ユービーアイソフト、パリ・ブロックチェーン・ウィークで魅力的なブロックチェーンゲームを発表
ユービーアイソフトは、ユニークなフィギュリンと戦略的バトルを特徴とする『チャンピオン・タクティクス グリモリア』でブロックチェーンゲームを開拓します。プレイヤーのオーナーシップと没入感のあるゲームプレイを重視するユービーアイソフトは、ゲーム業界における革新の舞台を築きます。
 Xu Lin
Xu Lin

By Geng Kai, DFG
ブロックチェーン技術の鍵となるデータは、分散型アプリケーション(dApps)開発の基礎となる。">データはブロックチェーン技術の鍵であり、分散型アプリケーション(dApps)を開発するための基盤です。現在の議論の多くはデータの可用性(DA)を中心に展開されていますが、これはすべてのネットワーク参加者が検証のために最新の取引データにアクセスできるようにすることです。
モジュール型ブロックチェーンの時代には、DAソリューションが不可欠となっています。これらのソリューションは、取引データがすべての参加者が利用できることを保証し、リアルタイムの検証を可能にし、ネットワークの整合性を維持します。しかし、DAレイヤーはデータベースというよりも広告塔のように機能する。つまり、データは無期限に保存されるわけではなく、ビルボードに貼られたポスターがやがて新しいものに入れ替わるように、時間とともに削除される。
一方、データアクセシビリティは、dAppsの開発やブロックチェーン分析の実行に不可欠な、過去のデータを取り出す機能に焦点を当てています。この側面は、正確な表現と実行を保証するために過去のデータへのアクセスを必要とするタスクにとって非常に重要です。データアクセシビリティは重要だがあまり議論されていないが、データの可用性と同じくらい重要である。どちらもブロックチェーンエコシステムにおいて異なるが補完的な役割を担っており、包括的なデータ管理アプローチは、堅牢で効率的なブロックチェーンアプリケーションをサポートするために両方に対処しなければならない。
ブロックチェーンはその誕生以来、インフラに革命をもたらし、ゲーム、金融、ソーシャルネットワーキングなど多様な分野で分散型アプリケーションの成長を牽引してきました。ブロックチェーンが誕生して以来、ブロックチェーンはインフラに革命をもたらし、ゲーム、金融、ソーシャルネットワークなどさまざまな分野で分散型アプリケーション(dApps)の成長を牽引してきた。しかし、こうしたdAppsを構築するには、大量のブロックチェーン・データにアクセスする必要があり、これは困難であると同時に高価でもある。
dApp開発者にとっての1つの選択肢は、独自のアーカイブRPCノードをホストして実行することです。これらのノードは、最初からすべての過去のブロックチェーンデータを保存し、データへの完全なアクセスを可能にします。しかし、アーカイブノードは維持費が高く、クエリ機能も限られているため、開発者が必要とする形式でデータをクエリすることは不可能です。より安価なノードを稼働させるという選択肢もありますが、これらのノードはデータ検索機能が限られているため、dAppの運用に支障をきたす可能性があります。
もう1つのアプローチは、商用のRPC(リモートプロシージャコール)ノードプロバイダーを使用することです。これらのプロバイダーは、ノードのコストと管理を行い、RPCエンドポイントを通じてデータを利用できるようにします。パブリックRPCエンドポイントは無料ですが、レートが制限されており、dAppのユーザーエクスペリエンスに悪影響を与える可能性があります。プライベートRPCエンドポイントは輻輳を軽減することでパフォーマンスを向上させますが、単純なデータ検索であっても多くの往復通信を必要とします。そのため、複雑なデータクエリではリクエストが多くなり、効率が悪くなります。さらに、プライベート RPC エンドポイントは、しばしば拡張が難しく、異なるネットワーク間での互換性に欠けます。
ブロックチェーンインデクサーは、オンチェーンデータを整理し、簡単にクエリできるようにデータベースに送信するという重要な役割を果たします。このため、しばしば「ブロックチェーンのグーグル」と呼ばれる。ブロックチェーンデータをインデックス化し、SQLライクなクエリ言語(GraphQLなどのAPIを使用)を通じて容易に利用できるようにすることで機能する。データをクエリするための統一されたインターフェースを提供することで、インデクサは、開発者が標準化されたクエリ言語を使用して必要な情報を迅速かつ正確に取得できるようにし、プロセスを大幅に簡素化します。
さまざまなタイプのインデクサーは、さまざまな方法でデータ検索を最適化します:
完全なノードインデクサー:完全なブロックチェーンノードを実行し、そこから直接データを抽出することで、完全で正確なデータを確保しますが、かなりのストレージと処理能力を必要とします。
軽量インデクサー:これらのインデクサーは、必要に応じて特定のデータをフェッチするために完全なノードに依存し、ストレージ要件を削減しますが、クエリ時間が増加する可能性があります。
特化型インデクサー:これらのインデクサーは、特定のタイプのデータまたは特定のブロックチェーンに特化しており、NFTデータやDeFiトランザクションなど、特定のユースケースにおける検索のために最適化することができます。
集約インデクサー:これらのインデクサーは、オフチェーン情報を含む複数のブロックチェーンやソースからデータを引き出し、統一されたクエリインターフェースを提供します。
イーサだけでも3TBのストレージが必要で、ブロックチェーンが成長し続けるにつれて、Erigonアーカイブノードに保存されるデータ量も増えています。インデクサー・プロトコルは複数のインデクサーを配置し、RPCでは不可能な高速で大量のデータに効率的にインデックスを付け、クエリを実行します。
インデクサはまた、複雑なクエリ、異なる基準に基づくデータの容易なフィルタリング、およびデータの抽出後の分析を可能にします。複数のノードに分散されることで、RPCプロバイダーが中央集権的な性質のために中断やダウンタイムに見舞われる可能性があるのに対し、インデクサーはセキュリティとパフォーマンスを強化します。
全体として、インデクサはデータ検索の効率と信頼性を向上させる一方で、RPCノードプロバイダーと比較して個々のノードの展開コストを削減します。このため、ブロックチェーン・インデクサー・プロトコルはdApp開発者にとって好ましい選択肢となっています。
前述したように、dAppを構築するには、そのサービスを実行するためにブロックチェーンのデータを取得し、読み取る必要があります。これには、DeFi、NFTプラットフォーム、ゲーム、さらにはソーシャルネットワークを含むあらゆるタイプのdAppが含まれ、他のトランザクションを実行する前にデータを読み取る必要があります。
DeFiプロトコルは、ユーザーに特定の価格、レート、手数料などを提示するために、さまざまな情報を必要とします。自動マーケットメイカー(AMM)はスワップ金利を計算するために特定の資金プールに関する価格と流動性情報を必要とし、貸出プロトコルは借入金利と清算のための負債比率を決定するために利用率を必要とする。ユーザーによって実行されるレートを計算する前に、dAppに情報を入力することが不可欠です。
GameFiは、ユーザーがスムーズにゲームをプレイできるように、インデックスを作成し、素早くデータにアクセスする必要があります。Web3 ゲームが Web2 ゲームに匹敵するパフォーマンスを発揮し、より多くのユーザーを惹きつけるには、高速なデータ検索と実行が不可欠です。これらのゲームでは、土地の所有権、ゲーム内トークンの残高、ゲーム内のアクションなどのデータが必要です。インデクサを使用することで、データの安定したフローと安定したアップタイムを確保し、完璧なゲーム体験を保証することができます。
NFTマーケットプレイスおよび貸出プラットフォームは、NFTメタデータ、所有権および譲渡データ、ロイヤリティ情報などのさまざまな情報にアクセスするために、インデクサデータを必要とします。などです。このデータを迅速にインデックス化することで、所有権やNFTのプロパティデータを見つけるために各NFTを調べる必要がなくなります。
価格と流動性情報を必要とするDeFi自動マーケットメーカー(AMM)であろうと、新しいユーザーからの投稿を更新する必要があるSocialFiアプリであろうと、データを迅速に取得できることは、dAppが適切に機能するために不可欠です。Indexerを使えば、効率的かつ正確にデータを取得し、スムーズなユーザー体験を提供することができます。
インデクサは、各ブロックのスマートコントラクトイベントを含む生のブロックチェーンデータから特定のデータを抽出する方法を提供します。これは、包括的な洞察を提供するためのより具体的なデータ分析の機会を提供します。
例えば、永久取引プロトコルは、どのトークンが大量に取引されているか、どのトークンに手数料が発生しているかを知ることができ、その結果、それらのトークンを永久契約として自社のプラットフォームに掲載するかどうかを決めることができます。DEXの開発者は、自社の商品のためにダッシュボードを作成することができ、どの資金プールの収益率が最も高いか、または最も流動性が高いかを知ることができる。公開ダッシュボードも作成できるため、開発者はチャートに表示したいあらゆる種類のデータをクエリする自由と柔軟性を得ることができます。
複数のブロックチェーンインデクサーを利用できるため、開発者が自分のニーズに最も適したインデクサーを選択できるようにするには、インデクシングプロトコル間の違いを認識することが重要です。
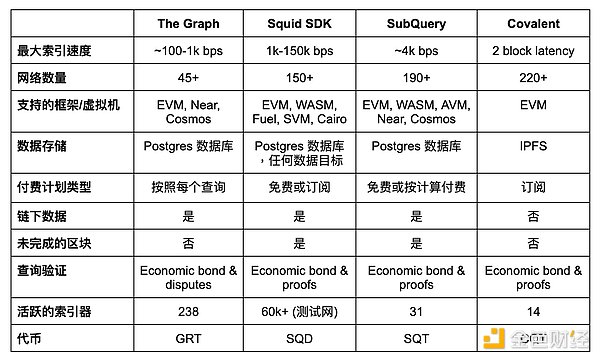
グラフはイーサ上で初めて登場したインデクサ・プロトコルであり、以前はアクセスできなかったトランザクション・データへのクエリーを容易にします。これは、Uniswap v3 USDC/ETHプールに関連するすべてのトランザクションなど、ブロックチェーンから収集されたデータのサブセットを定義し、フィルタリングするためにサブグラフを使用します。
プルーフ・オブ・インデクシング(Proof of Indexing)を使用して、インデクサはインデクシングとクエリーサービスのためにネイティブトークンGRTを誓約し、プリンシパルはそのトークンを誓約することを選択できます。キュレーターは高品質なサブグラフにアクセスすることができ、インデクサがどのサブグラフのデータをまとめれば最高のクエリ料金を得られるかを判断するのに役立つ。より大きな分散化への移行において、The Graphは最終的にホスティングサービスを中止し、サブグラフをネットワークにアップグレードすることを要求し、またインデクサにアップグレードを提供する。
そのインフラは、100万クエリーあたり平均40ドルというコストを可能にしており、これはセルフホスティングのノードのコストよりもはるかに低い。また、ファイル・データ・ソースを使用することで、効率的なデータ検索のために、オンチェーンデータとオフチェーンデータの並列インデックス作成をサポートしています。
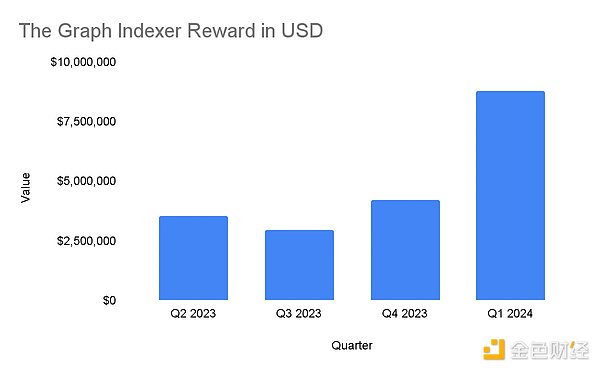
過去数四半期に渡って着実に伸びているThe Graphのインデクサーの報酬を見てみましょう。これはクエリの増加によるところもあるが、将来的にAI支援クエリを統合する予定であるため、トークン価格の上昇にも起因している。
Subsquidはピアツーピアで水平方向にスケーラブルな分散型データレイクです。ゼロ知識証明によって保護されています。ワーカーの分散型ネットワークとして、各ノードはブロックの特定のサブセットからのデータの保存を担当し、必要なデータを保持するノードを迅速に特定することで、データ検索プロセスを高速化します。
Subsquidはリアルタイムのインデックス作成もサポートしており、ブロックが確定する前にインデックスを作成することができます。また、BigQuery、Parquet、CSVなどのツールを使った分析を容易にするため、開発者が選択したフォーマットでのデータ保存もサポートしている。さらに、サブグラフはSquid SDKに移行することなく、Subsquidネットワークにデプロイすることができ、コードフリーのデプロイが可能になります。
まだベータ版ではありますが、Subsquidはすでに80,000人以上のベータ版ユーザー、60,000人以上のSquidインデクサーのデプロイ、20,000人以上のネットワーク上の検証された開発者という素晴らしい統計を達成しています。の開発者がネットワークに参加しています。最近では、6月3日にSubsquidはデータレイクのメインネットワークを立ち上げました。
インデックス作成に加えて、Subsquid Networkデータレイクは、アナリティクス、ZK/TEEコプロセッサ、AIエージェント、OracleなどのユースケースでRPCを置き換えることができます
SubQueryは、RPCとインデックス付きデータサービスを提供する分散型ミドルウェア・インフラストラクチャ・ネットワークです。当初はPolkadotとSubstrateのネットワークをサポートしていたが、現在は200以上のチェーンを含むまでに拡大している。Proof of Indexingを利用したThe Graphと同様の仕組みで、インデクサがデータのインデックスを作成し、クエリーリクエストを提供する。しかし、管理者ではなく、インデクサーの収入が保証されていることを示すために、消費者が購入注文を提出することを導入している。
シャーディングが可能なSubQueryデータノードを導入し、各ノード間で常に新しいデータが同期されるのを防ぐことで、クエリの効率を最適化しつつ、より分散化を進める。ユーザーは、1000リクエストにつき~1SQTトークンの計算手数料を支払うか、プロトコルを介してインデクサにカスタム手数料を設定するかを選択できる。
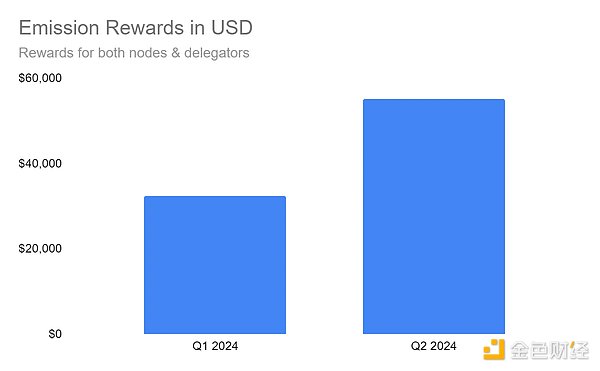
SubQueryは今年初めにトークンをローンチしたばかりにもかかわらず、ノードとプリンシパルの発行報酬もドル建てで鳴り響き、これは同社のプラットフォームで提供されるクエリーサービスの数が増えていることを表しています。TGE以来、誓約されたSQTの総額は600万から1億2500万に増加し、そのネットワークへの参加が増加していることを強調しています。
コバレントはインデクサーの分散型ネットワークであり、ブロック・サンプル・プロデューサー(BSP)ネットワーク・ノードは以下のようなものです。バッチエクスポートによってブロックチェーンデータのコピーを作成し、Covalent L1ブロックチェーン上に証明を公開する。このデータはその後、ブロックリザルトプロデューサー(BRP)ノードによって、設定されたルールに基づいて精製され、要件を満たすデータがフィルタリングされる。
統一されたAPIにより、開発者はデータにアクセスするためにカスタムの複雑なクエリを記述することなく、一貫したリクエストとレスポンス形式で関連するブロックチェーンデータを簡単に抽出することができます。これらの事前設定されたデータセットは、支払い手段としてMoonbeam上で決済されたCQTトークンを使用して、ネットワークオペレータから抽出することができます。
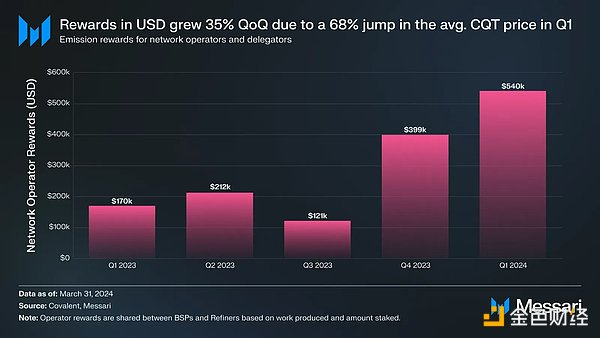
Covalentの報酬は、CovalentトークンであるCQTの価格が上昇したこともあり、1Q23から1Q24にかけて概ね上昇傾向にあるようだ。
いくつかのインデクサは、そのインデクサを選択する際の考慮事項です。align: left;">一部のインデクサ(Covalentなど)は、APIを通じて標準的な設定済みデータセットのみを提供する汎用インデクサである。それらは高速かもしれないが、データセットをカスタマイズする必要のある開発者には柔軟性を提供しない。インデクサ・フレームワークを使用することで、アプリケーション固有のニーズを満たすために、よりカスタムなデータ処理が可能になります。
インデックスされたデータは安全でなければなりません。例えば、取引やウォレットの残高が操作されれば、dAppは流動性を失い、ユーザーに影響を与える可能性がある。すべてのインデクサがインデクサ誓約トークンを通じて何らかの形のセキュリティを採用している一方で、他のインデクサ・ソリューションは、セキュリティをさらに向上させるためにプルーフを使用することがある。
Subsquidは楽観的証明とゼロ知識証明を使用するオプションを提供しており、Covalentはブロックハッシュを含む証明もリリースしています。各ブロックは、そのデータベースに格納されているすべてのデータの各ブロックのハッシュ値を計算するために、Merkle Mountain証明を生成します。
ブロックチェーンが成長し続けるにつれて、トランザクションの量も増加します。より多くの処理能力とストレージスペースが必要になるためだ。ブロックチェーン・ネットワークが成長するにつれて、効率を維持することが難しくなりますが、インデクサ・プロトコルは、こうした需要の増大に対応するソリューションを導入しています。
例えば、Subsquidはデータを保存するノードを追加することで水平方向にスケールし、ハードウェアの向上に応じて拡張できるようになります。を導入している。
ブロックチェーンの活動の大部分はまだイーサ内で行われていますが、異なるブロックチェーンは時間の経過とともに人気が高まっています。例えば、レイヤー2、ソラナ、ムーブ・ブロックチェーン、ビットコイン・エコシステム・チェーンはすべて、独自の開発者や活動が増えており、インデックス作成サービスも必要とされています。
他のインデクサプロトコルではサポートされていない特定のチェーンをサポートすることは、より多くの市場シェア手数料につながる可能性があります。Solanaのようなデータ集約型ネットワークのインデックス作成は容易ではなく、今のところSubsquidだけがインデックス作成サポートに成功しています。
dApp開発におけるインデクサーの広範な採用にもかかわらず、インデクサーの可能性は、特にAIの統合によって、まだ巨大です。AIがWeb2やWeb3で普及し続ける中、その能力を向上させるには、モデルを訓練しAIエージェントを開発するための関連データへのアクセスにかかっています。データの整合性を確保することは、モデルに偏った情報や不正確な情報が与えられるのを防ぐため、AIアプリケーションにとって非常に重要です。
インデクサソリューションの領域において、Subsquidはパフォーマンスとユーザー測定基準において大きな進歩を遂げました。ユーザーは、Subsquid を使用して AI エージェントを構築する実験を開始し、データインデックスの進化する分野におけるプラットフォームの汎用性と可能性を実証しています。さらに、AutoAgoraのようなツールは、インデックス作成者がAIを使用してThe Graph上のクエリサービスに動的な価格設定を提供するのを支援し、SubQueryはOriginTrailやOraichainのような複数のAIネットワークをサポートして透過的なデータインデックスを作成します。
AIとインデクサーの統合は、ブロックチェーンエコシステムにおけるデータアクセシビリティとユーザビリティを高めることが期待されます。AI技術を活用することで、インデクサはより効率的で正確なデータ検索を提供できるようになり、開発者はより洗練されたdAppsや分析ツールを構築できるようになる。AIとインデクサが共に進化し続ける中、私たちはデータインデクシングの将来と、分散型デジタルランドスケープを形成する上での役割について楽観的な見方を続けています。
ユービーアイソフトは、ユニークなフィギュリンと戦略的バトルを特徴とする『チャンピオン・タクティクス グリモリア』でブロックチェーンゲームを開拓します。プレイヤーのオーナーシップと没入感のあるゲームプレイを重視するユービーアイソフトは、ゲーム業界における革新の舞台を築きます。
Xu LinInscriptionsとOrdinalのプロトコルが導入される前は、ビットコインはそのスクリプト言語のチューリング不完全性により、応用範囲が限られていた。
 JinseFinance
JinseFinance本稿では、Rollupの目標を共有しながらも、その実装において大きく異なる、Web3インフラの設計パラダイムであるStorage Consensus Paradigm(SCP)を紹介する。
JinseFinance2024年が始まったばかりなのに、2023年に大成功を収めたBRC20がフォークしようとしている?一体何が起こっているのか?
JinseFinanceJinseFinance第11回ブロックチェーン・ライフ・フォーラムは2023年10月25日にドバイで開催され、120カ国から7000人以上の参加者を集めて閉幕した。
 Olive
Oliveブロックチェーン創世記、タイ・ブロックチェーン・ウィーク2023、"Build in Bear, Rise in Bull "のコンセプトで6年目を迎える。
Oliveブロックチェーン技術は、デジタル関係を促進するための信頼できる当事者の必要性を排除し、暗号通貨のバックボーンです.
 Coindesk
Coindeskブロックチェーンは、コミットメントを行うことができるコンピューターです。 [https://cdixon.org/2020/01/26/computers-that-can-make-commitments](https://cdixon.org/2020/01/26/computers-that-can-make-commitments) このプロパティのパフォーマンス オーバーヘッドが発生します。
 Cdixon
CdixonWeb3 ベースの歴史的保存組織である Blockchain Relics は、その Web サイトと強力なコミュニティ キャンペーンを ...
 Bitcoinist
Bitcoinist