How Arweave works and why it exists
Arweave, Arweave's working principle and significance of existence Golden Finance, this article briefly introduces Arweave's working principle and value.
 JinseFinance
JinseFinance

Author: Arweave Source: X, @ArweaveOasis
Arweave Ecosystem Since its launch in 2018, it has been considered one of the most valuable networks in the decentralized storage circuit. But in the blink of an eye, 5 years later, many people are both familiar and unfamiliar with Arweave/AR due to its technology-led attributes. This article starts with a review of the technological development history of Arweave since its establishment to enhance everyone's in-depth understanding of Arweave.
Arweave has experienced more than ten major technology upgrades in 5 years. The core goal of its major iterations is to transform from a computing-dominated mining mechanism to a storage-dominated mining mechanism.
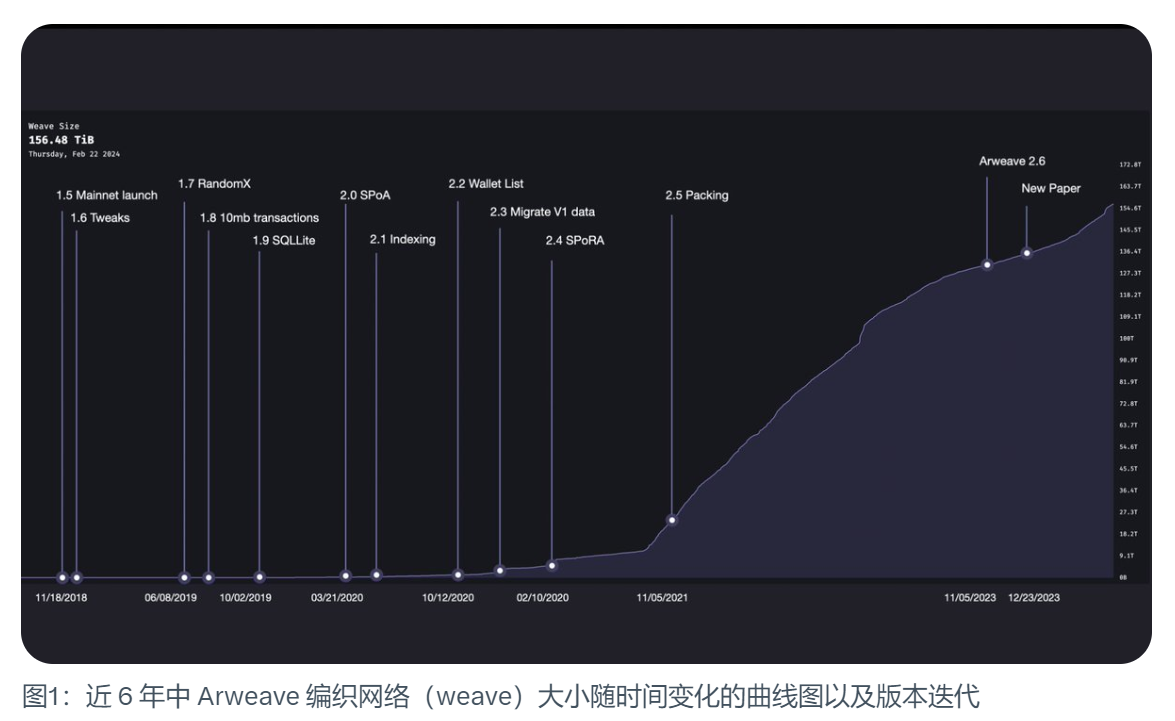
Arweave 1.5: Mainnet launch
Arweave mainnet was launched on November 18, 2018. The size of the braided network at that time was only 177 MiB. The early Arweave was similar to today in some aspects, with a 2-minute block time and a maximum of 1,000 transactions per block. Beyond that, there are more different aspects, such as the size limit of only 5.8 MiB per transaction. And it uses a mining mechanism called Proof of Access.
Then the question is, what is Proof of Access (PoA)?
Simply put, in order to generate a new block, miners must prove that they have access to other blocks in the blockchain history. So Proof of Access randomly selects a historical block from the chain and requires miners to put that historical block as a recall block (Recall Block) into the current block they are trying to generate. And this will be a complete backup of this traceback block.
The idea was that miners did not have to store all the blocks, as long as they could prove they had access to the blocks, they could compete in mining. (Dmac used a racing analogy in his video to facilitate understanding, which is quoted here.)
First of all, this game has a finish line, which will move with the number of participants or mining speed, so as to Make sure the game always ends in about two minutes. This is the reason for the two-minute block time.
Secondly, this game is divided into two parts.
·The first part, which can be called the qualifying round, miners must prove that they can access historical blocks. Once you have the designated block in hand, you can enter the finals. If miners don’t have the block stored, it doesn’t matter, they can still access it from their peers and join the competition as well.
·The second part is equivalent to the finals after the qualifying round. This part is to use hash computing power to mine purely in a proof-of-work manner. In essence, it consumes energy to calculate hashes and ultimately wins the game.
Once a miner crosses the finish line, the game ends and the next one begins. The mining rewards are all owned by one winner, which makes mining extremely intense. As a result, Arweave began to grow rapidly.

Arweave 1.7: RandomX
The early Arweave principle was a very simple and easy-to-understand mechanism, but it didn’t take long for researchers to Just be aware of the possible undesirable consequences. That is, miners may adopt some strategies that are detrimental to the network, which we call corrupt strategies.
Mainly because some miners have to access other people's blocks when they do not store designated quick access blocks, which makes them one step slower than miners who have stored blocks and lose at the starting line. But the solution is also simple, just stack a lot of GPUs to make up for this flaw with a lot of computing power and consume a lot of energy, so they can even surpass the miners who store blocks and maintain fast access. If this strategy becomes mainstream, miners will no longer store and share blocks. Instead, they will continue to optimize computing equipment and consume large amounts of energy to win the competition. The end result will be that the usefulness of the network is greatly reduced, and the data gradually becomes centralized. This is obviously a depraved departure for storage networks.
To solve this problem, Arweave version 1.7 appeared.
The biggest feature of this version is the introduction of a mechanism called RandomX. It is a hash formula that is very difficult to run on a GPU or ASIC device, which makes miners give up stacking GPU computing power and only use general-purpose CPUs to compete in the hashing power competition.
Arweave 1.8/1.9: 10 MiB transaction size with SQL lite
For miners, there are more important matters to deal with besides proving their ability to access historical blocks , that is, processing transactions posted by users to Arweave.
All new user transaction data must be packaged into new blocks, which is the minimum requirement for a public chain. In the Arweave network, when a user submits a transaction data to a miner, the miner will not only package the data into the block he is about to submit, but also share it with other miners, so that all miners can This transaction data is packaged into the respective blocks to be submitted. Why do they do this? There are at least two reasons for this:
· They are financially incentivized to do this because each transaction data included in a block increases the reward for that block. Miners share transaction data with each other to ensure that whoever wins the right to produce a block gets the maximum reward.
·Prevent the death spiral of network development. If users’ transaction data is often not packaged into blocks, there will be fewer and fewer users, the network will lose its value, and miners’ income will also decrease. This is something no one wants to see.
So miners choose to maximize their own interests in this mutually beneficial way. But this brings about a problem in data transmission, which becomes a bottleneck of network scalability. The more transactions there are, the larger the blocks, and the 5.8 MiB transaction limit doesn’t help. Therefore, Arweave gained some relief by hard forking and increasing the transaction size to 10 MiB.
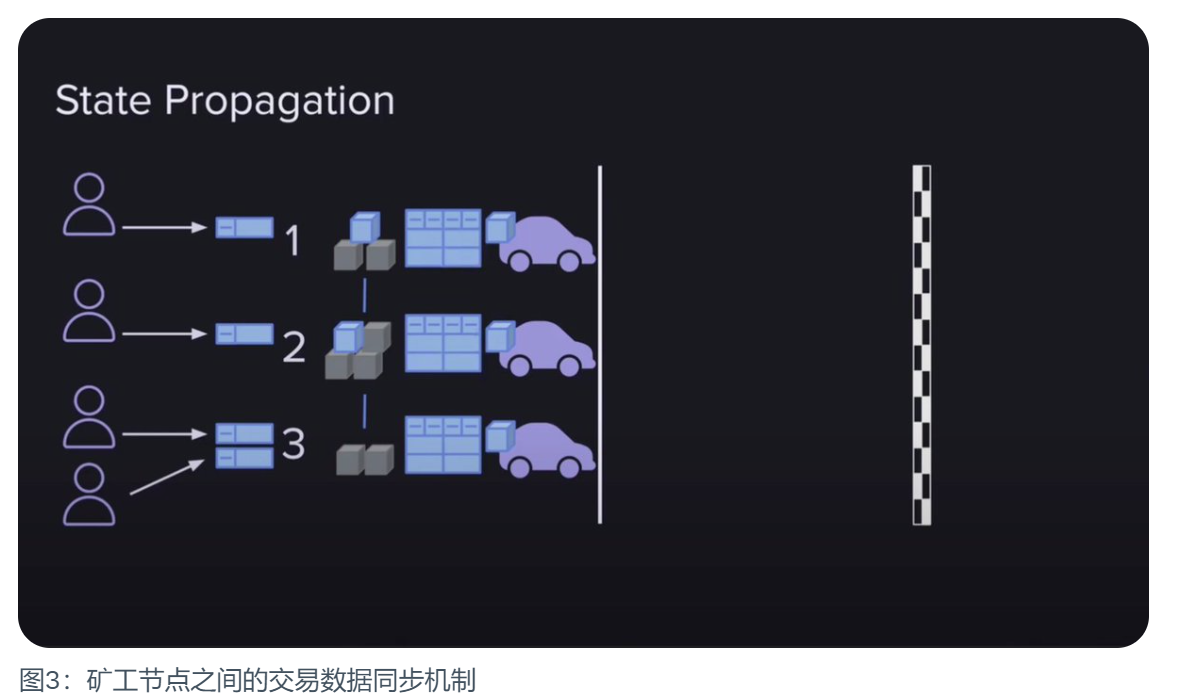
But even so, the problem of transmission bottleneck has not been solved. Arweave is a globally distributed network of miners, and all miners need to synchronize their status. And each miner has a different speed connection, which gives the network an average connection speed. In order for the network to produce a new block every two minutes, the connection speed needs to be fast enough to upload all the data that is expected to be stored in those two minutes. If users upload data that exceeds the average connection speed of the network, it will cause congestion and reduce the effectiveness of the network. This will become a stumbling block for Arweave's development. Therefore, the subsequent updated version 1.9 uses infrastructure such as SQL lite to improve network performance.
Arweave 2.0: SPoA
In March 2020, the Arweave 2.0 update introduced two important updates to the network, thereby lifting the shackles of network scalability and breaking the shackles on network scalability. The limits of data storage capabilities on Arweave.
The first update is Succinct Proof. This is built on the Merkle tree cryptographic structure, which enables miners to prove that they stored all bytes in a block by providing a simple Merkle tree-like compressed branch path. The change it brings is that miners only need to pack a concise proof of less than 1 KiB into the block, instead of packing a traceback block that may be 10 GiB.
The second update is "Format 2 Transactions". This version optimizes the transaction format in order to slim down the data transmission blocks shared between nodes. Compared with the "Format 1 transaction" mode that requires the transaction header and data to be added to the block at the same time, the "Format 2 transaction" allows the transaction header and data to be separated, that is, in the sharing and transmission of block information data between miner nodes, In addition to the concise proof of backtracking blocks, all transactions only need to add transaction headers to the block, and transaction data can be added to the block after the competition ends. This will significantly reduce the transmission requirements when synchronizing intra-block transactions between miner nodes.
The result of these updates is that it creates blocks that are lighter and easier to transmit than in the past, freeing up excess bandwidth in the network. Miners will use this excess bandwidth to transmit the data of "Format 2 transactions" because this data will become lookback blocks in the future. Therefore, the scalability problem is solved.
Arweave 2.4: SPoRA
Have all the issues in the Arweave network been resolved so far? The answer is obviously not. Another problem arises due to the new SPoA mechanism.
A mining strategy similar to miners stacking GPU computing power has emerged again. Although this time it is not a computing power centralization problem of GPU stacking, it brings a mainstream strategy that may be more computing-centric. That's where fast access storage pools come in. All historical blocks are stored in these storage pools, and when proofs of access generate a random lookback block, they can quickly generate proofs and then synchronize between miners at extremely fast speeds.
Although this does not seem to be a big problem, the data can still get enough backup and storage in such a strategy. But the problem is that this strategy will subtly shift the focus of miners. Miners no longer have the incentive to obtain high-speed access to data, because now it is very easy and fast to transfer proof, so they will invest most of their energy into proof of work. in the hash operation, not the data storage. Isn’t this just another form of depraved strategy?

As a result, Arweave has undergone several functional upgrades, such as data index iteration (Indexing), wallet list compression (Wallet List), V1 version transaction data migration, etc. . Finally ushered in another major version iteration - SPoRA, a concise proof of random access.
SPoRA truly introduces Arweave into a new era. Through mechanism iteration, miners' attention shifts from hash calculation to data storage.
So, what difference does a concise proof of random access make?
It first has two prerequisites,
·Indexed Dataset. Thanks to the iterative Indexing feature in version 2.1, it marks each data chunk (Chunk) in the weaving network with a global offset so that each data chunk can be quickly accessed through this global offset. This brings us to the core mechanism of SPoRA - the continuous retrieval of data blocks. It is worth reminding that the data block (Chunk) mentioned here is the smallest data unit after splitting a large file, and its size is 256 KiB. It is not the concept of Block.
·Slow Hash. This hash is used to randomly select candidate chunks. Thanks to the RandomX algorithm introduced in version 1.7, miners cannot use computing power stacking to get ahead and can only use the CPU for calculations.
Based on these two prerequisites, the SPoRA mechanism has 4 steps
The first step is to generate a random number and use the random number and the previous block information to generate a slow hash through RandomX;
The second step In the first step, use this slow hash to calculate a unique traceback byte (Recall Byte, which is the global offset of the data block);
In the third step, the miner uses this traceback byte to find the corresponding traceback byte in its own storage space. data block. If the miner does not store the data block, return to the first step and start again;
The fourth step is to use the slow hash generated in the first step and the newly found data block to perform a fast hash;
The fifth step, if the calculated hash result is greater than the current mining difficulty value, the mining and distribution of the block is completed. Otherwise, go back to step one and start again.
So as you can see here, there is a huge incentive for miners to store as much data as possible on hard drives that can be connected to their CPUs via very fast buses, rather than in storage pools far away . Completed the transformation of mining strategy from calculation-oriented to storage-oriented.
Arweave 2.5: Packing and data explosion
SPoRA makes miners start storing data like crazy because this is the lowest hanging fruit to improve mining efficiency. So what happens next?
Some smart miners realized that the bottleneck under this mechanism was actually how fast it could get data from the hard drive. The more data blocks obtained from the hard disk, the more concise proofs can be calculated, the more hash operations can be performed, and the higher the chance of mining.
So if a miner spends ten times the cost on a hard drive, such as using an SSD with faster read and write speeds to store data, then the hashing power the miner has will be ten times greater. Of course, there will also be an arms race similar to GPU computing power. Faster storage formats than SSDs will also emerge, such as RAM drives, exotic storage formats with faster transfer speeds. But it all depends on the input-output ratio.
Now, the fastest speed at which a miner can generate hashes is the read and write speed of an SSD hard drive, which sets a lower upper limit on energy consumption similar to the PoW model, making it more environmentally friendly.
Is this perfect? Of course not yet. Technicians believe they can do better on this basis.
In order to upload a larger amount of data, Arweave 2.5 introduces the data bundle mechanism. While this isn't really a protocol upgrade, it has been an important part of the scalability plan, allowing the network to explode in size. Because it breaks the 1000 transactions per block cap we talked about at the beginning. The data bundle only takes up one of those 1,000 transactions. This laid the foundation for Arweave 2.6.
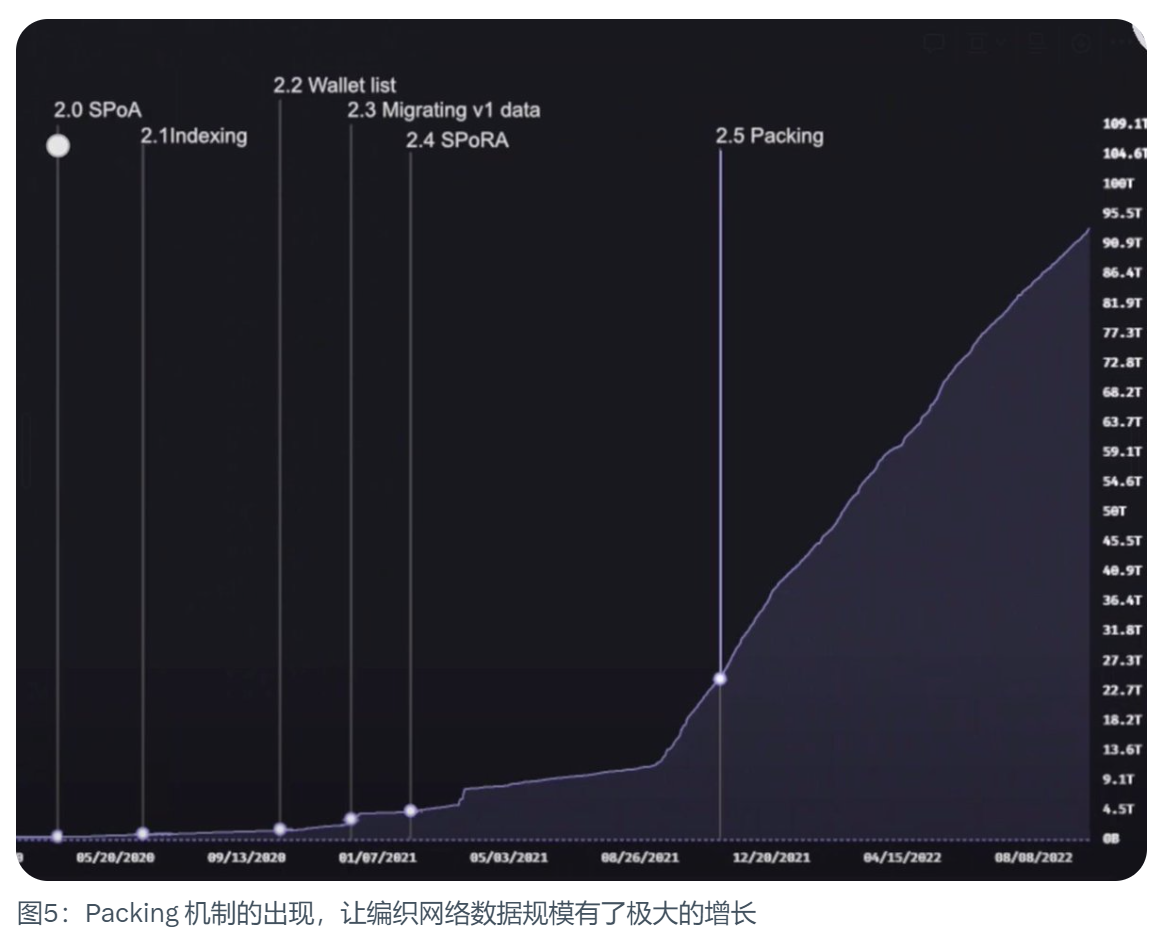
Arweave 2.6
Arweave 2.6 is a major version upgrade since SPoRA. It has taken another step toward its vision of making Arweave mining more cost-effective to promote a more decentralized distribution of miners.
So what exactly is the difference? Due to space issues, only a brief introduction will be given here. In the future, the mechanism design of Arweave 2.6 will be explained in more detail.
To put it simply, Arweave 2.6 is the speed-limited version of SPoRA. It introduces a verifiable encryption clock to SPoRA that can tick once per second, which we call a Hash Chain.
·It generates a mining hash (Mining Hash) every tick,
·Miners choose an index of their stored data partition to participate in mining,
·Combined this mining hash With the partition index, a traceback range can be generated in the stored data partition selected by the miner. This traceback range includes 400 traceback blocks. These are the traceback blocks that the miner can use to mine. In addition to this traceback range, another traceback range 2 will be randomly generated in the weave network (Weave). If the miner stores enough data partitions, he can obtain this scope 2, which is another 400 traceback blocks. Mining opportunities to increase the chance of final victory. This creates a good incentive for miners to store enough copies of the data partitions.
·Miners use the data blocks within the backtracking range to test one by one. If the result is greater than the current given network difficulty, they win the right to mine. If not, the next data block is used for testing.
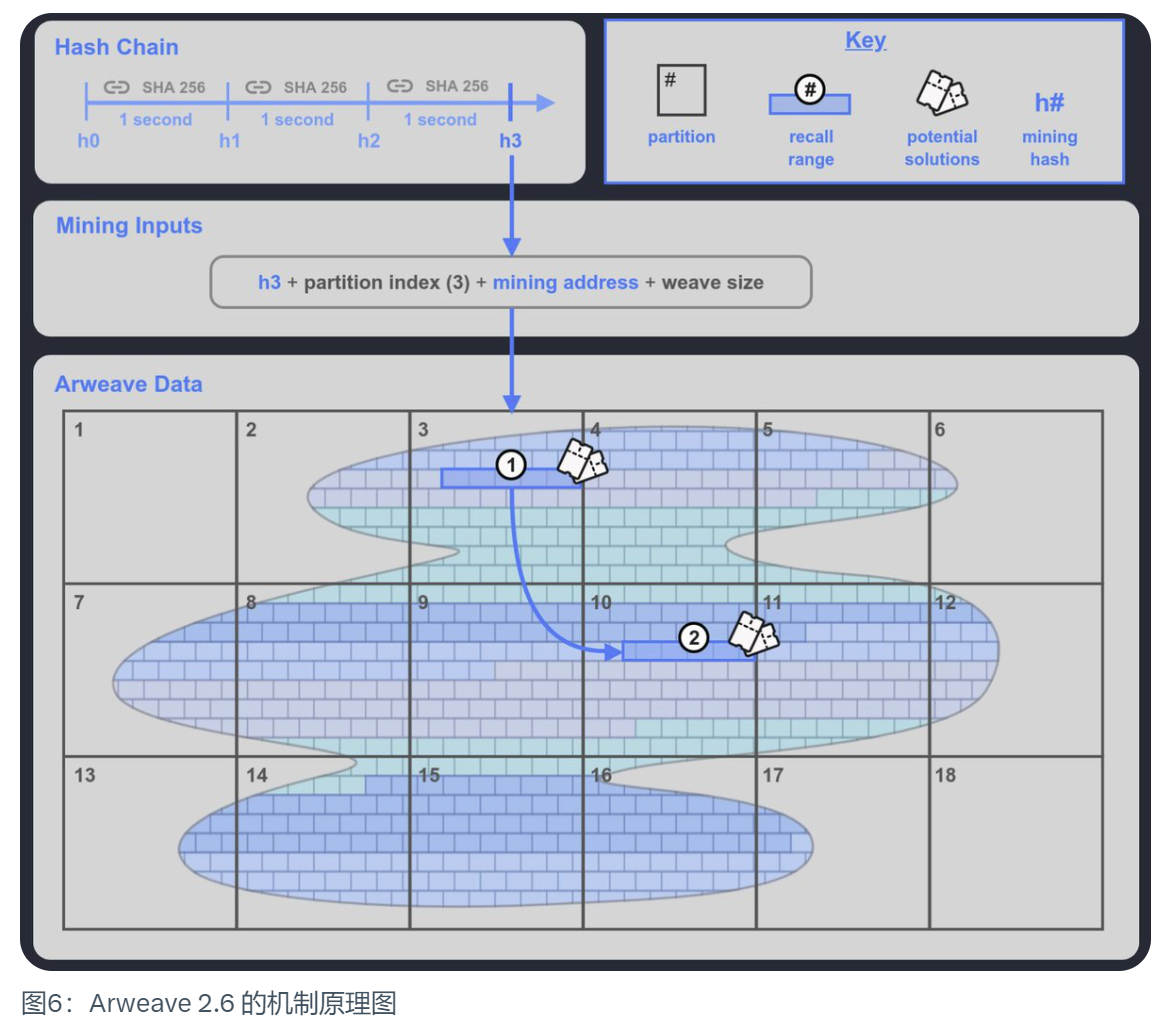
This means that the maximum number of hashes that will be generated per second is fixed. Version 2.6 controls this number to a level that can be handled by ordinary mechanical hard disk performance. within the range. This makes the original SSD hard drive's maximum speed of thousands or hundreds of thousands of hashes per second become a display, and can only compete with mechanical hard drives at a speed of several hundred hashes per second. It's like a Lamborghini competing against a Toyota Prius in a race where the speed limit is 60 kilometers per hour. The advantage of the Lamborghini is greatly limited. Therefore, the biggest contributor to mining performance now is the number of data sets stored by miners.
The above are some important iterative milestones in Arweave’s development history. From PoA to SPoA to SPoRA to the speed-limited version of Arweave 2.6, SPoRA, the original vision has always been followed. On December 26, 2023, Arweave officially released the 2.7 version of the white paper, which made great adjustments based on these mechanisms and evolved the consensus mechanism to SPoRes’ simple replication proof.
Arweave, Arweave's working principle and significance of existence Golden Finance, this article briefly introduces Arweave's working principle and value.
JinseFinanceIn this article, we discuss in detail how storage donation works and then study its characteristics and risk profile by simulating its execution using Markov chains.
JinseFinanceThis article will explore the redundancy mechanisms of Arweave and IPFS, and which option is safer for your data.
JinseFinance100 billion WhatsApp messages are sent every day. Most blockchains are not designed for storage. If you want to store 100 billion WhatsApp messages on Ethereum or any blockchain, it will be extremely expensive.
JinseFinanceThis article explores how Arweave and IPFS store, maintain, and access files, and how this affects the reliability and durability of digital assets.
JinseFinanceArweave is a decentralized data storage solution that provides permanent and immutable data storage services through its Blockweave technology and native cryptocurrency AR token.
JinseFinanceWhy is Arweave not a replacement for Filecoin, but a more significant innovation worthy of attention?
JinseFinanceIrys plans to fork Arweave, resetting token supply, a move criticized by Arweave's founder as short-sighted and greedy.
 BerniceJinseFinance
BerniceJinseFinanceThis event is poised to host more than a hundred Arweave ecosystem developers and investors, offering attendees exclusive perks such as product testing opportunities, AR airdrop rewards, and practical merchandise.
 Samantha
Samantha