
Microsoft nâng cao khả năng hỗ trợ cho các mô hình OpenAI GPT-4-5 và GPT-5
Theo như đưa tin, Microsoft có kế hoạch lưu trữ mô hình mới nhất của OpenAI sớm nhất là vào tuần tới.
 JinseFinance
JinseFinance

Nguồn: Trái tim của cỗ máy
Ban biên tập trái tim của máy móc< / strong>
AI đa năng, AI có thể sử dụng trong cuộc sống hàng ngày Nếu nó không được làm như thế này, tôi sẽ rất xấu hổ khi khai mạc một hội nghị ngay bây giờ.
Sáng sớm ngày 15 tháng 5, “Gala Lễ hội mùa xuân công nghệ” thường niên của Google I/O Developer Conference đã chính thức khai mạc. Bài phát biểu chính dài 110 phút đề cập đến trí tuệ nhân tạo bao nhiêu lần? Google đã thực hiện số liệu thống kê của riêng mình:

Đúng vậy, AI đang được nhắc đến hàng phút.
Sự cạnh tranh về AI sáng tạo gần đây đã đạt đến đỉnh điểm mới và nội dung của hội nghị I/O này đương nhiên xoay quanh trí tuệ nhân tạo.
“Một năm trước, trên sân khấu này, chúng tôi lần đầu tiên chia sẻ kế hoạch cho Gemini, một mô hình lớn đa phương thức gốc. Nó đánh dấu một thế hệ I/O mới,” Giám đốc điều hành Google Sundar Pichai Yi (Sundar Pichai) cho biết. "Hôm nay, chúng tôi hy vọng mọi người có thể hưởng lợi từ công nghệ của Gemini. Những tính năng đột phá này sẽ được đưa vào tìm kiếm, hình ảnh, công cụ năng suất, hệ thống Android, v.v."
24 giờ trước, OpenAI đã cố tình dẫn đầu Phát hành GPT-4o , gây chấn động thế giới với khả năng tương tác bằng giọng nói, video và văn bản theo thời gian thực. Hôm nay, Google đã trình diễn Project Astra và Veo, dự án này trực tiếp đánh giá GPT-4o và Sora dẫn đầu OpenAI hiện tại.
Đây là ảnh chụp trực tiếp nguyên mẫu của Project Astra:
Chúng ta đang chứng kiến những cuộc chiến kinh doanh cao cấp nhất, được tiến hành theo cách khiêm tốn nhất.
Tại hội nghị I/O, Google đã trình diễn khả năng tìm kiếm được hỗ trợ bởi phiên bản mới nhất của Gemini.
25 năm trước, Google đã hỗ trợ làn sóng đầu tiên của Thời đại Thông tin bằng công cụ tìm kiếm của mình. Giờ đây, các công cụ tìm kiếm có thể trả lời tốt hơn các câu hỏi của bạn khi công nghệ AI tổng hợp phát triển, tận dụng tốt hơn nội dung theo ngữ cảnh, nhận thức về vị trí và khả năng thông tin theo thời gian thực.
Dựa trên phiên bản mới nhất của mô hình Gemini có thể tùy chỉnh, bạn có thể hỏi công cụ tìm kiếm bất kỳ điều gì bạn nghĩ hoặc bất kỳ điều gì cần thực hiện - từ nghiên cứu, lập kế hoạch đến trí tưởng tượng và Google sẽ lo liệu tất cả.
Đôi khi bạn muốn có câu trả lời nhanh chóng nhưng không có thời gian để ghép tất cả các câu hỏi lại thông tin cùng nhau. Lúc này, công cụ tìm kiếm sẽ thực hiện công việc cho bạn thông qua AI tổng quan. Được tổng quan bởi Trí tuệ nhân tạo, AI có thể tự động truy cập một số lượng lớn trang web để đưa ra câu trả lời cho một câu hỏi phức tạp.
Với khả năng suy luận nhiều bước tùy chỉnh của Gemini, AI Tổng quan sẽ giúp giải quyết các vấn đề ngày càng phức tạp. Bạn không cần phải chia câu hỏi của mình thành nhiều tìm kiếm nữa, giờ đây bạn có thể hỏi những câu hỏi phức tạp nhất cùng một lúc, với tất cả các sắc thái và lưu ý mà bạn đã nghĩ đến.
Ngoài việc tìm ra câu trả lời hoặc thông tin phù hợp cho các câu hỏi phức tạp, các công cụ tìm kiếm có thể làm việc với bạn để lập kế hoạch theo từng bước.
Tại I/O, Google đã nêu bật khả năng đa phương thức và văn bản dài của các mô hình lớn. Những tiến bộ về công nghệ đang khiến các công cụ tăng năng suất như Google Workspace trở nên thông minh hơn.
Ví dụ: bây giờ chúng ta có thể yêu cầu Gemini tóm tắt tất cả các email gần đây từ trường học. Nó sẽ xác định các email có liên quan ở chế độ nền và thậm chí phân tích các tệp đính kèm như tệp PDF. Sau đó, bạn sẽ nhận được bản tóm tắt các điểm chính và các mục hành động.

Nếu bạn đang đi du lịch và không thể tham dự cuộc họp dự án và việc ghi lại cuộc họp là một giờ. Nếu cuộc họp được tổ chức trên Google Meet, bạn có thể yêu cầu Song Tử giới thiệu cho mình những điểm chính. Có một nhóm đang tìm kiếm tình nguyện viên và bạn có mặt ngay ngày hôm đó. Song Tử có thể giúp bạn viết email để đăng ký.
Hơn nữa, Google nhận thấy nhiều cơ hội hơn trong các Đại lý mô hình lớn, tin rằng họ có thể hoạt động như những hệ thống thông minh với khả năng suy luận, lập kế hoạch và ghi nhớ. Các ứng dụng sử dụng Agent có thể “suy nghĩ” trước nhiều bước và hoạt động trên nhiều phần mềm, hệ thống giúp bạn hoàn thành công việc thuận tiện hơn. Ý tưởng này đã được phản ánh trong các sản phẩm như công cụ tìm kiếm và mọi người có thể trực tiếp nhìn thấy sự cải thiện của khả năng AI.
Ít nhất về mặt ứng dụng Family Bucket, Google đi trước OpenAI.
Google có lợi thế bẩm sinh về mặt sinh thái, nhưng Nền tảng của các mô hình lớn là rất quan trọng và Google đã tích hợp sức mạnh của nhóm riêng của mình và DeepMind cho mục đích này. Hôm nay, Hassabis cũng lần đầu tiên lên sân khấu tại hội nghị I/O và đích thân giới thiệu mẫu mới bí ẩn.

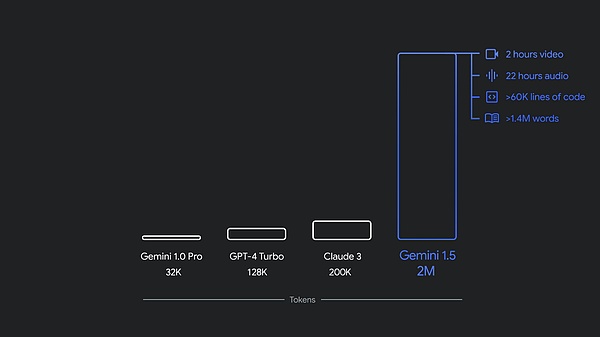
Vào tháng 12 năm ngoái, Google đã ra mắt Gemini 1.0, phiên bản đa phương thức gốc đầu tiên của hãng model , có ba kích cỡ: Ultra, Pro và Nano. Chỉ vài tháng sau, Google đã phát hành phiên bản mới, 1.5 Pro, với hiệu suất được cải thiện và cửa sổ ngữ cảnh vượt quá 1 triệu mã thông báo.
Giờ đây, Google đã công bố giới thiệu một loạt bản cập nhật cho loạt mô hình Gemini, bao gồm cả Gemini 1.5 Flash mới, mô hình nhẹ của Google về tốc độ và hiệu quả cũng như Project Astra, tầm nhìn A của Google vì tương lai của trợ lý trí tuệ nhân tạo).
Hiện tại, 1.5 Pro và 1.5 Flash đều có sẵn ở dạng xem trước công khai, với cửa sổ ngữ cảnh 1 triệu mã thông báo có sẵn trong Google AI Studio và Vertex AI. 1.5 Pro hiện cũng cung cấp cửa sổ ngữ cảnh 2 triệu mã thông báo thông qua danh sách chờ cho các nhà phát triển và khách hàng Google Cloud sử dụng API.
Ngoài ra, Gemini Nano cũng đã mở rộng từ nhập văn bản thuần túy sang nhập hình ảnh. Cuối năm nay, bắt đầu với Pixel, Google sẽ ra mắt Gemini Nano đa chế độ. Điều này có nghĩa là người dùng điện thoại di động không chỉ có thể xử lý văn bản nhập mà còn hiểu được nhiều thông tin theo ngữ cảnh hơn như hình ảnh, âm thanh và ngôn ngữ nói.
1.5 Flash mới được tối ưu hóa về tốc độ và hiệu quả.
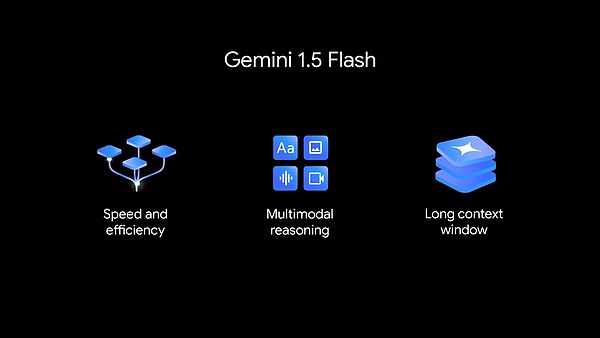
1.5 Flash là thành viên mới nhất của dòng mô hình Song Tử và nhanh nhất trong số các mô hình Mô hình API Gemini. Nó được tối ưu hóa cho các nhiệm vụ quy mô lớn, khối lượng lớn, tần suất cao, với các dịch vụ tiết kiệm chi phí hơn và thời lượng ngữ cảnh dài mang tính đột phá (1 triệu mã thông báo).

Gemini 1.5 Flash có khả năng suy luận đa phương thức mạnh mẽ và cửa sổ ngữ cảnh dài mang tính đột phá.
1.5 Flash vượt trội trong việc tóm tắt, ứng dụng trò chuyện, phụ đề hình ảnh và video, trích xuất dữ liệu từ các tài liệu và bảng dài, v.v. Đó là bởi vì 1.5 Pro đào tạo nó thông qua một quy trình gọi là “chưng cất”, chuyển kiến thức và kỹ năng cơ bản nhất từ mô hình lớn hơn sang mô hình nhỏ hơn, hiệu quả hơn.
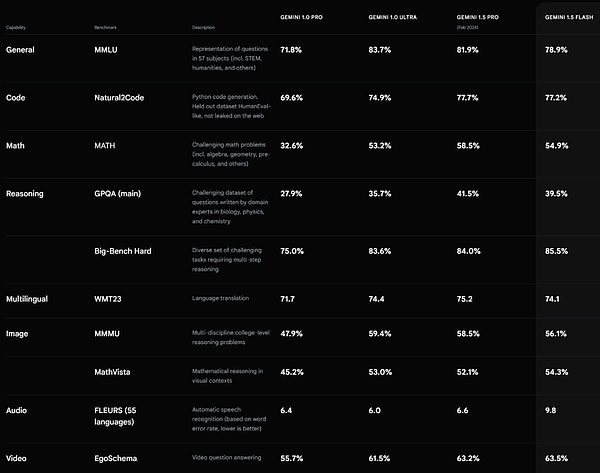
Hiệu suất Flash của Gemini 1.5. Nguồn https://deepmind.google/technologists/gemini/#introduction
Google đã đề cập rằng hiện nay có hơn 1,5 triệu nhà phát triển đang sử dụng mô hình Gemini và hơn 2 tỷ người dùng sản phẩm đã sử dụng Gemini.

Trong vài tháng qua, Google đã thêm cửa sổ ngữ cảnh Gemini 1.5 Pro vào Mở rộng Ngoài 2 triệu mã thông báo, Google cũng đã nâng cao khả năng tạo mã, lập kế hoạch và lập luận logic, đối thoại nhiều lượt cũng như khả năng hiểu âm thanh và hình ảnh thông qua các cải tiến về dữ liệu và thuật toán.

1.5 Pro giờ đây có thể làm theo các hướng dẫn ngày càng phức tạp và chi tiết, bao gồm cả các Chỉ thị đó chỉ định hành vi cấp sản phẩm liên quan đến vai trò, định dạng và kiểu dáng. Ngoài ra, Google còn cho phép người dùng hướng dẫn hành vi của mô hình bằng cách thiết lập các lệnh hệ thống.
Giờ đây, Google đã bổ sung tính năng hiểu âm thanh trong API Gemini và Google AI Studio, nên 1.5 Pro hiện có thể thực hiện suy luận về hình ảnh và âm thanh video được tải lên trong Google AI Studio. Ngoài ra, Google đang tích hợp 1.5 Pro vào các sản phẩm của Google, bao gồm cả Gemini Advanced và ứng dụng Workspace.
Gemini 1.5 Pro có giá 3,50 USD cho 1 triệu token.
Trên thực tế, một trong những bước chuyển đổi thú vị nhất tại Gemini là Google Tìm kiếm.
Trong năm qua, Google Tìm kiếm đã trả lời hàng tỷ truy vấn như một phần của trải nghiệm tạo tìm kiếm. Giờ đây, mọi người có thể sử dụng nó để tìm kiếm theo những cách mới, đặt những loại câu hỏi mới, truy vấn dài hơn, phức tạp hơn, thậm chí tìm kiếm bằng ảnh và nhận thông tin tốt nhất mà web cung cấp.

Google sắp ra mắt tính năng Hỏi Ảnh. Trong trường hợp của Google Photos, tính năng này đã ra mắt cách đây khoảng 9 năm. Ngày nay, người dùng tải lên hơn 6 tỷ ảnh và video mỗi ngày. Mọi người thích sử dụng hình ảnh để tìm kiếm cuộc sống của họ. Song Tử làm cho nó dễ dàng hơn.
Giả sử bạn đang trả tiền ở một bãi đậu xe và không thể nhớ được biển số xe của mình. Trước đây, bạn có thể tìm kiếm từ khóa trong ảnh và sau đó cuộn qua nhiều bức ảnh để tìm biển số xe. Bây giờ, tất cả những gì bạn phải làm là yêu cầu chụp ảnh.

Một ví dụ khác, bạn nhớ lại thời thơ ấu của con gái Lucia của bạn. Bây giờ, bạn có thể hỏi bức ảnh: Lucia học bơi khi nào? Bạn cũng có thể theo dõi một điều gì đó phức tạp hơn: cho tôi biết quá trình bơi lội của Lucia diễn ra như thế nào.
Ở đây, Gemini vượt xa việc tìm kiếm đơn giản và xác định các bối cảnh khác nhau - bao gồm các cảnh khác nhau như bể bơi, đại dương, v.v. và các bức ảnh tập hợp mọi thứ lại với nhau để dễ xem. Google sẽ ra mắt Ask Photos vào mùa hè này và sắp ra mắt nhiều tính năng hơn.

Hôm nay, Google cũng tung ra một loạt bản cập nhật cho open nguồn mô hình lớn Gemma— —Gemma 2 đã có mặt.
Theo báo cáo, Gemma 2 áp dụng kiến trúc mới và nhằm mục đích đạt được hiệu suất và hiệu quả đột phá. Tham số mô hình nguồn mở mới là 27B.

Ngoài ra, gia đình Gemma cũng được mở rộng với PaliGemma, mô hình ngôn ngữ hình ảnh đầu tiên của Google lấy cảm hứng từ PaLI-3.
Agent luôn là hướng nghiên cứu trọng tâm của Google DeepMind.
Hôm qua, chúng tôi đã xem GPT-4o của OpenAI và bị sốc trước khả năng tương tác video và thoại theo thời gian thực mạnh mẽ của nó.
Hôm nay, Dự án tổng thể về tác nhân AI tương tác bằng giọng nói và tầm nhìn của DeepMind đã được công bố. Đây là tầm nhìn của Google DeepMind về các trợ lý AI trong tương lai.
Để thực sự hiệu quả, Google cho biết, các đặc vụ cần hiểu và phản ứng với thế giới thực phức tạp, năng động giống như con người. Họ cũng cần tiếp thu và ghi nhớ những gì họ nhìn thấy và nghe thấy để hiểu ngữ cảnh và hành động. . Ngoài ra, tổng đài viên cần phải chủ động, dễ dạy và được cá nhân hóa để người dùng có thể nói chuyện với tổng đài một cách tự nhiên, không bị trễ hoặc chậm trễ.
Trong vài năm qua, Google đã nỗ lực cải thiện cách các mô hình của chúng tôi nhận thức, suy luận và trò chuyện để giúp tốc độ và chất lượng tương tác trở nên tự nhiên hơn.
Trong Keynote hôm nay, Google DeepMind đã trình diễn khả năng tương tác của Project Astra:
Theo báo cáo, Google đã phát triển một nguyên mẫu tác nhân thông minh dựa trên Gemini, có thể liên tục Xử lý thông tin nhanh hơn bằng cách mã hóa khung hình video, kết hợp đầu vào video và giọng nói thành dòng thời gian của các sự kiện và lưu thông tin này vào bộ nhớ đệm để thu hồi hiệu quả.
Thông qua mô hình giọng nói, Google cũng nâng cao khả năng phát âm của nhân viên hỗ trợ và cung cấp cho nhân viên hỗ trợ nhiều ngữ điệu hơn. Các tác nhân này có thể hiểu rõ hơn về bối cảnh mà chúng được sử dụng và phản hồi nhanh chóng trong các cuộc trò chuyện.
Chỉ là một nhận xét ngắn gọn ở đây. Tâm huyết của máy cho thấy bản demo do dự án Project Astra tung ra kém hơn nhiều so với bản demo thời gian thực GPT-4o về mặt trải nghiệm tương tác. Cho dù đó là độ dài phản hồi, độ giàu cảm xúc của giọng nói, khả năng ngắt quãng, v.v., trải nghiệm tương tác của GPT-4o dường như tự nhiên hơn. Tôi tự hỏi người đọc cảm thấy thế nào?
Về video do AI tạo ra, Google đã công bố ra mắt mô hình tạo video Veo. Veo có khả năng sản xuất video độ phân giải 1080p chất lượng cao với nhiều phong cách khác nhau và có thể dài hơn một phút.
Với sự hiểu biết sâu sắc về ngôn ngữ tự nhiên và ngữ nghĩa hình ảnh, mô hình Veo đã tạo ra những bước đột phá trong việc hiểu nội dung video, hiển thị hình ảnh độ phân giải cao và mô phỏng các nguyên lý vật lý. Video do Veo tạo ra thể hiện chính xác và tỉ mỉ ý định sáng tạo của người dùng.
Ví dụ: nhập dấu nhắc văn bản:
Nhiều loài sứa đốm đang dao động dưới nước. phát sáng trong đại dương sâu thẳm.
(Nhiều loài sứa đốm đập xung dưới nước. Cơ thể trong suốt của chúng lấp lánh trong đại dương sâu thẳm. )< /span>
Đối với một ví dụ khác, để tạo video nhân vật, hãy nhập dấu nhắc:
Một chàng cao bồi đơn độc cưỡi ngựa băng qua vùng đồng bằng rộng mở lúc hoàng hôn tuyệt đẹp, ánh sáng dịu nhẹ, màu sắc ấm áp.
(tại Dưới ánh hoàng hôn tuyệt đẹp, ánh sáng dịu nhẹ và màu sắc ấm áp, một chàng cao bồi đơn độc cưỡi ngựa băng qua vùng đồng bằng rộng mở)
Video cận cảnh về một người, nhập dấu nhắc: <. >
Một người phụ nữ ngồi một mình trong quán cà phê thiếu ánh sáng, một cuốn tiểu thuyết đang đọc dở mở ra trước mặt cô ấy. không khí đen trắng.
(Một người phụ nữ đang ngồi một mình trong quán cà phê thiếu ánh sáng, đọc một cuốn sách chưa viết The Cuốn tiểu thuyết đã hoàn thành nằm trước mắt cô. Phim noir mang tính thẩm mỹ, bầu không khí bí ẩn.)
Đáng chú ý, mô hình Veo mang đến khả năng kiểm soát và hiểu biết sáng tạo chưa từng có. -lapsequay" và "chụp ảnh trên không" làm cho video mạch lạc và chân thực.
Ví dụ: đối với ảnh chụp đường bờ biển từ trên không ở cấp độ phim, hãy nhập lời nhắc:
Chụp bằng máy bay không người lái dọc theo bờ biển rừng rậm Hawaii, ngày nắng
(Chụp bằng máy bay không người lái dọc theo bờ biển rừng rậm Hawaii, ngày nắng)< /p>
Veo cũng hỗ trợ sử dụng hình ảnh và văn bản cùng nhau làm lời nhắc tạo video. Bằng cách cung cấp hình ảnh tham chiếu và tín hiệu văn bản, video do Veo tạo tuân theo kiểu hình ảnh và mô tả văn bản của người dùng.
Điều thú vị là bản demo do Google phát hành là một video "alpaca" do Veo tạo ra, dễ gợi nhớ đến mô hình loạt mã nguồn mở Llama của Meta.

Về video dài, Veo có thể sản xuất video dài 60 giây hoặc thậm chí dài hơn . Nó có thể thực hiện điều này chỉ bằng một lời nhắc hoặc bằng cách cung cấp một loạt lời nhắc cùng nhau kể một câu chuyện. Điều này rất quan trọng đối với việc ứng dụng các mô hình tạo video trong sản xuất phim và truyền hình.
Veo xây dựng dựa trên công việc tạo nội dung trực quan của Google, bao gồm Mạng truy vấn sáng tạo (GQN), DVD-GAN, Imagen-Video, Phenaki, WALT, VideoPoet, Lumiere, v.v.
Bắt đầu từ hôm nay, Google sẽ cung cấp phiên bản xem trước của VideoFX cho một số người sáng tạo Với Veo , người sáng tạo có thể tham gia danh sách chờ của Google. Google cũng sẽ đưa một số tính năng của Veo vào các sản phẩm như YouTube Shorts.
Về việc tạo văn bản thành hình ảnh, Google một lần nữa nâng cấp loạt mô hình của mình - phát hành Imagen 3.
Imagen 3 đã được tối ưu hóa và nâng cấp về mặt tạo chi tiết, ánh sáng, nhiễu, v.v. và khả năng hiểu lời nhắc đã được nâng cao đáng kể.
Để giúp Imagen 3 ghi lại chi tiết từ những lời nhắc dài hơn, chẳng hạn như góc máy hoặc bố cục cụ thể, Google đã bổ sung thêm chi tiết phong phú hơn cho chú thích của từng hình ảnh trong dữ liệu đào tạo.
Ví dụ: nếu bạn thêm "hơi mất nét ở tiền cảnh", "ánh sáng ấm", v.v. vào lời nhắc đầu vào, Imagen 3 có thể tạo ra hình ảnh theo yêu cầu:

Ngoài ra, Google đã thực hiện những cải tiến đặc biệt để giải quyết vấn đề "văn bản bị mờ" trong quá trình tạo hình ảnh, nghĩa là nó đã tối ưu hóa khả năng hiển thị hình ảnh để Văn bản trong hình ảnh được tạo ra rõ ràng và cách điệu.

Để cải thiện khả năng sử dụng, Imagen 3 sẽ cung cấp nhiều phiên bản, mỗi phiên bản đều được tối ưu hóa cho các loại nhiệm vụ khác nhau.
Bắt đầu từ hôm nay, Google sẽ cung cấp phiên bản xem trước của Imagen 3 trong ImageFX cho một số người sáng tạo và người dùng có thể đăng ký tham gia danh sách chờ.
Generative AI đang thay đổi cách con người tương tác với công nghệ, đồng thời mang lại lợi ích cho doanh nghiệp Cơ hội hiệu quả lớn. Nhưng những tiến bộ này đòi hỏi sức mạnh tính toán, bộ nhớ và truyền thông cao hơn để đào tạo và tinh chỉnh các mô hình mạnh mẽ nhất.
Để đạt được mục tiêu này, Google đã ra mắt TPU Trillium thế hệ thứ sáu, đây là loại TPU mạnh mẽ và tiết kiệm năng lượng nhất cho đến nay và sẽ được ra mắt chính thức vào cuối năm 2024.
TPU Trillium là phần cứng dành riêng cho AI có khả năng tùy chỉnh cao, nhiều cải tiến được công bố tại hội nghị Google I/O, bao gồm các mẫu mới như Gemini 1.5 Flash, Imagen 3 và Gemma 2, đều được thực hiện trong chương trình Đào tạo. trên TPU và các dịch vụ được cung cấp bằng TPU.

Theo báo cáo, so với TPU v5e, tính toán cao nhất trên mỗi chip của Trillium Hiệu suất TPU được cải thiện gấp 4,7 lần và nó cũng tăng gấp đôi băng thông bộ nhớ băng thông cao (HBM) và băng thông kết nối giữa các chip (ICI). Ngoài ra, Trillium còn có SparseCore thế hệ thứ ba được thiết kế để xử lý các phần nhúng rất lớn phổ biến trong khối lượng công việc đề xuất và xếp hạng nâng cao.
Google cho biết Trillium có thể đào tạo thế hệ mô hình AI mới nhanh hơn đồng thời giảm độ trễ và chi phí. Ngoài ra, Trillium được coi là TPU bền vững nhất của Google cho đến nay, với mức cải thiện hơn 67% về hiệu quả sử dụng năng lượng so với phiên bản tiền nhiệm.
Trillium có thể mở rộng tới 256 TPU (Bộ xử lý Tensor) trong một cụm (nhóm) điện toán có băng thông cao, độ trễ thấp. Ngoài khả năng mở rộng ở cấp độ cụm này, Trillium TPU có thể được mở rộng thành hàng trăm cụm và kết nối hàng nghìn chip thông qua công nghệ đa lát và các đơn vị xử lý thông minh (IPU). Hình thành một siêu máy tính được kết nối với nhau bằng mạng trung tâm dữ liệu nhiều petabit mỗi giây. .
Google đã ra mắt TPU v1 đầu tiên vào đầu năm 2013, sau đó là TPU đám mây vào năm 2017. Những TPU này đã hỗ trợ nhiều dịch vụ khác nhau như tìm kiếm bằng giọng nói theo thời gian thực, nhận dạng đối tượng ảnh và dịch ngôn ngữ. thậm chí còn cung cấp sức mạnh kỹ thuật cho các sản phẩm như hãng xe tự lái Nuro.
Trillium cũng là một phần của Siêu máy tính AI của Google, một kiến trúc siêu máy tính đột phá được thiết kế để xử lý khối lượng công việc AI tiên tiến. Google đang hợp tác với Hugging Face để tối ưu hóa phần cứng cho việc đào tạo và phục vụ mô hình nguồn mở.

Trên đây là tất cả những điểm nổi bật của hội nghị Google I/O ngày hôm nay. Có thể thấy Google đang cạnh tranh hoàn toàn với OpenAI về công nghệ và sản phẩm mô hình lớn. Thông qua việc phát hành OpenAI và Google trong hai ngày qua, chúng ta cũng có thể thấy rằng cuộc thi mô hình lớn đã bước sang một giai đoạn mới: trải nghiệm tương tác đa phương thức và tự nhiên hơn đã trở thành sản phẩm của công nghệ mô hình lớn và được nhiều người chấp nhận hơn. Sự cần thiết.
Hướng tới năm 2024, công nghệ mô hình lớn và đổi mới sản phẩm sẽ mang đến cho chúng ta nhiều bất ngờ hơn.
Theo như đưa tin, Microsoft có kế hoạch lưu trữ mô hình mới nhất của OpenAI sớm nhất là vào tuần tới.
JinseFinanceĐây là lần đầu tiên Google đứng đầu bảng xếp hạng Chatbot Arena.
JinseFinanceOpenAI tuyên bố rằng việc ra mắt GPT-4o mini đánh dấu sự tiến bộ đáng kể trong việc giảm chi phí và nâng cao khả năng của mô hình, đồng thời cam kết làm cho AI trở nên phổ biến và đáng tin cậy hơn.
 WenJun
WenJunOpenAI ra mắt "GPT-4o mini" vào ngày 18 tháng 7, tuyên bố rằng nó rẻ hơn và hiệu quả hơn GPT-3.5 Turbo. OpenAI có bắt chước các bản phát hành thường xuyên của Apple không và điều này có ảnh hưởng đến chất lượng của các mô hình AI tổng hợp của họ không?
 Kikyo
KikyoOpenAI tăng cường nỗ lực với phiên bản kế nhiệm GPT-4, tập trung vào sự an toàn. Trong bối cảnh bị giám sát và chỉ trích về mặt đạo đức, một ủy ban an toàn và an ninh được thành lập để giải quyết các mối lo ngại và đảm bảo sự phát triển AI có trách nhiệm.
 Huang Bo
Huang BoNhững vụ từ chức gần đây tại OpenAI, bao gồm Nhà khoa học trưởng Ilya Sutskever và Jan Leike từ "nhóm siêu liên kết", xuất phát từ những bất đồng về việc ưu tiên an toàn trong bối cảnh ra mắt GPT-4o. Những lo ngại vẫn tồn tại về sự chuyển dịch của OpenAI sang lợi nhuận và các rủi ro bảo mật tiềm ẩn trong các hoạt động hợp tác như bản cập nhật iOS 18 của Apple tích hợp công nghệ OpenAI.
 Weatherly
WeatherlyChỉ 17 tháng sau khi ChatGPT ra mắt, OpenAI đã cho ra đời một siêu AI giống như trong phim khoa học viễn tưởng, hoàn toàn miễn phí và dành cho tất cả mọi người.
JinseFinanceOpenAI hôm thứ Hai đã công bố mô hình ngôn ngữ lớn trí tuệ nhân tạo mới nhất của mình, theo đó sẽ giúp ChatGPT thông minh hơn và dễ sử dụng hơn.
JinseFinanceBản phát hành mới nhất thay đổi các tương tác AI bằng cách mở rộng cơ sở kiến thức đến tháng 4 năm 2023 và giới thiệu hỗ trợ cho các tài liệu 300 trang.
 JixuJinseFinance
JixuJinseFinance