That was the size of the ImageNet dataset when Fei-Fei Li, then an assistant professor at Princeton University, wanted to create it. In doing so, she hoped she could help advance the stagnant field of computer vision. It was a bold undertaking. 22,000 categories was at least two orders of magnitude more than any image dataset created before.
Her peers, who believed the answer to building better AI systems lay in algorithmic innovation, questioned her wisdom. “The more I discussed the idea of ImageNet with my colleagues, the lonelier I felt.”
Despite the skepticism, Fei-Fei and her small team—including PhD candidate Jia Deng and a few undergraduates making $10 an hour—began labeling images from search engines. Progress was slow and painful. At their rate, Jia Deng estimated, it would take 18 years to finish ImageNet—time that no one had. That’s when a master’s student introduced Fei Fei to Amazon’s Mechanical Turk, a marketplace that crowdsources “human intelligence tasks” from contributors around the world. Fei Fei immediately realized that this was exactly what they needed.
In 2009, three years after Fei Fei began the most important project of her life, ImageNet was finally ready with the help of a decentralized, global workforce. She had done her part in the shared mission of advancing computer vision.
Now it was up to the researchers to develop algorithms that could use this massive dataset to help computers see the world like humans do. However, that didn’t happen in the first two years. The algorithms barely performed better than the previous state of ImageNet.
Fei Fei began to wonder if her colleagues had been right about ImageNet being a futile endeavor.
Then, in August 2012, just as Fei Fei had given up hope that her project would inspire the changes she envisioned, Jia Deng called eagerly with the news about AlexNet. Trained on ImageNet, this new algorithm outperformed all computer vision algorithms in history. Created by three researchers from the University of Toronto, AlexNet used a mostly abandoned AI architecture called a “neural network” and exceeded Fei Fei’s wildest expectations.
In that moment, she knew her efforts had borne fruit. “History had just been made, and only a few people in the world knew about it,” Fei Fei Li shared the story behind ImageNet in her memoir, The World I See.
ImageNet combined with AlexNet was historic for several reasons.
First, the re-introduction of neural networks, long considered a dead-end technology, as the de facto architecture behind the algorithms that have driven more than a decade of exponential growth in AI.
Second, three researchers from Toronto (one of whom is Ilya Sutskever, who you may have heard of) were among the first to use graphics processing units (GPUs) to train AI models. This is now the industry standard.
Third, the AI industry is finally realizing a point that Fei Fei first made many years ago: the key ingredient for advanced AI is lots and lots of data.
We’ve all read and heard sayings like “data is the new oil” and “garbage in, garbage out” countless times. If these words weren’t fundamental truths about our world, we’d probably be bored by them. For years, AI has been slowly becoming a bigger part of our lives behind the scenes—influencing the tweets we read, the movies we watch, the prices we pay, and the credit we’re deemed worthy of. All of this is driven by data collected by painstakingly tracking our every move in the digital world.
But in the past two years, ever since a relatively unknown startup, OpenAI, released a chatbot app called ChatGPT, AI’s importance has moved from behind the scenes to the forefront. We are on the cusp of machine intelligence infiltrating every aspect of our lives. As the competition over who will control this intelligence heats up, so too does the demand for the data that drives it.
That’s what this post is about. We discuss the scale and urgency of the data AI companies need, and the problems they face in acquiring it. We explore how this insatiable demand threatens everything we love about the internet and its billions of contributors. Finally, we introduce a few emerging startups that are using cryptocurrencies to address these questions and concerns.
Before we dive in, a quick note: This post is written from the perspective of training Large Language Models (LLMs), not all AI systems. As a result, I often use "AI" and "LLMs" interchangeably. While this usage is technically inaccurate, the concepts and questions that apply to LLMs, particularly those regarding data, also apply to other forms of AI models.
Data
The training of large language models is constrained by three main resources: compute, energy, and data. Companies, governments, and startups are competing for these resources simultaneously, with a lot of capital behind them. Of the three, the competition for compute is the most intense, thanks in part to the meteoric rise in NVIDIA's stock price.
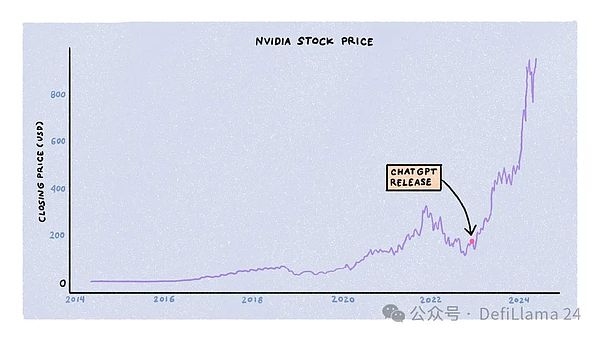
Training LLMs requires large clusters of specialized graphics processing units (GPUs), specifically NVIDIA’s A100, H100, and upcoming B100 models. These are not computers you can buy off the shelf from Amazon or your local computer store. Instead, they cost tens of thousands of dollars. NVIDIA decides how to allocate its supply to AI labs, startups, data centers, and hyperscale customers.
In the 18 months since ChatGPT’s release, GPU demand has far outstripped supply, with wait times as high as 11 months. However, as the dust from the initial frenzy has settled, supply and demand dynamics are normalizing. Startup closures, improvements in training algorithms and model architectures, the emergence of specialized chips from other companies, and NVIDIA’s increased production have all contributed to increasing GPU availability and decreasing prices.
Second, energy. Running GPUs in data centers requires a lot of energy. According to some estimates, by 2030, data centers will consume 4.5% of the world's energy. As this surging demand puts pressure on the existing power grid, technology companies are exploring alternative energy solutions. Amazon recently purchased a data center powered by a nuclear power plant for $650 million. Microsoft has hired a head of nuclear technology. OpenAI's Sam Altman has backed energy startups like Helion, Exowatt, and Oklo.
From the perspective of training AI models - energy and compute are just commodities. Using B100 instead of H100, or using nuclear power instead of traditional energy may make the training process cheaper, faster, and more efficient - but it will not affect the quality of the model. In other words, in the race to create the smartest and most human-like AI models, energy and compute are essential elements, not differentiators.
The key resource is data.
James Betker is a research engineer at OpenAI. In his own words, he has trained "more generative models than anyone should have the right to train". In a blog post, he noted that "trained on the same dataset for long enough, almost all models with enough weights and training time will converge to the same point." This means that what distinguishes one AI model from another is the dataset. Nothing else.
When we refer to a model as "ChatGPT", "Claude", "Mistral", or "Lambda", we are not talking about the architecture, the GPUs used, or the energy consumed, but the dataset it was trained on.
How much data does it take to train a state-of-the-art generative model?
The answer: a lot.
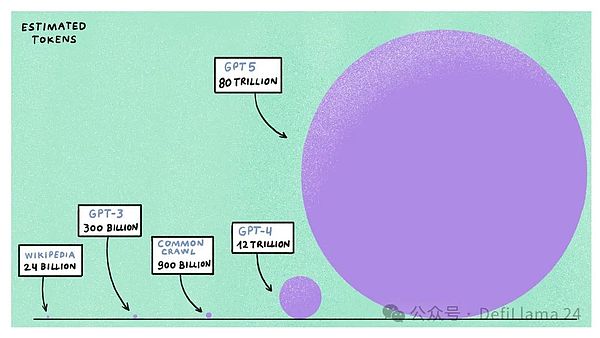
GPT-4, which is still considered the best large-scale language model more than a year after its release, was trained on an estimated 1.2 trillion tokens (or about 900 billion words). This data comes from the publicly available internet, including Wikipedia, Reddit, Common Crawl (a free and open repository of web crawled data), over a million hours of transcribed YouTube data, and code platforms like GitHub and Stack Overflow.
If you think that’s a lot of data, wait. There’s a concept in generative AI called the “Chinchilla Scaling Laws,” which states that for a given compute budget, it’s more efficient to train a smaller model on a larger dataset than a larger model on a smaller dataset. If we extrapolate the compute resources that AI companies have allocated to train the next generation of AI models — like GPT-5 and Llama-4 — we find that these models are expected to require five to six times as much compute power, using up to 100 trillion tokens to train.
Since most public internet data has already been crawled, indexed, and used to train existing models, where does additional data come from? This has become a cutting-edge research question for AI companies. There are two ways to address this problem. One is that you decide to use synthetic data generated directly by LLMs rather than by humans. However, the effectiveness of such data in making models smarter has not been tested.
Another option is to simply look for high-quality data rather than synthetically create it. However, acquiring additional data is challenging, especially when the problems AI companies face threaten not only the training of future models but also the effectiveness of existing models.
The first data problem involves legal issues. Although AI companies claim that they train models on "publicly available data," much of it is protected by copyright. For example, the Common Crawl dataset contains millions of articles from publications such as The New York Times and the Associated Press, as well as other copyrighted materials such as published books and song lyrics.
Some publications and creators are taking legal action against AI companies, claiming that they have violated their copyright and intellectual property rights. The Times sued OpenAI and Microsoft for "unlawfully copying and using The Times' unique and valuable work." A group of programmers filed a class-action lawsuit challenging the legality of using open source code to train GitHub Copilot, a popular AI programming assistant.
Comedian Sarah Silverman and writer Paul Tremblay have also sued AI companies for using their work without permission.
Others are embracing the era of change by partnering with AI companies. The Associated Press, the Financial Times, and Axel Springer have all signed content licensing agreements with OpenAI. Apple is exploring similar partnerships with news organizations such as Condé Nast and NBC. Google agreed to pay $60 million per year for access to Reddit’s API to train models, and Stack Overflow struck a similar deal with OpenAI. Meta is reportedly considering buying publisher Simon & Schuster outright.
These partnerships coincide with a second problem facing AI companies: the closing of the open web.
Internet forums and social media sites have realized the value AI companies create by training models with data on their platforms. Before striking a deal with Google (and potentially other AI companies in the future), Reddit began charging for its previously free API and shut down its popular third-party clients. Similarly, Twitter restricted access to its API and raised prices, and Elon Musk used Twitter data to train models for his own AI company, xAI.
Even smaller publications, fan fiction forums, and other niche corners of the internet that produced content for free consumption and monetized with advertising (if at all) are starting to close. The internet was envisioned as a magical online space where everyone could find a tribe that shared their unique interests and quirks. That magic seems to be slowly wearing off. The combination of the threat of lawsuits, the growing trend of multi-million content deals, and the closure of the open web has had two effects: First, the data wars are highly skewed in favor of the tech giants. Startups and small companies can neither access previously available APIs nor pay the cash required to purchase the rights without incurring legal risk. This has a clear concentration effect, where the rich who can buy the best data and create the best models get even richer. Second, the business model of user-generated content platforms is increasingly skewed against users. Platforms like Reddit and Stack Overflow rely on the contributions of millions of unpaid human creators and moderators. Yet, when these platforms strike multimillion-dollar deals with AI companies, they neither compensate nor ask for permission from their users, and without users there is no data to sell.
Both Reddit and Stack Overflow have experienced notable user walkouts protesting these decisions. The Federal Trade Commission (FTC), for its part, has launched an investigation into Reddit’s sales, licensing, and sharing of user posts with outside organizations to train AI models.
The questions raised by these issues are germane to the future of training the next generation of AI models and web content. For now, that future looks bleak. Could encryption solutions level the playing field for small companies and internet users and address these issues?
Breaking Down the Process
Training AI models and creating useful applications are complex and expensive endeavors that require months of planning, resource allocation, and execution. These processes include multiple stages, each with a different purpose and different data needs.
Let’s break down these stages to understand how encryption fits into the larger AI puzzle.
Pre-training
Pre-training, the first and most resource-intensive step in the LLM training process, forms the basis of the model. In this stage, the AI model is trained on a large amount of unlabeled text to capture general knowledge about the world and language usage information. When we say that GPT-4 was trained on 1.2 trillion tokens, this refers to the data used for pre-training.
We need a high-level overview of how LLMs work to understand why pre-training is the basis of LLMs. Note that this is a simplified overview. You can find a more thorough explanation in this excellent article by Jon Stokes, or in this great video, or even a deeper breakdown in this outstanding book by Andrej Karpathy. LLMs use a statistical technique called next token prediction. In simple terms, given a sequence of tokens (i.e. words), the model tries to predict the next most likely token. This process is repeated to form a complete response. Therefore, you can think of a large language model as a "completion machine". Let's understand this with an example.
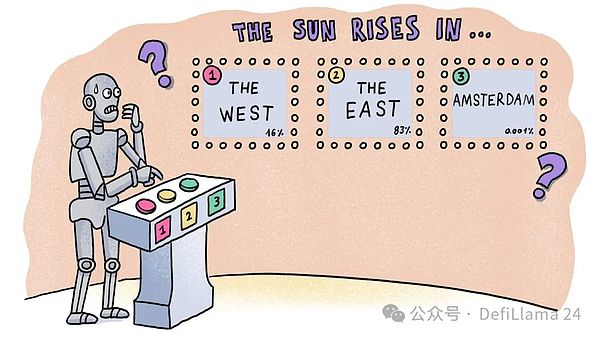
When I ask ChatGPT a question like "From which direction does the sun rise?", it first predicts the word "the", and then each subsequent word in the phrase "The sun rises from the east". But where do these predictions come from? How does ChatGPT determine that after "The sun rises from" it should be "east" and not "west", "north", or "Amsterdam"? In other words, how does it know that "east" is statistically more likely than the other options?

Another way to understand this is to compare the number of Wikipedia pages that contain these phrases. There are 55 pages for "The sun rises from the east", while there are 27 for "The sun rises from the west". "The sun rises in Amsterdam" shows no results! These are the patterns that ChatGPT picked up.
The answer lies in learning statistical patterns from large amounts of high-quality training data. If you think about all the text on the Internet, what is more likely to appear - "the sun rises in the east" or "the sun rises in the west"? The latter may be found in specific contexts, such as literary metaphors ("This is as ridiculous as believing that the sun rises in the west") or discussions about other planets (such as Venus, where the sun does rise in the west). But overall, the former is much more common.
By repeatedly predicting the next word, LLM forms an overall view of the world (what we call common sense) and an understanding of language rules and patterns. Another way to look at LLM is to think of it as a compressed version of the Internet. This also helps understand why data needs to be large (more categories to choose from) and high quality (to improve pattern learning accuracy).
But as discussed earlier, AI companies are running out of data to train larger models. The demand for training data is growing much faster than new data is being generated on the open internet. With looming lawsuits and the closure of major forums, AI companies face a serious problem.
This problem is exacerbated for smaller companies that can’t afford to strike multi-million dollar deals with proprietary data providers like Reddit.
That brings us to Grass, a decentralized residential proxy service provider that aims to solve some of these data problems. They call themselves the “data layer for AI.” Let’s first understand the role of residential proxy service providers.
The internet is the best source of training data, and crawling the internet is the preferred method for companies to obtain this data. In practice, crawling software is often hosted in data centers for scale, convenience, and efficiency. However, companies with valuable data don’t want their data to be used to train AI models (unless they’re paid). To enforce these restrictions, they often block IP addresses of known data centers, preventing large-scale crawling.
This is where residential proxy service providers come into play. Websites only block IP addresses of known data centers, not those of regular internet users like you and me, which makes our internet connections, or residential internet connections, valuable. Residential proxy service providers aggregate millions of these connections in order to crawl websites at scale for AI companies.
However, centralized residential proxy service providers operate in secret. They often do not clearly state their intentions. If users know that a product is using their bandwidth and that the product is not compensating them, they may be reluctant to provide their bandwidth. Worse still, they may demand compensation for their bandwidth usage, which in turn reduces their profits.
To protect their bottom line, residential proxy service providers attach bandwidth-consuming code to free applications that are widely distributed, such as mobile utility apps (think calculators and voice recorders), VPN providers, and even consumer TV screensavers. Users who think they are getting a product for free are often unaware that third-party residential providers are consuming their bandwidth (these details are often buried in terms of service that few people read).
Eventually, some of this data goes to AI companies, who use it to train models and create value for themselves.
While running his own residential proxy service provider, Andrej Radonjic realized the unethical nature of these practices and how unfair they were to users. He saw the growth of cryptocurrencies and identified a way to create a fairer solution. That’s how Grass was founded in late 2022. A few weeks later, ChatGPT was released, changing the world and putting Grass in the right place at the right time.

Unlike other residential proxy service providers who use sneaky tactics, Grass makes it clear to users about the use of bandwidth to train AI models. In return, they are directly rewarded. This model completely disrupts the way residential proxy service providers operate. By voluntarily providing bandwidth access and becoming partial owners of the network, users move from being uninformed passive participants to active propagators, improving the reliability of the network and benefiting from the value created by AI.
GRASS's growth has been phenomenal. Since launching in June 2023, they have gathered over 2 million active users running nodes (by installing the browser extension or mobile app) and contributing bandwidth to the network. This growth has occurred without any external marketing costs and has been driven by a very successful referral program.
Using Grass's service allows companies of all sizes, from large AI labs to open source startups, to gain access to scraped training data without having to pay millions of dollars. At the same time, everyday users are rewarded for sharing their internet connection and becoming part of the growing AI economy.
In addition to the raw crawled data, Grass also provides some additional services to its customers.
First, they convert unstructured web pages into structured data that can be more easily processed by AI models. This step is called data cleaning and is a resource-intensive task usually performed by AI labs. By providing structured, clean datasets, Grass increases its value to customers. In addition, Grass is training an open source LLM to automate the process of crawling, cleaning, and labeling data.
Second, Grass is bundling datasets with undeniable proof of origin. Given the importance of high-quality data to AI models, ensuring that bad actors - whether websites or residential proxy providers - do not have the right to tamper with datasets is crucial for AI companies.
The severity of this problem is reflected in the formation of bodies like the Data & Trust Alliance, a nonprofit group of more than two dozen companies, including Meta, IBM, and Walmart, working together to create provenance standards to help organizations determine whether a set of data is suitable and trusted for use.
Grass is taking a similar approach. Every time a Grass node crawls a web page, it also records metadata to verify the crawled page. These proofs of provenance are stored on the blockchain and shared with clients (who can further share them with their users).
Although Grass is built on Solana, one of the highest throughput blockchains, it is impractical to store the provenance of every crawl on L1. Therefore, Grass is building a rollup (one of the first on Solana) that batches proofs of provenance using a ZK processor and then publishes them on Solana. This rollup, which Grass calls the “data layer for AI,” becomes the data ledger for all the data they scrape.
Grass’ Web 3-first approach gives it several advantages over centralized residential proxy providers. First, by using incentives to get users to share bandwidth directly, they more fairly distribute the value created by AI (while also saving the cost of paying application developers to bundle their code). Second, they can charge a premium for providing “legitimate traffic,” which is extremely valuable in the industry.
Another protocol built on the “legitimate traffic” angle is Masa. The network allows users to pass in their login information for platforms like Reddit, Twitter, or TikTok. Nodes on the network then scrape contextual, updated data. The advantage of this model is that the data collected is what a normal Twitter user would see in their feed. You can have a rich dataset in real time to predict sentiment or content that is about to go viral
What are their datasets used for? For now, there are two main use cases for this contextual data.
Finance - If you have the mechanism to see what thousands of people see on their feeds, you can develop trading strategies based on them. Intelligent agents based on sentiment data can be trained on Masa's dataset.
Social - The advent of AI-based companions (or tools like Replika) means we need datasets that mimic human conversations. These conversations also need to be updated with the latest information. Masa's data stream can be used to train agents that can talk meaningfully about the latest trends on Twitter.
Masa's approach is to take information from closed gardens (like Twitter) and, with user consent, make them available to developers to build applications. This social-first approach to data collection also allows datasets to be built around different national languages.
For example, a bot that speaks Hindi could use data collected from social networks operating in Hindi. The types of applications these networks enable are yet to be explored.
Model Alignment
The pre-trained LLM is far from being ready for production use. Think about it. So far, all the model knows is how to predict the next word in a sequence, nothing else. If you give a pre-trained model some text, like “Who is Satoshi Nakamoto”, any of the following would be a valid response:
Complete the question: Satoshi Nakamoto?
Turn the phrase into a sentence: This is a question that has been bothering Bitcoin believers for years.
Really answer the question: Satoshi Nakamoto is the anonymous person or group who created Bitcoin, the first decentralized cryptocurrency, and its underlying blockchain technology.
The LLM, which is designed to provide a useful answer, will provide a third response. However, the pre-trained model’s response is not coherent or correct. In fact, they often randomly output text that makes no sense to the end user. In the worst case, the model secretly responds with factually false, toxic, or harmful information. When this happens, the model is said to be "hallucinating."

This is how a pre-trained GPT-3 answers questions.
The goal of model alignment is to make the pre-trained model ultimately useful to the user. In other words, to completely transform it from a mere statistical text tool to a chatbot that understands and aligns with user needs and engages in coherent, useful conversations.
Conversation Fine-tuning
The first step in this process is conversation fine-tuning. Fine-tuning is taking a pre-trained machine learning model and further training it on a smaller, targeted dataset, helping it adapt to a specific task or use case. For training LLMs, this specific use case is to have human-like conversations. Naturally, the dataset for such fine-tuning is a set of human-generated prompt-response pairs that demonstrate how the model should behave.
These datasets cover different types of conversations (question-answering, summarization, translation, code generation) and are usually designed by highly educated humans (sometimes called AI tutors) with excellent language skills and expertise.
State-of-the-art models like GPT-4 are estimated to be trained on around 100,000 of these prompt-response pairs.

Example of a prompt-response pair
Reinforcement Learning with Human Feedback (RLHF)
Think of this stage as similar to how a human trains a pet puppy: reward good behavior, punish bad behavior. The model is given a prompt, and its response is shared with a human labeler, who rates it on a numeric scale (e.g., 1-5) based on the accuracy and quality of the output. Another version of RLHF is to get a prompt to produce multiple responses, which are then ranked from best to worst by a human labeler.
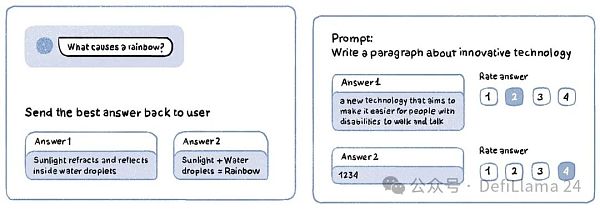
RLHF Task Examples
RLHF helps push models toward human preferences and desired behaviors. In fact, if you use ChatGPT, OpenAI is also using you as a RLHF data labeler! This happens when the model sometimes produces two responses, and asks you to choose the better one.
Even simple like or dislike icons that prompt you to rate the helpfulness of an answer are a form of RLHF training for your model.
When we use AI models, we rarely think about the millions of hours of human effort that went into them. This isn’t unique to LLM. Historically, even traditional machine learning use cases like content moderation, autonomous driving, and tumor detection have required a significant amount of human involvement in data annotation.
Mechanical Turk, the service Fei-Fei Li used to create the ImageNet database, has been called “artificial AI” by Jeff Bezos because its workers play the role of data annotation behind the scenes of AI training.
In a
Strange Tales
earlier this year, it was revealed that Amazon’s Just Walk Out stores, where customers can pick items off the shelves and walk out (and be automatically charged later), aren’t powered by some advanced AI. Instead, there are 1,000 contractors in India who are manually sifting through store footage.

The point is, every large-scale AI system relies on humans to some degree, and LLM is simply increasing the demand for these services. Companies like Scale AI, whose clients include OpenAI, have already reached an 11-figure valuation on the strength of this demand. Even Uber is repurposing some of its workers in India to annotate AI output when they’re not driving vehicles.
In their quest to become a full-stack AI data solution, Grass has also entered this market. They will soon release an AI annotation solution (as an extension of their main product), and users on their platform will be able to earn incentives by completing RLHF tasks.
The question is: what advantage does Grass gain over the hundreds of centralized companies in the same space through the decentralized process?
GRASS can use token incentives to bootstrap a network of workers. Just as they use tokens to reward users for sharing their internet bandwidth, they can also be used to reward humans for annotating AI training data. In a Web2 world, paying gig economy workers, especially for globally distributed work, is a poor user experience compared to the instant liquidity provided on a fast blockchain like Solana.
The crypto community in general, and GRASS’s existing community in particular, already has a high concentration of educated, internet-native, and technically skilled users. This reduces the resources GRASS needs to spend on recruiting and training workers.
You might wonder if using incentives in exchange for the task of annotating AI model responses will attract attention from farmers and bots. I had the same question. Fortunately, there has been extensive research into using consensus-based techniques to identify high-quality annotators and filter out bots.
Note that, at least for now, Grass is only entering the RLHF (Reinforcement Learning with Human Feedback) market and is not helping companies with conversational fine-tuning, which requires a highly specialized labor market and is difficult to automate.
Professional Fine-tuning
Once the pre-training and alignment steps are complete, we have what is called a base model. The base model has a general understanding of how the world works and can have fluent, human-like conversations on a wide range of topics. It also has a solid grasp of language and can help users compose emails, stories, poems, essays, and songs with ease.
When you use ChatGPT, you are interacting with the base model, GPT-4.
Base models are general-purpose models. While they have good enough understanding of millions of categories of topics, they are not specialized in any one of them. When asked to help understand Bitcoin's token economics, the responses will be useful and mostly accurate. However, you shouldn’t trust it when you ask it to elaborate on how to de-risk a re-staking protocol like EigenLayer.
Recall that fine-tuning is the process of taking a pre-trained machine learning model and further training it on a smaller, targeted dataset to help adapt it to a specific task or use case. We previously discussed fine-tuning in the context of converting a raw text completion tool into a conversational model. Similarly, we can also fine-tune the resulting base model to specialize in a specific domain or task.
Med-PaLM2, a fine-tuned version of Google’s base model PaLM-2, was trained to provide high-quality answers to medical questions. MetaMath was fine-tuned on Mistral-7B to perform better mathematical reasoning. Some fine-tuned models specialize in specific categories, such as storytelling, text summarization, and customer service, while others specialize in niche areas, such as Portuguese poetry, Hindi-English translation, and Sri Lankan law.
Fine-tuning a model for a specific use case requires a high-quality dataset relevant to that use case. These datasets can come from domain-specific websites (like a newsletter with encrypted data), proprietary datasets (a hospital might record thousands of doctor-patient interactions), or the experience of experts (which would require thorough interviews to capture).

As we move into a world with millions of AI models, these niche, long-tail datasets are becoming increasingly valuable. From large accounting firms like EY to freelance photographers in Gaza, the owners of these datasets are being sought after because they will soon be the hottest commodity in the AI arms race. Services like Gulp Data have emerged to help companies fairly assess the value of their data.
OpenAI even has an open request seeking data partnerships with entities that have “large-scale datasets that reflect human society and are not readily available online today.”
We know of at least one way to match buyers looking for specific products with sellers: Internet marketplaces! Ebay created a marketplace for collectibles, Upwork created a marketplace for human labor, and countless platforms have created marketplaces for countless other categories. Not surprisingly, we’ve also seen the emergence of marketplaces, some decentralized, for niche datasets.
Bagel is building “universal infrastructure,” a set of tools that enables holders of “high-quality, diverse data” to share their data with AI companies in a trustworthy, privacy-preserving way. They use techniques like zero-knowledge (ZK) and fully homomorphic encryption (FHE) to do this.
Companies often hold extremely valuable data that they cannot monetize due to privacy or competition concerns. For example, a research lab might have a trove of genomic data that they can’t share to protect patient privacy, or a consumer product manufacturer might have data on supply chain scrap reductions that it can’t make public without revealing competitive secrets. Bagel uses advances in cryptography to make these datasets useful while alleviating attendant concerns.
Grass’ residential proxy service can also help create specialized datasets. For example, if you want to fine-tune a model to provide expert cooking recommendations, you could ask Grass to scrape data from Reddit subreddits like r/Cooking and r/AskCulinary. Similarly, a travel-oriented model maker could ask Grass to scrape data from TripAdvisor forums.
While these aren’t exactly proprietary data sources, they can still be valuable additions to other datasets. Grass also plans to use its network to create archived datasets that can be reused by any customer.
Contextual Data
Try asking your favorite LLM “When is your training deadline?” You’ll get an answer like November 2023. This means that the base model only provides information available before that date. This makes sense given how computationally expensive and time-consuming it is to train these models (or fine-tune them).
To keep them up to date in real time, you’d have to train and deploy a new model every day, which is simply not feasible (at least so far).
However, an AI without up-to-date information about the world is pretty useless for many use cases. For example, if I use a personal digital assistant that relies on LLMs for responses, they will be limited when asked to summarize unread emails or provide the goalscorer for the last Liverpool game.
To get around these limitations and provide users with responses based on real-time information, application developers can query and insert information into the so-called “context window” of the base model. The context window is the input text that LLM can process to generate a response. It is measured in tokens, which represent the text that LLM can "see" at any given moment.
So, when I ask my digital assistant to summarize my unread emails, the application first queries my email provider to get the contents of all the unread emails, inserts the response into a prompt sent to LLM, and appends something like: "I have provided a list of all the unread emails in Shlok's inbox. Please summarize them." With this new context, LLM can then complete the task and provide a response. Think of this process as if you copy-pasted an email into ChatGPT and asked it to generate a response, but it happens on the backend.
To create applications with up-to-date responses, developers need access to real-time data. Grass nodes, which can crawl any website in real time, can provide this data to developers. For example, a news application based on LLM can ask Grass to crawl all the popular articles on Google News every five minutes. When a user queries “What was the magnitude of the earthquake that just hit New York City?”, the news application retrieves relevant articles, adds them to the context window of the LLM, and shares the response with the user.
This is where Masa fits in today as well. As it stands, Alphabet, Meta, and X are the only large platforms with constantly updated user data because they have user bases. Masa levels the playing field for smaller startups.
The technical term for this process is Retrieval Augmented Generation (RAG). The RAG workflow is at the heart of all modern LLM-based applications. This process involves vectorizing text, or converting text into arrays of numbers that can then be easily interpreted, manipulated, stored, and searched by computers.
Grass plans to release physical hardware nodes in the future to provide customers with vectorized, low-latency, real-time data to streamline their RAG workflows.
Most builders in the industry predict that context-level queries (also known as inference) will use the majority of resources (energy, compute, data) in the future. This makes sense. Training a model will always be a time-bounded process that consumes a certain amount of resource allocation. Application-level usage, on the other hand, can theoretically have unlimited demand.
Grass has seen this happen, with most of their text data requests coming from clients looking for real-time data.
The context windows of LLMs have expanded over time. When OpenAI first released ChatGPT, its context window was 32,000 tokens. Less than two years later, Google’s Gemini model had a context window of over a million tokens. A million tokens is the equivalent of over eleven 300-page books — a lot of text.
These developments have allowed context windows to be built for things much larger than just access to real-time information. For example, someone could dump all of Taylor Swift’s lyrics, or the entire archive of this newsletter, into a context window and ask the LLM to generate a new piece of content in a similar style.
Unless explicitly programmed not to do so, the model will produce pretty decent output.
If you can sense where this discussion is going, wait and see what happens next. So far, we’ve mainly discussed text models, but generative models are also becoming quite adept at other modalities like sound, image, and video generation. I recently saw this really cool London illustration by Orkhan Isayen on Twitter.

Midjourney, the popular (and very good) text-to-image tool has a feature called Style Adjuster that can generate new images in the same style as an existing image (this feature also relies on a RAG-like workflow, but is not exactly the same). I uploaded Orkhan’s handcrafted illustration and used the Style Adjuster to prompt Midjourney to change the city to New York. Here’s what I got:

Four images that, if you scroll through this artist’s illustrations, could easily be mistaken for their work. These were all generated by AI in under 30 seconds, based on a single input image. I requested “New York,” but the subject could be anything, really. Similar kinds of copying can be achieved in other modalities, like music.
Recalling our earlier discussion that some of the entities suing AI companies include creators, you can see why it makes sense for them to do so.
The internet was once a boon to creators, a way for them to share their stories, art, music, and other forms of creative expression with the world; a way for them to find their 1,000 real fans. Now, that same global platform is becoming the biggest threat to their livelihoods.
Why pay a $500 commission when you can get a copy that’s close enough in style to Orkhan’s work for a $30 per month Midjourney subscription?
Sound dystopian?
The great thing about technology is that it almost always comes up with new solutions to the problems it creates. If you turn what seems like a grim situation for creators upside down, you see it’s an opportunity for them to monetize their talents on an unprecedented scale.
Before AI, the amount of art Orkhan could create was limited by the number of hours they had in a day. With AI, they can now theoretically serve an unlimited customer base.
To understand what I mean, let’s look at elf.tech, the AI music platform from musician Grimes. Elf Tech allows you to upload a recording of a song, which it then transforms into the sound and style of Grimes. Any royalties earned from the song are split 50-50 between Grimes and the creator. This means that as a fan of Grimes, her voice, her concerts, or her distribution, you can simply come up with an idea for a song, and the platform leverages AI to transform it into Grimes’ voice.
If the song goes viral, both you and Grimes benefit. This also enables Grimes to amplify her talent and passively leverage her distribution.
TRINITI, the technology that powers elf.tech, is a tool created by the company CreateSafe. Their litepaper reveals one of the most interesting intersections of blockchain and generative AI technology we foresee.
Expanding the definition of digital content through creator-controlled smart contracts and reimagining distribution through blockchain-based, peer-to-peer, pay-for-access microtransactions, allowing any streaming platform to instantly verify and access digital content. Generative AI then executes instant micropayments based on the terms specified by the creator and streams the experience to the consumer.
Balaji puts it more succinctly.
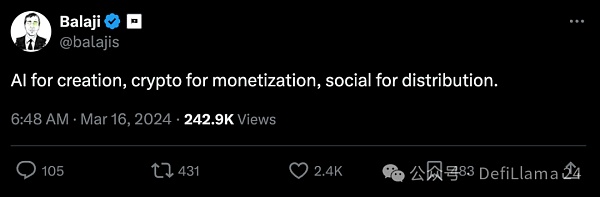
With the advent of new mediums, we rush to figure out how humans will interact with them. When they are combined with networks, they become powerful engines for change. Books fueled the Protestant Revolution. Radio and television were a big part of the Cold War. Media is often a double-edged sword. It can be used for good or for bad.
What we have today are centralized companies that own the majority of user data. It’s almost like we’re trusting our own companies to do the right thing for creativity, our mental health, and the development of a better society. That’s too much power to be handed over to a handful of companies whose inner workings we barely understand.
We are still in the early stages of the LLM revolution. Much like Ethereum in 2016, we barely know what kind of applications might be built with them. An LLM that can converse with my grandmother in Hindi? An intelligent agent that can browse through information streams and present only high-quality data? A mechanism for independent contributors to share specific cultural nuances such as slang? We don’t yet know too much about the possibilities.
However, it is clear that building these applications will be limited by one key element: data.
Protocols like Grass, Masa, and Bagel are the infrastructure that provide data provenance in an equitable way. When considering what can be built on top of it, the human imagination is the limit. To me, it seems exciting.


 Catherine
Catherine





