Is the altcoin market coming? Four indicators to judge
Alt season is a short-term phenomenon in which altcoins surpass Bitcoin and bring high returns. Its key indicators are predicted to be BTC.D, ETH/BTC, USDT.D and OTHERS/BTC in 2025.
 JinseFinance
JinseFinance

Author: Tu Min, CSDN
This May is like a dream back to March 2023, with a series of lively AI feasts.
However, whether intentionally or unintentionally, in March last year, when Google chose to open the PaLM API for large language models, OpenAI released its most powerful model GPT-4 at almost the same time, which amazed everyone. In addition, just a few days later, Microsoft announced at a press conference that its entire Office family bucket was innovated by GPT-4, causing Google to seem to be ignored by everyone.
Somewhat embarrassingly, the same situation seems to be happening this year. On the one hand, OpenAI brought the fully upgraded flagship GPT4o in the early morning of yesterday as the opening of this month's AI Spring Festival Gala. On the other hand, Microsoft will hold Bulid 2024 next week. So, can Google, which is under attack again this time, turn the tide against the wind and turn the "game" of the two companies? We will get a glimpse of it from the I/O 2024 Developer Conference that opened in the early morning of today.
This year's I/O conference is also the eighth year that Google has clearly promoted the "AI First" strategy.
As expected, in this nearly 2-hour Keynote, "AI" is the keyword throughout the I/O conference, but it is unexpected that it was mentioned as many as 121 times, and it is not difficult to see Google's anxiety about AI.

Facing aggressive external competitors, Google CEO Sundar Pichai said in a recent guest show, "AI is still in the early stages of development, and I believe Google will eventually win this war, just as Google was not the first company to do search."
At the I/O conference, Sundar Pichai also emphasized this point, "We are still in the early stages of the transformation of artificial intelligence platforms. We see huge opportunities for creators, developers, startups and everyone."
Sundar Pichai said that when Gemini was released last year, it was positioned as a large multimodal model that can reason across text, images, videos, codes, etc. In February of this year, Google released Gemini 1.5 Pro, which achieved a breakthrough in long texts and extended the context window length to 1 million tokens, more than any other large-scale basic model. Today, more than 1.5 million developers use Gemini models in Google tools.
At the launch event, Sundar Pichi shared the latest progress inside Google:
The Gemini app is now available on Android and iOS. With Gemini Advanced, users can access Google's most powerful models.
Google will roll out an improved version of Gemini 1.5 Pro to all developers worldwide. In addition, Gemini 1.5 Pro, which has a context of 1 million tokens today, is now available to consumers directly in Gemini Advanced, and it can be used across 35 languages.
Google has expanded the Gemini 1.5 Pro context window to 2 million tokens and is available to developers in private preview.
Although we are still in the early stages of Agent, Google has already begun to explore and tried Project Astra, analyzing the world through smartphone cameras, recognizing and interpreting codes, helping humans find glasses, and identifying sounds...
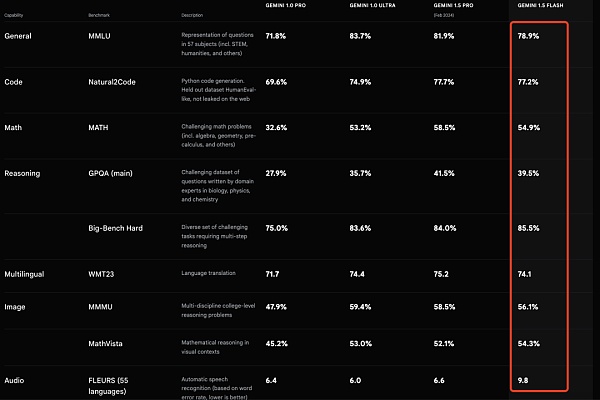
Gemini 1.5 Flash, which is lighter than Gemini 1.5 Pro, was released and optimized for important tasks such as low latency and cost.
The Veo model that can produce "high-quality" 1080p videos and the Imagen 3 model for text generation were released;
Gemma 2.0 with a new architecture and a size of 27B is here;
Android, the first mobile operating system with a built-in device base model, deeply integrates the Gemini model and becomes an operating system with Google AI at its core;
The sixth-generation TPU Trillium was released, and the computing performance of each chip was increased by 4.7 times compared with the previous generation TPU v5e.
It is said that making large models is very "competitive", but I didn't expect that in the process of accelerating to catch up, Google's "competitiveness" is far beyond imagination. At the press conference, Google not only upgraded the previous large models, but also released a number of new models.
When Gemini was released last year, Google positioned it as a large multimodal model that can reason across text, images, videos, codes, etc. In February of this year, Google released Gemini 1.5 Pro, which achieved a breakthrough in long texts and expanded the context window length to 1 million tokens, more than any other large-scale basic model.
At the launch conference, Google first made quality improvements to some key use cases of Gemini 1.5 Pro, such as translation, encoding, reasoning, etc., which can handle a wider range of more complex tasks. 1.5 Pro can now follow some complex and detailed instructions, including instructions that specify product-level behaviors involving roles, formats, and styles. It also allows users to control model behavior by setting system instructions.
At the same time, Google has added audio understanding to the Gemini API and Google AI Studio, so 1.5 Pro can now reason about images and audio of videos uploaded in Google AI Studio.
More notably, if the context of 1 million tokens is long enough, today, Google further expanded its capabilities, expanding the context window to 2 million tokens and providing it to developers in private preview, which means that it has taken the next step towards the ultimate goal of unlimited context.
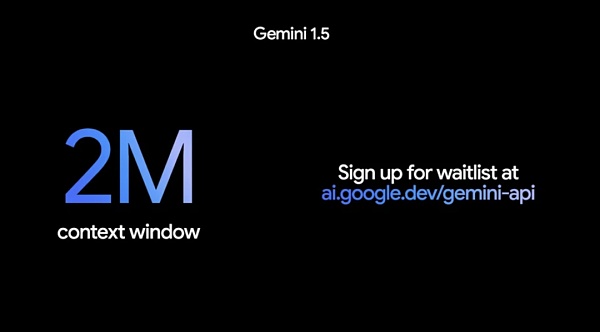
To access 1.5 Pro with a context window of 2 million tokens, you need to join the waitlist in Google AI Studio or Vertex AI for Google Cloud customers.
Gemini 1.5 Flash, a lightweight model built for expansion, is also the fastest Gemini model in the API. It is optimized for low latency and cost-critical tasks, serves more cost-effective services, and has a breakthrough long context window.

Although it is lighter than the 1.5 Pro model, it can perform multimodal reasoning on massive amounts of information. By default, Flash also has a 1 million token context window, which means you can process an hour of video, 11 hours of audio, a code base of more than 30,000 lines of code, or more than 700,000 words.
Gemini 1.5 Flash excels at summarization, chats, image and video captions, extracting data from long documents and tables, and more. This is because the 1.5 Pro was trained through a process called "distillation" to transfer the most important knowledge and skills from the larger model to a smaller, more efficient model.
Gemini 1.5 Flash is priced at 35 cents per 1 million tokens, which is slightly cheaper than GPT-4o's price of $5 per 1 million tokens.
Both Gemini 1.5 Pro and 1.5 Flash are now available in public preview and in Google AI Studio and Vertex AI.
PaliGemma is a powerful open VLM (visual-language model) inspired by PaLI-3. PaliGemma is built on open components such as the SigLIP visual model and the Gemma language model, and is designed to achieve state-of-the-art fine-tuning performance on a variety of visual-language tasks. This includes image and short video captioning, visual question answering, understanding text in images, object detection, and object segmentation.
Google said that in order to promote open exploration and research, PaliGemma is available through various platforms and resources. You can find PaliGemma on GitHub, Hugging Face model, Kaggle, Vertex AI Model Garden and ai.nvidia.com (accelerated with TensoRT-LLM), and easily integrated through JAX and Hugging Face Transformers.
All Releases Gemma 2 will provide new sizes and adopt a new architecture designed for breakthrough performance and efficiency. With 27 billion parameters, Gemma 2 has performance comparable to Llama 3 70B, but is only half the size of Llama 3 70B.

According to Google, Gemma 2's efficient design requires less than half the computation of similar models. The 27B model is optimized to run on NVIDIA's GPUs or efficiently on a single TPU host in Vertex AI, making it easier to deploy and more cost-effective for a wider range of users.

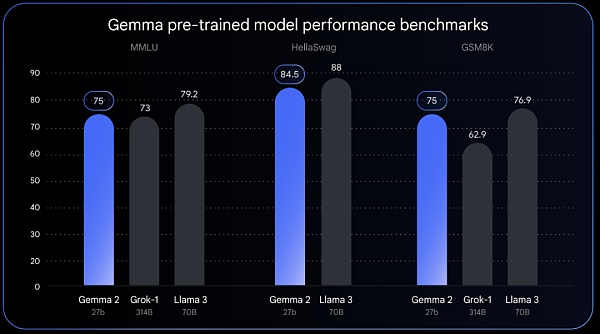
Gemma 2 will be available in June.
As a competitor to OpenAI's Sora, Google today launched Veo, a video generation model that can generate high-quality 1080p resolution videos of more than one minute in a variety of film and visual styles.
Veo builds on Google's years of work on generative video models, including Generative Query Networks (GQN), DVD-GAN, Imagen-Video, Phenaki, WALT, VideoPoet, and Lumiere, combining architectures, scaling laws, and other techniques to improve quality and output resolution.
Starting today, users can join the waitlist and apply to use Veo.
Compared to Google's previous models, the newly released Imagen 3 has far fewer distracting visual artifacts, can better understand natural language, the intent behind prompts, and incorporate small details in longer prompts.

Starting today, Imagen 3 is available to select creators for a private preview in ImageFX and to join a waitlist. Imagen 3 is coming soon to Vertex AI.
Agents are intelligent systems with reasoning, planning, and memory capabilities that can "think" multiple steps ahead and work across software and systems.
At today's press conference, Google DeepMind CEO and co-founder Demis Harbis revealed that Google has been working internally to develop general AI agents that are helpful in daily life, and Project Astra (Advanced Vision and Speech Response Agent) is one of the main attempts.
This project is based on Gemini. Google has developed a prototype agent that can process information faster by continuously encoding video frames, combining video and voice input into an event timeline, and caching this information for efficient calls.
By leveraging the voice model, Google has also enhanced their pronunciation, providing agents with a wider range of intonations. These agents can better understand the context in which they are used and respond quickly in conversations.
In the example demonstrated at the press conference, through Project Astra, it is possible to automatically identify what is making sounds in real-life scenes, and even directly locate the specific parts that make sounds. It can also explain the role of codes appearing on computer screens, and help humans find glasses, etc.
"With such technology, it is easy to imagine that in the future people will have professional artificial intelligence assistants through mobile phones or glasses devices. Some of these features will appear in Google products later this year," Google said.
Now, the improved Gemini 1.5 Pro is introduced in the Gemini Advanced subscription, and an improved version of Gemini 1.5 Pro is launched for all developers worldwide, which can be used across 35 languages.
As mentioned above, by default, Gemini 1.5 Pro has a 1 million token context. Such a long context window means that Gemini Advanced can understand multiple large documents, with a total of up to 1,500 pages, or summarize 100 emails, process one hour of video content, or more than 30,000 lines of code base.
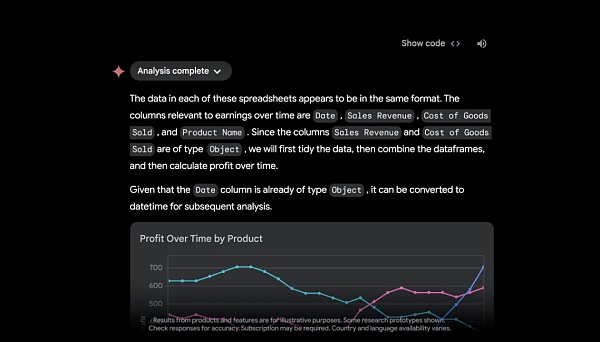
With the ability to upload files from Google Drive or directly from the device, Google revealed that soon, Gemini Advanced will act as a data analyst, discover insights from uploaded data files (such as spreadsheets) and dynamically build custom visualizations and charts.
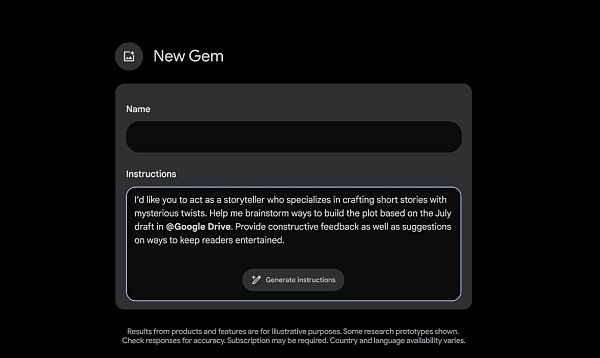
For a more personalized experience, Gemini Advanced subscribers will soon be able to create Gems - customized versions of Gemini. You can create any Gem you want, such as a fitness partner, a sous chef, a coding partner, or a creative writing guide. Just describe what you want the Gem to do and how you want it to respond, such as "You are my running coach, give me a daily running plan, and stay positive, optimistic and motivated." Gemini will take these instructions and enhance them with a single click to create a Gem that meets specific needs.
Without the application of commercial scenarios, the iteration of big model technology seems to be just "paper talk". Different from the route taken by OpenAI, Google and Microsoft are competing in speed in the AI application track. For Google, which started as a search engine, it is bound to not miss this wave of AI.
Liz Reid, vice president and head of search at Google, said, "With generative artificial intelligence, search can do more than you can imagine. Therefore, you can come up with anything you think of or anything you need to do - from research to planning to brainstorming - Google will take care of all the legwork."
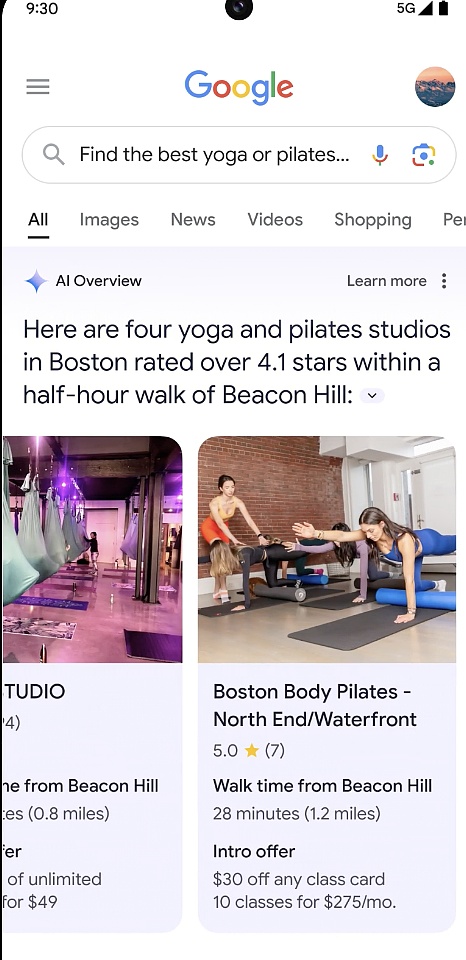
At the press conference, Google released a feature called "AI Overviews" to achieve "one search, get all the information".
To put it simply, sometimes you want to get answers quickly, but you don't have time to piece together all the information you need, such as "You are looking for a new yoga or Pilates studio, and you want a studio that is popular with locals, convenient for transportation, and also offers discounts for new members." You only need to make your needs clear and search once, and AI Overviews will give answers to complex problems.
Due to the progress of video understanding, Google has also enhanced the visual search function. You can use Google Lens video search to shoot the problems you encounter or the things you see around you (including moving objects), so as to search for answers, saving time and trouble caused by unclear text descriptions.
However, the above two features are currently only available in the United States, and will be launched in more countries in the future.
In addition to the search level, the arrival of large models will further enhance the intelligence of the product.
At the photo search application level, Google has brought an "Ask Photos" function.
With the help of Gemini, you can identify different background information of photos, such as asking: When did your daughter learn to swim? How is her swimming progress? Photos bring everything together, helping users quickly gather information and solve puzzles.
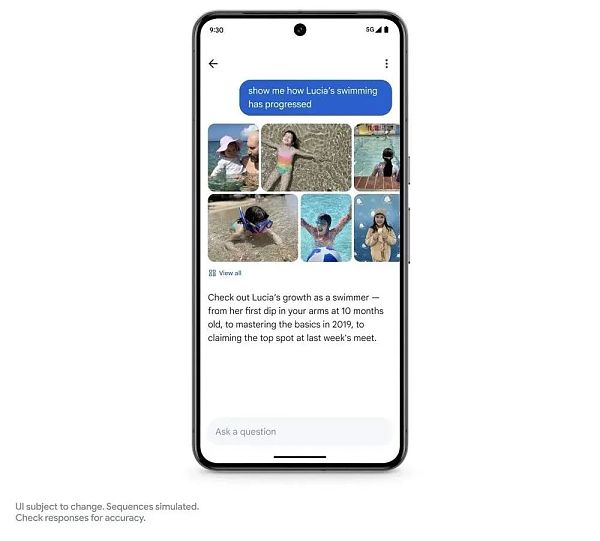
This feature is not yet available, but Google says it will be available this summer.
Google has also integrated big models into Google Workspace, so for example, you can search for emails in Gmail and keep up to date with everything that's happening at your child's school through recent emails with the school. We can ask Gemini to summarize all the recent emails from the school. It identifies relevant emails in the background and even analyzes attachments such as PDFs.
NotebookLM is an AI note-taking app launched by Google in July last year that can complete summaries and create ideas around user-uploaded documents.
Based on the multimodal large model technology, Google has added an audio output function to the app. It uses Gemini 1.5 Pro to obtain the user's source material and generate personalized interactive audio conversations.
Upgrading the operating system with AI is something that Microsoft and Google are vigorously promoting. As the world's largest mobile operating system, Android has billions of users. Google said that it has integrated the Gemini model into Android and introduced many practical AI functions.

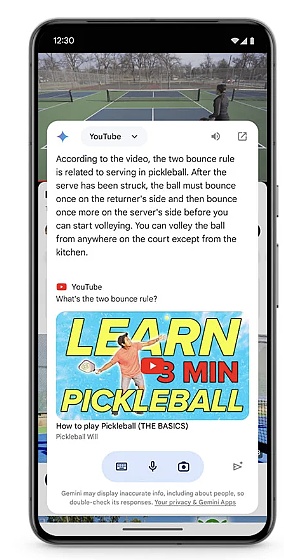
For example, through "Circle to Search", users can get more information by simple interactions such as drawing circles, doodling, and clicking without switching applications. Now, Circle to Search can help students complete their homework. When students circle the prompts they encounter, they will get step-by-step instructions to solve a series of physics and mathematics problems to gain a deeper understanding, not just the answers.
In addition, Google will soon update Gemini on the Android system, allowing users to call up Gemini's overlay on the top of the application to easily use Gemini in more ways.
"Android is the first mobile operating system to include a built-in device base model." With Gemini Nano, Android users can quickly experience AI capabilities. Google revealed that starting with Pixel later this year, it will launch the latest model Gemini Nano with multimodality. This means that the new Pixel phone can not only process text input, but also understand more contextual information, such as vision, sound and spoken language.
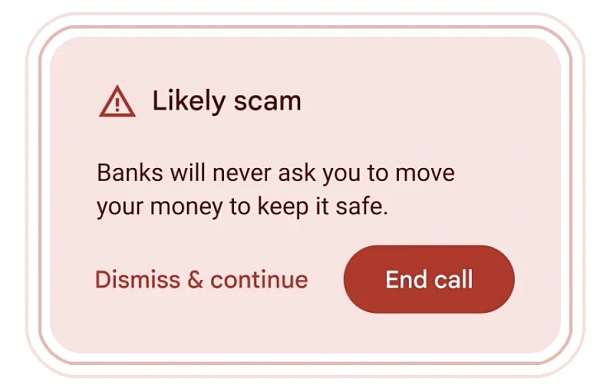
In addition, Google uses Gemini Nano in Android to provide real-time alerts when conversations that are commonly associated with fraud are detected during calls. For example, if someone claiming to be a "bank" asks you to transfer money urgently, pay with a gift card, or ask for personal information such as a card PIN or password (these are uncommon bank requests), you will receive a reminder, but this feature is still in testing.
Sundar Pichai said that training the most advanced models requires a lot of computing power. In the past six years, the industry's demand for ML computing has increased by 1 million times. And it will increase tenfold every year.
To adapt to the growing demand for ML computing, it launched the sixth-generation TPU, Trillium, which has a 4.7-fold increase in computing performance per Trillium chip compared to the previous generation TPU v5e. To achieve this level of performance, Google has expanded the size of the matrix multiplication unit (MXU) and increased the clock speed.
In addition, Trillium is equipped with the third-generation SparseCore, a dedicated accelerator for processing ultra-large embeddings common in advanced ranking and recommendation workloads. Trillium TPU can train the next wave of basic models faster and serve these models with less latency and lower cost.
Trillium TPU is more than 67% more energy efficient than TPU v5e.
It is reported that Google will provide Trillium to its cloud customers by the end of 2024.
In addition to the above model and product updates, Google has also made the latest moves in security, aiming to prevent AI abuse and other situations.
On the one hand, Google launched a new model series based on Gemini, fine-tuned for learning, and released LearnLM. It integrates research-supported learning science and academic principles into Google's products to help manage cognitive load and adapt to learners' goals, needs and motivations.

On the other hand, in order to make knowledge easier to acquire and digest, Google built a new experimental tool Illuminate, which uses the long context function of Gemini 1.5 Pro to convert complex research papers into short audio conversations. Illuminate can generate a conversation consisting of two AI-generated voices in a few minutes, providing an overview and brief discussion of key insights in research papers.
Finally, Google adopted the technology of "AI-assisted red team" to actively test its own systems for weaknesses and try to break them, and made AI-generated content easier to identify by expanding the watermarking tool SynthID to two new modes: text and video.
The above is the main content of the Google I/O 2024 Keynote. The products are very rich, but most of them need to wait.
With the end of this conference, many experts have also expressed some opinions. From NVIDIA Senior Research Manager Jim Fan said:
Google I/O. Some thoughts: The model seems to be multi-modal input, but not multi-modal output. Imagen-3 and music gen models are still separated from Gemini as independent components. Natively merging all modal input/output is an inevitable future trend:
Enables tasks like “speak more like a robot”, “speak 2x faster”, “iteratively edit this image”, and “generate consistent comic strips”.
Does not lose information across modal boundaries, like sentiment and background sounds.
Provides new contextual capabilities. You can teach models to combine different senses in novel ways with a small number of examples.
GPT-4o doesn’t do it perfectly, but it gets the form factor right. To use Andrej’s LLM-as-OS metaphor: we need models to natively support as many file extensions as possible.
Google is doing one thing right: they are finally making a serious effort to integrate AI into the search box. I feel the Agent flow: planning, real-time browsing, and multimodal input, all from a landing page. Google’s strongest moat is distribution. Gemini doesn’t have to be the best model, it can also be the most commonly used model in the world.
AI scholar Andrew Ng said, “Congratulations to all my Google friends on the cool announcements at I/O! I personally look forward to Gemini having a 2 million token input context window and better support for on-device AI - should bring new opportunities for application builders!”
Alt season is a short-term phenomenon in which altcoins surpass Bitcoin and bring high returns. Its key indicators are predicted to be BTC.D, ETH/BTC, USDT.D and OTHERS/BTC in 2025.
JinseFinanceIn the early morning of May 15, the Google I/O Developer Conference was officially held. This article is a summary of the 2-hour conference.
JinseFinanceJinseFinanceAt the Made by Google event, Google introduced its latest offerings, the Pixel 8 and 8 Pro smartphones, and the revelation of Assistant with Bard — an AI-enriched digital assistant.
 Catherine
CatherineMicrosoft and Google are investing heavily in AI research and development.
 Beincrypto
BeincryptoBinance’s Head of Product has a lot to share about his experience with the exchange, the challenges of 2022, and what’s to come.
 cryptopotato
cryptopotatoThe legal battle between the U.S. Securities and Exchange Commission (SEC) and Ripple saw renewed activity yesterday.
 Bitcoinist
BitcoinistGoogle now displays the wallet's ETH balance when there is a search for an Ethereum address.
 Others
OthersSentiment in the crypto community is the lowest it has ever been, leading to fresh speculation that BTC is a dying asset.
 Cointelegraph
CointelegraphSearch queries for "NFT" and "non-fungible token" are even more popular than searches for "Dogecoin," "Blockchain," or even "Ethereum."
Cointelegraph