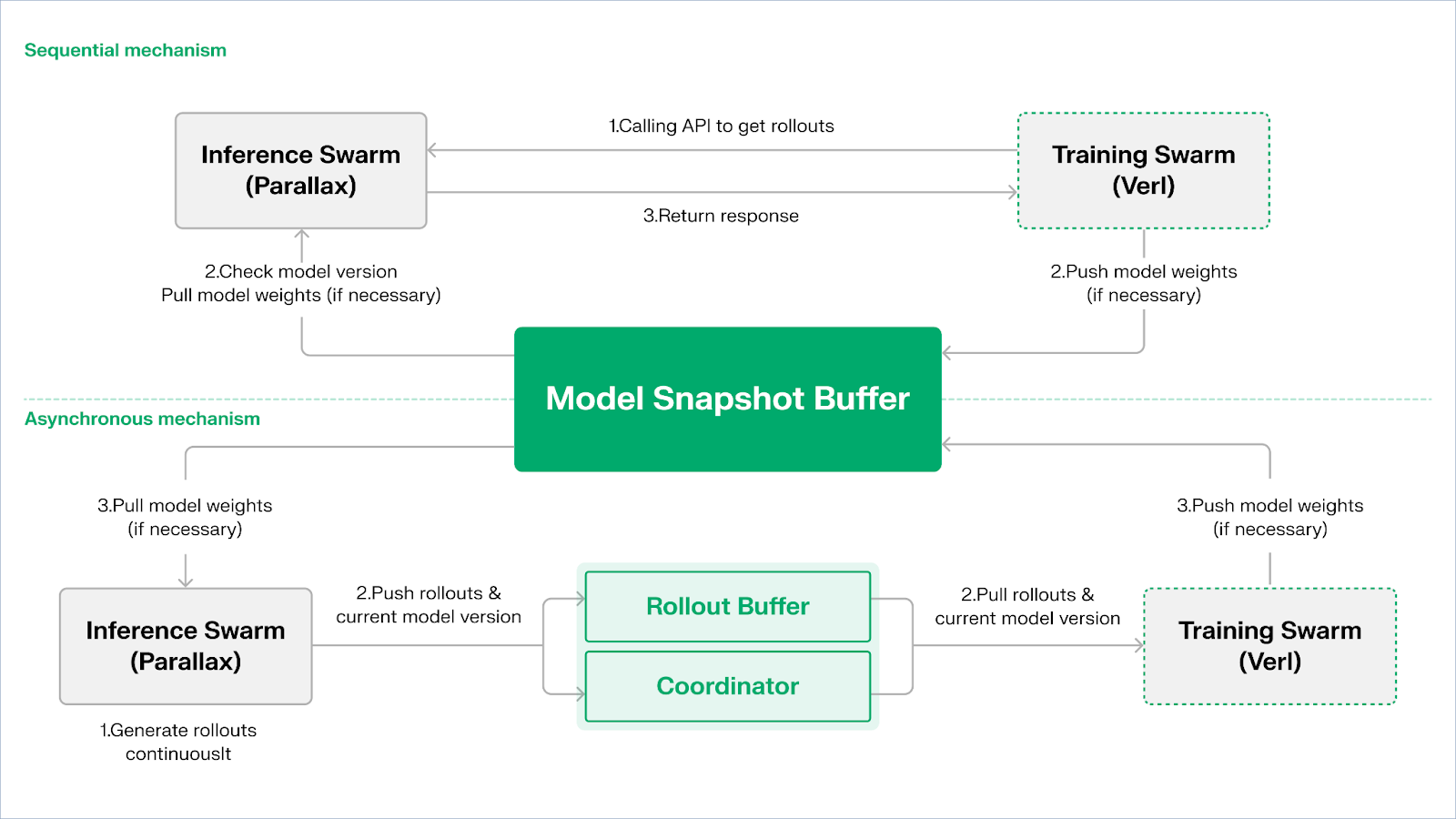
プッシュプル:推論側がバージョンラベル付きの軌跡を連続的に生成し、それを学習側が自分のペースで消費する。
Echoは、Parallax(低帯域幅環境における異種推論)と軽量分散学習コンポーネント(VERLなど)の上に構築されており、LoRAに依存してノード間の同期コストを削減し、世界中の異種ネットワーク上で強化学習を安定して実行できるようにしています。
Bittensorは、そのユニークなYumaコンセンサスメカニズムを通じて、大規模で、スパースで、非平滑な報酬関数ネットワークを構築します。関数ネットワークを構築します。
BittensorエコシステムのCovenant AIは、SN3 Templar、SN39 Basilica、SN81 Grailを使用して、事前学習からRL事後学習まで垂直統合パイプラインを構築します。SN3 Templarはベースモデルのプリトレーニングを担当し、SN39 Basilicaは分散演算マーケットプレイスを提供し、SN81 GrailはポストRLトレーニングの検証可能な推論レイヤーとして機能し、RLHF/RLAIFのコアプロセスを実行し、アライメント戦略に対するベースモデルの閉ループ最適化を完了します。

GRAILの目標は、モデルのアイデンティティにバインドされた各強化学習ロールアウトの真正性を暗号的に証明することであり、信頼が要求されない環境でもRLHFを安全に実行できるようにしています。
決定論的チャレンジ生成:ドランドランダムビーコンとブロックハッシュを使用して、予測不可能だが再現可能なチャレンジ(例:SAT、GSM8K)を生成し、事前計算の不正行為を排除する。PRFインデックスサンプルとスケッチコミットメントを使用して、検証者がトークンレベルのログプローブと推論チェーンをわずかなコストでスポットチェックできるようにし、ロールアウトが本当に宣言モデルによって生成されていることを確認する。
Model Identity Binding:モデルの重みフィンガープリントとトークン分布の構造化された署名に推論プロセスをバインドします。これは、RLにおける推論ロールアウトの信頼性の根源を提供します。
このメカニズムの上に、グレイルサブネットはGRPOスタイルの検証可能なポストトレーニングプロセスを実装しています。重みとしてチェーンに書き込む。公開実験によれば、このフレームワークはQwen2.5-1.5BのMATH精度を12.7%から47.6%に向上させ、チート防止とモデル能力の大幅な強化を実証している。Grailは、Covenant AIのトレーニングスタックにおける分散型RLVR/RLAIFの信頼と実行の礎石であり、メインネット上ではまだ正式に稼働していません。
フラクションAIのアーキテクチャは、競争からの強化学習を明確に中心としています。競争からの強化学習(RLFC)
とゲーム化されたデータ注釈により、従来のRLHFの静的な報酬と手作業による注釈を、オープンで動的な競争環境に置き換えます。エージェントは異なるスペースで互いに対戦し、その相対的な順位とAIジャッジのスコアがリアルタイムの報酬を構成し、アライメント・プロセスを継続的なオンライン・マルチインテリジェンス・ゲーム・システムへと進化させます。従来のRLHFとFraction AIのRLFCの主な違い

RLFCの中核的な価値は、報酬はもはや単一のモデルからではなく、進化する敵対者と評価者から得られるということです。RLFCの中核的な価値は、報酬がもはや単一のモデルからではなく、進化する敵対者と評価者から得られることであり、報酬モデルの搾取を回避し、戦略の多様性によって生態系が局所最適に陥るのを防ぎます。
システムアーキテクチャの観点から、Fraction AIはトレーニングプロセスを4つの主要なコンポーネントに分解します:
エージェント。strong>エージェント:オープンソースのLLMに基づく軽量なポリシーユニットで、QLoRAによる差分重みでスケーリングされ、低コストの更新が可能です。
スペース:孤立したタスクドメイン。
AIジャッジ:スケーラブルで分散化された評価を提供するためにRLAIFで構築されたインスタント報酬レイヤー
Fraction AIの本質は、人間と機械の共同進化エンジンを構築することです。ユーザーは戦略レベルでメタ最適化者として機能し、プロンプトエンジニアリングとハイパーパラメトリック構成を通じて探索の方向性を導き、エージェントはマイクロコンペティションで膨大な数の高品質なプリファレンスペアを自動的に生成します。このモデルは、トラストレス・ファインチューニングによってビジネスループを閉じるためのデータ注釈を可能にします。

上記の最先端プロジェクトの分解と分析に基づき、各チームのエントリーポイント(アルゴリズム、エンジニアリング、またはマーケティング)は異なるものの、強化学習(RL)とWeb3を組み合わせた基本的なアーキテクチャロジックは、非常に一貫性のある「デカップリング-検証」アプローチに収束していることがわかります。RLとWeb3の基本的なアーキテクチャ・ロジックは、一貫性の高い「デカップリング-検証-動機づけ」のパラダイムに収束する。これは単なる技術的な偶然ではなく、分散型ウェブが強化学習のユニークな特性に適応した必然的な結果なのです。
強化学習の一般的なアーキテクチャの特徴:核となる物理的制約と信頼の問題を解決する
Physical Separation of Rollouts & Learning - デフォルトの計算トポロジー
通信スパースで並列可能なロールアウトは、世界中のコンシューマーGPUに委託され、高帯域幅のパラメーター更新は、Prime Intellectの非同期アクターラーナーからGradient Echoのデュアルクラスターアーキテクチャまで、少数のトレーニングノードに集中されます。
検証主導の信頼 - インフラストラクチャ化
パーミッションレスネットワークでは、GensynのPoL、Prime IntellectのTOPLOC、Grailの暗号検証などの実装に代表される数学的・機械的設計によって、計算の真正性を強制する必要があります。
トークン化されたインセンティブ・ループ(Tokenised Incentive Loop)-市場の自主規制 演算能力の供給、データの生成、検証の並べ替え、報酬の分配は閉じたループを形成し、報酬を通じて参加を促し、スラッシュを通じて不正行為を抑制します。
Differentiated Technology Paths: Different "Breakthrough Points" under a Consistent Architecture
アーキテクチャの収束にもかかわらず、各プロジェクトは独自のDNAに基づいて異なる技術的な堀を選びました。
Algorithmic Breakthroughs (Nous Research):分散トレーニングの根本的な矛盾を、数学の底辺から解決しようとしています。(帯域幅のボトルネック)を解決しようとしています。そのDisTrOオプティマイザーは、勾配トラフィックを数千分の1に圧縮することを目標としており、大規模なモデル学習を家庭のブロードバンドで実行できるようにすることを目標としています。
システムエンジニアリング・スクール(Prime Intellect、Gensyn、Gradient):次世代の「AIランタイム・システム」の構築に注力するPrime IntellectのPrime IntellectのShardCastとGradientのParallaxは、既存のネットワーク条件下で、極端なエンジニアリングによって異種混合のクラスタから最大限の力を引き出すことを目的としています。
Bittensor, Fraction AI: 報酬関数の設計に注力。微妙な採点メカニズムを設計することで、採掘者が自発的に最適な戦略を見つけるように導き、知性の出現を加速させる。
Strengths, Challenges, and Endgame Perspectives
強化学習とWeb3を組み合わせたパラダイムでは、システムレベルの強みは、コスト構造とガバナンス構造の書き換えから始まります。
Cost reshaping:RLのポストトレーニングには、ロールアウトのための無限のニーズがあります。Web3は、非常に低コストで算数のグローバルロングテールを動員することができ、中央集権的なクラウドベンダーにはないコスト優位性があります。
Sovereign Alignment:AIの価値(アライメント)に関する大規模ベンダーの独占を打破し、コミュニティはトークン投票を通じてモデルの「良い答えは何か」に投票することができます。AIガバナンスを民主化する「答え」。
同時に、このシステムは2つの大きな構造的制約にも直面しています。
帯域幅の壁:DisTrOのような技術革新にもかかわらず、物理的な待ち時間によって、非常に大きなパラメーターモデル(70B以上)のフルボリューム学習には限界があり、Web3 AIは現在、微調整と推論に限られています。
Goodhart's Law (Reward Hacking):インセンティブが高いネットワークでは、採掘者が実際の知性を高める代わりに、報酬ルール(スワイプスコア)を「オーバーフィット」させることは非常に簡単です。チート防止の堅牢な報酬関数を設計することは、永遠のゲームです。
悪意のあるビザンチン・ノード攻撃(BYZANTINE worker):トレーニング信号の能動的な操作とポイズニングによって、モデルの収束を妨害する。チート防止報酬関数を継続的に設計するのではなく、敵対的なロバスト性を持つメカニズムを構築することに核心があります。
強化学習とWeb3の組み合わせは、本質的に、知性がどのように生み出され、整列され、価値を割り当てられるかを書き換えるものです。
Decentralised push-training networks:アルゴリズム・マイナーからポリシー・ネットワークへ、並列かつ検証可能なアウトソーシング。
嗜好と報酬の資産化:ラベル付けされた労働からデータの公平性へ。 >DeFi戦略の実行やコード生成など、検証可能な結果と定量化可能な利点を持つ、垂直シナリオにおける小型で強力な専用RLエージェントを育成することで、戦略の改善が価値の獲得に直結し、一般的なクローズドソースモデルを上回ることが期待されます。
全体として、強化学習×Web3の真の機会は、分散版OpenAIの複製ではなく、「インテリジェンスの生産関係」を書き換えることです:トレーニングの実行を算術のオープンな市場にし、報酬と嗜好を資産の管理可能な連鎖にし、インテリジェンスの価値を結果として生み出す必要がなくなります。そうすることで、インテリジェンスからの価値はもはやプラットフォームに集中するのではなく、トレーナー、アライナー、ユーザーの間で再分配されるようになります。
トランプ・メディアは暗号通貨会社Bakktを全株式取引で買収する方向で協議を進めていると報じられ、Bakktの株価は163%急騰した。高い評価にもかかわらず、トランプ・メディアは財務上の課題に直面しているが、競争の激しい暗号市場への拡大を目指している。
Weatherlyトルネード・キャッシュの共同創設者であるローマン・ストームの裁判が4月に延期され、検察はストームの資産の差し押さえを求めている。ストームは弁護のための資金を集めており、一方、暗号プライバシー擁護者たちは、この事件はプライバシー技術に対する攻撃だと批判している。
 Catherine
CatherineGeminiはVASP登録を確保した後、フランスでサービスを開始し、ユーザーは現地の支払い方法で70以上の暗号通貨を取引できるようになった。この動きは、有利な規制環境と今後予定されているEUのMiCA規制に支えられたフランスにおける暗号への関心の高まりに沿ったものである。
 Anais
Anaisネパールの暗号通貨禁止令は詐欺の増加につながり、犯罪者はデジタル資産を利用して資金洗浄を行い、オンライン詐欺を通じて被害者から搾取している。政府の法的規制により、被害者が詐欺を報告することが難しくなっており、この問題への取り組みがさらに複雑になっている。
Weatherlyトランプ政権移行チームは、コインベースCEOのブライアン・アームストロング氏との会談後、ベーカー・ホステトラー社のパートナーでブロックチェーンの専門家であるテレサ・グディ・ギレン氏をSEC委員長に検討している。ゲーリー・ゲンズラー氏の後任は感謝祭前に決定される見込み。
CatherineFTX事件で起訴された5人のうち、3人が服役中で、1人は刑期を終えている。11月20日に量刑が言い渡されるゲーリー・ワンは、厳しい判決を受けるのか、それとも寛大な処分を受けるのか。
 Kikyo
Kikyoドナルド・トランプやCoinbase CEOのブライアン・アームストロングのような重要人物が、暗号政策を推進するよう提唱しており、暗号業界はワシントンでも勢いを増している。Bakktの買収やSECの指導者交代の可能性など、トランプ氏の最近の動きは、米国政治における暗号の影響力拡大へのシフトを示唆している。
Anaisカトリック教会のアニメにインスパイアされたマスコットが、人気のミームコイン「Luce」の誕生に火をつけた。Bybitへの先物上場後、価格が大幅に高騰した後、わずか3週間前にローンチされたこのトークンは、暗号愛好家の間で急速に注目を集めている。
Catherine口止め料事件におけるドナルド・トランプの判決は、法的申し立てと彼の大統領職のために、何年も遅れる可能性がある。彼の弁護団は免責を主張し、マンハッタン検事は政治的な挑戦にもかかわらず有罪判決を支持すべきだと主張している。
Weatherlyマイケル・セイラー氏は、12月10日の重要な投票に先立ち、マイクロソフトの取締役会にビットコイン投資戦略を提示する予定だ。この提案は、マイクロソフトがビットコインを潜在的な投資対象として検討することを示唆するもので、マイクロストラテジーがこの資産で成功を収めていることを引き合いに出している。
Anais