Author |: Frank-Zhang.eth, Twitter: @dvzhangtz

The author believes that artificial intelligence itself represents a new type of productivity and is the direction of human development; the combination of Web3 and A will make Web3 a new type of production relationship in the new era, and a way to organize future human society and avoid the absolute monopoly of AI giants.
As a person who has been working on the front line of Web3 primary investment for a long time and a former AI researcher, I think it is my responsibility to write a track mapping.

I.Objective of this article
In order to understand A more fully, we need to understand:
1. Some basic concepts of A, such as: what is machine learning, why do we need a large language model.
2. The steps of AI development, such as: data acquisition, model pre-training, model fine tune, model use; what are they doing.
3. Some emerging directions, such as: external knowledge base, federated learning, ZKML, FHEML, promptlearning, and ability neurons.
4. What are the projects corresponding to Web3 on the entire A chain?
5. Which links in the entire AI chain have greater value or are easy to produce big projects.
When describing these concepts, the author will try not to use formulas and definitions, but to describe them in a metaphorical way.
This article covers as many new terms as possible. The author hopes to leave an impression in the reader's mind. If you encounter them in the future, you can come back to check where they are in the knowledge structure.
II. Basic concepts
Part 1
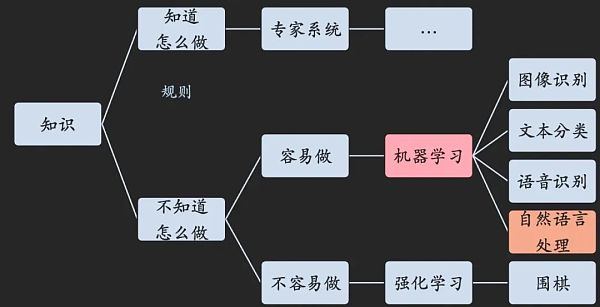
Today, the web3+ai projects we are familiar with, their technology belongs to the idea of neural networks in machine learning in artificial intelligence.
The following paragraph mainly defines some basic concepts: artificial intelligence, machine learning, neural networks, training, loss function, gradient descent, reinforcement learning, and expert systems.
Part 2
Artificial Intelligence
Definition: Artificial intelligence is a new technical science that studies and develops theories, methods, technologies and application systems that can simulate, extend and expand human intelligence. The research goal of artificial intelligence is to enable intelligent machines to: listen, see, speak, think, learn and act.
My definition: The results given by the machine are the same as those given by people, and it is difficult to distinguish between true and false (Turing test)
Part 3
Expert System
If something has clear steps and knowledge required: Expert System

Part 4
If something is difficult to describe how to do it:
How does a neural network teach a machine a piece of knowledge? We can use an analogy as follows:
If you want to teach a puppy how to pee on a mat (classic case, no bad direction)——(If you want to teach a machine a piece of knowledge)
Method 1: If the dog urinates on the mat, reward it with a piece of meat, otherwise spank it
Method 2: If the dog urinates on the mat, reward it with a piece of meat, otherwise spank it; and the farther away from the mat, the harder the spanking (calculate the loss function)
Method 3: Every time the dog takes a step, a judgment is made:
If it walks towards the mat, reward it with a piece of meat, if it does not walk towards the mat, spank it
(calculate the loss function once for each training)
Method 4: Every time the dog takes a step, a judgment is made. If it walks towards the mat, a piece of meat is rewarded. If it does not walk towards the mat, it is spanked. A piece of meat is placed in the direction of the mat to attract the dog to walk towards the mat. (After each training, the loss function is calculated, and then the gradient descent is performed in the direction that can best reduce the loss function) Part 6 Why have neural networks made rapid progress in the past decade? Because in the past decade, humans have made rapid progress in computing power, data, and algorithms.
Computing power: Neural networks were actually proposed in the last century, but the hardware at that time took too long to run neural networks. But with the development of chip technology in this century, the computing power of computer chips has doubled at a rate of 18 months. There are even chips such as GPUs that are good at parallel computing, which makes the computing time of neural networks "acceptable".
Data: Social media and the Internet have accumulated a large amount of training data, and large companies also have related automation needs.
Model: With computing power and data, researchers have developed a series of more efficient and accurate models.
"Computing power", "data" and "model" are also called the three elements of artificial intelligence.
Part 7
Why is the Large Language Model (LLM) important?
Why should we pay attention: Today we are gathered here because everyone is curious about Al+ web3; and A is popular because of ChatGPT; ChatGPT belongs to the large language model.
Why do we need a large language model: As we said above, machine learning requires training data, but the cost of large-scale data annotation is too high; the large language model solves this problem in a clever way.

Part8
Bert——The first large language model
What if we don’t have training data? A sentence of human speech itself is a segment of annotation. We can use the cloze method to create data.
We can hollow out some words in a paragraph and let the transformer architecture (not important) model predict what words should be filled in these places (let the dog find the mat);
If the model predicts wrong, measure some loss functions and gradient descent (if the dog walks towards the mat, reward a piece of meat, if it does not walk towards the mat, spank it, and put a piece of meat in the direction of the mat to attract the dog to walk towards the mat)
In this way, all texts on the Internet can become training data. Such a training process is also called "pre-training", so the large language model is also called a pre-training model. Such a model can give him a sentence and let him guess word by word what word should be said next. This experience is the same as using chatgpt now.
My understanding of pre-training: Pre-training allows machines to learn common human knowledge from corpus and cultivate "sense of language".

Part 9
Subsequent development of large language models
After Bert proposed it, everyone found that this thing is really useful!
You only need to make the model bigger and have more training data, and the effect will get better and better. This is not a mindless rush.
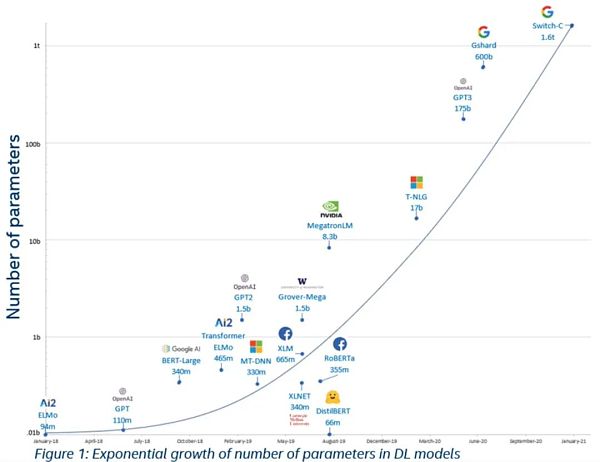
Training data surge: Bert used all Wikipedia and book data for training. Later, the training data was expanded to the entire network's English data, and then expanded to the entire network and all languages
The number of model parameters increased rapidly
Three,Steps in AI development
Part 1
Pre-training data acquisition
(This step is generally only done by large companies/large research institutes) Pre-training generally requires a huge amount of data. It is necessary to crawl all kinds of web pages on the entire network, accumulate TB of data, and then pre-process
Part 2
Model secondary pre-training
(option) Pre-training allows the machine to learn common human knowledge from the corpus and cultivate a "sense of language", but if we want the model to have more knowledge in a certain field, we can take the corpus in this field and feed it into the model for secondary pre-training.
For example, Meituan, as a food delivery platform, needs a large model that knows more about food delivery. Therefore, Meituan used the Meituan Dianping business corpus for secondary pre-training and developed MT-Bert. The resulting model works better in related scenarios.
My understanding of secondary pre-training: Secondary pre-training makes the model an expert in a certain scenario
Part 3
Model fine tune training
(option) If the pre-trained model wants to become an expert in a certain task, such as an expert in sentiment classification, topic extraction, or speaking and reading comprehension, you can use the data on the task to fine tune the model.
But here we need to label the data. For example, if we need sentiment classification data, we need data similar to the following:
The key maker asked me: "Do you match it?" neutral
The strong Xiao Wang next door asked me: "Do you match it?" negative
My understanding of secondary pre-training: Fine tune makes the model an expert in a certain task
It should be noted that the training of the model requires a large amount of data transmission between graphics cards. Currently, one of the major projects of Al+ web3 is distributed computing power - people from all over the world contribute their idle machines to do something. But it is very, very difficult to use this computing power to do complete distributed pre-training; if you want to do distributed Fine tune training, you also need a very clever design. Because the time to transmit information between graphics cards will be higher than the time to calculate.
Part 4
It should be noted that the training of the model requires a large amount of data transmission between graphics cards. Currently, one of the major projects of Al+web3 is distributed computing power - people from all over the world contribute their idle machines to do something. But it is very difficult to use this computing power to do complete distributed pre-training; if you want to do distributed Fine tune training, you also need a very clever design. Because the time to transmit information between graphics cards will be higher than the time to calculate.
Part 5
Model use
Model use is also called model inference. This refers to the process of using the model once after training is completed.
Compared to training, model inference does not require graphics cards to transmit a large amount of data, so distributed inference is a relatively easy thing.
Fourth, The latest application of large models
Part 1
External knowledge base
Reason: We hope that the model knows a small amount of knowledge in our field, but we don’t want to spend a lot of money to train the model
Method: Pack a large amount of PDF data into a vector database and use it as background information as input
Case: Baidu Cloud One, Myshell
Promptlearning
Reason: We feel that the external knowledge base cannot meet our customization needs for the model, but we don’t want to bear the burden of parameter adjustment and training of the entire model
Method: Do not train the model, only use training data, to learn what kind of Prompt should be written
Case: Widely used today
Part 2
Federated Learning (FL)
Cause: When using the training model, we need to provide our own data, which will leak our privacy, which is unacceptable for some financial and medical institutions
Method: Each institution uses data to train the model locally, and then concentrates the model in one place for model fusion
Case: Flock
FHEML
Cause: Federated learning requires each participant to train a model locally, but this threshold is too high for each participant
Method: Use FHE is used for fully homomorphic encryption, so the model can be trained directly with encrypted data
Disadvantages: very slow and expensive
Examples: ZAMA, Privasea
Part 3
ZKML
Cause: When we use model services provided by others, we hope to confirm that they are really providing model services according to our requirements, rather than using a small model and messing around
Method: Let it use ZK to generate a proof to prove that it is indeed doing the calculation it claims to have done
Disadvantages: very slow and expensive
Example: Modulus
Skillneuron
left;">Cause: Today's model is like a black box. We feed it a lot of training data, but we don't know what it has learned. We hope to have some way to optimize the model in a specific direction, such as having stronger emotional perception and higher moral standards.
Method: The model is like the brain. Some areas of the neurons manage emotions, and some areas manage morality. By finding these nodes, we can optimize them in a targeted manner.
Case: Future direction
V.Classification of Web3 projects on the A chain
Part 1
The author will divide it into three categories:
Infra: Decentralized A's infrastructure
Middleware: Let Infra better serve the application layer
Part 2
Infra layer: AI infrastructure will always be divided into three categories: data computing power algorithm (model)
Decentralized algorithm (model):
@TheBittensorHub Research report: x.com/dvzhangtz/stat..@flock_ io
Decentralized computing power:
General computing power: @akashnet_, @ionet
Specialized computing power: @rendernetwork(rendering), @gensynai(AI), @heuris_ai(Al)@exa_bits (A)(AD,
Decentralized data:
Data Annotation: @PublciAl_, QuestLab
Storage: IPFS, FIL
Oracle: Chainlink
Index: The Graph
Part 3
Middleware: How to make Infra better serve the application layer
Privacy: @zama fhe, @Privasea_ai
Verification: EZKL, @ModulusLabs , @gizatechxyz
Application layer: It is actually difficult to classify all applications. We can only list the most representative ones
Data Analysis
Agent
Market: @myshell_ai
Web3 knowledge chatbot:@qnaweb3
Help people do operations:@autonolas
Six,What kind of places are more likely to produce big projects?
First, similar to other fields, Infra is prone to big projects, especially decentralized models and decentralized computing power, and the author feels that its marginal cost is low.
Then, inspired by my conversation with @owenliang60, I feel that if a killer application can appear at the application layer, it will also become a top project.
Looking back at the history of big models, it was the killer application ChatGPT that pushed it to the forefront. It was not a major technical iteration, but an optimization for the Chat task. Perhaps in the future, there will be phenomenal applications like Stepn/Friendtech in the A+Web3 field. Let's wait and see.


 JinseFinance
JinseFinance


